Všechny softwarové aplikace komunikují s daty , nejčastěji prostřednictvím systému správy databází (DBMS). Některé programovací jazyky jsou dodávány s moduly, které můžete použít k interakci s DBMS, zatímco jiné vyžadují použití balíčků třetích stran. V tomto tutoriálu prozkoumáte různé knihovny Python SQL které můžete použít. Vyvinete přímou aplikaci pro interakci s databázemi SQLite, MySQL a PostgreSQL.
V tomto kurzu se dozvíte, jak:
- Připojit do různých systémů správy databází s Python SQL knihovnami
- Interakce s databázemi SQLite, MySQL a PostgreSQL
- Proveďte běžné databázové dotazy pomocí aplikace Python
- Vyvíjet aplikace v různých databázích pomocí skriptu Python
Abyste z tohoto tutoriálu vytěžili maximum, měli byste znát základní jazyk Python, SQL a práci se systémy správy databází. Měli byste také být schopni stahovat a importovat balíčky v Pythonu a vědět, jak nainstalovat a spustit různé databázové servery lokálně nebo vzdáleně.
Bezplatné stažení PDF: Cheat Sheet pro Python 3
Porozumění schématu databáze
V tomto tutoriálu vytvoříte velmi malou databázi pro aplikaci sociálních médií. Databáze se bude skládat ze čtyř tabulek:
userspostscommentslikes
Níže je zobrazen diagram schématu databáze na vysoké úrovni:
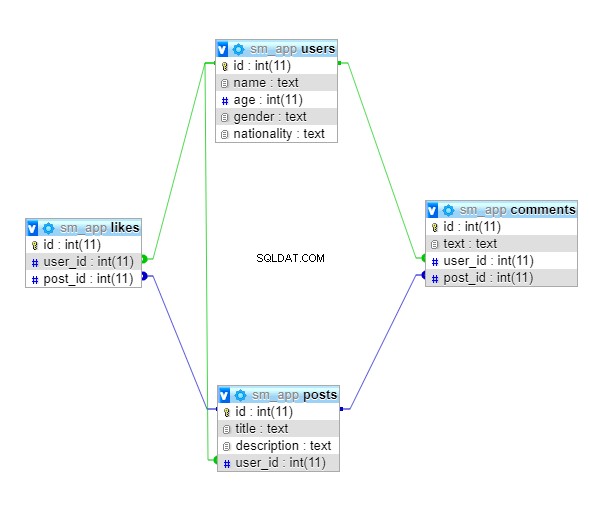
Oba users a posts bude mít vztah jeden k mnoha, protože jeden uživatel může lajkovat mnoho příspěvků. Podobně může jeden uživatel přidávat mnoho komentářů a jeden příspěvek může mít také více komentářů. Tedy oba users a posts bude mít také vztahy jedna k mnoha s comments stůl. To platí také pro likes tabulky, takže oba users a posts bude mít vztah jeden k mnoha s likes tabulka.
Použití knihoven Python SQL k připojení k databázi
Než začnete pracovat s jakoukoli databází prostřednictvím knihovny SQL Python, musíte se připojit do té databáze. V této části uvidíte, jak se připojit k databázím SQLite, MySQL a PostgreSQL z aplikace Python.
Poznámka: Před spuštěním skriptů v sekcích databáze MySQL a PostgreSQL budete potřebovat servery MySQL a PostgreSQL. Rychlý úvod o tom, jak spustit server MySQL, naleznete v části MySQL v části Spuštění projektu Django. Chcete-li se dozvědět, jak vytvořit databázi v PostgreSQL, podívejte se do části Nastavení databáze v tématu Prevence SQL Injection Attacks with Python.
Doporučuje se vytvořit tři různé soubory Pythonu, abyste měli jeden pro každou ze tří databází. Skript spustíte pro každou databázi v jejím odpovídajícím souboru.
SQLite
SQLite je pravděpodobně nejpřímější databáze pro připojení k aplikaci Python, protože k tomu nepotřebujete instalovat žádné externí moduly Python SQL. Ve výchozím nastavení vaše instalace Pythonu obsahuje knihovnu Python SQL s názvem sqlite3 které můžete použít k interakci s databází SQLite.
Databáze SQLite jsou navíc bezserverové a samostatné , protože čtou a zapisují data do souboru. To znamená, že na rozdíl od MySQL a PostgreSQL nemusíte k provádění databázových operací ani instalovat a spouštět SQLite server!
