Chcete se naučit navrhovat databázový systém a mapovat obchodní proces na datový model? Pak je tento příspěvek právě pro vás.
V tomto článku uvidíte, jak navrhnout jednoduché schéma databáze pro personální společnost. Po přečtení tohoto kurzu budete schopni porozumět tomu, jak jsou databázová schémata navržena pro aplikace v reálném světě.
Obchodní proces náborového systému
Před návrhem jakékoli databáze nebo datového modelu je nezbytné porozumět základnímu obchodnímu procesu pro tento systém. Databázové schéma, které vytvoříme, je pro imaginární personální společnost nebo tým. Nejprve se podívejme na kroky spojené s náborem nových zaměstnanců:
- Společnosti se obrátí na personální agentury, aby najímaly jejich jménem. V některých případech společnosti nabírají zaměstnance přímo.
- Osoba odpovědná za nábor zahájí proces náboru. Tento proces může mít více kroků, jako je úvodní screening, písemný test, první pohovor, následný pohovor, skutečné rozhodnutí o přijetí atd.
- Jakmile se náboráři dohodnou na konkrétním procesu – a ten se může změnit v závislosti na klientovi, společnosti nebo dané práci – je volná pozice inzerována na různých platformách.
- Uchazeči se začnou ucházet o práci.
- Uchazeči jsou zařazeni do užšího výběru a pozváni na test nebo úvodní pohovor.
- Uchazeči se dostaví na test/pohovor.
- Testy hodnotí náboráři. V některých případech jsou testy předány specialistům k hodnocení.
- Pohovory s uchazeči jsou bodovány jedním nebo více náborovými pracovníky.
- Uchazeči jsou hodnoceni na základě testů a pohovorů.
- Je učiněno rozhodnutí o přijetí.
Schéma databáze náborového systému
S ohledem na výše uvedený proces je naše schéma databáze rozděleno do pěti tematických oblastí:
ProcessJobsApplication, Applicant, and DocumentsTest and InterviewsRecruiters and Application Evaluation
Každou z těchto oblastí podrobně zkontrolujeme v pořadí, v jakém jsou uvedeny. Níže si můžete prohlédnout celý datový model.
Proces
Kategorie procesu obsahuje informace související s náborovými procesy. Obsahuje tři tabulky:process , step a process_step . Podíváme se na každý z nich.
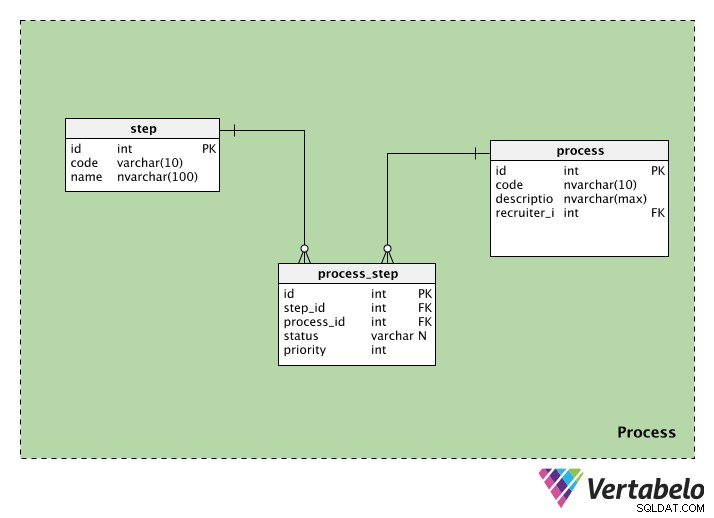
process tabulka ukládá informace o každém náborovém procesu. Každý proces bude mít speciální id, kód a description toho procesu. Budeme mít také recruiter_id osoby, která proces iniciuje.
step tabulka obsahuje informace o krocích provedených během tohoto náborového procesu. Každý krok má id a code název. Sloupec názvu může obsahovat hodnoty jako „úvodní prověrka“, „písemný test“, „HR rozhovor“ atd.
