MongoDB je databáze NoSQL, která podporuje širokou škálu zdrojů vstupních datových sad. Je schopen ukládat data do flexibilních dokumentů typu JSON, což znamená, že pole nebo metadata se mohou lišit dokument od dokumentu a struktura dat se může v průběhu času měnit. Model dokumentu usnadňuje práci s daty mapováním na objekty v kódu aplikace. MongoDB je ve svém jádru také známá jako distribuovaná databáze, takže vysoká dostupnost, horizontální škálování a geografická distribuce jsou integrovány a snadno se používají. Přichází s možností plynule upravovat parametry pro trénink modelu. Data Scientists mohou snadno sloučit strukturování dat s tímto generováním modelu.
Co je strojové učení?
Strojové učení je věda o tom, jak přimět počítače, aby se učily a chovaly se jako lidé, a zdokonaluje své učení v průběhu času autonomním způsobem. Proces učení začíná pozorováním nebo daty, jako jsou příklady, přímá zkušenost nebo instrukce, abychom hledali vzory v datech a činili v budoucnu lepší rozhodnutí na základě příkladů, které poskytujeme. Primárním cílem je umožnit počítačům učit se automaticky bez lidského zásahu nebo pomoci a podle toho upravit akce.
Rozsáhlý model programování a dotazování
MongoDB nabízí nativní ovladače i certifikované konektory pro vývojáře a datové vědce, kteří vytvářejí modely strojového učení s daty z MongoDB. PyMongo je skvělá knihovna pro vložení syntaxe MongoDB do kódu Pythonu. Můžeme importovat všechny funkce a metody MongoDB a použít je v našem kódu strojového učení. Je to skvělá technika, jak získat vícejazyčnou funkčnost v jediném kódu. Další výhodou je, že můžete použít základní funkce těchto programovacích jazyků k vytvoření efektivní aplikace.
Dotazovací jazyk MongoDB s bohatými sekundárními indexy umožňuje vývojářům vytvářet aplikace, které mohou dotazovat a analyzovat data ve více dimenzích. K datům lze přistupovat pomocí jednotlivých klíčů, rozsahů, textového vyhledávání, grafu a geoprostorových dotazů prostřednictvím komplexních agregací a úloh MapReduce, které vracejí odpovědi během milisekund.
Pro paralelizaci zpracování dat napříč distribuovaným databázovým clusterem poskytuje MongoDB agregační kanál a MapReduce. Agregační kanál MongoDB je modelován podle konceptu potrubí zpracování dat. Dokumenty vstupují do vícefázového kanálu, který převádí dokumenty na agregovaný výsledek pomocí nativních operací prováděných v rámci MongoDB. Nejzákladnější fáze potrubí poskytují filtry, které fungují jako dotazy, a transformace dokumentů, které upravují formu výstupního dokumentu. Další operace potrubí poskytují nástroje pro seskupování a třídění dokumentů podle konkrétních polí a také nástroje pro agregaci obsahu polí, včetně polí dokumentů. Kromě toho mohou fáze pipeline používat operátory pro úkoly, jako je výpočet průměru nebo standardních odchylek napříč kolekcemi dokumentů a manipulace s řetězci. MongoDB také poskytuje nativní operace MapReduce v rámci databáze pomocí vlastních funkcí JavaScriptu k provedení mapy a omezení fází.
Kromě svého nativního rámce dotazů nabízí MongoDB také vysoce výkonný konektor pro Apache Spark. Konektor zpřístupňuje všechny knihovny Spark, včetně Pythonu, R, Scaly a Javy. Data MongoDB se zhmotňují jako datové rámce a datové sady pro analýzu pomocí strojového učení, grafů, streamování a SQL API.
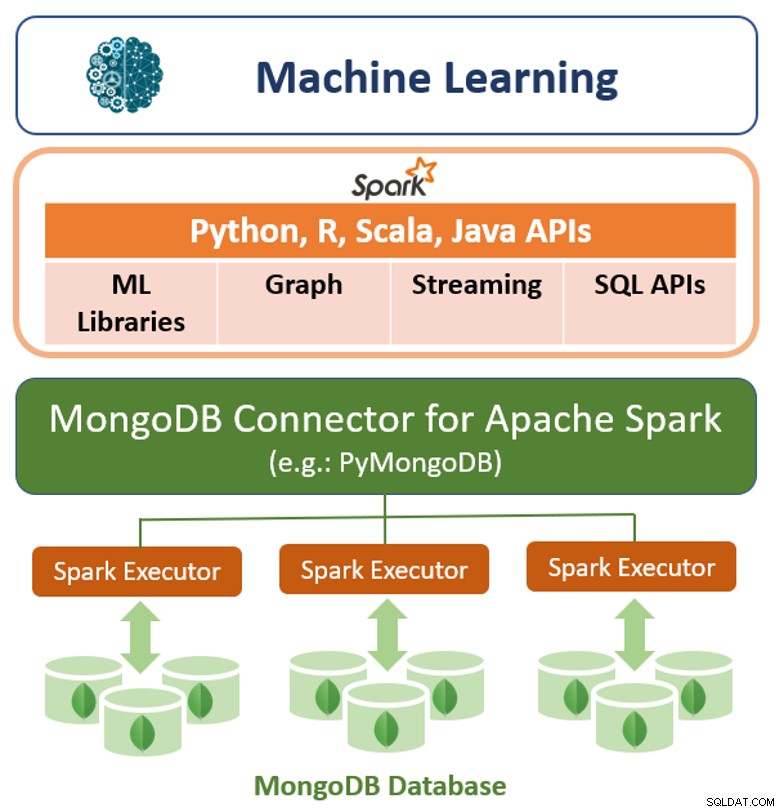
Konektor MongoDB pro Apache Spark může využívat agregační kanál MongoDB a sekundární indexy extrahovat, filtrovat a zpracovávat pouze rozsah dat, který potřebuje – například analýzu všech zákazníků nacházejících se v určité geografické oblasti. To se velmi liší od jednoduchých datových úložišť NoSQL, která nepodporují sekundární indexy ani agregace v databázi. V těchto případech by Spark musel extrahovat všechna data na základě jednoduchého primárního klíče, i když je pro proces Spark vyžadována pouze podmnožina těchto dat. To znamená vyšší režii na zpracování, více hardwaru a delší dobu potřebnou k nahlédnutí pro datové vědce a inženýry. Pro maximalizaci výkonu napříč velkými, distribuovanými datovými sadami může MongoDB Connector pro Apache Spark společně lokalizovat Resilient Distributed Datasets (RDD) se zdrojovým MongoDB uzlem, čímž se minimalizuje pohyb dat napříč clusterem a snižuje se latence.