Zde je návod, jak používáte sqlite3 pro připojení k databázi SQLite v Pythonu:
1import sqlite3
2from sqlite3 import Error
3
4def create_connection(path):
5 connection = None
6 try:
7 connection = sqlite3.connect(path)
8 print("Connection to SQLite DB successful")
9 except Error as e:
10 print(f"The error '{e}' occurred")
11
12 return connection
Tento kód funguje takto:
- Řádky 1 a 2 importovat
sqlite3aErrormodulu třída. - Řádek 4 definuje funkci
.create_connection()který přijímá cestu k databázi SQLite. - Řádek 7 používá
.connect()zsqlite3modul a jako parametr bere cestu k databázi SQLite. Pokud databáze v zadaném umístění existuje, je navázáno připojení k databázi. V opačném případě se v zadaném umístění vytvoří nová databáze a naváže se připojení. - Řádek 8 vypíše stav úspěšného připojení k databázi.
- Řádek 9 zachytí všechny výjimky, které by mohly být vyvolány, pokud
.connect()se nepodařilo navázat spojení. - Řádek 10 zobrazí chybovou zprávu v konzole.
sqlite3.connect(path) vrátí connection objekt, který je zase vrácen funkcí create_connection() . Toto connection objekt lze použít k provádění dotazů na databázi SQLite. Následující skript vytvoří připojení k databázi SQLite:
connection = create_connection("E:\\sm_app.sqlite")
Jakmile spustíte výše uvedený skript, uvidíte, že databázový soubor sm_app.sqlite je vytvořen v kořenovém adresáři. Pamatujte, že umístění můžete změnit tak, aby odpovídalo vašemu nastavení.
MySQL
Na rozdíl od SQLite neexistuje žádný výchozí modul Python SQL, který byste mohli použít k připojení k databázi MySQL. Místo toho budete muset nainstalovat ovladač Python SQL pro MySQL za účelem interakce s databází MySQL z aplikace Python. Jedním z takových ovladačů je mysql-connector-python . Tento modul Python SQL si můžete stáhnout pomocí pip :
$ pip install mysql-connector-python
Všimněte si, že MySQL je serverový Systém pro správu databází. Jeden MySQL server může mít více databází. Na rozdíl od SQLite, kde se vytvoření připojení rovná vytvoření databáze, má databáze MySQL proces vytváření databáze ve dvou krocích:
- Navázat spojení na server MySQL.
- Proveďte samostatný dotaz k vytvoření databáze.
Definujte funkci, která se připojí k databázovému serveru MySQL a vrátí objekt připojení:
1import mysql.connector
2from mysql.connector import Error
3
4def create_connection(host_name, user_name, user_password):
5 connection = None
6 try:
7 connection = mysql.connector.connect(
8 host=host_name,
9 user=user_name,
10 passwd=user_password
11 )
12 print("Connection to MySQL DB successful")
13 except Error as e:
14 print(f"The error '{e}' occurred")
15
16 return connection
17
18connection = create_connection("localhost", "root", "")
Ve výše uvedeném skriptu definujete funkci create_connection() který přijímá tři parametry:
- název_hostitele
- uživatelské_jméno
- heslo_uživatele
mysql.connector Python SQL modul obsahuje metodu .connect() který používáte v řádku 7 pro připojení k databázovému serveru MySQL. Jakmile je spojení navázáno, connection objekt je vrácen volající funkci. Nakonec v řádku 18 zavoláte create_connection() s názvem hostitele, uživatelským jménem a heslem.
Zatím jste pouze navázali spojení. Databáze ještě není vytvořena. Chcete-li to provést, definujete další funkci create_database() který přijímá dva parametry:
connectionjeconnectionobjekt k databázovému serveru, se kterým chcete komunikovat.queryje dotaz, který vytváří databázi.
Zde je návod, jak tato funkce vypadá:
def create_database(connection, query):
cursor = connection.cursor()
try:
cursor.execute(query)
print("Database created successfully")
except Error as e:
print(f"The error '{e}' occurred")
K provádění dotazů se používá cursor objekt. query který má být proveden, je předán do cursor.execute() ve formátu řetězce.
Vytvořte databázi s názvem sm_app pro vaši aplikaci sociálních médií na databázovém serveru MySQL:
create_database_query = "CREATE DATABASE sm_app"
create_database(connection, create_database_query)
Nyní jste vytvořili databázi sm_app na databázovém serveru. Nicméně connection objekt vrácený funkcí create_connection() je připojen k databázovému serveru MySQL. Musíte se připojit k sm_app databáze. Chcete-li tak učinit, můžete upravit create_connection() takto:
1def create_connection(host_name, user_name, user_password, db_name):
2 connection = None
3 try:
4 connection = mysql.connector.connect(
5 host=host_name,
6 user=user_name,
7 passwd=user_password,
8 database=db_name
9 )
10 print("Connection to MySQL DB successful")
11 except Error as e:
12 print(f"The error '{e}' occurred")
13
14 return connection
Na řádku 8 vidíte, že create_connection() nyní přijímá další parametr s názvem db_name . Tento parametr určuje název databáze, ke které se chcete připojit. Při volání této funkce můžete zadat název databáze, ke které se chcete připojit:
connection = create_connection("localhost", "root", "", "sm_app")
Výše uvedený skript úspěšně volá create_connection() a připojí se k sm_app databáze.
