V předchozím článku jsme diskutovali o modelu hvězdného schématu. Schéma sněhové vločky je vedle hvězdného schématu z hlediska jeho důležitosti v modelování datových skladů. Byl vyvinut z hvězdného schématu a nabízí některé výhody oproti svému předchůdci. Tyto výhody však něco stojí. V tomto článku probereme, kdy a jak použít schéma sněhové vločky.
Schéma sněhových vloček
Název schématu sněhových vloček pochází ze skutečnosti, že tabulky rozměrů se rozvětvují a vypadají jako sněhová vločka. Když se podíváme na model výše, všimneme si, že jde o tabulku faktů obklopenou několika tabulkami dimenzí, z nichž některé provádějí výše uvedené větvení. Na rozdíl od hvězdného schématu mohou mít tabulky dimenzí ve schématu sněhových vloček své vlastní kategorie.
Hlavní myšlenkou schématu sněhových vloček je, že tabulky dimenzí jsou zcela normalizovány. Každá tabulka rozměrů může být popsána jednou nebo více vyhledávacími tabulkami. Každá vyhledávací tabulka může být popsána jednou nebo více dalšími vyhledávacími tabulkami. Toto se opakuje, dokud není model plně normalizován. Proces normalizace tabulek rozměrů hvězdných schémat se nazývá sněhové vločky.
V tomto článku uslyšíte hodně o normalizaci. Co je normalizace? V zásadě jde o organizaci databáze způsobem, který minimalizuje redundanci a chrání integritu dat. Podívejte se na tento příspěvek, kde se dozvíte více o normalizaci a denormalizaci.
Příklad schématu sněhové vločky:Prodejní model
Dříve jsme k modelování fiktivního prodejního oddělení používali hvězdicové schéma – bylo by to podobné datovému trhu používanému ke sledování prodejních aktivit a výsledků. Model má pět rozměrů:produkt , čas , obchod , prodej typ a zaměstnanec . V fact_sales tabulka, cena a množství jsou uloženy a seskupeny na základě hodnot v tabulkách rozměrů. Pro připomenutí se podívejte na model prodeje hvězdicového schématu níže:
Zde je stejný model organizovaný jako schéma sněhové vločky:
dim_employee a dim_sales_type tabulky rozměrů jsou přesně stejné jako v modelu hvězdného schématu, protože jsou již normalizovány.
Na druhou stranu jsme aplikovali normalizační pravidla na zbytek tabulek dimenzí.


dim_product tabulka rozměrů z hvězdného schématu je v modelu sněhové vločky rozdělena do dvou tabulek. dim_product_type tabulka byla přidána jako odkaz na typ shody v dim_product stůl. Díky tomu jsme se vyhnuli některým problémům s integritou dat.
Je logické předpokládat, že již budeme mít všechny názvy produktů a jejich související typy vložené jako součást procesu ETL, ale předpokládejme, že potřebujeme přidat další názvy a typy produktů. Ve hvězdicovém schématu jsme mohli do tabulky omylem zadat nesprávný typ produktu. Ve schématu sněhových vloček:
- Pokud narazíme na nový název typu produktu, můžeme přidat nový typ produktu a pak tento typ přiřadit k nově přidanému záznamu. To však může vést k tomu, že uživatel zadá nesprávné informace, stejně jako ve hvězdicovém schématu.
- Mohli bychom zkontrolovat, zda název produktu, který chceme přidat, již existuje. Pokud ano, můžeme získat jeho ID; pokud ne, objeví se varování s dotazem, zda chceme přidat nový produkt a související typ.

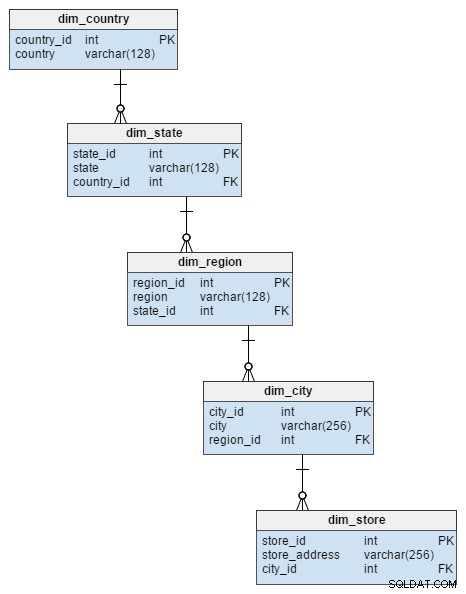
dim_store tabulka rozměrů z hvězdného schématu je reprezentována 5 tabulkami ve schématu sněhové vločky. Ty rozdělují atributy města, regionu, státu a země, které byly uloženy v dim_store stůl. Normalizace této tabulky nejenže zabránila riziku integrity dat, ale také ušetřila místo na disku.
