Při provádění dotazu se optimalizátor SQL Serveru snaží najít nejlepší plán dotazů na základě existujících indexů a dostupných nejnovějších statistik po rozumnou dobu, samozřejmě pokud tento plán již není uložen v mezipaměti serveru. Pokud ne, dotaz se provede podle tohoto plánu a plán se uloží do mezipaměti serveru. Pokud byl plán pro tento dotaz již vytvořen, dotaz se provede podle existujícího plánu.
Zajímá nás následující problém:
Pokud během sestavování plánu dotazů při řazení možných indexů server nenalezne nejlepší index, chybějící index se označí v plánu dotazů a server uchovává statistiky o takových indexech:kolikrát by server tento index použil a kolik by tento dotaz stál.
V tomto článku budeme tyto chybějící indexy analyzovat – jak s nimi naložit.
Zvažme to na konkrétním příkladu. Vytvořte několik tabulek v naší databázi na místním a testovacím serveru:
[rozbalit název =”Kód”]
if object_id ('orders_detail') is not null drop table orders_detail;
if object_id('orders') is not null drop table orders;
go
create table orders
(
id int identity primary key,
dt datetime,
seller nvarchar(50)
)
create table orders_detail
(
id int identity primary key,
order_id int foreign key references orders(id),
product nvarchar(30),
qty int,
price money,
cost as qty * price
)
go
with cte as
(
select 1 id union all
select id+1 from cte where id < 20000
)
insert orders
select
dt,
seller
from
(
select
dateadd(day,abs(convert(int,convert(binary(4),newid()))%365),'2016-01-01') dt,
abs(convert(int,convert(binary(4),newid()))%5)+1 seller_id
from cte
) c
left join
(
values
(1,'John'),
(2,'Mike'),
(3,'Ann'),
(4,'Alice'),
(5,'George')
) t (id,seller) on t.id = c.seller_id
option(maxrecursion 0)
insert orders_detail
select
order_id,
product,
qty,
price
from
(
select
o.id as order_id,
abs(convert(int,convert(binary(4),newid()))%5)+1 product_id,
abs(convert(int,convert(binary(4),newid()))%20)+1 qty
from orders o cross join
(
select top(abs(convert(int,convert(binary(4),newid()))%5)+1) *
from
(
values (1),(2),(3),(4),(5),(6),(7),(8)
) n(num)
) n
) c
left join
(
values
(1,'Sugar', 50),
(2,'Milk', 80),
(3,'Bread', 20),
(4,'Pasta', 40),
(5,'Beer', 100)
) t (id,product, price) on t.id = c.product_id
go [/expand]
Struktura je jednoduchá a skládá se ze dvou tabulek. První tabulka se nazývá objednávky s poli jako identifikátor, datum prodeje a prodejce. Druhým jsou detaily objednávky, kde je u některého zboží specifikována cena a množství.
Podívejte se na jednoduchý dotaz a jeho plán:
select count(*) from orders o join orders_detail d on o.id = d.order_id where d.cost > 1800 go
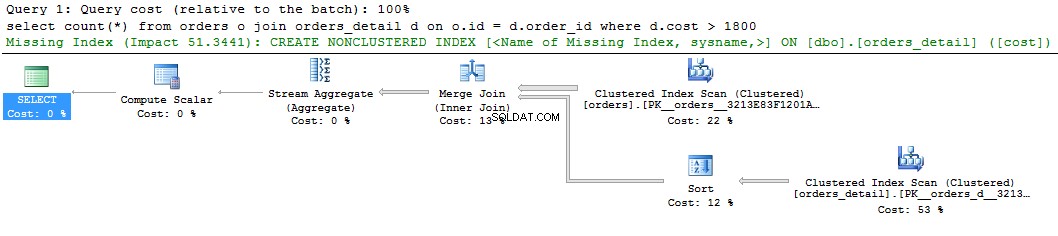
Na grafickém zobrazení plánu dotazů můžeme vidět zelenou nápovědu o chybějícím indexu. Pokud na něj kliknete pravým tlačítkem a vyberete „Chybí podrobnosti o indexu...“, zobrazí se text navrhovaného rejstříku. Jediné, co je třeba udělat, je odstranit komentáře v textu a pojmenovat index. Skript je připraven ke spuštění.