PostgreSQL
Stejně jako MySQL neexistuje žádná výchozí knihovna Python SQL, kterou byste mohli použít k interakci s databází PostgreSQL. Místo toho je třeba nainstalovat ovladač jazyka Python SQL třetí strany pro interakci s PostgreSQL. Jedním takovým ovladačem Python SQL pro PostgreSQL je psycopg2 . Spuštěním následujícího příkazu na svém terminálu nainstalujte psycopg2 Modul Python SQL:
$ pip install psycopg2
Stejně jako u databází SQLite a MySQL definujete create_connection() pro navázání spojení s vaší PostgreSQL databází:
import psycopg2
from psycopg2 import OperationalError
def create_connection(db_name, db_user, db_password, db_host, db_port):
connection = None
try:
connection = psycopg2.connect(
database=db_name,
user=db_user,
password=db_password,
host=db_host,
port=db_port,
)
print("Connection to PostgreSQL DB successful")
except OperationalError as e:
print(f"The error '{e}' occurred")
return connection
Používáte psycopg2.connect() pro připojení k serveru PostgreSQL z vaší aplikace Python.
Poté můžete použít create_connection() pro vytvoření připojení k databázi PostgreSQL. Nejprve se připojíte k výchozí databázi postgres pomocí následujícího řetězce:
connection = create_connection(
"postgres", "postgres", "abc123", "127.0.0.1", "5432"
)
Dále musíte vytvořit databázi sm_app uvnitř výchozího postgres databáze. Můžete definovat funkci pro provedení libovolného SQL dotazu v PostgreSQL. Níže definujete create_database() pro vytvoření nové databáze na databázovém serveru PostgreSQL:
def create_database(connection, query):
connection.autocommit = True
cursor = connection.cursor()
try:
cursor.execute(query)
print("Query executed successfully")
except OperationalError as e:
print(f"The error '{e}' occurred")
create_database_query = "CREATE DATABASE sm_app"
create_database(connection, create_database_query)
Po spuštění výše uvedeného skriptu uvidíte sm_app databáze na vašem databázovém serveru PostgreSQL.
Než spustíte dotazy na sm_app databáze, musíte se k ní připojit:
connection = create_connection(
"sm_app", "postgres", "abc123", "127.0.0.1", "5432"
)
Po provedení výše uvedeného skriptu bude navázáno spojení s sm_app databázi umístěnou v postgres databázový server. Zde 127.0.0.1 odkazuje na IP adresu hostitele databázového serveru a 5432 odkazuje na číslo portu databázového serveru.
Vytváření tabulek
V předchozí části jste viděli, jak se připojit k databázovým serverům SQLite, MySQL a PostgreSQL pomocí různých Python SQL knihoven. Vytvořili jste sm_app databáze na všech třech databázových serverech. V této části uvidíte, jak vytvářet tabulky uvnitř těchto tří databází.
Jak bylo uvedeno výše, vytvoříte čtyři tabulky:
userspostscommentslikes
Začnete s SQLite.
SQLite
Chcete-li spouštět dotazy v SQLite, použijte cursor.execute() . V této sekci definujete funkci execute_query() která používá tuto metodu. Vaše funkce přijme connection objekt a řetězec dotazu, který předáte cursor.execute() .
.execute() může provést jakýkoli dotaz, který mu byl předán ve formě řetězce. Tuto metodu použijete k vytvoření tabulek v této části. V nadcházejících částech použijete stejnou metodu k provádění aktualizací a mazání dotazů.
Poznámka: Tento skript by měl být spuštěn ve stejném souboru, ve kterém jste vytvořili připojení pro vaši databázi SQLite.
Zde je definice vaší funkce:
def execute_query(connection, query):
cursor = connection.cursor()
try:
cursor.execute(query)
connection.commit()
print("Query executed successfully")
except Error as e:
print(f"The error '{e}' occurred")
Tento kód se pokusí provést daný query a v případě potřeby vytiskne chybovou zprávu.
