Automatické převzetí služeb při selhání pro replikaci MySQL je předmětem debat již mnoho let.
Je to dobrá nebo špatná věc?
Pro ty s dlouhou pamětí ve světě MySQL si možná vzpomenou na výpadek GitHubu v roce 2012, který byl způsoben hlavně tím, že software dělal nesprávná rozhodnutí.
GitHub pak právě migroval na kombinaci MySQL Replication, Corosync, Pacemaker a Percona Replication Manager. PRM se rozhodl provést převzetí služeb při selhání poté, co selhaly kontroly stavu na hlavním serveru, který byl během migrace schématu přetížen. Byl vybrán nový master, ale fungoval špatně kvůli studeným mezipaměti. Vysoké zatížení dotazů z vytíženého webu způsobilo, že prezenční signály PRM znovu selhaly na studeném hlavním serveru a PRM poté spustilo další převzetí služeb při selhání původního hlavního serveru. A problémy jen pokračovaly, jak je shrnuto níže.
 Zdroj:Henrik Ingo &Massimo Brignoli na Percona Live 2013
Zdroj:Henrik Ingo &Massimo Brignoli na Percona Live 2013 Rychle vpřed o pár let a GitHub je zpět s docela propracovaným rámcem pro správu replikace MySQL a automatizovaného převzetí služeb při selhání! Jak to říká Shlomi Noach:
„Za tímto účelem používáme automatizovaná hlavní přepnutí při selhání. Doba, kterou by člověku zabralo probudit a opravit neúspěšného mastera, přesahuje naše očekávání dostupnosti a provoz takového převzetí služeb při selhání je někdy netriviální. Očekáváme, že hlavní selhání budou automaticky detekována a obnovena do 30 sekund nebo méně, a očekáváme, že převzetí služeb při selhání povede k minimální ztrátě dostupných hostitelů.“
Většina společností není GitHub, ale někdo by mohl namítnout, že žádná společnost nemá ráda výpadky. Výpadky jsou rušivé pro jakýkoli podnik a také stojí peníze. Domnívám se, že většina společností si pravděpodobně přála mít nějaký druh automatizovaného převzetí služeb při selhání, a důvody, proč jej neimplementovat, jsou pravděpodobně složitost stávajících řešení, nedostatek kompetencí při implementaci takových řešení nebo nedostatek důvěry v software, který je třeba přijmout. takové důležité rozhodnutí.
Existuje řada automatizovaných řešení pro překonání selhání, včetně (a nejen) MHA, MMM, MRM, mysqlfailover, Orchestrator a ClusterControl. Některé z nich jsou na trhu již řadu let, jiné jsou novější. To je dobré znamení, několik řešení znamená, že trh existuje a lidé se snaží problém řešit.
Když jsme navrhovali automatické převzetí služeb při selhání v rámci ClusterControl, použili jsme několik hlavních principů:
-
Před převzetím služeb při selhání se ujistěte, že je hlavní server skutečně mrtvý
V případě síťového oddílu, kde software pro přepnutí při selhání ztratí kontakt s masterem, přestane jej vidět. Ale hlavní server může fungovat dobře a zbytek replikační topologie ho může vidět.
