Jak byste chtěli sloučit „top“ proces pro všech vašich 5 databázových uzlů a seřadit podle využití procesoru pomocí jediného příkazu? Ano, čtete správně! Co takhle interaktivní zobrazení grafů v terminálovém rozhraní? Klienta CLI pro ClusterControl s názvem s9s jsme představili asi před rokem a je skvělým doplňkem webového rozhraní. Je to také open source..
V tomto příspěvku na blogu vám ukážeme, jak můžete monitorovat své databáze pomocí terminálu a rozhraní s9s CLI.
Úvod do s9s, The ClusterControl CLI
ClusterControl CLI (nebo s9s nebo s9s CLI) je projekt s otevřeným zdrojovým kódem a volitelný balíček představený s ClusterControl verze 1.4.1. Jedná se o nástroj příkazového řádku pro interakci, řízení a správu vaší databázové infrastruktury pomocí ClusterControl. Projekt příkazového řádku s9s je open source a lze jej nalézt na GitHubu.
Počínaje verzí 1.4.1 instalační skript automaticky nainstaluje balíček (s9s-tools) do uzlu ClusterControl.
Některé předpoklady. Abyste mohli spouštět s9s-tools CLI, musí platit následující:
- Spuštěný ClusterControl Controller (cmon).
- klient s9, nainstalujte jej jako samostatný balíček.
- Port 9501 musí být dostupný pro klienta s9.
Instalace s9s CLI je přímočará, pokud jej nainstalujete do samotného hostitele ClusterControl Controller:$ rm
$ rm -Rf ~/.s9s
$ wget https://repo.severalnines.com/s9s-tools/install-s9s-tools.sh
$ ./install-s9s-tools.shNástroje s9s-tools můžete nainstalovat mimo server ClusterControl (vašeho notebooku pracovní stanice nebo hostitele bastionu), pokud je rozhraní ClusterControl Controller RPC (TLS) vystaveno veřejné síti (výchozí 127.0.0.1:9501). Další podrobnosti o tom, jak to nakonfigurovat, najdete na stránce dokumentace.
Chcete-li ověřit, zda se můžete správně připojit k rozhraní ClusterControl RPC, měli byste při spuštění následujícího příkazu obdržet odpověď OK:
$ s9s cluster --ping
PING OK 2.000 msJako vedlejší poznámku se také podívejte na omezení při používání tohoto nástroje.
Příklad nasazení
Náš příklad nasazení se skládá z 8 uzlů ve 3 clusterech:
- PostgreSQL Streaming Replication – 1 hlavní, 2 podřízené
- Replikace MySQL – 1 hlavní, 1 podřízený
- Sada replik MongoDB – 1 primární, 2 sekundární uzly
Všechny databázové clustery byly nasazeny pomocí ClusterControl pomocí průvodce nasazením "Deploy Database Cluster" a z pohledu uživatelského rozhraní bychom na řídicím panelu clusteru viděli toto:
Monitorování clusteru
Začneme výpisem shluků:
$ s9s cluster --list --long
ID STATE TYPE OWNER GROUP NAME COMMENT
23 STARTED postgresql_single system admins PostgreSQL 10 All nodes are operational.
24 STARTED replication system admins Oracle 5.7 Replication All nodes are operational.
25 STARTED mongodb system admins MongoDB 3.6 All nodes are operational.Vidíme stejné shluky jako uživatelské rozhraní. Více podrobností o konkrétním clusteru můžeme získat pomocí parametru --stat. Tímto způsobem lze také monitorovat více klastrů a uzlů, možnosti příkazového řádku mohou dokonce používat zástupné znaky v názvech uzlů a klastrů:
$ s9s cluster --stat *Replication
Oracle 5.7 Replication Name: Oracle 5.7 Replication Owner: system/admins
ID: 24 State: STARTED
Type: REPLICATION Vendor: oracle 5.7
Status: All nodes are operational.