Nebudeme vytvářet index, který jsme obdrželi z nápovědy poskytované SSMS. Místo toho uvidíme, zda tento index doporučí dynamické pohledy napojené na chybějící indexy. Pohledy jsou následující:
select * from sys.dm_db_missing_index_group_stats select * from sys.dm_db_missing_index_details select * from sys.dm_db_missing_index_groups
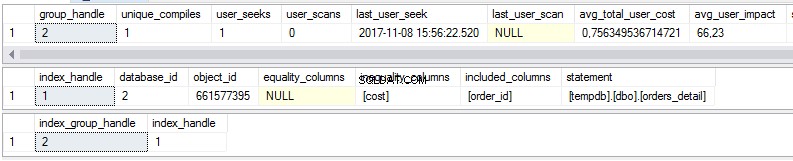
Jak vidíme, v prvním pohledu jsou nějaké statistiky o chybějících indexech:
- Kolikrát by bylo provedeno vyhledávání, kdyby navrhovaný index existoval?
- Kolikrát by byla provedena kontrola, kdyby navrhovaný index existoval?
- Poslední datum a čas, kdy jsme index použili
- Aktuální skutečné náklady na plán dotazů bez navrhovaného indexu.
Druhý pohled je tělo indexu:
- Databáze
- Objekt/tabulka
- Seřazené sloupce
- Přidané sloupce za účelem zvýšení pokrytí indexem
Třetí pohled je kombinací prvního a druhého pohledu.
V souladu s tím není obtížné získat skript, který by generoval skript pro vytváření chybějících indexů z těchto dynamických zobrazení. Skript je následující:
[expand title=”Kód”]
with igs as
(
select *
from sys.dm_db_missing_index_group_stats
)
, igd as
(
select *,
isnull(equality_columns,'')+','+isnull(inequality_columns,'') as ix_col
from sys.dm_db_missing_index_details
)
select --top(10)
'use ['+db_name(igd.database_id)+'];
create index ['+'ix_'+replace(convert(varchar(10),getdate(),120),'-','')+'_'+convert(varchar,igs.group_handle)+'] on '+
igd.[statement]+'('+
case
when left(ix_col,1)=',' then stuff(ix_col,1,1,'')
when right(ix_col,1)=',' then reverse(stuff(reverse(ix_col),1,1,''))
else ix_col
end
+') '+isnull('include('+igd.included_columns+')','')+' with(online=on, maxdop=0)
go
' command
,igs.user_seeks
,igs.user_scans
,igs.avg_total_user_cost
from igs
join sys.dm_db_missing_index_groups link on link.index_group_handle = igs.group_handle
join igd on link.index_handle = igd.index_handle
where igd.database_id = db_id()
order by igs.avg_total_user_cost * igs.user_seeks desc [/expand]
Kvůli efektivitě indexu jsou na výstupu chybějící indexy. Perfektním řešením je, když tato sada výsledků nevrací nic. V našem příkladu sada výsledků vrátí alespoň jeden index:

Když není čas a nemáte chuť řešit klientské chyby, provedl jsem dotaz, zkopíroval první sloupec a provedl jej na serveru. Poté vše fungovalo dobře.
S informacemi na těchto indexech doporučuji zacházet vědomě. Například pokud systém doporučuje následující indexy:
create index ix_01 on tbl1 (a,b) include (c) create index ix_02 on tbl1 (a,b) include (d) create index ix_03 on tbl1 (a)
A tyto indexy se používají pro vyhledávání, je zcela zřejmé, že je logičtější nahradit tyto indexy takovým, který bude pokrývat všechny tři navrhované:
create index ix_1 on tbl1 (a,b) include (c,d)
Proto provedeme kontrolu chybějících indexů před jejich nasazením na produkční server. Ačkoli…. Znovu jsem například nasadil ztracené indexy na server TFS, čímž jsem zvýšil celkový výkon. Provedení této optimalizace zabralo minimum času. Při přechodu z TFS 2015 na TFS 2017 jsem však čelil problému, že kvůli těmto novým indexům nedošlo k žádné aktualizaci. Přesto je lze snadno najít podle masky
select * from sys.indexes where name like 'ix[_]2017%'
Užitečný nástroj:
dbForge Index Manager – praktický doplněk SSMS pro analýzu stavu indexů SQL a řešení problémů s fragmentací indexů.