Protože jeden proces může mít více kroků a jeden krok může být součástí mnoha procesů, potřebujeme vyhledávací tabulku. process_step tabulka obsahuje informace o každém kroku (v step_id ) a proces, ke kterému patří (v process_id ). Máme také stav, který nám říká stav tohoto kroku v tomto procesu; toto může být NULL, pokud krok ještě nebyl spuštěn. Nakonec máme priority , který nám říká, v jakém pořadí se mají kroky provést. Kroky s nejvyšší priority hodnota bude provedena jako první.
Zaměstnání
Dále máme Jobs předmětová oblast, ve které jsou uloženy všechny informace související s prací, pro kterou přijímáme nábor. Schéma pro tuto kategorii vypadá takto:
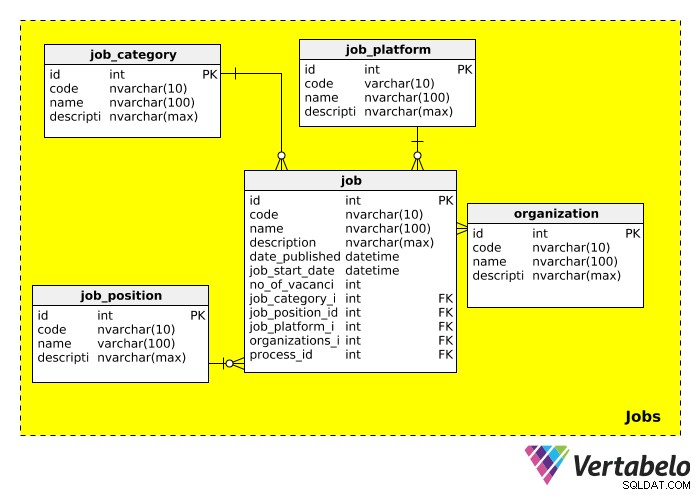
Pojďme si každou z tabulek podrobně vysvětlit.
job_category tabulka široce popisuje typ práce. Mohli bychom očekávat pracovní kategorie jako „IT“, „management“, „finance“, „vzdělávání“ atd.
job_position tabulka obsahuje aktuální pracovní pozici. Vzhledem k tomu, že jeden titul lze inzerovat pro více pracovních pozic (např. „IT Manager“, „Manažer prodeje“), vytvořili jsme samostatnou tabulku pro pracovní pozice. Můžeme očekávat, že v této tabulce uvidíme hodnoty jako „vedoucí IT týmu“, „viceprezident“ a „manažer“.
job_platform tabulka odkazuje na médium použité k inzerci pracovního místa. Úloha může být například zveřejněna na Facebooku, online nástěnce nebo v místních novinách. Odkaz na toto pracovní místo lze přidat do description pole.
organization tabulka ukládá informace o všech společnostech, které kdy tuto databázi použili jako součást svého náborového procesu. Tato tabulka je samozřejmě důležitá, když se provádí nábor pro jinou společnost.
Poslední tabulka v této oblasti, job , obsahuje skutečný popis práce. Většina atributů je samozřejmá. Měli bychom poznamenat, že tato tabulka má mnoho cizích klíčů, což znamená, že ji lze použít k vyhledání kategorie, pozice, platformy, náborové organizace a náborového procesu souvisejícího s tímto pracovním místem.
Žádost, žadatel a dokumenty
Třetí část schématu tvoří tabulky, které uchovávají informace o uchazečích o zaměstnání, jejich žádostech a případných dokumentech, které jsou k žádostem přiloženy.