Alarms: 0 crit 1 warn
Jobs: 0 abort 0 defnd 0 dequd 0 faild 7 finsd 0 runng
Config: '/etc/cmon.d/cmon_24.cnf'
LogFile: '/var/log/cmon_24.log'
HOSTNAME CPU MEMORY SWAP DISK NICs
10.0.0.104 1 6% 992M 120M 0B 0B 19G 13G 10K/s 54K/s
10.0.0.168 1 6% 992M 116M 0B 0B 19G 13G 11K/s 66K/s
10.0.0.156 2 39% 3.6G 2.4G 0B 0B 19G 3.3G 338K/s 79K/sVýše uvedený výstup poskytuje shrnutí naší replikace MySQL spolu se stavem clusteru, stavem, dodavatelem, konfiguračním souborem a tak dále. Níže můžete vidět seznam uzlů, které spadají pod toto ID clusteru, se souhrnným pohledem na systémové prostředky pro každého hostitele, jako je počet CPU, celková paměť, využití paměti, odkládací disk a síťová rozhraní. Všechny zobrazené informace jsou získávány z databáze CMON, nikoli přímo ze skutečných uzlů.
Můžete také získat souhrnný pohled na všechny databáze ve všech clusterech:
$ s9s cluster --list-databases --long
SIZE #TBL #ROWS OWNER GROUP CLUSTER DATABASE
7,340,032 0 0 system admins PostgreSQL 10 postgres
7,340,032 0 0 system admins PostgreSQL 10 template1
7,340,032 0 0 system admins PostgreSQL 10 template0
765,460,480 24 2,399,611 system admins PostgreSQL 10 sbtest
0 101 - system admins Oracle 5.7 Replication sys
Total: 5 databases, 789,577,728, 125 tables.Poslední řádek shrnuje, že máme celkem 5 databází se 125 tabulkami, z nichž 4 jsou v našem clusteru PostgreSQL.
Úplný příklad použití možností příkazového řádku clusteru s9s naleznete v dokumentaci clusteru s9s.
Monitorování uzlů
Pro monitorování uzlů má s9s CLI podobné funkce s možností clusteru. Chcete-li získat souhrnný pohled na všechny uzly, můžete jednoduše:
$ s9s node --list --long
STAT VERSION CID CLUSTER HOST PORT COMMENT
coC- 1.6.2.2662 23 PostgreSQL 10 10.0.0.156 9500 Up and running
poM- 10.4 23 PostgreSQL 10 10.0.0.44 5432 Up and running
poS- 10.4 23 PostgreSQL 10 10.0.0.58 5432 Up and running
poS- 10.4 23 PostgreSQL 10 10.0.0.60 5432 Up and running
soS- 5.7.23-log 24 Oracle 5.7 Replication 10.0.0.104 3306 Up and running.
coC- 1.6.2.2662 24 Oracle 5.7 Replication 10.0.0.156 9500 Up and running
soM- 5.7.23-log 24 Oracle 5.7 Replication 10.0.0.168 3306 Up and running.
mo-- 3.2.20 25 MongoDB 3.6 10.0.0.125 27017 Up and Running
mo-- 3.2.20 25 MongoDB 3.6 10.0.0.131 27017 Up and Running
coC- 1.6.2.2662 25 MongoDB 3.6 10.0.0.156 9500 Up and running
mo-- 3.2.20 25 MongoDB 3.6 10.0.0.35 27017 Up and Running
Total: 11Sloupec nejvíce vlevo určuje typ uzlu. Pro toto nasazení "c" představuje ClusterControl Controller, "p" pro PostgreSQL, "m" pro MongoDB, "e" pro Memcached a s pro generické MySQL uzly. Další je stav hostitele - "o" pro online, " l" pro off-line, "f" pro neúspěšné uzly a tak dále. Další je role uzlu v clusteru. Může to být M pro master, S pro slave, C pro kontrolér a - pro vše ostatní. Zbývající sloupce jsou docela samozřejmé.
