Je téměř zaručeno, že v určitém okamžiku dojde k výpadkům výroby. Přijetí této skutečnosti a analýza časové osy a scénáře selhání vašeho výpadku databáze může pomoci lépe se připravit, diagnostikovat a zotavit se z dalšího. Aby organizace zmírnily dopad prostojů, potřebují vhodný plán obnovy po havárii (DR). Plánování DR je kritickým úkolem pro mnoho SysOps/DevOps, ale i když je předvídáno; často neexistuje.
V tomto příspěvku na blogu budeme analyzovat různé scénáře zálohování a selhání v databázových systémech MongoDB. Provedeme vás také postupy obnovy a převzetí služeb při selhání pro každý příslušný scénář. Tyto případy použití se budou lišit od obnovení jednoho uzlu, obnovení uzlu v existující sadě replicaSet a osazení nového uzlu v sadě replicaSet. Doufejme, že vám to umožní dobře porozumět rizikům, kterým můžete čelit, a tomu, co je třeba vzít v úvahu při navrhování infrastruktury.
Než začneme diskutovat o možných scénářích selhání, podívejme se, jak MongoDB ukládá data a jaké typy záloh jsou dostupné.
Jak MongoDB ukládá data
MongoDB je databáze orientovaná na dokumenty. Místo ukládání dat do tabulek vytvořených z jednotlivých řádků (jako to dělá relační databáze), ukládá data do kolekcí vytvořených z jednotlivých dokumentů. V MongoDB je dokument velký blob JSON bez konkrétního formátu nebo schématu. Navíc lze data šířit mezi různé uzly clusteru pomocí sdílení nebo replikovat na podřízené servery pomocí replicaSet.
MongoDB ve výchozím nastavení umožňuje velmi rychlé zápisy a aktualizace. Kompromisem je, že často nejste výslovně upozorněni na selhání. Ve výchozím nastavení většina ovladačů provádí asynchronní, nebezpečné zápisy. To znamená, že ovladač nevrací chybu přímo, podobně jako INSERT DELAYED s MySQL. Pokud chcete vědět, zda se něco povedlo, musíte ručně zkontrolovat chyby pomocí getLastError.
Pro optimální výkon je pro úložiště vhodnější používat SSD než HDD. Je nutné se postarat o to, zda je vaše úložiště lokální nebo vzdálené a podle toho přijmout opatření. Pro ochranu hardwarových defektů a schémata obnovy je lepší používat RAID, ale nespoléhejte se na něj úplně, protože nenabízí ochranu proti nežádoucím selháním. Správný hardware je stavebním kamenem vaší aplikace pro optimalizaci výkonu a vyhnutí se velkému debaklu.
Poškození dat na úrovni disku nebo chybějící datové soubory mohou zabránit spuštění instancí mongodu a soubory deníku nemusí stačit k automatickému obnovení.
Pokud běžíte s povoleným žurnálováním, není téměř nikdy potřeba spouštět opravu, protože server může použít soubory žurnálu k automatické obnově datových souborů do čistého stavu. V případech, kdy se potřebujete zotavit z poškození dat na úrovni disku, budete možná muset spustit opravu.
Pokud žurnálování není povoleno, jedinou možností může být spuštění příkazu opravy. mongod --repair by měl být použit pouze v případě, že nemáte žádné jiné možnosti, protože operace během procesu opravy odstraní (a neuloží) všechna poškozená data. Tomuto typu operace by měla vždy předcházet záloha.
Scénář obnovy po havárii MongoDB
V plánu obnovy po selhání je cíl bodu obnovy (RPO) klíčovým parametrem obnovy, který určuje, kolik dat si můžete dovolit ztratit. RPO je uveden v čase, od milisekund až po dny a je přímo závislý na vašem zálohovacím systému. Bere v úvahu stáří vašich zálohovaných dat, která musíte obnovit, abyste mohli obnovit normální operace.