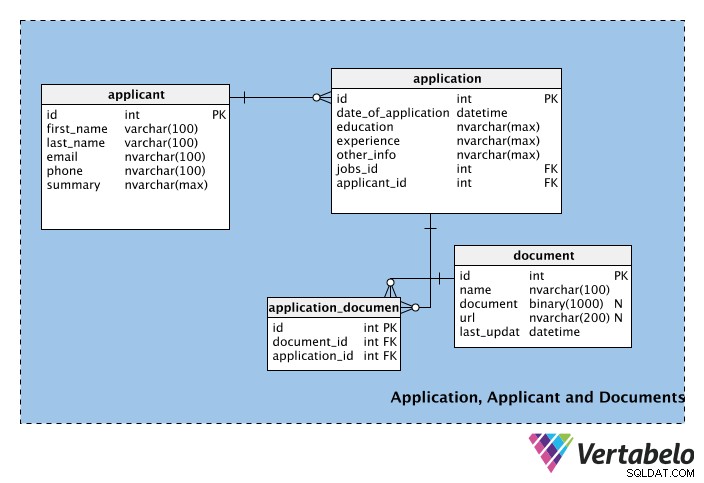
První tabulka, applicant , uchovává osobní údaje uchazečů, jako je jejich jméno, příjmení, e-mail, telefonní číslo atd. Pole shrnutí lze použít k uložení krátkého profilu uchazeče (tj. odstavce).
Další tabulka obsahuje informace pro každou application včetně jeho data. Tabulka také obsahuje experience a education sloupců. Tyto sloupce mohou být součástí applicant tabulkou, ale žadatel může nebo nemusí chtít uvádět konkrétní vzdělání nebo pracovní zkušenosti na každé žádosti, kterou předloží. Proto jsou tyto sloupce součástí application stůl. other_info ukládá všechny další informace související s aplikací. V application id tabulky, job_id a žadatel_id jsou cizí klíče z tabulek job a žadatelů.
Vzhledem k tomu, že pro každou úlohu může existovat více žádostí, ale každá žádost je určena pouze pro jednu úlohu, bude mezi jobs a application tabulky. Podobně může jeden uchazeč podat více přihlášek (tj. na různé pracovní pozice), ale každá přihláška je pouze od jednoho účastníka; implementovali jsme další vztah one-to-many mezi applicants a application tabulky, jak to zvládnout.
document tabulka spravuje podpůrné dokumenty, které mohou žadatelé připojit ke své žádosti. Mohou to být životopisy, životopisy, referenční dopisy, průvodní dopisy atd. Všimněte si, že tato tabulka má binární sloupec s názvem document, který uloží soubor v binárním formátu. Odkaz na dokument může být uložen v url pole; ve sloupci name je uložen název dokumentu a last_update označuje nejnovější verzi nahranou žadatelem. Všimněte si, že oba document a url jsou nulovatelné; žádná z nich není povinná a žadatel si může vybrat, zda použije jednu nebo obě metody k doplnění informací do své žádosti.
Ne každá žádost bude mít připojený dokument. Jeden dokument může být připojen k více aplikacím a jedna aplikace může mít více podpůrných dokumentů. To znamená, že mezi application a document tabulky. Ke správě tohoto vztahu použijte vyhledávací tabulku application_document byl vytvořen.
Testy a rozhovory
Nyní přejdeme k tabulkám, které uchovávají informace o testech a pohovorech souvisejících s náborovým procesem.
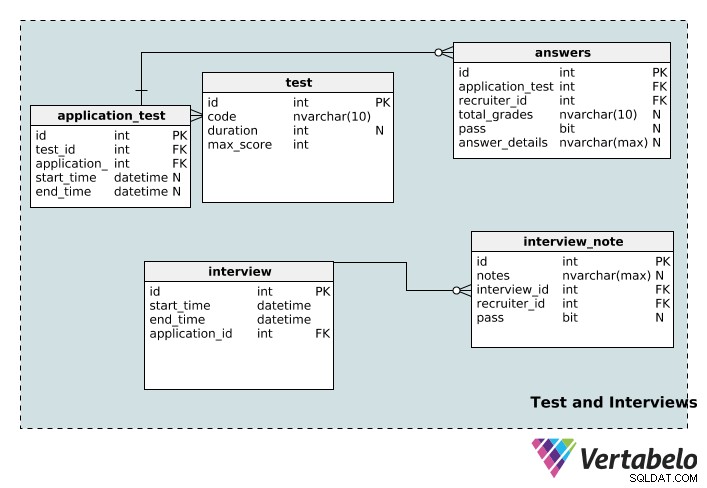
test tabulka ukládá podrobnosti testu včetně jeho jedinečného id , code název, jeho duration v minutách a maximum možné skóre pro tento test.