Celý seznam můžete získat pohledem na manuálovou stránku této komponenty:
$ man s9s-nodeOdtud můžeme přejít na podrobnější statistiky pro všechny uzly s příznakem --stats:
$ s9s node --stat --cluster-id=24
10.0.0.104:3306
Name: 10.0.0.104 Cluster: Oracle 5.7 Replication (24)
IP: 10.0.0.104 Port: 3306
Alias: - Owner: system/admins
Class: CmonMySqlHost Type: mysql
Status: CmonHostOnline Role: slave
OS: centos 7.0.1406 core Access: read-only
VM ID: -
Version: 5.7.23-log
Message: Up and running.
LastSeen: Just now SSH: 0 fail(s)
Connect: y Maintenance: n Managed: n Recovery: n Skip DNS: y SuperReadOnly: n
Pid: 16592 Uptime: 01:44:38
Config: '/etc/my.cnf'
LogFile: '/var/log/mysql/mysqld.log'
PidFile: '/var/lib/mysql/mysql.pid'
DataDir: '/var/lib/mysql/'
10.0.0.168:3306
Name: 10.0.0.168 Cluster: Oracle 5.7 Replication (24)
IP: 10.0.0.168 Port: 3306
Alias: - Owner: system/admins
Class: CmonMySqlHost Type: mysql
Status: CmonHostOnline Role: master
OS: centos 7.0.1406 core Access: read-write
VM ID: -
Version: 5.7.23-log
Message: Up and running.
Slaves: 10.0.0.104:3306
LastSeen: Just now SSH: 0 fail(s)
Connect: n Maintenance: n Managed: n Recovery: n Skip DNS: y SuperReadOnly: n
Pid: 975 Uptime: 01:52:53
Config: '/etc/my.cnf'
LogFile: '/var/log/mysql/mysqld.log'
PidFile: '/var/lib/mysql/mysql.pid'
DataDir: '/var/lib/mysql/'
10.0.0.156:9500
Name: 10.0.0.156 Cluster: Oracle 5.7 Replication (24)
IP: 10.0.0.156 Port: 9500
Alias: - Owner: system/admins
Class: CmonHost Type: controller
Status: CmonHostOnline Role: controller
OS: centos 7.0.1406 core Access: read-write
VM ID: -
Version: 1.6.2.2662
Message: Up and running
LastSeen: 28 seconds ago SSH: 0 fail(s)
Connect: n Maintenance: n Managed: n Recovery: n Skip DNS: n SuperReadOnly: n
Pid: 12746 Uptime: 01:10:05
Config: ''
LogFile: '/var/log/cmon_24.log'
PidFile: ''
