Úvod:Tento příklad ukazujestarší metodu použití IRI RowGen ke generování a naplňování velkých nebo složitých prototypů kolekcí pro testování nebo systémové kapacity pomocí plochých souborů. Jak se dočtete, RowGen by vytvořil potřebná testovací data a vytvořil soubor CSV, který by se načetl do MongoDB pomocí Mongo Import Utility.
Aktualizace pro rok 2019:IRI nyní nabízí také JSON a přímá podpora ovladačů pro přesun dat mezi kolekcemi MongoDB a softwarovými produkty IRI kompatibilními se SortCL, jako je RowGen nebo FieldShield. To znamená, že můžete použít RowGen ke generování testovacích souborů JSON pro import do MongoDB (ne nepodobné metodě uvedené níže v tomto článku) nebo použít FieldShield k maskování dat v Mongo tabulkách do testovacích cílů.
Upozorňujeme, že FieldShield i RowGen jsou součástí platformy pro správu dat IRI Voracity, která nabízí čtyři způsoby vytváření testovacích dat.
Přestože je MongoDB jemná multiplatformní, na dokumenty orientovaná databáze NoSQL, nemá žádný pohodlný způsob, jak generovat a plnit velké nebo složité prototypy kolekcí, které lze použít k testování dotazů nebo plánování kapacity. Tento článek vysvětluje, jak vytvořit testovací data, která může MongoDB používat prostřednictvím IRI RowGen, a uvádí parametry pro syntetický, ale realistický soubor CSV, který může MongoDB importovat pro testování funkčnosti a výkonu.
Nejprve musíte zvážit strukturu a obsah testovacích dat pro potřeby vaší sbírky (tabulka MongoDB). V tomto článku objevíte typické aspekty plánování.
Například víme, že naši sbírku budou tvořit zákazníci, kteří mají všichni Uživatelská jména , Jméno a příjmení , E-mailové adresy a Čísla kreditních karet .
Abychom vytvořili naše testovací data, musíme nejprve vygenerovat nějaké soubory sady. Soubor sady je seznam jedné nebo více hodnot oddělených tabulátory, které již mohou existovat nebo které je třeba vygenerovat ručně nebo automaticky ze sloupců databáze pomocí průvodce ‚Generate New Set File‘ v IRI RowGen.
Generování jmen
1) Vytvořte skript úlohy složené hodnoty dat (jméno a příjmení dohromady) s názvem „CreateNamesSet.rcl“, který může RowGen spustit a vytvořit soubor sady; volejte výstup „User.set“, protože tato jména budou také použita jako základ pro naše uživatelská jména.
2) Vytvořte tři pole, která se mají vygenerovat v Names.set:příjmení, oddělovač tabulátoru a jméno. První pole pojmenujte „LastName“ a vyberte metodiku, která vybere hodnoty ze souboru sady poskytovaného IRI s názvem „names_last.set“. Přidáním doslovné hodnoty „\t“ přidáte oddělovač tabulátoru a poté zopakujte proces použitý pro hodnoty Příjmení a Jméno pomocí name_first.set.
3) Spusťte CreateNamesSet.rcl pomocí RowGen, buď na příkazovém řádku, nebo z grafického uživatelského rozhraní IRI Workbench, abyste vytvořili soubor User.set se jménem a příjmením odděleným tabulátory, který bude použit v jak při generování uživatelských jmen, tak v konečném sestavení testovacího souboru, který naplní naši kolekci prototypů.

