Je SQL DISTINCT dobré (nebo špatné), když potřebujete odstranit duplikáty ve výsledcích?
Někteří říkají, že je to dobré, a když se objeví duplikáty, přidají DISTINCT. Někteří říkají, že je to špatné, a doporučují používat GROUP BY bez agregační funkce. Jiní říkají, že DISTINCT a GROUP BY jsou stejné, když potřebujete odstranit duplikáty.
Tento příspěvek se ponoří do podrobností, abyste získali správné odpovědi. Nakonec tedy použijete nejlepší klíčové slovo podle potřeby. Začněme.
Krátké připomenutí základů příkazu SQL SELECT DISTINCT
Než se ponoříme hlouběji, připomeňme si, co je příkaz SQL SELECT DISTINCT. Databázová tabulka může obsahovat duplicitní hodnoty z mnoha důvodů, ale můžeme chtít získat pouze jedinečné hodnoty. V tomto případě přijde vhod SELECT DISTINCT. Tato klauzule DISTINCT umožňuje příkazu SELECT načíst pouze jedinečné záznamy.
Syntaxe příkazu je jednoduchá:
SELECT DISTINCT column
FROM table_name
WHERE [condition];Zde je podmínka WHERE volitelná.
Příkaz platí jak pro jeden sloupec, tak pro více sloupců. Syntaxe tohoto příkazu aplikovaného na více sloupců je následující:
SELECT DISTINCT
column_name1,
column_name2,
column_nameN.
FROM
table_name;Všimněte si, že scénář dotazování na několik sloupců navrhne použití kombinace hodnot ve všech sloupcích definovaných příkazem k určení jedinečnosti.
A nyní se podívejme na praktické použití a úlovky použití příkazu SELECT DISTINCT.
Jak SQL DISTINCT funguje při odstraňování duplikátů
Najít odpovědi není tak těžké. SQL Server nám poskytl plány provádění, abychom viděli, jak bude dotaz zpracován, abychom získali potřebné výsledky.
Následující část se zaměřuje na plán provádění při použití DISTINCT. Musíte stisknout Ctrl-M v SQL Server Management Studio před provedením níže uvedených dotazů. Nebo klikněte na Zahrnout skutečný plán provádění z panelu nástrojů.
Plány dotazů v SQL DISTINCT
Začněme porovnáním 2 dotazů. První nebude používat DISTINCT a druhý dotaz ano.
USE AdventureWorks
GO
-- Without DISTINCT. Duplicates included
SELECT Lastname FROM Person.Person;
-- With DISTINCT. Duplicates removed
SELECT DISTINCT Lastname FROM Person.Person;
Zde je plán provedení:
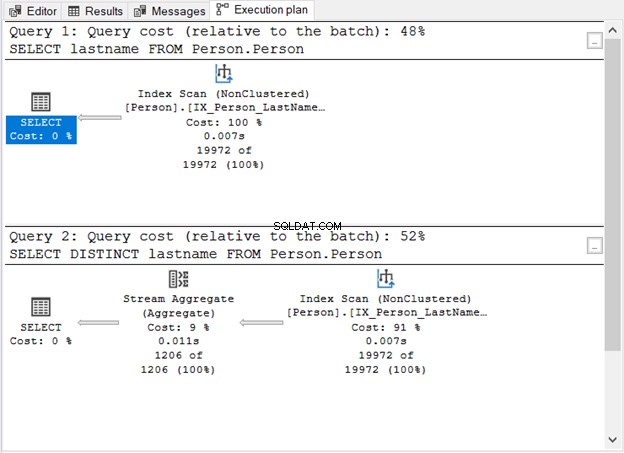
Co nám ukázal obrázek 1?
- Bez klíčového slova DISTINCT je dotaz jednoduchý.
- Po přidání DISTINCT se objeví další krok.
- Náklady na dotaz při použití DISTINCT jsou vyšší než bez něj.
- Oba mají operátory Index Scan. Je to pochopitelné, protože v našich dotazech není žádná konkrétní klauzule WHERE.
- Další krok, operátor Stream Aggregate, se používá k odstranění duplikátů.
Počet logických čtení je stejný (107), pokud zkontrolujete STATISTICS IO. Přesto je počet záznamů značně odlišný. První dotaz vrátí 19 972 řádků. Mezitím druhý dotaz vrátí 1 206 řádků.
Proto nemůžete přidat DISTINCT, kdykoli budete chtít. Ale pokud potřebujete jedinečné hodnoty, je to nezbytná režie.