Dále napište svůj dotaz :
create_users_table = """
CREATE TABLE IF NOT EXISTS users (
id INTEGER PRIMARY KEY AUTOINCREMENT,
name TEXT NOT NULL,
age INTEGER,
gender TEXT,
nationality TEXT
);
"""
To říká vytvořit tabulku users s následujícími pěti sloupci:
idnameagegendernationality
Nakonec zavoláte execute_query() k vytvoření tabulky. Projdete v connection objekt, který jste vytvořili v předchozí části, spolu s create_users_table řetězec, který obsahuje dotaz na vytvoření tabulky:
execute_query(connection, create_users_table)
K vytvoření posts se používá následující dotaz tabulka:
create_posts_table = """
CREATE TABLE IF NOT EXISTS posts(
id INTEGER PRIMARY KEY AUTOINCREMENT,
title TEXT NOT NULL,
description TEXT NOT NULL,
user_id INTEGER NOT NULL,
FOREIGN KEY (user_id) REFERENCES users (id)
);
"""
Protože mezi users existuje vztah jedna k mnoha a posts , můžete vidět cizí klíč user_id v posts tabulka, která odkazuje na id ve sloupci users stůl. Pro vytvoření posts spusťte následující skript tabulka:
execute_query(connection, create_posts_table)
Nakonec můžete vytvořit comments a likes tabulky s následujícím skriptem:
create_comments_table = """
CREATE TABLE IF NOT EXISTS comments (
id INTEGER PRIMARY KEY AUTOINCREMENT,
text TEXT NOT NULL,
user_id INTEGER NOT NULL,
post_id INTEGER NOT NULL,
FOREIGN KEY (user_id) REFERENCES users (id) FOREIGN KEY (post_id) REFERENCES posts (id)
);
"""
create_likes_table = """
CREATE TABLE IF NOT EXISTS likes (
id INTEGER PRIMARY KEY AUTOINCREMENT,
user_id INTEGER NOT NULL,
post_id integer NOT NULL,
FOREIGN KEY (user_id) REFERENCES users (id) FOREIGN KEY (post_id) REFERENCES posts (id)
);
"""
execute_query(connection, create_comments_table)
execute_query(connection, create_likes_table)
Můžete vidět, že vytváření tabulek v SQLite je velmi podobný použití raw SQL. Vše, co musíte udělat, je uložit dotaz do řetězcové proměnné a poté tuto proměnnou předat do cursor.execute() .
MySQL
Použijete mysql-connector-python Python SQL modul pro vytváření tabulek v MySQL. Stejně jako u SQLite musíte svůj dotaz předat do cursor.execute() , která je vrácena voláním .cursor() na connection objekt. Můžete vytvořit další funkci execute_query() který přijímá connection a query řetězec:
1def execute_query(connection, query):
2 cursor = connection.cursor()
3 try:
4 cursor.execute(query)
5 connection.commit()
6 print("Query executed successfully")
7 except Error as e:
8 print(f"The error '{e}' occurred")
Na řádku 4 předáte query na cursor.execute() .
Nyní můžete vytvářet své users tabulky pomocí této funkce:
create_users_table = """
CREATE TABLE IF NOT EXISTS users (
id INT AUTO_INCREMENT,
name TEXT NOT NULL,
age INT,
gender TEXT,
nationality TEXT,
PRIMARY KEY (id)
) ENGINE = InnoDB
"""
execute_query(connection, create_users_table)
Dotaz na implementaci vztahu cizího klíče se v MySQL ve srovnání s SQLite mírně liší. A co víc, MySQL používá AUTO_INCREMENT klíčové slovo (ve srovnání s SQLite AUTOINCREMENT klíčové slovo), chcete-li vytvořit sloupce, ve kterých se hodnoty automaticky zvyšují při vkládání nových záznamů.
Následující skript vytvoří posts tabulka, která obsahuje cizí klíč user_id který odkazuje na id sloupec users tabulka:
create_posts_table = """
CREATE TABLE IF NOT EXISTS posts (
id INT AUTO_INCREMENT,
title TEXT NOT NULL,
description TEXT NOT NULL,
user_id INTEGER NOT NULL,
FOREIGN KEY fk_user_id (user_id) REFERENCES users(id),
PRIMARY KEY (id)
) ENGINE = InnoDB
"""
execute_query(connection, create_posts_table)
Podobně vytvořte comments a likes tabulky, můžete předat odpovídající CREATE dotazy na execute_query() .
PostgreSQL
Stejně jako u databází SQLite a MySQL, connection objekt, který vrací psycopg2.connect() obsahuje cursor objekt. Můžete použít cursor.execute() spouštět dotazy Python SQL ve vaší databázi PostgreSQL.
