Údržba je něco, čemu se operační tým nevyhne. Servery musí držet krok s nejnovějším softwarem, hardwarem a technologií, aby zajistily, že systémy budou stabilní a běží s co nejnižším rizikem, a zároveň využívají novější funkce ke zlepšení celkového výkonu.
Nepochybně existuje dlouhý seznam úkolů údržby, které musí provádět správci systému, zejména pokud jde o kritické systémy. Některé z úkolů je třeba provádět v pravidelných intervalech, například denně, týdně, měsíčně a ročně. Některé je třeba udělat hned, naléhavě. Nicméně jakákoli operace údržby by neměla vést k dalšímu většímu problému a s každou údržbou je třeba zacházet s mimořádnou opatrností, aby nedošlo k přerušení podnikání.
Při probíhající údržbě je běžné získat pochybný stav a falešné poplachy. To se očekává, protože během období údržby nebude server fungovat tak, jak by měl, dokud nebude dokončena úloha údržby. ClusterControl, komplexní platforma pro správu a monitorování vašich databází s otevřeným zdrojovým kódem, lze nakonfigurovat tak, aby těmto okolnostem porozuměla, a zjednodušila tak vaše rutiny údržby, aniž byste museli obětovat funkce monitorování a automatizace, které nabízí.
Režim údržby
ClusterControl zavedl režim údržby ve verzi 1.4.0, kde můžete jednotlivý uzel uvést do údržby, což zabrání ClusterControl spouštět poplachy a odesílat upozornění po stanovenou dobu. Režim údržby lze konfigurovat z uživatelského rozhraní ClusterControl a také pomocí nástroje ClusterControl CLI zvaného „s9s“. Z uživatelského rozhraní stačí přejít na Uzly -> vybrat uzel -> Akce uzlů -> Režim plánování údržby :
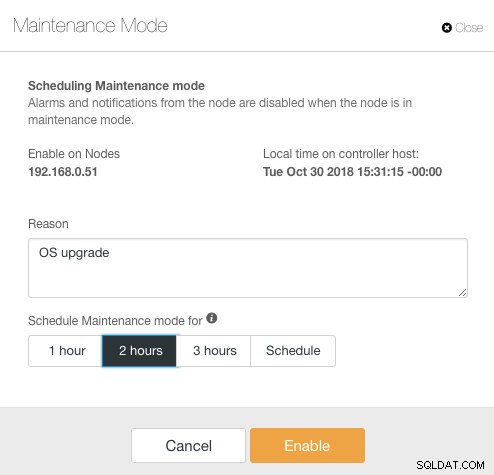
Zde lze nastavit periodu údržby na předem definovanou dobu nebo ji podle toho naplánovat. Můžete si také zapsat důvod naplánování upgradu, což je užitečné pro účely auditu. Když je aktivní režim údržby, měli byste vidět následující upozornění:
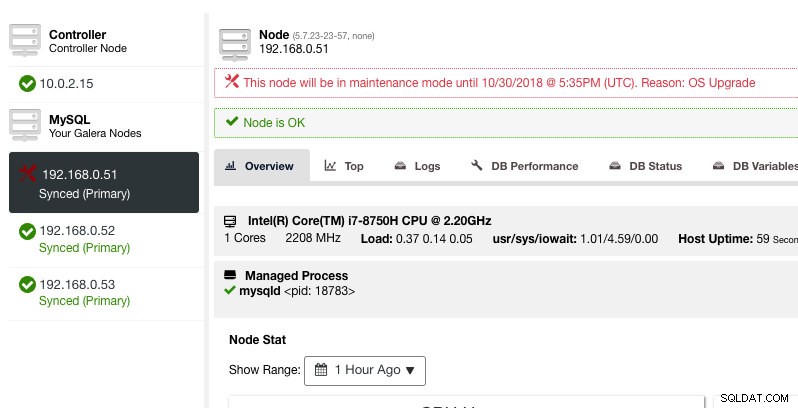
ClusterControl nedegraduje uzel, takže stav uzlu zůstane tak, jak je, pokud neprovedete žádnou akci, která stav změní. Alarmy a upozornění pro tento uzel budou znovu aktivovány, jakmile skončí období údržby nebo je operátor výslovně deaktivuje přechodem na Akce uzlů -> Deaktivovat režim údržby .