Pro výstup jedinečných hodnot se používají operátory. Podívejme se na některé z nich.
STREAM AGGREGATE
Toto je operátor, který jste viděli na obrázku 1. Přijímá jeden vstup a vydává agregovaný výsledek. Na obrázku 1 pochází vstup od operátora Index Scan. Stream Aggregate však potřebuje seřazený vstup.
Jak můžete vidět na obrázku 1, používá IX_Person_LastName_FirstName_MiddleName , nejedinečný index jmen. Vzhledem k tomu, že index již řadí záznamy podle názvu, Stream Aggregate přijímá vstup. Bez indexu se může optimalizátor dotazů rozhodnout použít v plánu další operátor řazení. A to bude dražší. Nebo může použít hash Match.
HASH MATCH (AGGREGATE)
Dalším operátorem, který používá DISTINCT, je Hash Match. Tento operátor se používá pro spojení a agregace.
Při použití DISTINCT Hash Match agreguje výsledky a vytváří jedinečné hodnoty. Zde je jeden příklad.
USE AdventureWorks
GO
-- Get unique first names
SELECT DISTINCT Firstname FROM Person.Person;
A zde je plán provedení:
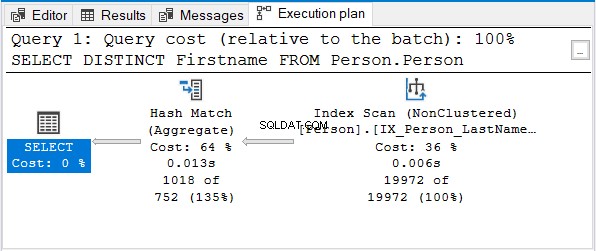
Ale proč ne Stream Aggregate?
Všimněte si, že je použit stejný jmenný index. Tento index se řadí podle Příjmení za prvé. Tedy Jméno pouze dotaz bude netříděný.
Hash Match (Aggregate) je další logickou volbou pro odstranění duplikátů.
HASH MATCH (FLOW DISTINCT)
Hash Match (Aggregate) je operátor blokování. Neprodukuje tedy výstup, který zpracoval celý vstupní tok. Pokud omezíme počet řádků (jako použití TOP s DISTINCT), vytvoří se jedinečný výstup, jakmile budou tyto řádky k dispozici. To je to, o čem je Hash Match (Flow Distinct).
USE AdventureWorks
GO
SELECT DISTINCT TOP 100
sod.ProductID
,soh.OrderDate
,soh.ShipDate
FROM Sales.SalesOrderDetail sod
INNER JOIN Sales.SalesOrderHeader soh ON sod.SalesOrderID = soh.SalesOrderID;
Dotaz používá TOP 100 spolu s DISTINCT. Zde je plán provedení:
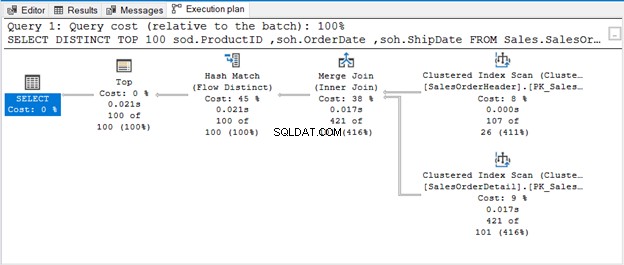
KDYŽ NENÍ ŽÁDNÝ OPERÁTOR, KDYBY DUPLIKÁTY ODESTRANIL
Ano. To se může stát. Zvažte příklad níže.
USE AdventureWorks
GO
SELECT DISTINCT
BusinessEntityID
FROM Person.Person;
Poté zkontrolujte plán provádění:
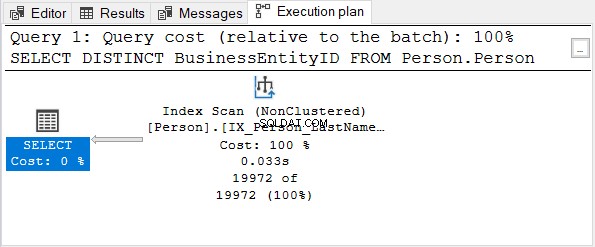
ID obchodní entity sloupec je primární klíč. Vzhledem k tomu, že tento sloupec je již jedinečný, nemá smysl použít DISTINCT. Zkuste odstranit DISTINCT z příkazu SELECT – plán provádění je stejný jako na obrázku 4.