Definujte funkci execute_query() :
def execute_query(connection, query):
connection.autocommit = True
cursor = connection.cursor()
try:
cursor.execute(query)
print("Query executed successfully")
except OperationalError as e:
print(f"The error '{e}' occurred")
Tuto funkci můžete použít k vytváření tabulek, vkládání záznamů, úpravě záznamů a mazání záznamů ve vaší databázi PostgreSQL.
Nyní vytvořte users tabulky v sm_app databáze:
create_users_table = """
CREATE TABLE IF NOT EXISTS users (
id SERIAL PRIMARY KEY,
name TEXT NOT NULL,
age INTEGER,
gender TEXT,
nationality TEXT
)
"""
execute_query(connection, create_users_table)
Můžete vidět, že dotaz na vytvoření users tabulka v PostgreSQL se mírně liší od SQLite a MySQL. Zde klíčové slovo SERIAL se používá k vytváření sloupců, které se automaticky zvyšují. Připomeňme, že MySQL používá klíčové slovo AUTO_INCREMENT .
Kromě toho je odkazování na cizí klíč také specifikováno jinak, jak ukazuje následující skript, který vytváří posts tabulka:
create_posts_table = """
CREATE TABLE IF NOT EXISTS posts (
id SERIAL PRIMARY KEY,
title TEXT NOT NULL,
description TEXT NOT NULL,
user_id INTEGER REFERENCES users(id)
)
"""
execute_query(connection, create_posts_table)
Chcete-li vytvořit comments tabulky, budete muset napsat CREATE dotaz na comments tabulku a předejte ji execute_query() . Proces vytváření likes tabulka je stejná. Musíte pouze upravit CREATE dotaz k vytvoření likes místo comments tabulka.
Vkládání záznamů
V předchozí části jste viděli, jak vytvořit tabulky ve vašich databázích SQLite, MySQL a PostgreSQL pomocí různých modulů Python SQL. V této části uvidíte, jak vložit záznamy do vašich tabulek.
SQLite
Chcete-li vložit záznamy do databáze SQLite, můžete použít stejné execute_query() funkce, kterou jste použili k vytvoření tabulek. Nejprve si musíte uložit INSERT INTO dotaz v řetězci. Poté můžete předat connection objekt a query řetězec na execute_query() . Do users vložíme pět záznamů tabulka:
create_users = """
INSERT INTO
users (name, age, gender, nationality)
VALUES
('James', 25, 'male', 'USA'),
('Leila', 32, 'female', 'France'),
('Brigitte', 35, 'female', 'England'),
('Mike', 40, 'male', 'Denmark'),
('Elizabeth', 21, 'female', 'Canada');
"""
execute_query(connection, create_users)
Protože jste nastavili id sloupec na automatické zvýšení, nemusíte zadávat hodnotu id sloupec pro tyto users . users tabulka automaticky vyplní těchto pět záznamů pomocí id hodnoty od 1 až 5 .
Nyní vložte šest záznamů do posts tabulka:
create_posts = """
INSERT INTO
posts (title, description, user_id)
VALUES
("Happy", "I am feeling very happy today", 1),
("Hot Weather", "The weather is very hot today", 2),
("Help", "I need some help with my work", 2),
("Great News", "I am getting married", 1),
("Interesting Game", "It was a fantastic game of tennis", 5),
("Party", "Anyone up for a late-night party today?", 3);
"""
execute_query(connection, create_posts)
Je důležité zmínit, že user_id sloupec posts tabulka je cizí klíč který odkazuje na id sloupec users stůl. To znamená, že user_id sloupec musí obsahovat hodnotu, která již existuje v id sloupec users stůl. Pokud neexistuje, zobrazí se chyba.
Podobně následující skript vkládá záznamy do comments a likes tabulky:
create_comments = """
INSERT INTO
comments (text, user_id, post_id)
VALUES
('Count me in', 1, 6),
('What sort of help?', 5, 3),
('Congrats buddy', 2, 4),
('I was rooting for Nadal though', 4, 5),
('Help with your thesis?', 2, 3),
('Many congratulations', 5, 4);
"""
create_likes = """
INSERT INTO
likes (user_id, post_id)
VALUES
(1, 6),
(2, 3),
(1, 5),
(5, 4),
(2, 4),
(4, 2),
(3, 6);
"""
execute_query(connection, create_comments)
execute_query(connection, create_likes)
V obou případech uložíte INSERT INTO dotaz jako řetězec a spusťte jej pomocí execute_query() .
MySQL
Existují dva způsoby, jak vložit záznamy do databází MySQL z aplikace Python. První přístup je podobný SQLite. Můžete uložit INSERT INTO zadejte dotaz do řetězce a poté použijte cursor.execute() vkládat záznamy.
