Pokud chcete vědět vše o Hadoop MapReduce, jste na správném místě. Tento tutoriál MapReduce vám poskytuje kompletního průvodce o každém a všem v Hadoop MapReduce.
V tomto Úvodu MapReduce prozkoumáte, co je Hadoop MapReduce a jak funguje rámec MapReduce. Článek také zahrnuje MapReduce DataFlow, různé fáze v MapReduce, Mapper, Reducer, Partitioner, Cominer, Shuffling, Sorting, Data Locality a mnoho dalších.
Také jsme uvedli výhody rámce MapReduce.
Pojďme nejprve prozkoumat, proč potřebujeme Hadoop MapReduce.
Proč MapReduce?
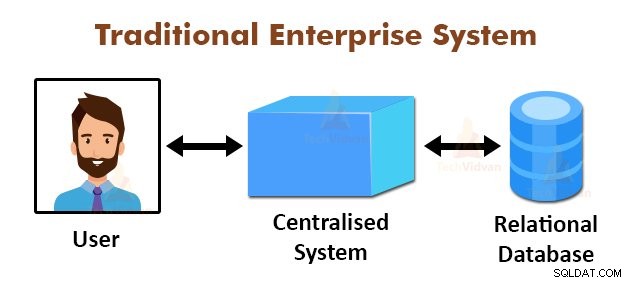
Výše uvedený obrázek znázorňuje schematický pohled na tradiční podnikové systémy. Tradiční systémy mají obvykle centralizovaný server pro ukládání a zpracování dat. Tento model není vhodný pro zpracování velkého množství škálovatelných dat.
Tento model také nemohly vyhovět standardním databázovým serverům. Centralizovaný systém navíc vytváří příliš mnoho úzkých míst při zpracování více souborů současně.
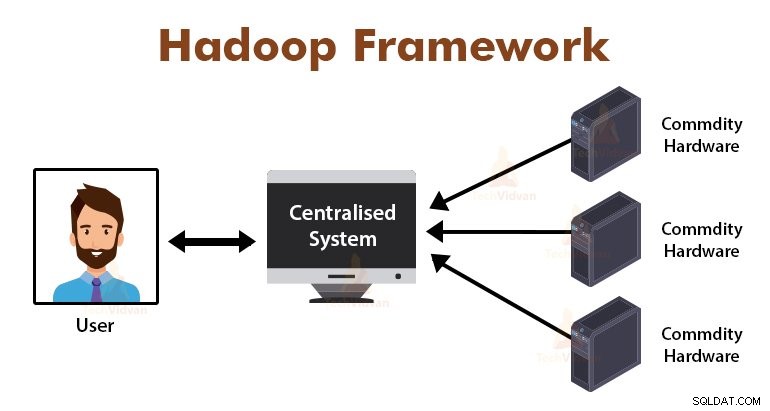
Pomocí algoritmu MapReduce vyřešil Google tento problém s úzkým hrdlem. Rámec MapReduce rozděluje úkol na malé části a přiděluje úkoly mnoha počítačům.
Později jsou výsledky shromažďovány na běžném místě a jsou pak integrovány do výsledné datové sady.
Úvod do MapReduce Framework
MapReduce je vrstva zpracování v Hadoop. Jedná se o softwarový rámec navržený pro paralelní zpracování velkých objemů dat rozdělením úlohy na sadu nezávislých úloh.
Musíme jen vložit obchodní logiku do způsobu, jakým MapReduce funguje, a framework se postará o ostatní věci. Rámec MapReduce funguje tak, že práci rozděluje na malé úkoly a tyto úkoly přiděluje otrokům.
Programy MapReduce jsou napsány zvláštním stylem ovlivněným funkčními programovacími konstrukcemi, specifickými idiomy pro zpracování seznamů dat.
V MapReduce jsou vstupy ve formě seznamu a výstup z frameworku je také ve formě seznamu. MapReduce je srdcem Hadoopu. Efektivita a síla Hadoopu je způsobena paralelním zpracováním rámce MapReduce.
Pojďme nyní prozkoumat, jak Hadoop MapReduce funguje.
Jak Hadoop MapReduce funguje?
Rámec Hadoop MapReduce funguje tak, že rozděluje úlohu na nezávislé úlohy a tyto úlohy provádí na podřízených strojích. Úloha MapReduce se provádí ve dvou fázích, kterými jsou fáze mapy a fáze redukce.
Vstup a výstup z obou fází jsou páry klíčů a hodnot. Rámec MapReduce je založen na principu datové lokality (probráno později), což znamená, že odesílá výpočet do uzlů, kde jsou uložena data.
