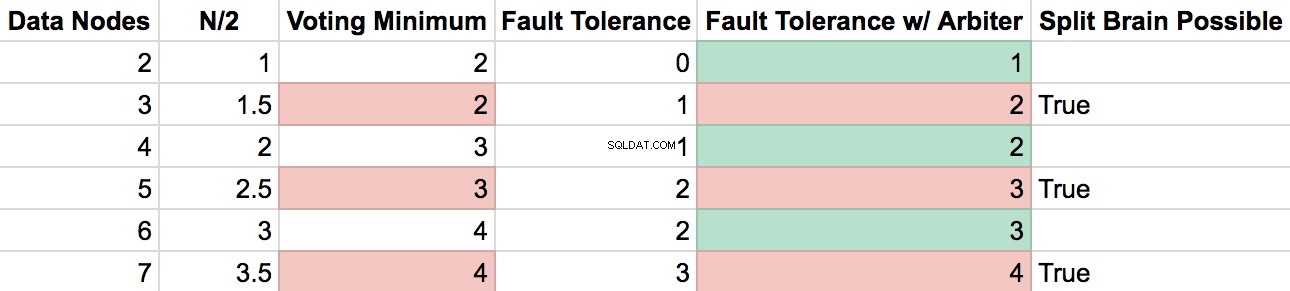
Vytvořil jsem tabulku, abych lépe ilustroval účinek uzlů arbitra v sadě replik.
V zásadě jde o tyto body:
- S RS 2 datovými uzly , ztráta 1 serveru vás dostane pod vaše minimum hlasů (které je "větší než N/2"). To řeší arbitr.
- S RS datových uzlů se sudým číslem , přidání arbitra zvýší vaši odolnost proti chybám o 1, aniž by bylo možné mít 2 hlasovací clustery kvůli rozdělení.
- S RS lichých datových uzlů , přidání arbitra by umožnilo rozdělení vytvořit 2 izolované shluky s „větším než N/2“ hlasů, a tedy scénář rozděleného mozku.
Volby jsou zde vysvětleny [nekvalitně]. V tom dokumentu to uvádí že RS může mít 50 členů (sudý počet) a 7 hlasujících členů. Zdůrazňuji „stavy“, protože to nevysvětluje jak to funguje. Zdá se mi, že pokud dojde k rozkolu se 4 členy (všichni hlasují) na jedné straně a 46 členy (3 hlasujícími) na straně druhé, raději byste měli nechat 46 volit primárky a 4 číst. pouze shluk. Ale právě tomu brání „omezené hlasování“. V takové situaci budete mít ve skutečnosti 4členný cluster s primárním a 46členným clusterem, který je pouze pro čtení. Vysvětlovat, jak to dává smysl, je mimo rozsah této otázky a mimo mé znalosti.