Vezměte na vědomí, že pokud je povolena automatická obnova uzlu, ClusterControl vždy obnoví uzel bez ohledu na stav režimu údržby. Nezapomeňte deaktivovat obnovu uzlu, aby ClusterControl nezasahoval do vašich úkolů údržby, to lze provést z horního souhrnného panelu.
Režim údržby lze také konfigurovat pomocí ClusterControl CLI nebo „s9s“. Můžete použít příkaz "s9s maintenance" k vypsání a manipulaci s obdobími údržby. Následující příkazový řádek naplánuje zítra jednohodinové okno údržby pro uzel 192.168.1.121:
$ s9s maintenance --create \
--nodes=192.168.1.121 \
--start="$(date -d 'now + 1 day' '+%Y-%m-%d %H:%M:%S')" \
--end="$(date -d 'now + 1 day + 1 hour' '+%Y-%m-%d %H:%M:%S')" \
--reason="Upgrading software."Další podrobnosti a příklady naleznete v dokumentaci údržby s9s.
Režim údržby v celém clusteru
V době psaní tohoto článku musí být konfigurace režimu údržby konfigurována pro každý spravovaný uzel. Pro údržbu v celém clusteru je nutné opakovat proces plánování pro každý spravovaný uzel clusteru. To může být nepraktické, pokud máte ve svém clusteru velký počet uzlů nebo pokud je interval údržby mezi dvěma úkoly velmi krátký.
Naštěstí lze ClusterControl CLI (a.k.a s9s) použít jako řešení k překonání tohoto omezení. K vypsání a manipulaci se spravovanými uzly v clusteru můžete použít "uzly s9s". Tento seznam lze iterovat a naplánovat režim údržby v rámci celého clusteru v jeden daný čas pomocí příkazu "s9s maintenance".
Podívejme se na příklad, abychom to lépe pochopili. Zvažte následující tříuzlový Percona XtraDB Cluster, který máme:
$ s9s nodes --list --cluster-name='PXC57' --long
STAT VERSION CID CLUSTER HOST PORT COMMENT
coC- 1.7.0.2832 1 PXC57 10.0.2.15 9500 Up and running.
go-M 5.7.23 1 PXC57 192.168.0.51 3306 Up and running.
go-- 5.7.23 1 PXC57 192.168.0.52 3306 Up and running.
go-- 5.7.23 1 PXC57 192.168.0.53 3306 Up and running.
Total: 4Cluster má celkem 4 uzly – 3 databázové uzly s jedním uzlem ClusterControl. První sloupec STAT ukazuje roli a stav uzlu. První znak je role uzlu – „c“ znamená kontrolér a „g“ znamená uzel databáze Galera. Předpokládejme, že chceme naplánovat údržbu pouze databázových uzlů, můžeme odfiltrovat výstup, abychom získali název hostitele nebo IP adresu, kde má hlášený STAT na začátku „g“:
$ s9s nodes --list --cluster-name='PXC57' --long --batch | grep ^g | awk {'print $5'}
192.168.0.51
192.168.0.52
192.168.0.53S jednoduchou iterací pak můžeme naplánovat okno údržby celého clusteru pro každý uzel v clusteru. Následující příkaz iteruje vytváření údržby na základě všech IP adres nalezených v clusteru pomocí cyklu for, kde plánujeme zahájit operaci údržby zítra ve stejnou dobu a skončit o hodinu později:
$ for host in $(s9s nodes --list --cluster-id='PXC57' --long --batch | grep ^g | awk {'print $5'}); do \
s9s maintenance \
--create \
--nodes=$host \
--start="$(date -d 'now + 1 day' '+%Y-%m-%d %H:%M:%S')" \
--end="$(date -d 'now + 1 day + 1 hour' '+%Y-%m-%d %H:%M:%S')" \
--reason="OS upgrade"; done
f92c5370-004d-4735-bba0-8c1bd26b9b98
9ff7dd8c-f2cb-4446-b14b-a5c2b915b853
103d715d-d0bc-4402-9326-1a053bc5d36bMěli byste vidět výtisk 3 UUID, jedinečného řetězce, který identifikuje každé období údržby. Poté můžeme ověřit pomocí následujícího příkazu:
$ s9s maintenance --list --long
ST UUID OWNER GROUP START END HOST/CLUSTER REASON
-h f92c537 admin admins 2018-10-31 16:02:00 2018-10-31 17:02:00 192.168.0.51 OS upgrade
-h 9ff7dd8 admin admins 2018-10-31 16:02:00 2018-10-31 17:02:00 192.168.0.52 OS upgrade
-h 103d715 admin admins 2018-10-31 16:02:00 2018-10-31 17:02:00 192.168.0.53 OS upgrade
Total: 3Z výše uvedeného výstupu jsme získali seznam plánovaných časů údržby pro každý databázový uzel. Během naplánovaného času nebude ClusterControl vyvolávat alarmy ani odesílat upozornění, pokud zjistí nesrovnalosti do clusteru.