Jedna aplikace může být spojena s více testy a jeden test může být spojen s více aplikacemi. Opět máme vyhledávací tabulku pro implementaci tohoto vztahu:application_test . start_time a end_time sloupce mohou mít hodnotu null, protože test nemusí mít žádné konkrétní trvání, čas zahájení nebo čas ukončení.
Test může hodnotit více náborových pracovníků a jeden náborový pracovník může hodnotit více testů. answers table je tabulka, která to umožňuje. total_grades sloupec zaznamenává, jak dobře si kandidát vedl v testu, a sloupec prospěl jednoduše označuje, zda daná osoba uspěla nebo neuspěla. Specifika každého jednotlivého testu jsou zaznamenána v answer_details sloupec. Všimněte si, že tyto tři sloupce mají hodnotu null; test aplikace může být přidělen náboráři, který jej ještě neohodnotil. Kromě toho může být náboráři přidělen test ještě předtím, než bude skutečně složen.
interview tabulka ukládá základní informace (start_time , end_time , jedinečné id a příslušné application_id ) pro každý rozhovor. Jeden pohovor může být spojen pouze s jednou aplikací. Na druhou stranu jedna aplikace může mít více pohovorů. Mezi aplikací a tabulkou rozhovorů tedy existuje vztah jedna k mnoha.
Jeden pohovor může vést více recenzentů a jeden recenzent může absolvovat více pohovorů. Je to další vztah mnoho k mnoha, proto jsme vytvořili vyhledávací tabulku interview_note . Ukládá informace o pohovoru (v interview_id ), náborář (v recruiter_id ) a poznámky náborového pracovníka o pohovoru. Náboroví pracovníci mohou také zaznamenat, zda žadatel u pohovoru uspěl či nikoli, do sloupce „úspěšné“, který je nulový.
Hodnocení a stav aplikace náborářů
Poslední část našeho náborového modelu uchovává informace o náborářích, stavech žádostí a hodnocení žádostí.
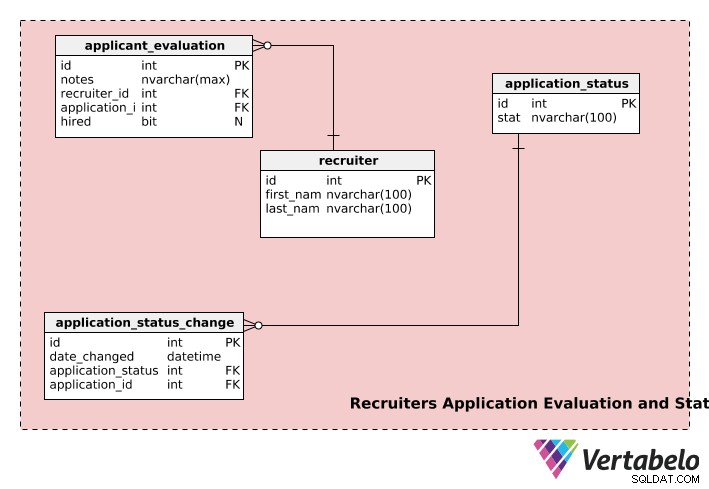
recruiters tabulka ukládá first_name každého náborového pracovníka , last_name a jedinečné id číslo.
application_evaluation tabulka obsahuje informace o hodnocení aplikací. Kromě application_id a recruiter_id , obsahuje zpětnou vazbu náborového pracovníka (v notes ) a konečné rozhodnutí o náboru, pokud existuje, v hired . Jednu žádost může hodnotit více náborářů a jeden náborář může hodnotit více žádostí, takže obě recruiter a application tabulka má vztah jedna k mnoha s application_evaluation stůl.