Dříve jste definovali funkci wrapper execute_query() které jste použili k vkládání záznamů. Tuto stejnou funkci nyní můžete použít k vkládání záznamů do vaší tabulky MySQL. Následující skript vloží záznamy do users tabulky pomocí execute_query() :
create_users = """
INSERT INTO
`users` (`name`, `age`, `gender`, `nationality`)
VALUES
('James', 25, 'male', 'USA'),
('Leila', 32, 'female', 'France'),
('Brigitte', 35, 'female', 'England'),
('Mike', 40, 'male', 'Denmark'),
('Elizabeth', 21, 'female', 'Canada');
"""
execute_query(connection, create_users)
Druhý přístup používá cursor.executemany() , který přijímá dva parametry:
- Dotaz řetězec obsahující zástupné symboly pro záznamy, které mají být vloženy
- Seznam záznamů, které chcete vložit
Podívejte se na následující příklad, který vkládá dva záznamy do likes tabulka:
sql = "INSERT INTO likes ( user_id, post_id ) VALUES ( %s, %s )"
val = [(4, 5), (3, 4)]
cursor = connection.cursor()
cursor.executemany(sql, val)
connection.commit()
Je jen na vás, jaký přístup zvolíte pro vkládání záznamů do tabulky MySQL. Pokud jste odborníkem na SQL, můžete použít .execute() . Pokud nejste příliš obeznámeni s SQL, může být pro vás jednodušší použít .executemany() . Pomocí kteréhokoli z těchto dvou přístupů můžete úspěšně vkládat záznamy do posts , comments a likes tabulky.
PostgreSQL
V předchozí části jste viděli dva přístupy pro vkládání záznamů do databázových tabulek SQLite. První používá dotaz na řetězec SQL a druhý používá .executemany() . psycopg2 následuje tento druhý přístup, ačkoli .execute() se používá k provedení dotazu založeného na zástupném symbolu.
SQL dotaz se zástupnými symboly a seznamem záznamů předáte do .execute() . Každý záznam v seznamu bude n-tice, kde hodnoty n-tice odpovídají hodnotám sloupců v databázové tabulce. Zde je návod, jak můžete vložit uživatelské záznamy do users tabulka v databázi PostgreSQL:
users = [
("James", 25, "male", "USA"),
("Leila", 32, "female", "France"),
("Brigitte", 35, "female", "England"),
("Mike", 40, "male", "Denmark"),
("Elizabeth", 21, "female", "Canada"),
]
user_records = ", ".join(["%s"] * len(users))
insert_query = (
f"INSERT INTO users (name, age, gender, nationality) VALUES {user_records}"
)
connection.autocommit = True
cursor = connection.cursor()
cursor.execute(insert_query, users)
Výše uvedený skript vytvoří seznam users který obsahuje pět uživatelských záznamů ve formě n-tic. Dále vytvoříte zástupný řetězec s pěti zástupnými prvky (%s ), které odpovídají pěti uživatelským záznamům. Řetězec zástupného symbolu je zřetězen s dotazem, který vkládá záznamy do users stůl. Nakonec je řetězec dotazu a uživatelské záznamy předány .execute() . Výše uvedený skript úspěšně vloží pět záznamů do users tabulka.
Podívejte se na další příklad vkládání záznamů do PostgreSQL tabulky. Následující skript vloží záznamy do posts tabulka:
posts = [
("Happy", "I am feeling very happy today", 1),
("Hot Weather", "The weather is very hot today", 2),
("Help", "I need some help with my work", 2),
("Great News", "I am getting married", 1),
("Interesting Game", "It was a fantastic game of tennis", 5),
("Party", "Anyone up for a late-night party today?", 3),
]
post_records = ", ".join(["%s"] * len(posts))
insert_query = (
f"INSERT INTO posts (title, description, user_id) VALUES {post_records}"
)
connection.autocommit = True
cursor = connection.cursor()
cursor.execute(insert_query, posts)
Záznamy můžete vkládat do comments a likes tabulky se stejným přístupem.
Výběr záznamů
V této části uvidíte, jak vybrat záznamy z databázových tabulek pomocí různých modulů Python SQL. Zejména uvidíte, jak provést SELECT dotazy na vaše databáze SQLite, MySQL a PostgreSQL.
SQLite
Pro výběr záznamů pomocí SQLite můžete opět použít cursor.execute() . Až to však uděláte, budete muset zavolat .fetchall() . Tato metoda vrací seznam n-tic, kde je každá n-tice mapována na odpovídající řádek v načtených záznamech.
Pro zjednodušení procesu můžete vytvořit funkci execute_read_query() :
def execute_read_query(connection, query):
cursor = connection.cursor()
result = None
try:
cursor.execute(query)
result = cursor.fetchall()
return result
except Error as e:
print(f"The error '{e}' occurred")
Tato funkce přijímá connection objekt a SELECT dotaz a vrátí vybraný záznam.