Iterace režimu údržby
Některé rutiny údržby je třeba provádět v pravidelných intervalech, např. zálohování, úklid a úklid. Během doby údržby bychom očekávali, že se server bude chovat jinak. Jakákoli porucha služby, dočasná nedostupnost nebo vysoká zátěž by však našemu monitorovacímu systému jistě způsobila zmatek. Pro časté a krátké intervaly údržby se to může ukázat jako velmi nepříjemné a přeskakování falešných poplachů vám může zajistit lepší spánek během noci.
Povolení režimu údržby však také může vystavit server většímu riziku, protože přísné sledování je po určitou dobu ignorováno. Proto je pravděpodobně dobré porozumět povaze operace údržby, kterou bychom chtěli provést, než povolíme režim údržby. Následující kontrolní seznam by nám měl pomoci určit naše zásady režimu údržby:
- Dotčené uzly – Které uzly se účastní údržby?
- Důsledky – Co se stane s uzlem, když probíhá údržba? Bude nepřístupný, vysoce nabitý nebo restartovaný?
- Trvání – Jak dlouho trvá dokončení operace údržby?
- Frekvence – Jak často by měla probíhat údržba?
Pojďme to dát do případu použití. Uvažujme, že máme tříuzlový cluster Percona XtraDB s uzlem ClusterControl. Předpokládejme, že všechny naše servery běží na virtuálních počítačích a zásady zálohování virtuálních počítačů vyžadují, aby byly všechny virtuální počítače zálohovány každý den od 1:00, jeden uzel po druhém. Během této operace zálohování bude uzel zablokován maximálně na 10 minut a uzel, který spravuje a monitoruje ClusterControl, bude nepřístupný, dokud nebude zálohování dokončeno. Z pohledu Galera Cluster tato operace nesníží celý cluster, protože cluster zůstává v kvoru a primární komponenta není ovlivněna.
Na základě povahy úlohy údržby ji můžeme shrnout následovně:
- Dotčené uzly – všechny uzly pro cluster ID 1 (3 uzly databáze a 1 uzel ClusterControl).
- Následek – Zálohovaný virtuální počítač bude až do dokončení nepřístupný.
- Trvání – Dokončení každé operace zálohování virtuálního počítače trvá přibližně 5 až 10 minut.
- Frekvence – Spouštění zálohy virtuálního počítače je naplánováno denně, počínaje 1:00 v prvním uzlu.