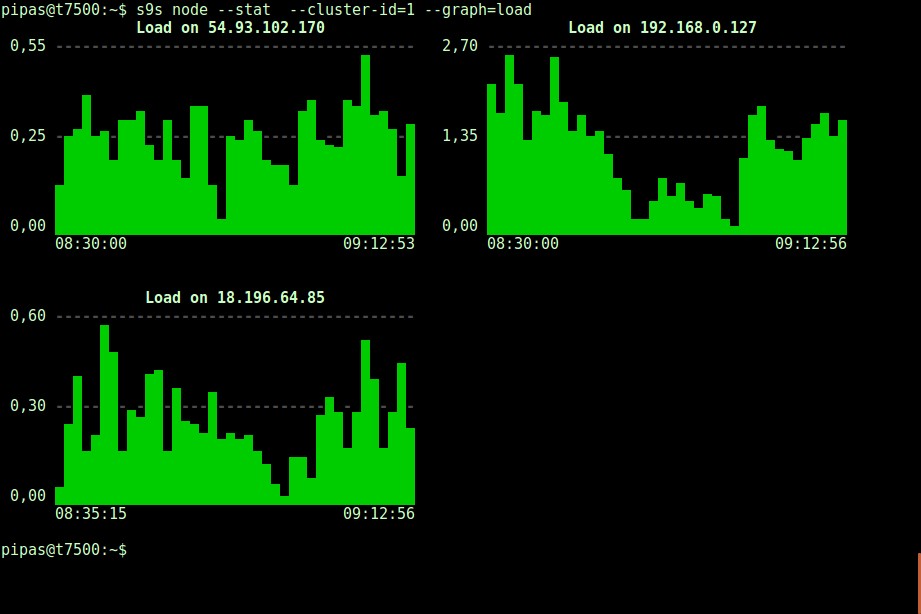
DataDir: ''Tisk grafů pomocí klienta s9s může být také velmi informativní. To představuje data, která správce shromáždil, v různých grafech. Tento nástroj podporuje téměř 30 grafů, jak je zde uvedeno, a s9s-node je všechny vyjmenovává. Následující ukazuje histogram zatížení serveru všech uzlů pro cluster ID 1, jak je shromáždil CMON přímo z vašeho terminálu:
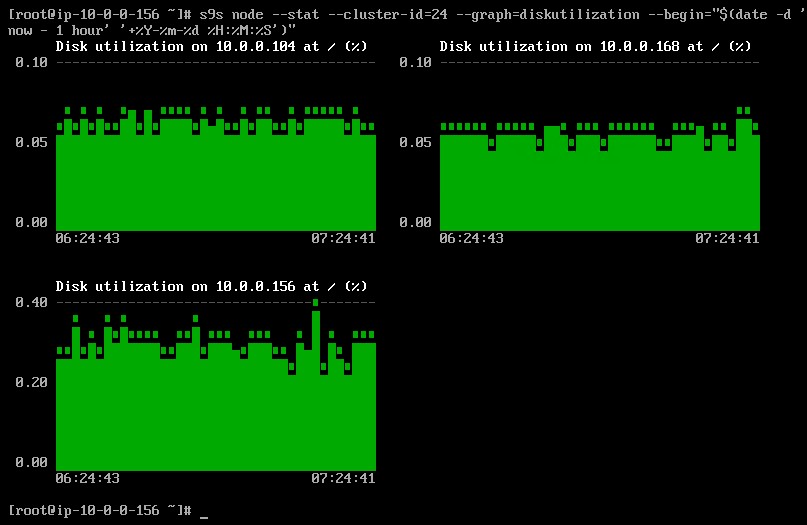
Je možné nastavit datum a čas začátku a konce. Lze zobrazit krátká období (např. poslední hodinu) nebo delší období (např. týden nebo měsíc). Následuje příklad zobrazení využití disku za poslední hodinu:
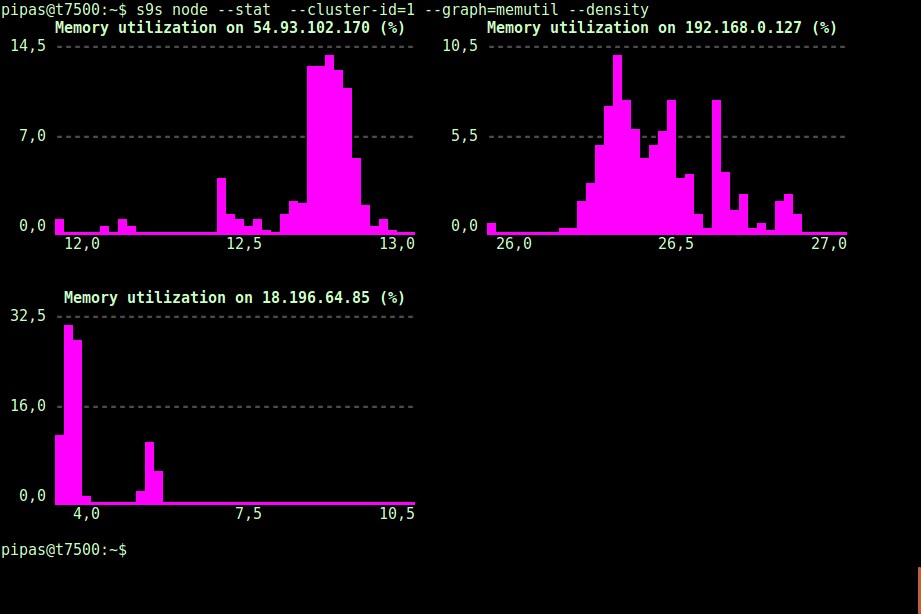
Pomocí volby --density lze pro každý graf vytisknout jiný pohled. Tento graf hustoty neukazuje časovou řadu, ale jak často byly dané hodnoty vidět (osa X představuje hodnotu hustoty):
Pokud terminál nepodporuje znaky Unicode, možnost --only-ascii je může vypnout:
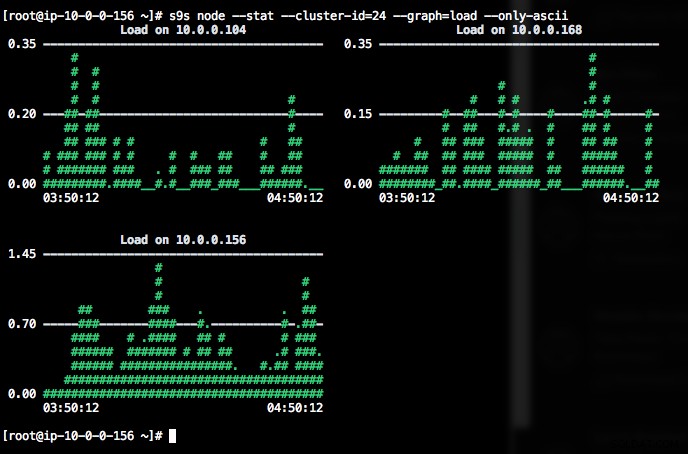
Grafy mají barvy, kde jsou například nebezpečně vysoké hodnoty zobrazeny červeně. Seznam uzlů lze filtrovat pomocí volby --nodes, kde můžete zadat názvy uzlů nebo použít zástupné znaky, pokud je to vhodné.
Monitorování procesu
Další skvělá věc na s9s CLI je, že poskytuje seznam procesů celého clusteru – „top“ pro všechny uzly, všechny procesy sloučené do jednoho. Následující příkaz spustí příkaz „top“ na všech uzlech databáze pro cluster ID 24, seřazený podle největší spotřeby CPU a průběžně aktualizován:
$ s9s process --top --cluster-id=24
Oracle 5.7 Replication - 04:39:17 All nodes are operational.
3 hosts, 4 cores, 10.6 us, 4.2 sy, 84.6 id, 0.1 wa, 0.3 st,
GiB Mem : 5.5 total, 1.7 free, 2.6 used, 0.1 buffers, 1.1 cached
GiB Swap: 0 total, 0 used, 0 free,
PID USER HOST PR VIRT RES S %CPU %MEM COMMAND