Generování uživatelských jmen
Pro uživatelská jména vytvoříme soubor sady, který využívá soubor Users.set vygenerovaný výše. Uživatelská jména v tomto příkladu budou kombinovat příjmení, první iniciály a náhodně vygenerované číslo mezi 100 a 999.
1) Vytvořte nový skript úlohy RowGen pomocí Průvodce složenými daty, nazvěte jej „CreateUsernamesSet.rcl“ a pojmenujte soubor výstupní sady „Usernames.set“.
2) Sestavte hodnoty složených uživatelských jmen se třemi komponentami pojmenovanými Part1, Part2 a Part3.
3) Pro část 1 vyberte metodiku, která vybere hodnoty z (procházení) dříve vygenerovaného souboru User.set, a pro typ výběru zadejte „ALL“, aby bylo zachováno spojení mezi uživateli. uživatelská jména a e-mailové adresy. Nastavte velikost na 5.
4) Pro Část 2 zopakujte proces použitý pro Část 1, kromě Typu výběru, vyberte „Řádek“ a nastavte Index sloupce na 2. Nastavte velikost na 1. Tím zaručíte, že budou použita všechna příjmení v generaci a že první písmeno křestního jména ve stejném řádku je připojeno k uživatelskému jménu.
5) Pro část 3 zadejte generování číselné hodnoty mezi 100 a 999, která bude ke každému uživatelskému jménu přidávat náhodné celé číslo.
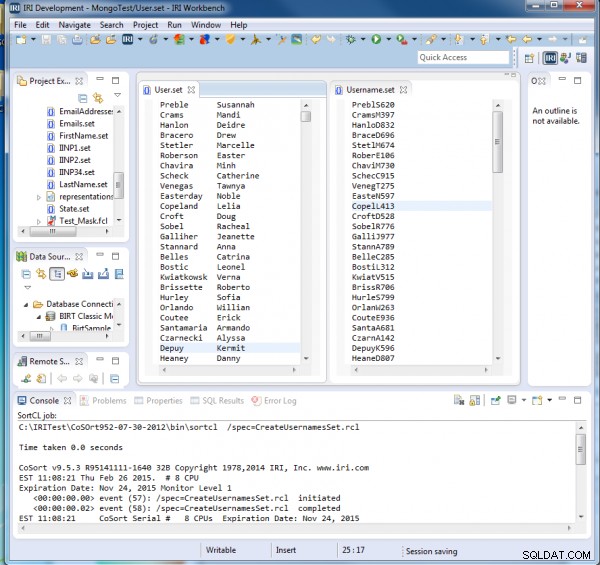
Po spuštění CreateUsernamesSet.rcl vidíme, že každé uživatelské jméno obsahuje prvních pět písmen svého příjmení, poté první iniciálu a poté náhodné 3místné číslo:
Generování e-mailů
Dále vytvoříme soubor e-mailové sady, který k hodnotám uživatelských jmen připojí náhodně vybrané názvy domén. Protože některé e-mailové služby jsou populárnější než jiné, vytvoříme také systém vážení, který bude odrážet vyšší frekvenci domén yahoo a gmail.
1) Spusťte průvodce úlohou „New Custom Test Data“ společnosti RowGen a vytvořte úlohu s názvem „CreateEmailsSet“, která vytvoří soubor sady s názvem „Emails.set“.
2) Vytvořte část e-mailu s uživatelským jménem. V dialogovém okně Definice testovacích dat klikněte na Nové pole a přejmenujte první pole na Uživatelská jména. Poklepáním na něj spustíte dialog Generation Field a „Define…“ jeho soubor Set jako Usernames.set. Nastavte velikost na 9 a klikněte na OK.
3) Vytvořte doménovou část e-mailu (která obsahuje symbol @). V dialogu Pole rozložení klikněte na Nové pole, přejmenujte jej na „adresa“ a dvakrát na něj klikněte. V dialogu Pole generování zadejte „ “ s pozicí 10 a velikostí 20. V části Generování dat / Distribuce dat níže klikněte na „Definovat…“ a pojmenujte novou distribuci dat položek „WeightedEmails“.
4) V Průvodci novou distribucí vyberte možnost „Vážená distribuce položek“ a zadejte tyto položky do textových polí pro poměr a doslovný text a poté je přidejte do seznamu.
(32 | @gmail.com), (32 | @yahoo.com), (2 | @ibm.com), (4 | @msn.com), (2 | @ymail.com), (2 | @inmail.com), (2 | @cnet.net), (2 | @chase.org), (1 | @iri.com), (1 | @gdic.com), (1 | @aci.com), (2 | @oracle.net), (1 | @gmx.org), (4 | @aol.com), (2 | @inbox.com), (2 | @hushmail.com), (2 | @outlook.com), (2 | @zoho.com), (2 | @yandex.net), (2 | @mail.com)
Po zadání těchto hodnot klikněte v původním průvodci na tlačítko Další a přesuňte se do dialogového okna Data Targets. Pomocí „Add Data Target…“ zadejte výstupní soubor „Email.set“. To bude také použito při sestavení kolekce.
E-mail, pro který jsme nastavili nejvyšší váhu (gmail a yahoo), se zobrazují nejčastěji, ostatní se zobrazují pravidelně.