SELECT
Nyní vybereme všechny záznamy z users tabulka:
select_users = "SELECT * from users"
users = execute_read_query(connection, select_users)
for user in users:
print(user)
Ve výše uvedeném skriptu SELECT dotaz vybere všechny uživatele z users stůl. Toto je předáno do execute_read_query() , který vrací všechny záznamy od users stůl. Záznamy jsou poté procházeny a vytištěny na konzoli.
Poznámka: Nedoporučuje se používat SELECT * na velkých tabulkách, protože to může vést k velkému počtu I/O operací, které zvyšují síťový provoz.
Výstup výše uvedeného dotazu vypadá takto:
(1, 'James', 25, 'male', 'USA')
(2, 'Leila', 32, 'female', 'France')
(3, 'Brigitte', 35, 'female', 'England')
(4, 'Mike', 40, 'male', 'Denmark')
(5, 'Elizabeth', 21, 'female', 'Canada')
Stejným způsobem můžete získat všechny záznamy z posts tabulka s níže uvedeným skriptem:
select_posts = "SELECT * FROM posts"
posts = execute_read_query(connection, select_posts)
for post in posts:
print(post)
Výstup vypadá takto:
(1, 'Happy', 'I am feeling very happy today', 1)
(2, 'Hot Weather', 'The weather is very hot today', 2)
(3, 'Help', 'I need some help with my work', 2)
(4, 'Great News', 'I am getting married', 1)
(5, 'Interesting Game', 'It was a fantastic game of tennis', 5)
(6, 'Party', 'Anyone up for a late-night party today?', 3)
Výsledek zobrazuje všechny záznamy v posts tabulka.
JOIN
Můžete také provádět složité dotazy zahrnující JOIN operace k načtení dat ze dvou souvisejících tabulek. Například následující skript vrátí ID a jména uživatelů spolu s popisem příspěvků, které tito uživatelé zveřejnili:
select_users_posts = """
SELECT
users.id,
users.name,
posts.description
FROM
posts
INNER JOIN users ON users.id = posts.user_id
"""
users_posts = execute_read_query(connection, select_users_posts)
for users_post in users_posts:
print(users_post)
Here’s the output:
(1, 'James', 'I am feeling very happy today')
(2, 'Leila', 'The weather is very hot today')
(2, 'Leila', 'I need some help with my work')
(1, 'James', 'I am getting married')
(5, 'Elizabeth', 'It was a fantastic game of tennis')
(3, 'Brigitte', 'Anyone up for a late night party today?')
You can also select data from three related tables by implementing multiple JOIN operators . The following script returns all posts, along with the comments on the posts and the names of the users who posted the comments:
select_posts_comments_users = """
SELECT
posts.description as post,
text as comment,
name
FROM
posts
INNER JOIN comments ON posts.id = comments.post_id
INNER JOIN users ON users.id = comments.user_id
"""
posts_comments_users = execute_read_query(
connection, select_posts_comments_users
)
for posts_comments_user in posts_comments_users:
print(posts_comments_user)
The output looks like this:
('Anyone up for a late night party today?', 'Count me in', 'James')
('I need some help with my work', 'What sort of help?', 'Elizabeth')
('I am getting married', 'Congrats buddy', 'Leila')
('It was a fantastic game of tennis', 'I was rooting for Nadal though', 'Mike')
('I need some help with my work', 'Help with your thesis?', 'Leila')
('I am getting married', 'Many congratulations', 'Elizabeth')
You can see from the output that the column names are not being returned by .fetchall() . To return column names, you can use the .description attribute of the cursor objekt. For instance, the following list returns all the column names for the above query:
cursor = connection.cursor()
cursor.execute(select_posts_comments_users)
cursor.fetchall()
column_names = [description[0] for description in cursor.description]
print(column_names)
The output looks like this:
['post', 'comment', 'name']
You can see the names of the columns for the given query.
WHERE
Now you’ll execute a SELECT query that returns the post, along with the total number of likes that the post received:
select_post_likes = """
SELECT
description as Post,
COUNT(likes.id) as Likes
FROM
likes,
posts
WHERE
posts.id = likes.post_id
GROUP BY
likes.post_id
"""
post_likes = execute_read_query(connection, select_post_likes)
for post_like in post_likes:
print(post_like)
The output is as follows:
('The weather is very hot today', 1)
('I need some help with my work', 1)
('I am getting married', 2)
('It was a fantastic game of tennis', 1)
('Anyone up for a late night party today?', 2)
By using a WHERE clause, you’re able to return more specific results.