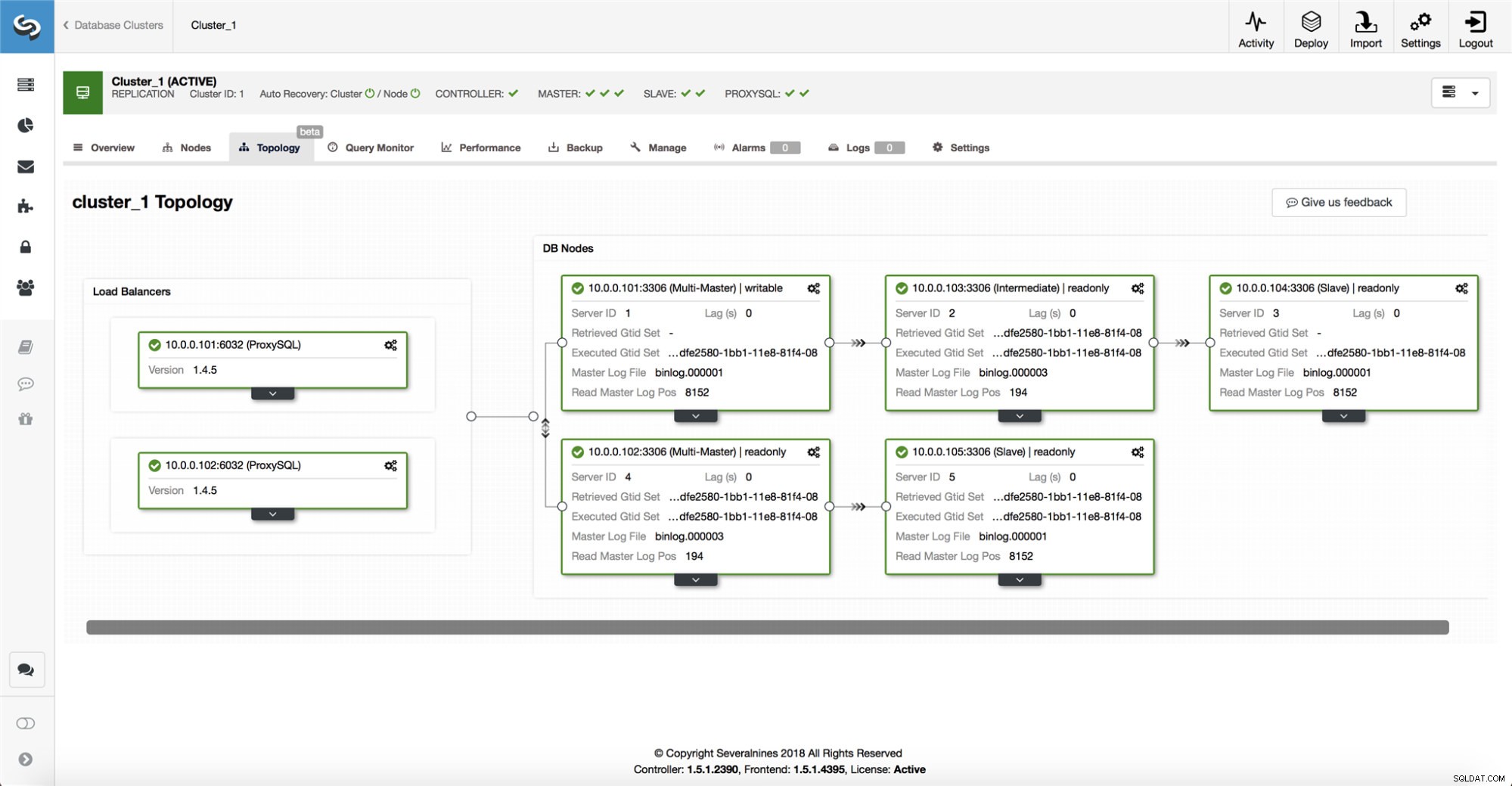
ClusterControl shromažďuje informace ze všech databázových uzlů a také všech použitých databázových proxy/load balancerů a poté vytváří reprezentaci topologie. Nepokusí se o převzetí služeb při selhání, pokud podřízené jednotky vidí hlavní jednotku, ani pokud si ClusterControl není 100% jistý stavem hlavní jednotky.
ClusterControl také usnadňuje vizualizaci topologie nastavení a také stavu různých uzlů (toto je chápání stavu systému ClusterControl na základě informací, které shromažďuje).
