Úvod
SQL dotaz popisuje očekávaný výsledek, nikoli způsob, jak výsledek získat. Sada konkrétních kroků, které musí server provést, aby vrátil výsledek, se nazývá plán provádění dotazu. Plán je vytvořen optimalizátorem. Výběr plánu ovlivňuje rychlost provádění, což z něj dělá jeden z nejdůležitějších prvků analýzy problému výkonu dotazu.
Prováděcí plán obsahuje operátory a jejich vlastnosti, které jsou vzájemně provázány formou stromové struktury. Každý operátor je odpovědný za samostatnou logickou nebo fyzickou operaci. Všechny dohromady zajišťují výsledek popsaný v textu dotazu. Uvnitř stromu jsou operátory reprezentovány objekty tříd v paměti SQL Serveru. Uživatelé serveru (tedy vy a já) vidí popis vygenerovaný ve formátu XML se specifickým schématem, které je graficky zobrazeno prostředím SQL Server Management Studio (SSMS).
Existuje mnoho různých operátorů plánů a ještě více nemovitostí. Kromě toho se čas od času objeví nové. Tento článek si netroufá popsat všechny možné varianty operátorů. Místo toho bych se rád podělil o nejzajímavější doplňky v tomto tématu a připomněl některé staré, ale užitečné prvky.
Verze serveru
Někdy můžete na fórech najít požadavky na verzi serveru, i když je plán dotazů poskytnut ve správném formátu (XML). Místo toho můžete ušetřit čas a otevřít plán provádění jako XML. A první prvek popisující plán vám ukáže verzi serveru ve vlastnosti Build.
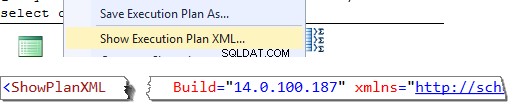
Tato metoda neumožňuje získat úplné informace o edici serveru, ale ve většině případů stačí k pochopení toho, čím se zabýváme.
Počet řádků tabulky
Druhou častou otázkou je „Kolik řádků obsahuje vaše tabulka?“. Tyto informace lze také získat z plánu dotazů (od verze serveru 2008). K tomu musíme vybrat operátora přístupu k datům (Scan nebo Seek) příslušné tabulky a podívat se na TableCardinality vlastnictví. Existuje ještě jedna zajímavá vlastnost, Odhadovaná velikost řádku pro specifikaci velikosti řádku a přibližné vyhodnocení velikosti tabulky nebo indexu (vzhledem k tomu, že tabulka není komprimována).
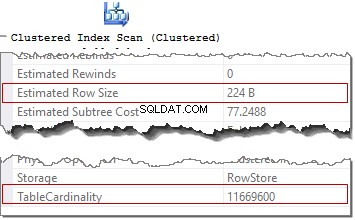
Rád bych poznamenal, že se nejedná o skutečný počet řádků v tabulce, ale o data ze statistik objektů. Tato data jsou však základem pro rozhodnutí, která optimalizátor činí při sestavování dotazu.
Kontext
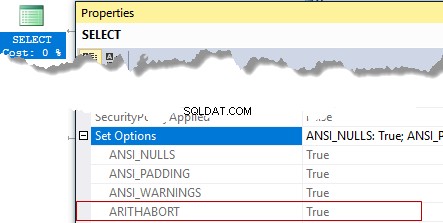
Plán dotazů ukládá významná nastavení SET, pro která byl vytvořen. Chcete-li zobrazit nastavení, musíte vybrat kořenový prvek v plánu a rozbalit Možnosti nastavení vlastnictví. Můžeme se například dozvědět, zda byl plán vytvořen pomocí ARITHABORT volba povolena (rozdíl v tomto nastavení často vede ke dvěma různým plánům a situacím se špatným sniffováním parametrů).
Počet procesorů
Můžeme získat počet procesorů, které jsou k dispozici pro optimalizátor. K tomu musíme otevřít OptimizerHardwareDependentPropertie s -> EstimatedAvailableDegreeOfParallelism parametr ve stejném kořenovém prvku a vynásobte jej 2. Pokud je k dispozici pouze jeden procesor, není nutné násobení.