- Fáze mapy − Ve fázi mapy uživatelsky definovaná mapová funkce zpracovává vstupní data. Do funkce mapy uživatel vloží obchodní logiku. Výstup z fáze Map jsou mezivýstupy a jsou uloženy na místním disku.
- Snížit fázi – Tato fáze je kombinací fáze míchání a fáze snižování. Ve fázi redukce je výstup z fáze mapy předán do reduktoru, kde jsou agregovány. Výstup fáze Reduce je konečným výstupem. Ve fázi Reduce zpracuje uživatelsky definovaná funkce Reduce výstup Mappers a generuje konečné výsledky.
Během úlohy MapReduce odešle framework Hadoop úlohy Map a úlohy Reduce do příslušných počítačů v clusteru.
Samotný framework spravuje všechny detaily předávání dat, jako je vydávání úkolů, ověřování dokončení úkolů a kopírování dat mezi uzly kolem clusteru. Úlohy probíhají na uzlech, kde jsou uložena data, aby se snížil provoz v síti.
MapReduce Data Flow
Všichni možná budete chtít vědět, jak se tyto páry klíč-hodnota generují a jak MapReduce zpracovává vstupní data. Tato část odpovídá na všechny tyto otázky.
Podívejme se, jak musí data proudit z různých fází v Hadoop MapReduce, aby bylo možné zpracovávat nadcházející data paralelním a distribuovaným způsobem.
1. Vstupní soubory
Vstupní datová sada, která má být zpracována programem MapReduce, je uložena v InputFile. Vstupní soubor je uložen v distribuovaném systému souborů Hadoop.
2. InputSplit
Záznam v InputFiles je rozdělen do logického modelu. Velikost rozdělení se obecně rovná velikosti bloku HDFS. Každé rozdělení zpracovává individuální mapovač.
3. Vstupní formát
InputFormat určuje specifikaci vstupu souboru. Definuje cestu ke čtečce záznamů, ve které je záznam ze vstupního souboru převeden na páry klíč, hodnota.
4. RecordReader
RecordReader čte data z InputSplit a převádí záznamy na páry klíč, hodnota a předkládá je mapovačům.
5. Mappers
Mapovači přebírají páry klíč, hodnota jako vstup z RecordReaderu a zpracovávají je implementací uživatelem definované mapovací funkce. V každém mapovači se současně zpracovává jedno rozdělení.
Vývojář vložil obchodní logiku do funkce mapy. Výstupem všech mapovačů je přechodný výstup, který je rovněž ve formě párů klíč, hodnota.
6. Zamíchat a seřadit
Mezivýstup generovaný Mappers je před předáním do reduktoru tříděn, aby se snížilo přetížení sítě. Seřazené mezivýstupy jsou pak přes síť zamíchány do reduktoru.
7. Reduktor
Reducer zpracovává a agreguje výstupy Mapper implementací uživatelem definované funkce snížení. Výstup Reducers je konečným výstupem a je uložen v Hadoop Distributed File System (HDFS).
Pojďme si nyní prostudovat některé terminologie a pokročilé koncepty rámce Hadoop MapReduce.
Páry klíč-hodnota v MapReduce
Rámec MapReduce funguje na párech klíč, hodnota, protože se zabývá nestatickým schématem. Přebírá data ve formě páru klíč, hodnota a generovaný výstup je také ve formě párů klíč, hodnota.
Pár klíč Hodnota MapReduce je entita záznamu, kterou přijímá úloha MapReduce pro provedení. V páru klíč–hodnota:
- Klíč je posun řádku od začátku řádku v souboru.
- Hodnota je obsah řádku s výjimkou zakončení řádku.
MapReduce Partitioner
Hadoop MapReduce Partitioner rozděluje klíčový prostor. Rozdělení klíčového prostoru v MapReduce určuje, že všechny hodnoty každého klíče byly seskupeny, a zajišťuje, že všechny hodnoty jednoho klíče musí jít do stejného Reduceru.
Toto rozdělení umožňuje rovnoměrnou distribuci výstupu mapovače přes Reducer tím, že zajišťuje, že správný klíč jde do správného Reduceru.
Výchozím oddílem MapReducer je Hash Partitioner, který rozděluje klíčové prostory na základě hodnoty hash.
Kombinátor MapReduce
MapReduce Combiner je také známý jako „Semi-Reducer“. Hraje hlavní roli při snižování přetížení sítě. Rámec MapReduce poskytuje funkcionalitu pro definování Combineru, který kombinuje přechodný výstup z Mappers před jejich předáním Reduceru.