Poté můžeme vypracovat plán provádění, který naplánuje režim údržby:
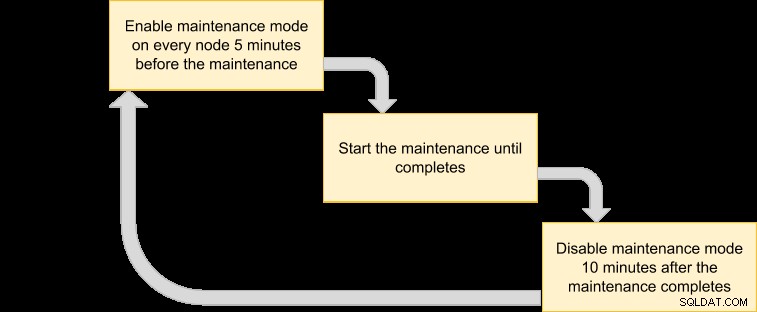
Protože chceme, aby všechny uzly v clusteru byly zálohovány správcem virtuálních počítačů, jednoduše vypište uzly pro odpovídající ID clusteru:
$ s9s nodes --list --cluster-id=1
192.168.0.51 10.0.2.15 192.168.0.52 192.168.0.53Výše uvedený výstup lze použít k plánování údržby v celém clusteru. Pokud například spustíte následující příkaz, ClusterControl od nynějška do následujících 50 minut aktivuje režim údržby pro všechny uzly s ID clusteru 1:
$ for host in $(s9s nodes --list --cluster-id=1); do \
s9s maintenance --create \
--nodes=$host \
--start="$(date -d 'now' '+%Y-%m-%d %H:%M:%S')" \
--end="$(date -d 'now + 50 minutes' '+%Y-%m-%d %H:%M:%S')" \
--reason="Backup VM"; donePomocí výše uvedeného příkazu jej můžeme převést na spouštěcí soubor vložením do skriptu. Vytvořte soubor:
$ vim /usr/local/bin/enable_maintenance_modeA přidejte následující řádky:
for host in $(s9s nodes --list --cluster-id=1)
do \
s9s maintenance \
--create \
--nodes=$host \
--start="$(date -d 'now' '+%Y-%m-%d %H:%M:%S')" \
--end="$(date -d 'now + 50 minutes' '+%Y-%m-%d %H:%M:%S')" \
--reason="VM Backup"
doneUložte jej a ujistěte se, že oprávnění k souboru je spustitelné:
$ chmod 755 /usr/local/bin/enable_maintenance_modePoté pomocí cronu naplánujte spuštění skriptu na 5 minut až 1:00 denně, těsně před zahájením operace zálohování virtuálního počítače v 1:00:
$ crontab -e
55 0 * * * /usr/local/bin/enable_maintenance_modeZnovu načtěte démona cron, abyste zajistili, že náš skript bude zařazen do fronty:
$ systemctl reload crond # or service crond reloadA je to. Nyní můžeme provádět naši každodenní údržbu, aniž bychom byli odposloucháváni falešnými poplachy a upozorněním e-mailem, dokud nebude údržba dokončena.
Funkce bonusové údržby – vynechání obnovy uzlu
S povolenou automatickou obnovou je ClusterControl dostatečně chytrý na to, aby detekoval selhání uzlu a pokusí se obnovit poškozený uzel po 30sekundové dodatečné lhůtě, bez ohledu na stav režimu údržby. Věděli jste, že ClusterControl lze nakonfigurovat tak, aby záměrně přeskakoval obnovu uzlu pro konkrétní uzel? To může být velmi užitečné, když musíte provést neodkladnou údržbu, aniž byste znali časové rozpětí a výsledek údržby.
Představte si například, že došlo k poškození souborového systému a po tvrdém restartu je vyžadována kontrola a oprava souborového systému. Je těžké předem určit, kolik času bude k dokončení této operace zapotřebí. Můžeme tedy jednoduše použít příznakový soubor k signalizaci ClusterControl, aby vynechal obnovu pro uzel.
Nejprve přidejte následující řádek do souboru /etc/cmon.d/cmon_X.cnf (kde X je ID clusteru) v uzlu ClusterControl:
node_recovery_lock_file=/root/do_not_recoverPoté restartujte službu cmon a načtěte změnu:
$ systemctl restart cmon # service cmon restartNakonec se ujistěte, že zadaný soubor je přítomen v uzlu, který chceme přeskočit pro obnovu ClusterControl:
$ touch /root/do_not_recoverBez ohledu na stav režimu automatického obnovení a údržby ClusterControl obnoví uzel pouze v případě, že tento příznakový soubor neexistuje. Správce je pak odpovědný za vytvoření a odstranění souboru v uzlu databáze.
To je ono, lidi. Šťastnou údržbu!