Získejte přehled o dostupných mechanismech pro zálohování dat uložených v Apache HBase a o tom, jak tato data obnovit v případě různých scénářů obnovy dat / selhání
Se zvýšeným zaváděním a integrací HBase do kritických podnikových systémů musí mnoho podniků chránit toto důležité obchodní aktivum vytvořením robustních strategií zálohování a obnovy po havárii (BDR) pro své clustery HBase. Jakkoli může znít rychlé a snadné zálohování a obnova potenciálně petabajtů dat, HBase a ekosystém Apache Hadoop poskytují mnoho vestavěných mechanismů, jak toho dosáhnout.
V tomto příspěvku získáte přehled na vysoké úrovni o dostupných mechanismech pro zálohování dat uložených v HBase a o tom, jak tato data obnovit v případě různých scénářů obnovy dat/failover. Po přečtení tohoto příspěvku byste měli být schopni učinit kvalifikované rozhodnutí o tom, která strategie BDR je pro vaše obchodní potřeby nejlepší. Měli byste také porozumět výhodám, nevýhodám a dopadům na výkon každého mechanismu. (Podrobnosti zde platí pro CDH 4.3.0/HBase 0.94.6 a novější.)
Poznámka:V době psaní tohoto článku nabízí Cloudera Enterprise 4 funkce zálohování a obnovy po havárii připravené k produkci pro HDFS a Hive Metastore prostřednictvím Cloudera BDR 1.0 jako samostatně licencovanou funkci. HBase není součástí tohoto vydání GA; proto jsou nutné různé mechanismy popsané v tomto blogu. (Cloudera Enterprise 5, aktuálně ve verzi beta, nabízí správu snímků HBase prostřednictvím Cloudera BDR.)
Záloha
HBase je logově strukturované úložiště distribuovaných dat slučovacího stromu se složitými interními mechanismy pro zajištění přesnosti dat, konzistence, verzování a tak dále. Jak tedy proboha můžete získat konzistentní záložní kopii těchto dat, která se nachází v kombinaci souborů HFiles a protokolů WAL (Write-Ahead-Logs) na HDFS a v paměti na desítkách regionálních serverů?
Začněme s nejméně rušivým, nejmenším datovým prostorem, mechanismem s nejmenším dopadem na výkon a propracujme se k nejrušivějšímu nástroji ve stylu vysokozdvižného vozíku:
- Snímky
- Replikace
- Exportovat
- CopyTable
- HTable API
- Offline zálohování dat HDFS
Následující tabulka poskytuje přehled pro rychlé porovnání těchto přístupů, které podrobně popíšu níže.
| Dopad na výkon | Datová stopa | Prostoj | Přírůstkové zálohy | Snadnost implementace | Mean Time To Recovery (MTTR) | |
| Snímky | Minimální | Drobeček | Krátce (pouze při obnovení) | Ne | Snadné | Vteřiny |
| Replikace | Minimální | Velký | Žádné | Intrinsic | Střední | Vteřiny |
| Exportovat | Vysoká | Velký | Žádné | Ano | Snadné | Vysoká |
| CopyTable | Vysoká | Velký | Žádné | Ano | Snadné | Vysoká |
| API | Střední | Velký | Žádné | Ano | Obtížné | Záleží na vás |
| Manuál | Není k dispozici | Velký | Dlouhé | Ne | Střední | Vysoká |
Snímky
Od CDH 4.3.0 jsou snímky HBase plně funkční, bohaté na funkce a nevyžadují při vytváření žádné prostoje clusteru. Můj kolega Matteo Bertozzi ve svém příspěvku na blogu a následném hlubokém ponoru velmi dobře popsal momentky. Zde poskytnu pouze přehled na vysoké úrovni.