Agregace výstupů Mapperu před předáním do Reduceru pomáhá frameworku míchat malá množství dat, což vede k nízkému zahlcení sítě.
Hlavní funkcí Combineru je shrnout výstup mapovačů pomocí stejného klíče a předat jej Reduceru. Třída Combiner se používá mezi třídou Mapper a třídou Reducer.
Lokalita dat v MapReduce
Lokalitou dat se rozumí „Přesouvání výpočtu blíže k datům spíše než přesun dat do výpočtu.“ Je mnohem efektivnější, pokud se výpočet požadovaný aplikací provádí na počítači, kde jsou požadovaná data umístěna.
To platí v případě, kdy je velikost dat obrovská. Je to proto, že minimalizuje zahlcení sítě a zvyšuje celkovou propustnost systému.
Jediným předpokladem je, že je lepší přesunout výpočet blíže ke stroji, kde jsou data přítomna, než přesunout data do stroje, kde běží aplikace.
Apache Hadoop pracuje na obrovském objemu dat, takže není efektivní přesouvat tak velká data po síti. Proto framework přišel s nejinovativnějším principem, kterým je datová lokalita, která přesouvá výpočetní logiku do dat namísto přesunu dat do výpočetních algoritmů. Tomu se říká datová lokalita.
Výhody MapReduce
1. Škálovatelnost: Rámec MapReduce je vysoce škálovatelný. Umožňuje organizacím spouštět aplikace z velkých sad strojů, což může vyžadovat využití tisíců terabajtů dat.
2. Flexibilita: Rámec MapReduce poskytuje organizaci flexibilitu při zpracování dat jakékoli velikosti a formátu, ať už strukturovaných, polostrukturovaných nebo nestrukturovaných.
3. Zabezpečení a ověřování: Programovací model MapReduce poskytuje vysokou bezpečnost. Chrání jakýkoli neoprávněný přístup k datům a zvyšuje zabezpečení clusteru.
4. Nákladově efektivní: Rámec zpracovává data napříč clusterem komoditního hardwaru, což jsou drahé stroje. Je tedy velmi nákladově efektivní.
5. Rychle: MapReduce zpracovává data paralelně, díky čemuž je velmi rychlý. Zpracování terabajtů dat trvá jen několik minut.
6. Jednoduchý model pro programování: Programy MapReduce mohou být napsány v jakémkoli jazyce, jako je Java, Python, Perl, R atd. Každý se tedy může snadno naučit a psát programy MapReduce a splnit své potřeby zpracování dat.
Použití MapReduce
1. Analýza protokolu: MapReduce se v podstatě používá pro analýzu souborů protokolu. Rámec rozděluje velké soubory protokolu na rozdělení a mapovač hledá různé webové stránky, které byly navštíveny.
Pokaždé, když je v protokolu nalezena webová stránka, je pár klíč, hodnota předán reduktoru, kde klíčem je webová stránka a hodnota je „1“. Po odeslání páru klíč, hodnota do Reducer, Reduktor agreguje počet pro určité webové stránky.
Konečným výsledkem bude celkový počet přístupů pro každou webovou stránku.
2. Fulltextové indexování: MapReduce se také používá k provádění fulltextové indexace. Mapovač v MapReduce namapuje každou frázi nebo slovo v jednom dokumentu na dokument. Reducer zapíše tato mapování do indexu.
3. Google používá MapReduce pro výpočet jejich Pagerank.
4. Reverzní graf webových odkazů: MapReduce se také používá v Reverse Web-Link GRaph. Funkce Map vypíše cílovou adresu URL a zdroj a převezme vstup z webové stránky (zdroje).
Funkce snížení pak zřetězí seznam všech zdrojových URL, které jsou spojeny s danou cílovou URL, a vrátí cíl a seznam zdrojů.
5. Počet slov v dokumentu: Rámec MapReduce lze použít pro počítání, kolikrát se slovo objeví v dokumentu.
Shrnutí
Toto je vše o výukovém programu Hadoop MapReduce. Framework paralelně zpracovává obrovské objemy dat napříč clusterem komoditního hardwaru. Rozdělí úlohu na nezávislé úlohy a provádí je paralelně na různých uzlech v clusteru.
MapReduce překonává úzké hrdlo tradičního podnikového systému. Rámec funguje na párech klíč, hodnota. Uživatel definuje dvě funkce, kterými jsou mapovací funkce a funkce zmenšení.
Obchodní logika je vložena do funkce mapy. Článek vysvětloval různé pokročilé koncepty rámce MapReduce.