Generování čísel kreditních karet
Nakonec vytvoříme výpočetně platná čísla karet ve formátu XXXX-XXXX-XXXX-XXXX. První čtyři číslice odrážejí skutečná identifikační čísla vydání (IIN) různých společností vydávajících kreditní karty a poslední číslice ověřují pravost karet.
Za tímto účelem vytvořte a spusťte novou (prázdnou) úlohu. Nazvěte jej „CreateCCNSet.rcl“ (nebo .scl) a naplňte jej níže uvedeným skriptem, abyste vytvořili „CCN.set“. Hodnota /INCOLLECT ve skriptech RowGen určuje počet vygenerovaných řádků.

K vyplnění tohoto pole je volána účelová funkce generování CCN společnosti RowGen, ccn_gen(“ANY, “-“). Všimněte si, že podobné funkce existují pro čísla sociálního zabezpečení v USA a Koreji a národní ID Itálie a Nizozemska.
Vytvoření souboru závěrečného testu
Když jsou všechny nastavené soubory vytvořeny, je čas je použít v testovacím souboru CSV, který vytvoříme a exportujeme do sbírky MongoDB.
1) Spusťte průvodce úlohou 'New Custom Test Data' společnosti RowGen a vytvořte úlohu s názvem „CreateMongoUserData.rcl“, která vygeneruje soubor Customers.csv, soubor, který pak exportujeme do MongoDB.
1) P>2) Kliknutím na „Pole rozložení…“ otevřete dialogové okno Pole rozložení. Klikněte na Nové pole a přejmenujte první pole na Uživatelská jména. Poklepáním na něj spustíte dialog Generation Field a „Define…“ jeho soubor Set jako Usernames.set; potom vyberte ALL jako typ výběru.
3) Klikněte na Nové pole a přejmenujte druhé pole na Příjmení. Poklepáním na něj spustíte dialog Generation Field a „Define…“ jeho soubor Set jako Users.set; potom vyberte ALL jako typ výběru.
4) Klikněte na Nové pole a přejmenujte třetí pole na Křestní jména. Poklepáním na něj spustíte dialog Generation Field a „Define…“ jeho soubor Set jako Users.set; pak jako typ výběru vyberte ŘÁDKY a nastavte index sloupce na 2.
5) Klikněte na Nové pole a přejmenujte čtvrté pole na E-mail. Poklepáním na něj spustíte dialog Generation Field a „Define…“ jeho soubor Set jako Emails.set; potom vyberte ALL jako typ výběru.
6) Klikněte na Nové pole a přejmenujte páté pole na CreditCardNumbers. Poklepáním na něj spustíte dialog Generation Field a „Define…“ jeho soubor Set jako CCN.set; potom vyberte ALL jako typ výběru.
7) Po zadání těchto hodnot se kliknutím na tlačítko Další v původním průvodci přesunete do dialogového okna Data Targets. Pomocí „Přidat cíl dat…“ zadejte výstupní soubor Customers.csv; poté spusťte skript ve Workbench nebo na příkazovém řádku a vygenerujte tento soubor:
rowgen /spec=CreateMongoUserData.rcl

Všimněte si, že RowGen, kromě vytvoření tohoto souboru CSV za běhu, mohl také vytvořit několik dalších souborů, databází, formátovaných zpráv, pojmenovaných kanálů, procedurálních a dokonce i zobrazení BIRT v reálném čase , s poli z vygenerovaných testovacích dat, to vše ve stejnou dobu.
Import do MongoDB
Chcete-li importovat soubor CSV do databáze Mongo, zavolejte „mongoimport utility“ a spusťte následující příkaz:
--db <Database Name> --collection <Collection Name> --type csv --fields <fieldname1,fieldname2,...> --file <File path to the CSV file to import>

Zde jsou záznamy v testovací kolekci (zobrazené s MongoVUE), které MongoDB automaticky indexuje s vygenerovanými hodnotami ID pro každý záznam:
MongoDB přiřadí každému záznamu kolekce jedinečnou hodnotu ID.
Testovací data můžete také načíst přímo do databáze Mongo pomocí ovladače DataDirect ODBC od Progress Software pro MongoDB. Před spuštěním úlohy RowGen ve Workbench jsem měl prázdnou kolekci s názvem CUSTOMERS_CNN v MYDB pro příjem dat.
Nejprve jsem spustil úlohu pomocí stdout, abych si v okně konzoly zobrazil náhled testovacích dat:

Po spuštění skriptu ve Workbench nyní mohu vidět svá data pomocí Průzkumníka datových zdrojů a ovladače DataDirect JDBC.

Další informace o dostupných možnostech generování naleznete v části Cíle testovacích souborů sekce na: https://www.iri.com/products/rowgen/technical-details.