Scénář
Jste vlastníkem internetového obchodu se sídlem v Polsku. Většina vašich zákazníků je z Polska a mluví polsky. Ale chcete své produkty prodávat i do zahraničí a vaši zahraniční zákazníci mluví převážně anglicky. Chcete, aby byl váš internetový obchod dostupný v polštině a angličtinu . Také očekáváte, že se vaše produkty budou dobře prodávat ve Francii, takže předpokládáte, že si budete muset připravit francouzský verze obchodu také (a možná španělská taky, protože proč ne?).
Chcete, aby vaši uživatelé mohli přejít z polské verze

na anglickou verzi a zpět.

A samozřejmě chcete, aby se podrobnosti o produktu přepnuly z polštiny do angličtiny.
Jak vytvoříte vícejazyčnou webovou aplikaci?
Ve vaší aplikaci jsou dva typy textu. Jeden je statický data:popisky tlačítek, záhlaví tabulek, grafika (která často obsahuje text). Druhý je definovaný uživatelem údaje, jako je název produktu, cena produktu, popis produktu atd. Data jsou normálně přebírána z databáze.
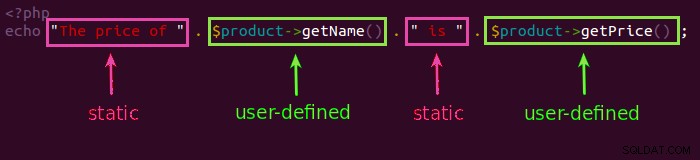
Statická data jsou to, co byste chtěli ve svém výstupu zapsat jako řetězcový literál. Uživatelsky definovaná data jsou data, která přebíráte ze své databáze.
Dnes nebudu mluvit o statických datech. Internacionalizaci statických dat zvládne jakýkoli rozumný webový rámec. Podrobnosti najdete v dokumentaci vaší webové aplikace. Hledejte klíčová slova jako „internacionalizace“, „i18n“, „lokalizace“ nebo „překlady“.
Dnes budu mluvit o tom, jakou databázovou strukturu zde v e-pointu obvykle používáme ke zpracování vícejazyčných dat. V databázi vašeho obchodu pravděpodobně máte product tabulka, která ukládá informace o všech produktech dostupných v obchodě.
product tabulka má sloupce jako name , description a price . Když překládáte informace o produktu do jiných jazyků, musíte přeložit pouze některé sloupce. Zde byste přeložili pouze name a description , ale price se při přepnutí jazyka nezmění.
Když přidáme podporu pro více jazyků, přidáme novou tabulku s názvem language_version , ve kterém jsou uloženy všechny jazykové verze dostupné v obchodě. Obvykle přidáváme sloupec s názvem code a jeden s názvem is_default (s příslušným omezením:pouze jedna verze může být výchozí).
Dále rozdělíme product tabulka do dvou tabulek:tabulka product a tabulka product_lv . Pro každý produkt bude v product tabulka a více řádků v product_lv stůl; jeden řádek pro každou jazykovou verzi. Tabulka product_lv obsahuje pouze sloupce, které je třeba přeložit:name a description . Sloupce, které jsou jazykově nezávislé (jako price , protože prodáváte za stejnou cenu bez ohledu na to, zda váš zákazník mluví anglicky nebo polsky) zůstaňte v tabulce product .
Totéž uděláme pro každou tabulku, která obsahuje přeložená data. Přeložená data jdou do table_lv tabulky, data nezávislá na jazyce zůstanou v hlavní tabulce.
Pro a proti
Zjevnou nevýhodou je, že všechny operace vytváření, načítání, aktualizace nebo mazání (CRUD) jsou trochu komplikovanější. Chcete-li získat správný popis, musíte se vždy připojit pomocí další tabulky jazykových verzí.
Výhodou tohoto designu je, že při přidávání nové jazykové verze nemusíte měnit schéma databáze. Neříkám, že přidání nové jazykové verze je snadné. Koneckonců, musíte přeložit VŠECHNY popisy produktů. Je to organizační výzva, ale z hlediska databáze je to docela snadné:spousta příloh.
Jak navrhujete své vícejazyčné databáze?