2*2 =4, k dispozici jsou 4 CPU. Ve skutečnosti mám na svém počítači 4jádrový procesor a všechna 4 jádra jsou pro server k dispozici. Tyto informace vám mohou pomoci odhalit stroj, na kterém byl plán vytvořen.
Verze odhadu mohutnosti
Od SQL Server 2014 je k dispozici několik verzí Cardinality Estimator (RU). Tento mechanismus ovlivňuje většinu rozhodnutí, která optimalizátor přijímá při výběru plánu. Verzi Cardinality Estimator můžete získat z CardinalityEstimationModelVersion vlastnost kořenového operátoru.
- 0 – SQL Server <=2012
- 120 – SQL Server 2014
- 130 – SQL Server 2016
- 140 – SQL Server vNext

Doba provedení dotazu a doba čekání
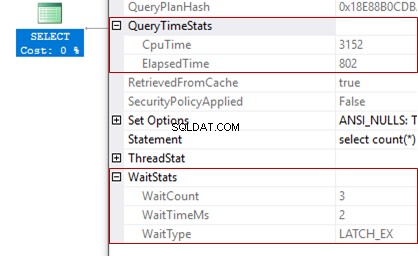
Od SQL Server 2016 SP1 obsahuje skutečný plán dotazů informace o době provádění a době procesoru. Chcete-li tato data načíst, musíte rozbalit QueryTimeStats vlastnost v kořenovém prvku a zobrazit hodnoty CpuTime a ElapsedTime . Nemusíme povolovat shromažďování času provedení nebo se ptát „jak dlouho byl dotaz proveden?“ již – všechny tyto informace jsou součástí plánu.
Druhým významným vylepšením je top 10 nejdelších čekání během provádění dotazu. K tomu potřebujeme rozbalit WaitStats vlastnost v kořenovém prvku. Tento doplněk umožňuje získat přesnější důvody pomalého provádění dotazu a výrazně zjednodušuje diagnostiku.
Typy parametrů
Seznam parametrů vlastnost, která uvádí parametry použité v dotazu, existovala v plánu již dávno. Od verze SQL Server 2016 SP1 však Typ dat parametru vlastnost byla přidána do definice parametru. Tato vlastnost ukládá datový typ parametru. Může to být užitečné pro pochopení problémů s převodem typu.
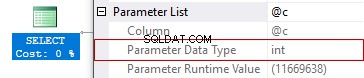
Počet přečtených řádků a odhadovaný počet řádků ke čtení
Plán provádění obsahuje dvě velmi důležité vlastnosti, Skutečný počet řádků a Odhadovaný počet řádků. Tyto vlastnosti obsahují informace o počtu řádků vrácených operátorem čtení dat, ale ne o počtu řádků, které skutečně přečetl. Vlastnosti Počet přečtených řádků a Odhadovaný počet řádků ke čtení odpovídají na tuto otázku a umožňují načíst počet řádků, které server skutečně přečetl nebo se chystá číst. Vlastnost ActualRowsRead (počet řádků přečtených v SSMS) je k dispozici od SQL Server 2012 SP3, 2014 SP2, 2016 SP1. EstimatedRowsRead Vlastnost (Odhadovaný počet řádků ke čtení v SSMS) je k dispozici od SQL Server 2016 SP1.
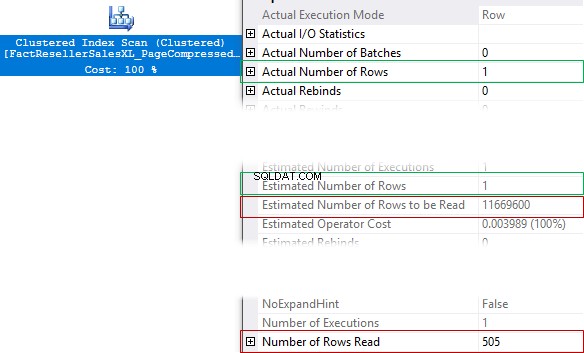
Statistika IO a doba provádění operátora
Existuje několik velmi užitečných vlastností vytvořených v SQL Server 2016, 2014 SP2 a dostupných ve skutečném plánu dotazů. Jsou to metriky IO (pokud má operátor IO) – Statistika aktuální IO, CPU a metriky doby provádění – Statistika skutečného času a metriky paměti (od 2016 SP1, pokud operátor vyžaduje paměť).