Abyste odhadli RPO, musíte si položit několik otázek. Kdy jsou moje data zálohována? Co je SLA spojeno s načítáním dat? Je obnovování zálohy dat přijatelné, nebo musí být data online a připravena k dotazování v kteroukoli danou chvíli?
Odpovědi na tyto otázky vám pomohou určit, jaký typ zálohovacího řešení potřebujete.
Řešení zálohování MongoDB
Techniky zálohování mají různé dopady na výkon běžící databáze. Některá řešení zálohování snižují výkon databáze natolik, že možná budete muset naplánovat zálohování, abyste se vyhnuli špičkovému využití nebo oknům údržby. Můžete se rozhodnout nasadit nové sekundární servery pouze pro podporu zálohování.
Tři nejběžnější řešení pro zálohování serveru/klastru MongoDB jsou...
- Mongodump/Mongorestore – logické zálohování.
- Mongo Management System (Cloud) – Produkční databáze lze zálohovat pomocí MongoDB Ops Manager nebo pokud používáte službu MongoDB Atlas, můžete použít plně spravované zálohovací řešení.
- Snímky databáze (záloha na úrovni disku)
Mongodump/Mongorestore
Při provádění mongodump budou všechny kolekce v rámci určených databází vypsány jako výstup BSON. Pokud není zadána žádná databáze, MongoDB vypíše všechny databáze kromě administrátorské, testovací a lokální databáze, protože jsou vyhrazeny pro interní použití.
Ve výchozím nastavení mongodump vytvoří adresář nazvaný dump, s adresářem pro každou databázi obsahující soubor BSON pro každou kolekci v této databázi. Případně můžete říci mongodump, aby zálohu uložil do jednoho archivního souboru. Parametr archiv zřetězí výstup ze všech databází a kolekcí do jednoho jediného proudu binárních dat. Navíc parametr gzip může přirozeně komprimovat tento archiv pomocí gzip. V ClusterControl streamujeme všechny naše zálohy, takže povolujeme parametry archivu i gzip.
Podobně jako u mysqldump s MySQL, pokud vytvoříte zálohu v MongoDB, zmrazí kolekce a obsah uloží do záložního souboru. Protože MongoDB nepodporuje transakce (změněno ve 4.2), nemůžete vytvořit 100% plně konzistentní zálohu, pokud zálohu nevytvoříte s parametrem oplog. Povolení této možnosti v záloze zahrnuje transakce z oplogu, které byly prováděny při vytváření zálohy.
Pro lepší automatizaci a můžete spustit MongoDB z příkazového řádku nebo použít externí nástroje, jako je ClusterControl. ClusterControl je doporučená volba pro správu zálohování a automatizaci zálohování, protože umožňuje vytvářet pokročilé strategie zálohování pro různé open source databázové systémy.
ClusterControl vám umožňuje nahrát zálohu do cloudu. Podporuje úplné zálohování a obnovuje šifrování mongodump. Pokud chcete vidět, jak to funguje, na našem webu je ukázka.