Žádost může během procesu náboru projít několika fázemi, např. „neodesláno“, „přezkoumáváno“, „čeká na rozhodnutí“, „rozhodnutí učiněno“ atd. Žádost bude mít stav „neodeslána“, když uživatel zahájí přihlášku, ale neodešle ji ke kontrole náborářům. Jakmile je žádost odeslána, stav se změní na „probíhá kontrola“ a tak dále. application_status Tabulka se používá k uložení takových informací.
application_status_change tabulka slouží k evidenci změn stavu u všech podaných žádostí. date_changed sloupec ukládá datum změny stavu. Tato tabulka může být užitečná, pokud chcete analyzovat dobu zpracování pro každou fázi různých aplikací. Kromě toho lze stav libovolného sloupce získat pomocí application_id ze sloupce application_status_change stůl.
Jednoduchý případ použití náboru
Pojďme se podívat, jak by naše databáze mohla pomoci náborovému procesu.
Předpokládejme, že vám společnost pověřila najmutím IT manažera se zkušenostmi s programováním. Naše databáze nám může pomoci najmout takovou osobu provedením následujících kroků:
- Prvním krokem je zahájení nového náborového procesu. Za tímto účelem jsou data vložena do
processastepstabulky. Náborář může přidat tolik kroků, kolik potřebuje. - Během výše uvedeného úkolu může náborář vytvořit novou práci a zadat podrobnosti do
job,job_category,job_positionaorganizationtabulky. Nakonec bude na jednu z platforem uložených vjob_platformstůl. - Dále si žadatelé vytvoří profil odesláním svých údajů
applicantsstůl. Poté spustí novou aplikaci zadáním dalších údajů doapplicationstůl. - Žadatelé mohou ke svým žádostem rovněž připojit dokumenty. Tato data budou uložena v
documentaapplication_documenttabulky. - Pokud se chce uživatel přihlásit k více než jedné práci, zopakuje kroky 3 a 4.
- Jakmile je žádost odeslána, stav žádosti bude nastaven na „odesláno“ (nebo jiný název stavu, který zvolí náborář).
- Náborový pracovník vyhodnotí žádost a zadá svou zpětnou vazbu do
application_evaluationstůl. V této fázi nebude sloupec najatých obsahovat žádné informace. - Jakmile obdrží dostatečný počet žádostí, náborář provede další krok uvedený v
process_stepstůl. - Pokud je dalším krokem administrace nějakého druhu testu, náborář vytvoří test přidáním dat do
teststůl. - Test vytvořený v kroku 9 bude přiřazen konkrétní aplikaci. Informace, které přiřazují každý test každé aplikaci, budou uloženy v
application_teststůl. Všimněte si, že během každé fáze se stav aplikace bude neustále měnit. To bude zaznamenáno vapplication_status_changestůl. - Jakmile žadatel test dokončí, náborář označí známky pro každý aplikační test a zadá je do
answersstůl. - Po provedení testu následuje další krok z
process_steptabulka bude provedena. Řekněme, že dalším krokem je rozhovor. - Údaje o rozhovoru budou vloženy do
interviewstůl. Náborový pracovník zadá své komentáře a řekne, zda daná osoba prošla pohovorem nebo ne. To bude uloženo vinterview_notestůl. - Pokud
processtabulka obsahuje další kroky pohovoru a testu, budou provedeny, dokud nebude dosaženo posledního kroku. - Poslední krok v
process_steptabulka je obvykle rozhodnutím o náboru. Pokud uchazeč projde testy a pohovory a společnost se ho rozhodne zaměstnat, údaje se zadají do sloupce pronájmu vapplication_evaluationstůl a osoba je najatá.
Co si myslíte o našem datovém modelu náborového systému?
V tomto článku jsme viděli, jak vytvořit velmi jednoduché schéma databáze pro náborový systém. Schéma jsme rozdělili do čtyř kategorií a každou z nich pak podrobně vysvětlili. Nakonec jsme spustili případ použití, abychom ukázali, že naše schéma může skutečně pomoci získat zaměstnance.
Práce v oblasti návrhu databází zažívají boom. Chcete přidat do svých databázových dovedností? Ať už jste nováček, který se chce naučit základy SQL, nebo ostřílený profesionál, který se chce rozdělit do oblasti Vytváření tabulek v SQL | Interaktivní kurz | Vertabelo Academy" target="_blank">návrh databáze, podívejte se na kurzy LearnSQL.com pro vlastní tempo.