Vlastnosti zahrnují následující nové metriky, které lze v případě paralelního plánu rozdělit do vláken:
- Aktuální uplynulé hodiny
- Skutečné CPU
- Aktuální skeny
- ActualLogicalReads
- Aktuální fyzické čtení
- ActualReadAheads
- ActualLobLogicalReads
- ActualLobPhysicalReads
- ActualLobReadAheads
- InputMemoryGrant
- OutputMemoryGrant
- UsedMemoryGrant
Jak můžete vidět z výše uvedeného seznamu, můžete získat komplexní informace o provádění jakéhokoli daného operátoru, spotřebovaném IO a paměti. V posledních verzích SSMS jsou tyto metriky zastoupeny v okně vlastností. Pokud používáte starou verzi SSMS, můžete je načíst otevřením plánu jako XML. Podle mého názoru je nyní k dispozici vše pro zobrazení procent ne podle odhadovaných nákladů, ale podle skutečných uplynulých zdrojů (návrh jsem vytvořil na Connect. Takže, pokud se vám nápad líbí, hlasujte pro něj).
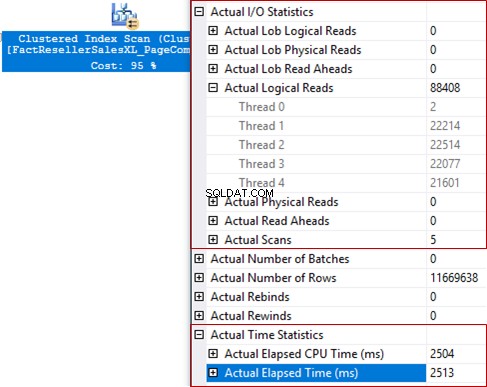
Informace o povolených příznacích trasování
Příznaky trasování v SQL Server jsou speciální „přepínače“ z výchozího chování serveru na jiné chování. Od SQL Server 2014 SP2 a 2016 SP1 jsou informace o povolených příznacích trasování dostupné ve vlastnosti TraceFlags konkrétního prvku. Může zahrnovat až 100 současně povolených příznaků v okamžiku vytváření dotazu.
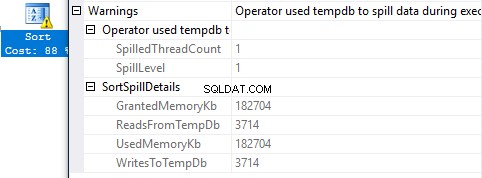
Informace o úniku dat do databáze tempdb
Některé operátory plánu, například Sort nebo Hash Match, vyžadují paměť během provádění dotazu. Objem paměti se však vypočítává v okamžiku kompilace. Z různých důvodů (např. nesprávné vyhodnocení předpokládaného počtu nebo řádků) může být objem paměti vypočítán nesprávně. Pokud je přiděleno méně paměti, než je požadováno pro spuštění, server bude muset přelévat data do databáze tempdb. Zpomaluje provádění dotazu. Upozornění na takovou situaci bylo zavedeno na serveru 2012, ale od SQL Server 2012 SP3, 2014 SP2, 2016 byly diagnostické informace rozšířeny a nyní zahrnují objem rozlitých dat a přečtených dat. Takže můžete vyhodnotit problém a přijmout vhodná opatření.
Závěr
Plán provádění obsahuje spoustu užitečných informací, skutečný plán dotazů obsahuje ještě více informací a skutečný plán dotazů v posledních verzích SQL Server je jen důl užitečných informací. Tento článek není určen k tomu, aby někoho naučil analyzovat plány dotazů. Místo toho jsem zvažoval nejzajímavější vlastnosti plánu, včetně nových nemovitostí a starých, ale podceňovaných. Doufám, že vám tento článek pomůže příště, až budete potřebovat analyzovat výkon dotazu.
Článek byl přeložen týmem Codingsight se svolením autora.
Užitečný nástroj:
dbForge Query Builder pro SQL Server – umožňuje uživatelům rychle a snadno vytvářet složité SQL dotazy prostřednictvím intuitivního vizuálního rozhraní bez ručního psaní kódu.