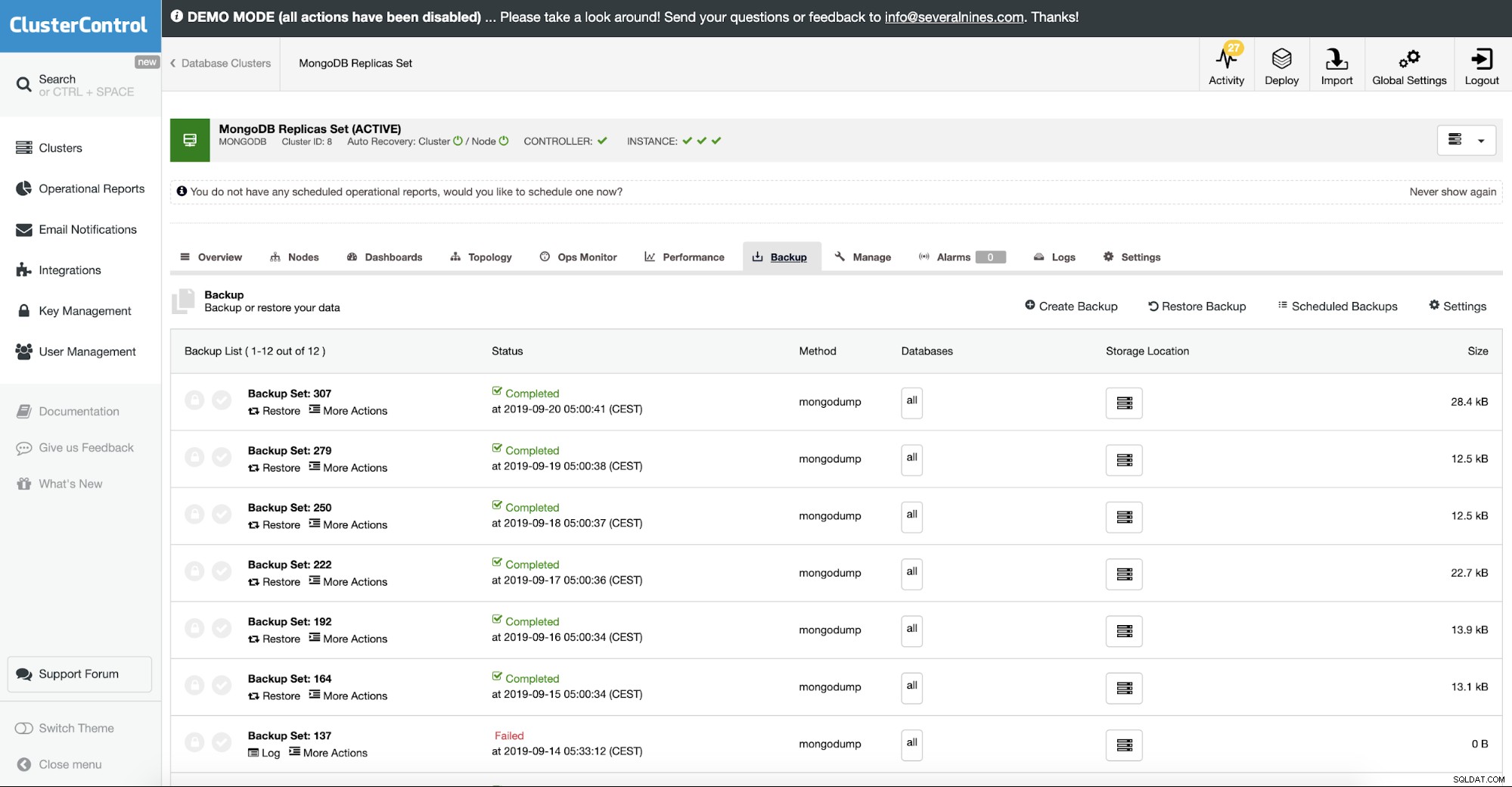
Obnovení MongoDB ze zálohy
Existují v zásadě dva způsoby, jak můžete použít výpis formátu BSON:
- Spusťte mongod přímo ze záložního adresáře
- Spusťte mongorestore a obnovte zálohu
Spustit mongoda přímo ze zálohy
Předpokladem pro spuštění mongodu přímo ze zálohy je, že cíl zálohy je standardní výpis a není gzipován.
Démon MongoDB poté zkontroluje integritu datového adresáře, přidá databázi správce, žurnály, katalogy kolekcí a indexů a některé další soubory potřebné ke spuštění MongoDB. Pokud jste dříve spouštěli WiredTiger jako modul úložiště, bude nyní spouštět existující kolekce jako MMAP. Pro jednoduché výpisy dat nebo kontroly integrity to funguje dobře.
Spuštění mongorestore
Lepším způsobem obnovení by samozřejmě bylo obnovení uzlu pomocí mongorestore.
mongorestore dump/Tímto obnovíte zálohu do výchozího nastavení serveru (localhost, port 27017) a přepíšete všechny databáze v záloze, které se nacházejí na tomto serveru. Nyní existuje spousta parametrů pro manipulaci s procesem obnovy a my se budeme zabývat některými z důležitých.
