Zóny MongoDB
Abychom porozuměli zónám MongoDB, musíme nejprve porozumět tomu, co je zóna:skupina útržků založená na konkrétní sadě značek.
Zóny MongoDB pomáhají při distribuci kousků na základě značek přes úlomky. Veškerá práce (čtení a zápis) související s dokumenty v zóně se provádí na fragmentech odpovídajících této zóně.
Mohou existovat různé scénáře, kdy se mohou štěpené clustery (založené na zónách) ukázat jako velmi užitečné. Řekněme:
- Aplikace, která je geograficky distribuována, může vyžadovat rozhraní i úložiště dat
- Aplikace má n-vrstvou architekturu, takže některé záznamy jsou načteny z hardwaru vyšší úrovně (nízká latence), zatímco jiné mohou být načteny z hardwaru s nízkou úrovní (vyvolávající vysokou latenci)
Výhody používání zón MongoDB
S pomocí MongoDB Zones mohou správci databází vytvářet vrstvená řešení úložiště, která podporují životní cyklus dat, s často používanými daty uloženými v paměti, méně používanými daty uloženými na serveru a archivovanými daty ve správnou dobu offline.
Jak nastavit zóny
Ve sdílených klastrech můžete vytvořit zóny, které představují skupinu útržků, a přiřadit k této zóně jeden nebo více rozsahů hodnot útržků. MongoDB směruje všechna čtení a všechny zápisy, které přicházejí do rozsahu zón, pouze do těch fragmentů uvnitř zóny. Každou zónu můžete přidružit k jednomu nebo více útržkům v clusteru a útržek se může přidružit k libovolnému počtu zón.
Některé z nejběžnějších vzorů nasazení, kde lze zóny použít, jsou následující:
- Izolujte konkrétní podmnožinu dat na konkrétní sadě fragmentů.
- Zajištěním, že nejrelevantnější data budou uložena na fragmentech, které jsou geograficky nejblíže aplikačním serverům.
- Směrujte data do datových fragmentů na základě výkonu hardwaru shardu.
Následující obrázek ilustruje střepový shluk se třemi střepy a dvěma zónami. Zóna A představuje rozsah s dolní hranicí 0 a horní hranicí 10. Zóna B zobrazuje rozsah s dolní hranicí 10 a horní hranicí 20. ČERVENÉ a MODRÉ úlomky mají zónu A. Shard BLUE má také zónu B. Shard GREEN s ním nejsou spojeny žádné zóny. Cluster je v ustáleném stavu a žádné části nenarušují žádnou ze zón
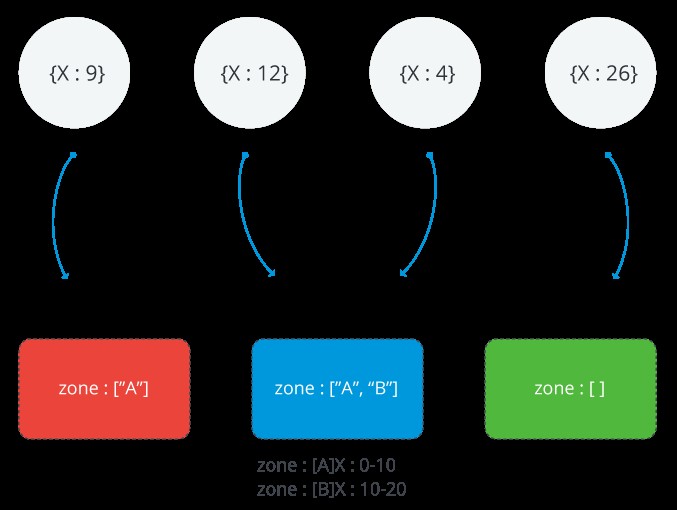
Rozsah zóny MongoDB
Každá zóna pokrývá jeden nebo více rozsahů hodnot hardwarových klíčů. Každý rozsah, který zóna pokrývá, vždy zahrnuje svou spodní hranici a bez její horní hranice.
PAMATUJTE: Zóny nemohou sdílet rozsahy a nemohou mít překrývající se rozsahy.
Přidání úlomků do zóny
Metoda sh.addShardTag() se používá k přidání zón do fragmentu. Jeden úlomek může mít více zón a více útržků může mít také stejnou zónu. Následující příklad přidá zónu A k jednomu fragmentu.
sh.addShardTag("shard0000", "A")Odebrání úlomků do zóny
K odstranění zóny z datového fragmentu se používá metoda sh.removeShardTag(). Následující příklad odstraní zónu A z datového fragmentu.
sh.removeShardTag("shard0002", "A")Tipy pro zóny MongoDB
Udržujte dokumenty jednoduché
MongoDB je databáze bez schémat. To znamená, že ve výchozím nastavení neexistuje žádné předdefinované schéma. V novějších verzích můžeme přidat předdefinované schéma, ale není to povinné. Nepodceňujte potíže, ke kterým dochází při práci s dokumenty a poli, protože může být opravdu obtížné analyzovat vaše data v procesu na straně aplikace/ETL. Kromě toho mohou pole poškodit výkon replikace:při každé změně v poli se replikují všechny hodnoty pole.
Nejlepší hardware není vždy tou nejlepší volbou
Použití dobrého hardwaru rozhodně pomáhá k dobrému výkonu. Ale co by se mohlo stát v prostředí, kdy jeden příklad velkého stroje zemře? Odpověď je ‘failover’.
Mít více malých počítačů (místo jednoho nebo dvou) v distribuovaném prostředí může zajistit, že výpadky ovlivní pouze několik částí datového fragmentu s malým nebo žádným vnímáním aplikací. Ale zároveň více strojů znamená vysokou pravděpodobnost selhání. Zvažte tento kompromis při navrhování vašeho prostředí. Správná volba ovlivňuje výkon.
Pracovní sada
Jak velká je pracovní sada? Aplikace obvykle nevyužívá všechna data. Některá data se aktualizují často, zatímco jiná ne. Vejde se váš pracovní datový soubor do RAM? Optimálního výkonu dosáhnete, když je veškerá pracovní datová sada v paměti RAM.