-
Převzetí služeb při selhání pouze jednou
O plácání bylo napsáno mnoho. Pokud se nástroj dostupnosti rozhodne provést vícenásobné převzetí služeb při selhání, může to být velmi chaotické. To je nebezpečná situace. Každý zvolený hlavní server, bez ohledu na to, po jakou dobu zastával hlavní roli, může mít své vlastní sady změn, které nebyly nikdy replikovány na žádný server. Takže můžete skončit s nekonzistencí mezi všemi zvolenými mistry.
-
Nepřebírejte na nekonzistentní slave
Při výběru slave, který má být povýšen jako master, zajistíme, že slave nebude mít nesrovnalosti, např. chybné transakce, protože to může velmi dobře narušit replikaci.
-
Pište pouze hlavnímu serveru
Replikace přechází z masteru na slave(y). Zápis přímo do slave by vytvořil rozdílnou datovou sadu, a to může být potenciální zdroj problémů. Nastavili jsme slave na read_only a super_read_only v novějších verzích MySQL nebo MariaDB. Doporučujeme také použití nástroje pro vyrovnávání zatížení, např. ProxySQL nebo MaxScale, k ochraně aplikační vrstvy před základní databázovou topologií a jakýmikoli jejími změnami. Nástroj pro vyrovnávání zatížení také vynucuje zápisy na aktuální master.
-
Neznovu automaticky neobnovovat neúspěšnou předlohu
Pokud selhal master a byl zvolen nový master, ClusterControl se nepokusí obnovit neúspěšný master. Proč? Tento server může mít data, která ještě nebyla replikována, a správce bude muset provést nějaké šetření ohledně selhání. Dobře, stále můžete nakonfigurovat ClusterControl tak, aby vymazal data na neúspěšném hlavním serveru a nechal jej připojit jako slave k novému hlavnímu serveru – pokud jste v pořádku se ztrátou některých dat. Ale ve výchozím nastavení nechá ClusterControl neúspěšný master být, dokud se na něj někdo nepodívá a nerozhodne se jej znovu zavést do topologie.
Měli byste tedy automatizovat převzetí služeb při selhání? Záleží na tom, jak jste replikaci nakonfigurovali. Nastavení kruhové replikace s více zapisovatelnými mastery nebo komplexními topologiemi pravděpodobně nejsou vhodnými kandidáty pro automatické převzetí služeb při selhání. Při návrhu řešení replikace bychom se drželi výše uvedených zásad.
Na PostgreSQL
Pokud jde o replikaci streamování PostgreSQL, ClusterControl používá podobné principy k automatizaci převzetí služeb při selhání. Pro PostgreSQL podporuje ClusterControl jak asynchronní, tak synchronní modely replikace mezi master a slave. V obou případech a v případě poruchy je jako nový master zvolen podřízený s nejaktuálnějšími daty. Selhali hlavní servery nejsou automaticky obnoveny/opraveny, aby se mohli znovu připojit k nastavení replikace.
Bylo přijato několik ochranných opatření, aby se zajistilo, že neúspěšný master je dole a zůstane dole, např. odebere se z nastavení vyvažování zátěže v proxy a je zabit, pokud např. uživatel by jej restartoval ručně. Tam je trochu náročnější detekovat rozdělení sítě mezi ClusterControl a master, protože slave neposkytují žádné informace o stavu masteru, ze kterého se replikují. Proxy před nastavením databáze je tedy důležitý, protože může poskytnout další cestu k hlavnímu serveru.
Na MongoDB
Replikace MongoDB v rámci replikační sady prostřednictvím oplogu je velmi podobná replikaci binlogu, tak jak to, že MongoDB automaticky obnoví neúspěšný master? Problém stále existuje a MongoDB to řeší vrácením všech změn, které nebyly replikovány do podřízených zařízení v době selhání. Tato data jsou odstraněna a umístěna do složky „rollback“, takže je na správci, aby je obnovil.
Chcete-li se dozvědět více, podívejte se na ClusterControl; a neváhejte níže komentovat nebo pokládat otázky.