V ClusterControl se to provádí v možnosti obnovení zálohy. Můžete si vybrat stroj, kdy bude záloha obnovena a zpracovat se postarat o zbytek. To zahrnuje šifrované zálohy, kde byste normálně museli zálohu také dešifrovat.
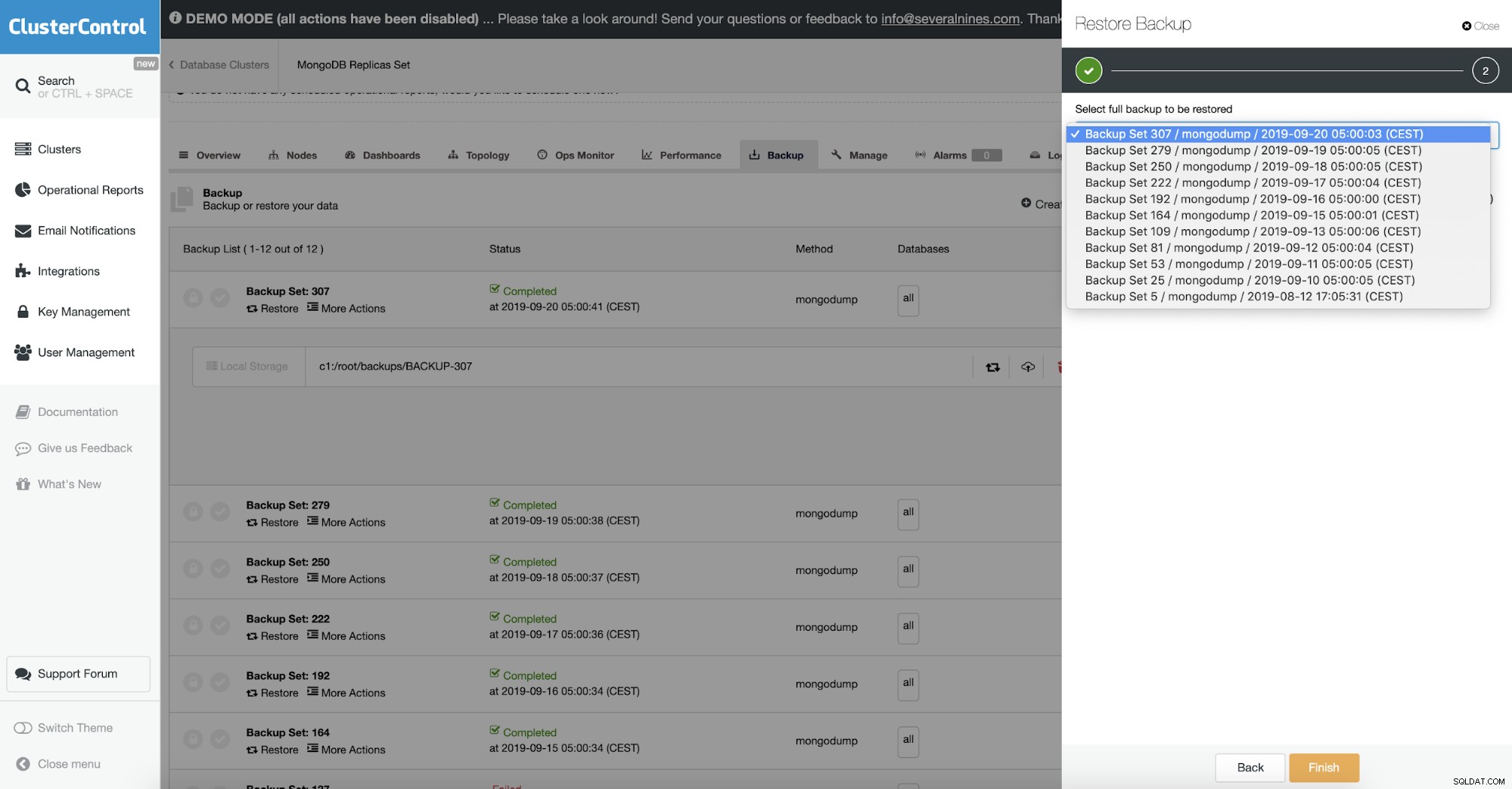
Ověření objektu
Protože záloha obsahuje data BSON, očekávali byste, že obsah zálohy bude správný. Mohlo se však stát, že dokument, který byl vyhozen, byl pro začátek poškozený. Mongodump nekontroluje integritu dat, která vypisuje.