Totéž platí při použití DISTINCT na sloupcích s jedinečným indexem.
SQL DISTINCT funguje pro VŠECHNY sloupce v seznamu SELECT
Doposud jsme v našich příkladech použili pouze 1 sloupec. DISTINCT však funguje pro VŠECHNY sloupce, které zadáte v seznamu SELECT.
Zde je příklad. Tento dotaz zajistí, že hodnoty všech 3 sloupců budou jedinečné.
USE AdventureWorks
GO
SELECT DISTINCT
Lastname
,FirstName
,MiddleName
FROM Person.Person;
Všimněte si prvních několika řádků v sadě výsledků na obrázku 5.
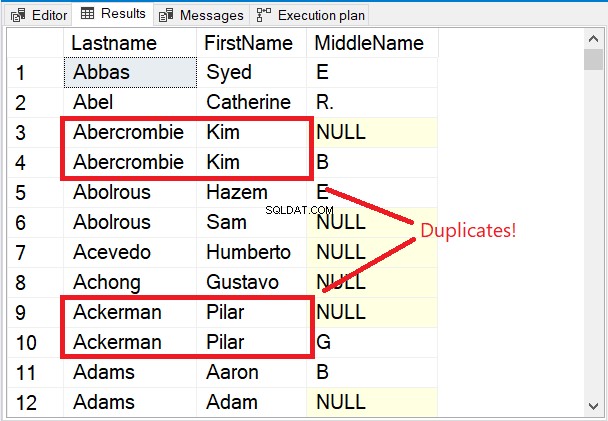
Prvních několik řádků je jedinečných. Klíčové slovo DISTINCT zajistilo, že Prostřední jméno sloupec je také uvažován. Všimněte si 2 jmen označených červeně. S ohledem na Příjmení a Jméno pouze z nich udělá duplikáty. Ale přidání Prostřední jméno mix vše změnil.
Co když chcete získat jedinečná jména a příjmení, ale do výsledku zahrnout prostřední jméno?
Máte 2 možnosti:
- Přidáním klauzule WHERE odstraníte střední jména s hodnotou NULL. Tím se odstraní všechna jména s NULL prostředním jménem.
- Nebo přidejte do Příjmení klauzuli GROUP BY a Jméno sloupců. Poté použijte agregační funkci MIN na Prostřední jméno sloupec. Získáte 1 druhé jméno se stejným příjmením a křestním jménem.
SQL DISTINCT vs. GROUP BY
Při použití GROUP BY bez agregační funkce se chová jako DISTINCT. jak to víme? Jedním ze způsobů, jak to zjistit, je použít příklad.
USE AdventureWorks
GO
-- using DISTINCT
SELECT DISTINCT
soh.TerritoryID
,st.Name
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesTerritory st ON soh.TerritoryID = st.TerritoryID;
-- using GROUP BY
SELECT
soh.TerritoryID
,st.Name
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesTerritory st ON soh.TerritoryID = st.TerritoryID
GROUP BY
soh.TerritoryID
,st.Name;
Spusťte je a podívejte se na plán provádění. Je to jako na obrázku níže?
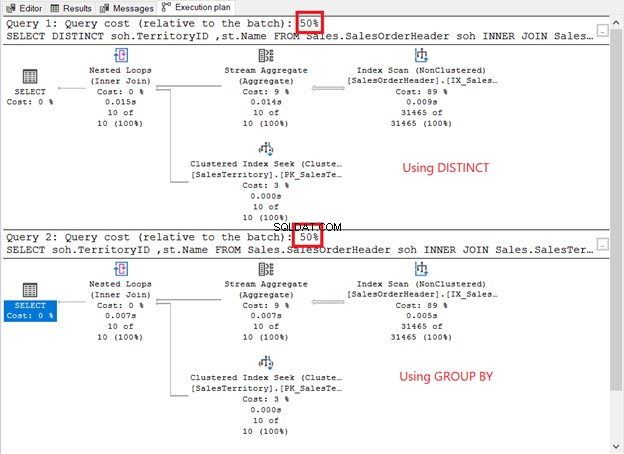
Jak se porovnávají?
- Mají stejné operátory plánu a sekvenci.
- Náklady na operátora a náklady na dotaz jsou stejné.
Pokud zaškrtnete QueryPlanHash vlastnosti 2 operátorů SELECT, jsou stejné. Proto optimalizátor dotazů použil stejný proces k vrácení stejných výsledků.