MySQL
The process of selecting records in MySQL is absolutely identical to selecting records in SQLite. You can use cursor.execute() followed by .fetchall() . The following script creates a wrapper function execute_read_query() that you can use to select records:
def execute_read_query(connection, query):
cursor = connection.cursor()
result = None
try:
cursor.execute(query)
result = cursor.fetchall()
return result
except Error as e:
print(f"The error '{e}' occurred")
Now select all the records from the users tabulka:
select_users = "SELECT * FROM users"
users = execute_read_query(connection, select_users)
for user in users:
print(user)
The output will be similar to what you saw with SQLite.
PostgreSQL
The process of selecting records from a PostgreSQL table with the psycopg2 Python SQL module is similar to what you did with SQLite and MySQL. Again, you’ll use cursor.execute() followed by .fetchall() to select records from your PostgreSQL table. The following script selects all the records from the users table and prints them to the console:
def execute_read_query(connection, query):
cursor = connection.cursor()
result = None
try:
cursor.execute(query)
result = cursor.fetchall()
return result
except OperationalError as e:
print(f"The error '{e}' occurred")
select_users = "SELECT * FROM users"
users = execute_read_query(connection, select_users)
for user in users:
print(user)
Again, the output will be similar to what you’ve seen before.
Updating Table Records
In the last section, you saw how to select records from SQLite, MySQL, and PostgreSQL databases. In this section, you’ll cover the process for updating records using the Python SQL libraries for SQLite, PostgresSQL, and MySQL.
SQLite
Updating records in SQLite is pretty straightforward. You can again make use of execute_query() . As an example, you can update the description of the post with an id z 2 . First, SELECT the description of this post:
select_post_description = "SELECT description FROM posts WHERE id = 2"
post_description = execute_read_query(connection, select_post_description)
for description in post_description:
print(description)
You should see the following output:
('The weather is very hot today',)
The following script updates the description:
update_post_description = """
UPDATE
posts
SET
description = "The weather has become pleasant now"
WHERE
id = 2
"""
execute_query(connection, update_post_description)
Now, if you execute the SELECT query again, you should see the following result:
('The weather has become pleasant now',)
The output has been updated.
MySQL
The process of updating records in MySQL with mysql-connector-python is also a carbon copy of the sqlite3 Python SQL module. You need to pass the string query to cursor.execute() . For example, the following script updates the description of the post with an id z 2 :
update_post_description = """
UPDATE
posts
SET
description = "The weather has become pleasant now"
WHERE
id = 2
"""
execute_query(connection, update_post_description)
Again, you’ve used your wrapper function execute_query() to update the post description.
PostgreSQL
The update query for PostgreSQL is similar to what you’ve seen with SQLite and MySQL. You can use the above scripts to update records in your PostgreSQL table.
Deleting Table Records
In this section, you’ll see how to delete table records using the Python SQL modules for SQLite, MySQL, and PostgreSQL databases. The process of deleting records is uniform for all three databases since the DELETE query for the three databases is the same.
SQLite
You can again use execute_query() to delete records from YOUR SQLite database. All you have to do is pass the connection object and the string query for the record you want to delete to execute_query() . Then, execute_query() will create a cursor object using the connection and pass the string query to cursor.execute() , which will delete the records.
As an example, try to delete the comment with an id of 5 :
delete_comment = "DELETE FROM comments WHERE id = 5"
execute_query(connection, delete_comment)
Now, if you select all the records from the comments table, you’ll see that the fifth comment has been deleted.
MySQL
The process for deletion in MySQL is also similar to SQLite, as shown in the following example:
delete_comment = "DELETE FROM comments WHERE id = 2"
execute_query(connection, delete_comment)
Here, you delete the second comment from the sm_app database’s comments table in your MySQL database server.
PostgreSQL
The delete query for PostgreSQL is also similar to SQLite and MySQL. You can write a delete query string by using the DELETE keyword and then passing the query and the connection object to execute_query() . This will delete the specified records from your PostgreSQL database.
Conclusion
In this tutorial, you’ve learned how to use three common Python SQL libraries. sqlite3 , mysql-connector-python , and psycopg2 allow you to connect a Python application to SQLite, MySQL, and PostgreSQL databases, respectively.
Now you can:
- Interact with SQLite, MySQL, or PostgreSQL databases
- Use three different Python SQL modules
- Execute SQL queries on various databases from within a Python application
However, this is just the tip of the iceberg! There are also Python SQL libraries for object-relational mapping , such as SQLAlchemy and Django ORM, that automate the task of database interaction in Python. You’ll learn more about these libraries in other tutorials in our Python databases section.