Řešení tohoto použití -- objcheck, který nutí mongorestore ověřovat všechny požadavky od klientů po přijetí, aby bylo zajištěno, že klienti nikdy nevloží do databáze neplatné dokumenty. Může to mít malý dopad na výkon.
Oplog Replay
Přihlášení k zálohování vám umožní provádět konzistentní zálohování a obnovení v určitém okamžiku. Chcete-li použít oplog během procesu obnovy, povolte parametr oplogReplay. Chcete-li řídit, jak daleko se má oplog přehrát, můžete definovat časové razítko v parametru oplogLimit. Poté budou použity pouze transakce do časového razítka.
Obnovení úplné sady replik ze zálohy
Obnovení sady replicaSet se příliš neliší od obnovy jednoho uzlu. Buď musíte nejprve nastavit sadu replicaSet a obnovit ji přímo do sady replicaSet. Nebo nejprve obnovíte jeden uzel a poté tento obnovený uzel použijete k vytvoření sady replicaSet.
Nejprve obnovte uzel a poté vytvořte sadu replicaSet
Nyní druhý a třetí uzel synchronizují svá data z prvního uzlu. Po dokončení synchronizace byla naše sada replicaSet obnovena.
Nejprve vytvořte sadu ReplicaSet a poté obnovte
Na rozdíl od předchozího procesu můžete nejprve vytvořit sadu replicaSet. Nejprve nakonfigurujte všechny tři hostitele s povolenou sadou replicaSet, spusťte všechny tři démony a spusťte sadu replicaSet na prvním uzlu:
Nyní, když jsme vytvořili sadu replicaSet, můžeme do ní přímo obnovit naši zálohu:
Podle našeho názoru je obnovení sady replicaSet tímto způsobem mnohem elegantnější. Je to blíže způsobu, jakým byste normálně vytvořili novou sadu replicaSet od začátku a poté ji naplnili (produkčními) daty.
Nasazení nového uzlu v ReplicaSet
Při škálování clusteru přidáním nového uzlu v MongoDB musí proběhnout počáteční synchronizace datové sady. S replikací MySQL a Galera jsme tak zvyklí používat zálohu pro počáteční synchronizaci. S MongoDB je to možné, ale pouze vytvořením binární kopie datového adresáře. Pokud nemáte prostředky k vytvoření snímku systému souborů, budete muset čelit výpadkům na jednom ze stávajících uzlů. Proces s prostoji je popsán níže.
Seedování se zálohou
Co by se tedy stalo, kdybyste místo toho obnovili nový uzel ze zálohy mongodump a poté jej připojili k sadě replicaSet? Obnova ze zálohy by teoreticky měla poskytnout stejnou datovou sadu. Protože tento nový uzel byl obnoven ze zálohy, bude postrádat replicaSetId a MongoDB si toho všimne. Protože MongoDB nevidí tento uzel jako součást replicaSet, příkaz rs.add() pak vždy spustí počáteční synchronizaci MongoDB. Počáteční synchronizace vždy spustí odstranění všech existujících dat v uzlu MongoDB.
Id replicaSetId se generuje při spouštění sady replicaSet a bohužel jej nelze nastavit ručně. To je škoda, protože obnova ze zálohy (včetně přehrání oplogu) by nám teoreticky poskytla 100% identickou sadu dat. Bylo by hezké, kdyby počáteční synchronizace byla v MongoDB volitelná, aby se uspokojil tento případ použití.