12746 root 10.0.0.156 20 1359348 58976 S 25.25 1.56 cmon
1587 apache 10.0.0.156 20 462572 21632 S 1.38 0.57 httpd
390 root 10.0.0.156 20 4356 584 S 1.32 0.02 rngd
975 mysql 10.0.0.168 20 1144260 71936 S 1.11 7.08 mysqld
16592 mysql 10.0.0.104 20 1144808 75976 S 1.11 7.48 mysqld
22983 root 10.0.0.104 20 127368 5308 S 0.92 0.52 sshd
22548 root 10.0.0.168 20 127368 5304 S 0.83 0.52 sshd
1632 mysql 10.0.0.156 20 3578232 1803336 S 0.50 47.65 mysqld
470 proxysql 10.0.0.156 20 167956 35300 S 0.44 0.93 proxysql
338 root 10.0.0.104 20 4304 600 S 0.37 0.06 rngd
351 root 10.0.0.168 20 4304 600 R 0.28 0.06 rngd
24 root 10.0.0.156 20 0 0 S 0.19 0.00 rcu_sched
785 root 10.0.0.156 20 454112 11092 S 0.13 0.29 httpd
26 root 10.0.0.156 20 0 0 S 0.13 0.00 rcuos/1
25 root 10.0.0.156 20 0 0 S 0.13 0.00 rcuos/0
22498 root 10.0.0.168 20 127368 5200 S 0.09 0.51 sshd
14538 root 10.0.0.104 20 0 0 S 0.09 0.00 kworker/0:1
22933 root 10.0.0.104 20 127368 5200 S 0.09 0.51 sshd
28295 root 10.0.0.156 20 127452 5016 S 0.06 0.13 sshd
2238 root 10.0.0.156 20 197520 10444 S 0.06 0.28 vc-agent-007
419 root 10.0.0.156 20 34764 1660 S 0.06 0.04 systemd-logind
1 root 10.0.0.156 20 47628 3560 S 0.06 0.09 systemd
27992 proxysql 10.0.0.156 20 11688 872 S 0.00 0.02 proxysql_galera
28036 proxysql 10.0.0.156 20 11688 876 S 0.00 0.02 proxysql_galeraExistuje také příznak --list, který vrací podobný výsledek bez průběžné aktualizace (podobně jako příkaz "ps"):
$ s9s process --list --cluster-id=25Sledování práce
Úlohy jsou úlohy prováděné kontrolérem na pozadí, takže klientská aplikace nemusí čekat na dokončení celé úlohy. ClusterControl provádí úlohy správy přiřazením ID pro každou úlohu a umožňuje internímu plánovači rozhodnout, zda lze paralelně spustit dvě nebo více úloh. Například lze současně provést více nasazení clusteru, stejně jako další dlouhodobé operace, jako je zálohování a automatické nahrávání záloh do cloudového úložiště.