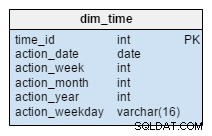
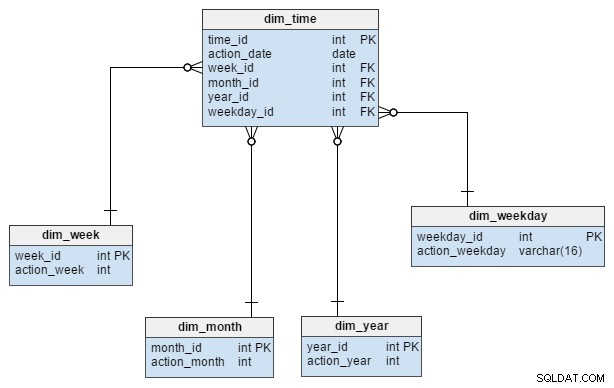
dim_time rozměr je reprezentován pěti tabulkami. Můžeme si představit dim_week , dim_month , dim_year a dim_weekday tabulky jako slovníky, které popisují dim_time stůl.
dim_week , dim_month , dim_year a dim_weekday tabulky jsou čtyři různé hierarchie používané k popisu naší časové dimenze. Pokud bychom je potřebovali, mohli bychom přidat další rozměry, jako jsou čtvrtiny nebo jiné související tabulky. V tomto příkladu dim_month je slovník obsahující 12 měsíců; pouze z této dimenze nemáme žádný způsob, jak zjistit, do kterého roku ten měsíc patří; to je funkce dim_year stůl.
Příklad schématu sněhové vločky:Model objednávek dodávek
Další datový obchod, o kterém jsme hovořili, byl pro objednávky dodávek. Cílem je uložit a agregovat všechna data objednávky dodávek pro následující čtyři dimenze:produkt , čas , dodavatel a zaměstnanec . Ještě jednou se podíváme na příslušné hvězdné schéma:
Když to převedeme na schéma sněhové vločky, dostaneme následující model:
U dim_product , dim_time a dim_supplier tabulky rozměrů.
Výhody a nevýhody schématu sněhové vločky
Existují dvě hlavní výhody ke schématu sněhových vloček:
- Lepší kvalita dat (data jsou strukturovanější, takže problémy s integritou dat jsou sníženy)
- Na disku se použije méně místa než v denormalizovaném modelu
Nejvýraznější nevýhoda pro model sněhové vločky je to, že vyžaduje složitější dotazy. Tyto dotazy by se zvýšeným počtem spojení mohly výrazně snížit výkon.
Přepíšeme stejný dotaz jako v článku o hvězdicovém schématu pro model prodeje schématu sněhové vločky. Zde je dotaz potřebný k vrácení množství všech produktů typu telefon prodaných v berlínských obchodech v roce 2016:
SELECT dim_store.store_address, SUM(fact_sales.quantity) AS quantity_sold FROM fact_sales INNER JOIN dim_product ON fact_sales.product_id = dim_product.product_id INNER JOIN dim_product_type ON dim_product.product_type_id = dim_product_type.product_type_id INNER JOIN dim_time ON fact_sales.time_id = dim_time.time_id INNER JOIN dim_year ON dim_time.year_id = dim_year.year_id INNER JOIN dim_store ON fact_sales.store_id = dim_store.store_id INNER JOIN dim_city ON dim_store.city_id = dim_city.city_id WHERE dim_year.action_year = 2016 AND dim_city.city = 'Berlin' AND dim_product_type.product_type_name = 'phone' GROUP BY dim_store.store_id, dim_store.store_address
Schéma hvězdných vloček
Schéma hvězdné vločky je kombinací sněhové vločky a schématu hvězdy. Můžeme to vidět jako schéma sněhové vločky, které má některé tabulky dimenzí denormalizované. Při správném použití může schéma hvězdné vločky poskytnout nejlepší přístup z obou světů. Je zřejmé, že sněhová vločková část modelu by měla šetřit místo na disku, zatímco hvězdná část by měla zlepšit výkon.
Výše uvedený model je v podstatě model sněhové vločky s denormalizovaným dim_time stůl. Protože toto schéma snižuje počet potřebných spojení dotazů, může zlepšit výkon. Na druhou stranu nepřijdeme o značnou část místa na disku, protože většina atributů tabulky a cizího klíče sdílí int typ.
Schéma galaxie
V datovém skladu je schéma galaxie, když dvě nebo více tabulek faktů sdílí jednu nebo více tabulek dimenzí. Jedním z důvodů použití tohoto schématu je úspora místa na disku. Níže jsme vytvořili vzorové schéma galaxie:
Zde máme dvě tabulky faktů, fact_sales a fact_supply_order , které přímo sdílejí třírozměrné tabulky:dim_product , dim_employee a dim_time . Všimněte si, že i dim_store a dim_supplier sdílet stejnou vyhledávací tabulku dim_city .
Tímto způsobem ušetříme místo, ale než spojíme dva datové trhy (v tomto případě objednávky prodeje a dodávek) do jednoho schématu galaxie, musíme mít na paměti několik věcí:
- Je za tím spojením nějaká logika? Např. Používaly by oba datové tržiště stejné oddělení?
- Jsme si jisti, že potřebujeme přesně stejný rozměr a zrnitost? pro oba datové trhy?
Schéma sněhové vločky se často používá v datovém modelování. Může to být správná volba v situacích, kdy je místo na disku důležitější než výkon. Pokud chceme rovnováhu mezi úsporou místa a výkonem, můžeme použít schéma hvězdné vločky. Správné přizpůsobení pro jakýkoli konkrétní problém však závisí na mnoha parametrech. Toto je jedna z oblastí IT, kde si můžeme ‚hrát‘ s faktory, abychom přišli s nejlepším řešením.