Snímky jednoduše zachycují okamžik pro váš stůl vytvořením ekvivalentu pevných odkazů UNIX na soubory úložiště vašeho stolu na HDFS (obrázek 1). Tyto snímky jsou hotové během několika sekund, nekladou na cluster téměř žádné nároky na výkon a vytvářejí nepatrnou datovou stopu. Vaše data nejsou vůbec duplikována, ale pouze katalogizována v malých souborech metadat, což systému umožňuje vrátit se zpět k danému okamžiku, pokud byste potřebovali daný snímek obnovit.
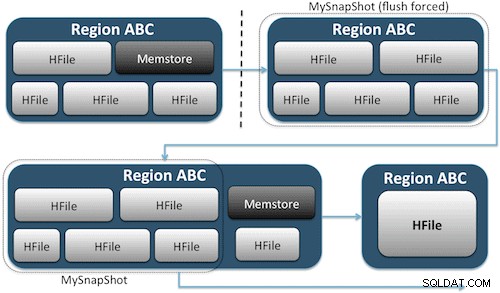
Vytvoření snímku tabulky je stejně jednoduché jako spuštění tohoto příkazu z prostředí HBase:
hbase(main):001:0> snapshot 'myTable', 'MySnapShot'
Po zadání tohoto příkazu najdete několik malých datových souborů umístěných v /hbase/.snapshot/myTable (CDH4) nebo /hbase/.hbase-snapshots (Apache 0.94.6.1) v HDFS, které obsahují potřebné informace k obnovení vašeho snímku. . Obnova je stejně jednoduchá jako vydávání těchto příkazů z shellu:
hbase(main):002:0> disable 'myTable' hbase(main):003:0> restore_snapshot 'MySnapShot' hbase(main):004:0> enable 'myTable'
Poznámka:Jak můžete vidět, obnovení snímku vyžaduje krátký výpadek, protože tabulka musí být offline. Veškerá data přidaná/aktualizovaná po pořízení obnoveného snímku budou ztracena.
Pokud jsou vaše obchodní požadavky takové, že musíte mít zálohu dat mimo pracoviště, můžete použít příkaz exportSnapshot k duplikování dat tabulky do místního clusteru HDFS nebo vzdáleného clusteru HDFS podle vašeho výběru.
Snímky jsou pokaždé úplným obrazem vašeho stolu; v současné době není k dispozici žádná funkce přírůstkového snímku.
Replikace HBase
Dalším nástrojem zálohování s velmi nízkou režií je replikace HBase. (Můj kolega Himanshu Vashishtha se replikaci podrobně věnuje v tomto příspěvku na blogu.) Stručně řečeno, replikaci lze definovat na úrovni skupiny sloupců, funguje na pozadí a synchronizuje všechny úpravy mezi clustery v řetězci replikace.
Replikace má tři režimy:master->slave, master<->master a cyklický. Tento přístup vám poskytuje flexibilitu při ingestování dat z jakéhokoli datového centra a zajišťuje, že se replikují ve všech kopiích této tabulky v jiných datových centrech. V případě katastrofálního výpadku v jednom datovém centru mohou být klientské aplikace přesměrovány do alternativního umístění pro data pomocí nástrojů DNS.
Replikace je robustní proces odolný proti chybám, který poskytuje „případnou konzistenci“, což znamená, že v každém okamžiku nemusí být poslední úpravy tabulky dostupné ve všech replikách této tabulky, ale je zaručeno, že se tam nakonec dostanou.
Poznámka:U existujících tabulek musíte nejprve ručně zkopírovat zdrojovou tabulku do cílové tabulky jedním z dalších prostředků popsaných v tomto příspěvku. Replikace působí pouze na nové zápisy/úpravy poté, co ji povolíte.