V jakékoli operaci správy by bylo užitečné, kdybychom mohli sledovat průběh a stav konkrétní úlohy, jako je například škálování nového slave pro naši replikaci MySQL. Následující příkaz přidá nového slave, 10.0.0.77, aby škáloval naši replikaci MySQL:
$ s9s cluster --add-node --nodes="10.0.0.77" --cluster-id=24
Job with ID 66992 registered.Poté můžeme sledovat jobID 66992 pomocí možnosti úlohy:
$ s9s job --log --job-id=66992
addNode: Verifying job parameters.
10.0.0.77:3306: Adding host to cluster.
10.0.0.77:3306: Testing SSH to host.
10.0.0.77:3306: Installing node.
10.0.0.77:3306: Setup new node (installSoftware = true).
10.0.0.77:3306: Setting SELinux in permissive mode.
10.0.0.77:3306: Disabling firewall.
10.0.0.77:3306: Setting vm.swappiness = 1
10.0.0.77:3306: Installing software.
10.0.0.77:3306: Setting up repositories.
10.0.0.77:3306: Installing helper packages.
10.0.0.77: Upgrading nss.
10.0.0.77: Upgrading ca-certificates.
10.0.0.77: Installing socat.
...
10.0.0.77: Installing pigz.
10.0.0.77: Installing bzip2.
10.0.0.77: Installing iproute2.
10.0.0.77: Installing tar.
10.0.0.77: Installing openssl.
10.0.0.77: Upgrading openssl openssl-libs.
10.0.0.77: Finished with helper packages.
10.0.0.77:3306: Verifying helper packages (checking if socat is installed successfully).
10.0.0.77:3306: Uninstalling existing MySQL packages.
10.0.0.77:3306: Installing replication software, vendor oracle, version 5.7.
10.0.0.77:3306: Installing software.
...Nebo můžeme použít příznak --wait a získat spinner s ukazatelem průběhu:
$ s9s job --wait --job-id=66992
Add Node to Cluster
- Job 66992 RUNNING [ █] ---% Add New Node to ClusterTo je pro dnešní doplněk monitorování vše. Doufáme, že CLI vyzkoušíte a získáte z něj hodnotu. Šťastné shlukování