Nakonec nemůžeme říci, že použití GROUP BY je lepší než DISTINCT v vracení jedinečných hodnot. Můžete to dokázat pomocí výše uvedených příkladů k nahrazení DISTINCT za GROUP BY.
Nyní je otázkou preferencí, které budete používat. Dávám přednost DISTINCT. Explicitně sděluje záměr v dotazu – vytvořit jedinečné výsledky. A pro mě je GROUP BY pro seskupování výsledků pomocí agregační funkce. Tento záměr je také jasný a konzistentní se samotným klíčovým slovem. Nevím, jestli někdo bude jednoho dne udržovat mé dotazy. Kód by tedy měl být jasný.
Ale to není konec příběhu.
Když SQL DISTINCT není totéž jako GROUP BY
Právě jsem vyjádřil svůj názor a pak tohle?
To je pravda. Nebudou stále stejné. Zvažte tento příklad.
-- using DISTINCT
SELECT DISTINCT
soh.TerritoryID
,(SELECT name FROM Sales.SalesTerritory st WHERE st.TerritoryID = soh.TerritoryID) AS TerritoryName
FROM Sales.SalesOrderHeader soh;
-- using GROUP BY
SELECT
soh.TerritoryID
,(SELECT name FROM Sales.SalesTerritory st WHERE st.TerritoryID = soh.TerritoryID) AS TerritoryName
FROM Sales.SalesOrderHeader soh
GROUP BY
soh.TerritoryID;
Přestože je sada výsledků neseřazená, řádky jsou stejné jako v předchozím příkladu. Jediný rozdíl je v použití poddotazu:
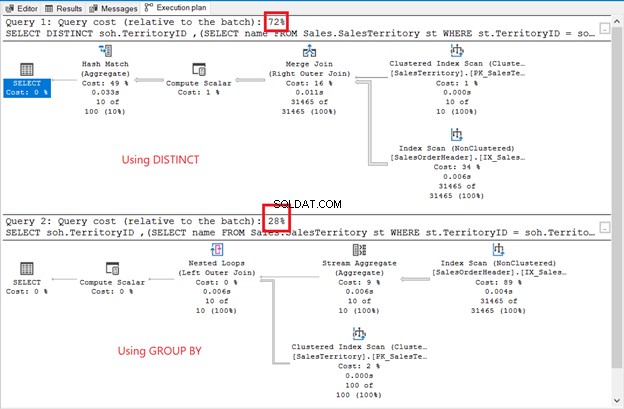
Rozdíly jsou zřejmé:operátoři, náklady na dotaz, celkový plán. Tentokrát vyhrává GROUP BY s pouze 28% náklady na dotaz. Ale o to jde.
Cílem je ukázat vám, že mohou být různé. To je vše. Toto není v žádném případě doporučení. Použití spojení má lepší plán provádění (viz znovu obrázek 6).
Sečteno a podtrženo
Zde je to, co jsme se zatím naučili:
- DISTINCT přidá operátor plánu k odstranění duplikátů.
- DISTINCT a GROUP BY bez agregační funkce vedou ke stejnému plánu. Zkrátka jsou většinu času stejné.
- Někdy mohou mít DISTINCT a GROUP BY různé plány, když je poddotaz zahrnut v seznamu SELECT.
Je tedy SQL DISTINCT dobré nebo špatné při odstraňování duplicitních výsledků?
Výsledky říkají, že je to dobré. Není to lepší ani horší než GROUP BY, protože plány jsou stejné. Ale je dobrým zvykem zkontrolovat plán provádění. Myslete na optimalizaci od začátku. Tímto způsobem, pokud narazíte na nějaké rozdíly v DISTINCT a GROUP BY, zjistíte je.
Kromě toho moderní nástroje tento úkol mnohem zjednodušují. Například oblíbený produkt dbForge SQL Complete od společnosti Devart má specifickou funkci, která vypočítává hodnoty v agregačních funkcích v sadě hotových výsledků v mřížce výsledků SSMS. Jsou tam také hodnoty DISTINCT.
Líbí se vám příspěvek? Pak to prosím rozšiřte sdílením na svých oblíbených platformách sociálních médií.
Související články pro další informace
- SQL GROUP BY:3 snadné tipy pro seskupování výsledků jako profesionál
- SQL INSERT DO SELECT:5 snadných způsobů, jak zvládnout duplikáty
- Co jsou agregační funkce SQL? (Snadné tipy pro nováčky)
- Optimalizace dotazů SQL:5 základních faktů pro zvýšení počtu dotazů