(ze stránky Replikace Apache)
Exportovat
Exportní nástroj HBase je vestavěný nástroj HBase, který umožňuje snadný export dat z tabulky HBase do prostých SequenceFiles v adresáři HDFS. Vytvoří úlohu MapReduce, která provede sérii volání HBase API do vašeho clusteru a jeden po druhém získá každý řádek dat ze zadané tabulky a zapíše tato data do vašeho zadaného adresáře HDFS. Tento nástroj je pro váš cluster náročnější na výkon, protože využívá MapReduce a klientské rozhraní API HBase, ale je bohatý na funkce a podporuje filtrování dat podle verze nebo období – a umožňuje tak přírůstkové zálohování.
Zde je ukázka příkazu v jeho nejjednodušší podobě:
hbase org.apache.hadoop.hbase.mapreduce.Export
Jakmile je tabulka exportována, můžete výsledné datové soubory zkopírovat kamkoli budete chtít (například úložiště mimo pracoviště/mimo clusteru). Můžete také zadat vzdálený klastr/adresář HDFS jako výstupní umístění příkazu a Export přímo zapíše obsah do vzdáleného klastru. Upozorňujeme, že tento přístup zavede síťový prvek do cesty pro zápis exportu, takže byste měli potvrdit, že vaše síťové připojení ke vzdálenému clusteru je spolehlivé a rychlé.
CopyTable
Nástroj CopyTable je dobře popsán v příspěvku na blogu Jona Hsieha, ale zde shrnu základy. Podobně jako u Exportu vytvoří CopyTable úlohu MapReduce, která využívá HBase API ke čtení ze zdrojové tabulky. Klíčový rozdíl je v tom, že CopyTable zapisuje svůj výstup přímo do cílové tabulky v HBase, která může být lokální ve zdrojovém clusteru nebo na vzdáleném clusteru.
Příkladem nejjednodušší formy příkazu je:
hbase org.apache.hadoop.hbase.mapreduce.CopyTable --new.name=testCopy test
Tento příkaz zkopíruje obsah tabulky s názvem „test“ do tabulky ve stejném clusteru s názvem „testCopy“.
Všimněte si, že CopyTable má značnou výkonnostní režii v tom, že používá jednotlivé „umístění“ k zápisu dat, řádek po řádku, do cílové tabulky. Pokud je vaše tabulka velmi velká, CopyTable může způsobit zaplnění memstore na serverech cílové oblasti, což bude vyžadovat vyprázdnění memstore, které nakonec povede ke zhutnění, sběru odpadu atd.
Kromě toho musíte vzít v úvahu dopady na výkon spuštění MapReduce přes HBase. U velkých souborů dat nemusí být tento přístup ideální.
HTable API (jako je vlastní aplikace Java)
Jako vždy u Hadoopu můžete vždy napsat svou vlastní aplikaci, která využívá veřejné API a dotazuje se přímo na tabulku. Můžete to udělat pomocí úloh MapReduce, abyste mohli využít výhody distribuovaného dávkového zpracování tohoto rámce, nebo pomocí jakýchkoli jiných prostředků vlastního návrhu. Tento přístup však vyžaduje hluboké pochopení vývoje Hadoop a všech API a výkonových důsledků jejich použití ve vašem produkčním clusteru.
Offline záloha nezpracovaných dat HDFS
Mechanismus zálohování s největší hrubou silou – také ten nejničivější – zahrnuje největší datovou stopu. Můžete čistě vypnout cluster HBase a ručně zkopírovat všechna data a adresářové struktury umístěné v /hbase ve vašem clusteru HDFS. Vzhledem k tomu, že HBase nefunguje, zajistí to, že všechna data byla uložena do HFiles v HDFS a získáte přesnou kopii dat. Přírůstkové zálohy však bude téměř nemožné získat, protože při budoucích zálohách nebudete schopni zjistit, jaká data byla změněna nebo přidána.
Je také důležité poznamenat, že obnovení vašich dat by vyžadovalo offline opravu metadat, protože .META. tabulka by v době obnovy obsahovala potenciálně neplatné informace. Tento přístup také vyžaduje rychlou a spolehlivou síť pro přenos dat mimo pracoviště a v případě potřeby je později obnoví.