Výkon, škálovatelnost a redundance
Dobu školení modelu lze zkrátit vytvořením platformy strojového učení nad výkonnou a škálovatelnou databázovou vrstvu. MongoDB nabízí řadu inovací pro maximalizaci propustnosti a minimalizaci latence strojového učení:
- WiredTiger je známý jako výchozí modul úložiště pro MongoDB, vyvinutý architekty Berkeley DB, nejrozšířenějšího integrovaného softwaru pro správu dat na světě. WiredTiger se škáluje na moderních vícejádrových architekturách. Pomocí různých programovacích technik, jako jsou ukazatele nebezpečí, algoritmy bez zámku, rychlé blokování a předávání zpráv, WiredTiger maximalizuje výpočetní práci na jádro CPU a takt. Pro minimalizaci režie na disku a I/O používá WiredTiger kompaktní formáty souborů a kompresi úložiště.
- Pro aplikace strojového učení, které jsou nejvíce citlivé na latenci, lze MongoDB nakonfigurovat s modulem úložiště In-Memory. Tento úložný modul založený na WiredTiger poskytuje uživatelům výhody in-memory computingu, aniž by se vzdali bohaté flexibility dotazů, analýzy v reálném čase a škálovatelné kapacity, kterou nabízejí konvenční diskové databáze.
- K paralelizaci trénování modelu a škálování vstupních datových sad mimo jeden uzel používá MongoDB techniku zvanou sharding, která distribuuje zpracování a data mezi klastry komoditního hardwaru. Sharding MongoDB je plně elastický, automaticky přerovnává data v rámci clusteru, jak se vstupní datová sada zvětšuje nebo jak jsou přidávány a odstraňovány uzly.
- V rámci clusteru MongoDB jsou data z každého fragmentu automaticky distribuována do několika replik hostovaných na samostatných uzlech. Sady replik MongoDB poskytují redundanci pro obnovu trénovacích dat v případě selhání, čímž snižují režii kontrolních bodů.
Laditelná konzistence MongoDB
MongoDB je ve výchozím nastavení silně konzistentní, což umožňuje aplikacím strojového učení okamžitě číst, co bylo zapsáno do databáze, a vyhnout se tak vývojářské složitosti způsobené nakonec konzistentními systémy. Silná konzistence poskytne nejpřesnější výsledky pro algoritmy strojového učení; v některých scénářích je však přijatelné obchodovat konzistentnost s konkrétními výkonnostními cíli distribucí dotazů do klastru členů sekundární sady replik MongoDB.
Flexibilní datový model v MongoDB
Datový model dokumentu MongoDB usnadňuje vývojářům a datovým vědcům ukládat a agregovat data jakékoli formy struktury v databázi, aniž by se museli vzdát sofistikovaných pravidel ověřování pro řízení kvality dat. Schéma lze dynamicky upravovat bez výpadku aplikace nebo databáze, který je důsledkem nákladných úprav schématu nebo přepracování, které si vyžádají systémy relačních databází.
Ukládání modelů do databáze a jejich načítání pomocí pythonu je také jednoduchá a velmi požadovaná metoda. Volba MongoDB je také výhodou, protože se jedná o open-source databázi dokumentů a také přední NoSQL databázi. MongoDB také slouží jako konektor pro distribuovaný framework Apache Spark.
Dynamická povaha MongoDB
Dynamická povaha MongoDB umožňuje jeho použití v úlohách manipulace s databází při vývoji aplikací strojového učení. Je to velmi efektivní a snadný způsob, jak provádět analýzu datových sad a databází. Výstup analýzy lze použít při trénování modelů strojového učení. Bylo doporučeno, aby datoví analytici a programátoři Machine Learning získali mistrovství v MongoDB a použili jej v mnoha různých aplikacích. Agregační rámec MongoDB se používá pro pracovní tok datové vědy pro provádění analýzy dat pro řadu aplikací.
Závěr
MongoDB nabízí několik různých funkcí, jako jsou:flexibilní datový model, bohaté programování, datový model, model dotazů a jeho laditelná konzistence, díky kterým je školení a používání algoritmů strojového učení mnohem jednodušší než u tradičních relačních databází. Spuštění MongoDB jako backendové databáze umožní ukládání a obohacování dat strojového učení umožňuje vytrvalost a vyšší efektivitu.