Z těchto důvodů Cloudera důrazně nedoporučuje tento přístup k zálohám HBase.
Obnova po havárii
HBase je navržen jako distribuovaný systém extrémně odolný proti chybám s nativní redundancí za předpokladu, že hardware bude často selhávat. Obnova po havárii v HBase má obvykle několik forem:
- Katastrofální selhání na úrovni datového centra vyžadující převzetí služeb při selhání do umístění zálohy
- Potřeba obnovit předchozí kopii dat kvůli chybě uživatele nebo náhodnému smazání
- Možnost obnovit kopii vašich dat v určitém okamžiku pro účely auditu
Stejně jako u každého plánu obnovy po havárii budou obchodní požadavky určovat, jak je plán navržen a kolik peněz do něj investovat. Jakmile vytvoříte zálohy dle vašeho výběru, obnova bude mít různé formy v závislosti na typu požadované obnovy:
- Cluster zálohování při selhání
- Importovat tabulku/obnovit snímek
- Nasměrujte kořenový adresář HBase na umístění zálohy
Pokud je vaše strategie zálohování taková, že jste svá data HBase replikovali do zálohovacího clusteru v jiném datovém centru, selhání je stejně snadné jako nasměrování vašich aplikací koncových uživatelů na zálohovací cluster pomocí technik DNS.
Mějte však na paměti, že pokud plánujete povolit zápis dat do záložního clusteru během období výpadku, budete se muset ujistit, že se data po skončení výpadku vrátí zpět do primárního clusteru. Master-to-master nebo cyklická replikace zvládne tento proces automaticky za vás, ale schéma replikace master-slave způsobí, že váš hlavní cluster nebude synchronizován a po výpadku bude vyžadovat ruční zásah.
Spolu s dříve popsanou funkcí Export existuje odpovídající nástroj pro import, který dokáže převzít data dříve zálohovaná exportem a obnovit je do tabulky HBase. Stejné dopady na výkon, které se uplatňovaly u exportu, jsou ve hře i s importem. Pokud vaše schéma zálohování zahrnovalo pořizování snímků, návrat zpět k předchozí kopii dat je stejně jednoduchý jako obnovení tohoto snímku.
Po havárii se také můžete zotavit tak, že jednoduše upravíte vlastnost hbase.root.dir v hbase-site.xml a nasměrujete ji na záložní kopii vašeho adresáře /hbase, pokud jste provedli offline kopii datových struktur HDFS hrubou silou. . To je však také nejméně žádoucí z možností obnovení, protože vyžaduje delší výpadek, zatímco kopírujete celou datovou strukturu zpět do produkčního clusteru, a jak již bylo zmíněno, .META. může být mimo synchronizaci.
Závěr
Stručně řečeno, obnova dat po nějaké formě ztráty nebo výpadku vyžaduje dobře navržený plán BDR. Důrazně doporučuji, abyste důkladně porozuměli vašim obchodním požadavkům na dobu provozuschopnosti, přesnost/dostupnost dat a obnovu po havárii. Vyzbrojeni podrobnými znalostmi vašich obchodních požadavků si můžete pečlivě vybrat nástroje, které tyto potřeby nejlépe splňují.
Výběr nástrojů je však pouze začátek. Měli byste provést rozsáhlé testy vaší strategie BDR, abyste se ujistili, že funkčně funguje ve vaší infrastruktuře, vyhovuje vašim obchodním potřebám a že vaše provozní týmy jsou dobře obeznámeny s kroky požadovanými předtím, než dojde k výpadku a vy zjistíte, jak těžké váš plán BDR nebude fungovat.
Pokud byste chtěli toto téma komentovat nebo diskutovat dále, použijte naše komunitní fórum pro HBase.
Další čtení:
- Prezentace Strata + Hadoop World 2012 od Jona Hsieha
- HBase:Definitivní průvodce (Lars George)
- HBase v akci (Nick Dimiduk/Amandeep Khurana)