SQL Server se tradičně vyhýbá poskytování nativních řešení některých běžnějších statistických otázek, jako je například výpočet mediánu. Podle WikiPedie je "medián popsán jako číselná hodnota oddělující vyšší polovinu vzorku, populace nebo rozdělení pravděpodobnosti od dolní poloviny. Medián konečného seznamu čísel lze nalézt uspořádáním všech pozorování z od nejnižší hodnoty po nejvyšší a vybere se střední hodnota. Pokud existuje sudý počet pozorování, neexistuje jediná střední hodnota; medián je pak obvykle definován jako průměr dvou středních hodnot."
Pokud jde o dotaz SQL Server, klíčovou věcí, kterou si z toho odnesete, je to, že musíte „uspořádat“ (seřadit) všechny hodnoty. Řazení na SQL Serveru je obvykle poměrně nákladná operace, pokud neexistuje podpůrný index, a přidání indexu na podporu operace, která pravděpodobně není požadována, se často nemusí vyplatit.
Podívejme se, jak jsme tento problém obvykle vyřešili v předchozích verzích SQL Server. Nejprve si vytvořte velmi jednoduchou tabulku, abychom mohli zjistit, že naše logika je správná a odvodit přesný medián. Můžeme otestovat následující dvě tabulky, jednu se sudým počtem řádků a druhou s lichým počtem řádků:
CREATE TABLE dbo.EvenRows ( id INT PRIMARY KEY, val INT );
CREATE TABLE dbo.OddRows ( id INT PRIMARY KEY, val INT );
INSERT dbo.EvenRows(id,val)
SELECT 1, 6
UNION ALL SELECT 2, 11
UNION ALL SELECT 3, 4
UNION ALL SELECT 4, 4
UNION ALL SELECT 5, 15
UNION ALL SELECT 6, 14
UNION ALL SELECT 7, 4
UNION ALL SELECT 8, 9;
INSERT dbo.OddRows(id,val)
SELECT 1, 6
UNION ALL SELECT 2, 11
UNION ALL SELECT 3, 4
UNION ALL SELECT 4, 4
UNION ALL SELECT 5, 15
UNION ALL SELECT 6, 14
UNION ALL SELECT 7, 4;
DECLARE @Median DECIMAL(12, 2); Jen z náhodného pozorování můžeme vidět, že medián pro tabulku s lichými řádky by měl být 6 a pro sudou tabulku by měl být 7,5 ((6+9)/2). Nyní se tedy podívejme na některá řešení, která byla v průběhu let používána:
SQL Server 2000
V SQL Server 2000 jsme byli omezeni velmi omezeným dialektem T-SQL. Zkoumám tyto možnosti pro srovnání, protože někteří lidé tam stále používají SQL Server 2000 a jiní možná upgradovali, ale protože jejich výpočty mediánu byly napsány "v minulosti", kód může i dnes vypadat takto.
2000_A – maximálně jedna polovina, minimálně druhá
Tento přístup vezme nejvyšší hodnotu z prvních 50 procent, nejnižší hodnotu z posledních 50 procent a poté je vydělí dvěma. To funguje pro sudé nebo liché řádky, protože v sudém případě jsou tyto dvě hodnoty dva prostřední řádky a v lichém případě jsou tyto dvě hodnoty ve skutečnosti ze stejného řádku.
SELECT @Median = (
(SELECT MAX(val) FROM
(SELECT TOP 50 PERCENT val
FROM dbo.EvenRows ORDER BY val, id) AS t)
+ (SELECT MIN(val) FROM
(SELECT TOP 50 PERCENT val
FROM dbo.EvenRows ORDER BY val DESC, id DESC) AS b)
) / 2.0; 2000_B – #temp tabulka
Tento příklad nejprve vytvoří #temp tabulku a pomocí stejného typu matematiky jako výše určí dva „prostřední“ řádky s pomocí sousední IDENTITY sloupec seřazený podle sloupce val. (Pořadí přiřazení IDENTITY Na hodnoty se lze spolehnout pouze díky MAXDOP nastavení.)
CREATE TABLE #x
(
i INT IDENTITY(1,1),
val DECIMAL(12, 2)
);
CREATE CLUSTERED INDEX v ON #x(val);
INSERT #x(val)
SELECT val
FROM dbo.EvenRows
ORDER BY val OPTION (MAXDOP 1);
SELECT @Median = AVG(val)
FROM #x AS x
WHERE EXISTS
(
SELECT 1
FROM #x
WHERE x.i - (SELECT MAX(i) / 2.0 FROM #x) IN (0, 0.5, 1)
);
SQL Server 2005, 2008, 2008 R2
SQL Server 2005 představil některé zajímavé nové funkce okna, jako je ROW_NUMBER() , což může pomoci vyřešit statistické problémy, jako je medián, o něco snadněji, než bychom mohli v SQL Server 2000. Všechny tyto přístupy fungují v SQL Server 2005 a vyšších:
2005_A – soubojová čísla řádků
Tento příklad používá ROW_NUMBER() procházet nahoru a dolů hodnoty jednou v každém směru, pak najde "střední" jeden nebo dva řádky na základě tohoto výpočtu. To je docela podobné prvnímu příkladu výše, s jednodušší syntaxí:
SELECT @Median = AVG(1.0 * val)
FROM
(
SELECT val,
ra = ROW_NUMBER() OVER (ORDER BY val, id),
rd = ROW_NUMBER() OVER (ORDER BY val DESC, id DESC)
FROM dbo.EvenRows
) AS x
WHERE ra BETWEEN rd - 1 AND rd + 1; 2005_B – číslo řádku + počet
Tento je velmi podobný výše uvedenému, používá jediný výpočet ROW_NUMBER() a poté pomocí celkového počtu COUNT() k nalezení "prostředního" jednoho nebo dvou řádků:
SELECT @Median = AVG(1.0 * Val)
FROM
(
SELECT val,
c = COUNT(*) OVER (),
rn = ROW_NUMBER() OVER (ORDER BY val)
FROM dbo.EvenRows
) AS x
WHERE rn IN ((c + 1)/2, (c + 2)/2); 2005_C – variace na číslo řádku + počet
Kolega MVP Itzik Ben-Gan mi ukázal tuto metodu, která dosahuje stejné odpovědi jako výše uvedené dvě metody, ale velmi mírně odlišným způsobem:
SELECT @Median = AVG(1.0 * val)
FROM
(
SELECT o.val, rn = ROW_NUMBER() OVER (ORDER BY o.val), c.c
FROM dbo.EvenRows AS o
CROSS JOIN (SELECT c = COUNT(*) FROM dbo.EvenRows) AS c
) AS x
WHERE rn IN ((c + 1)/2, (c + 2)/2);
SQL Server 2012
V SQL Server 2012 máme nové funkce oken v T-SQL, které umožňují přímější vyjádření statistických výpočtů, jako je medián. K výpočtu mediánu pro sadu hodnot můžeme použít PERCENTILE_CONT() . Můžeme také použít nové rozšíření "stránkování" do ORDER BY klauzule (OFFSET / FETCH ).
2012_A – nová distribuční funkce
Toto řešení používá velmi přímočarý výpočet pomocí rozdělení (pokud nechcete průměr mezi dvěma středními hodnotami v případě sudého počtu řádků).
SELECT @Median = PERCENTILE_CONT(0.5) WITHIN GROUP (ORDER BY val) OVER () FROM dbo.EvenRows;
2012_B – trik se stránkováním
Tento příklad implementuje chytré použití OFFSET / FETCH (a ne přesně ten, pro který byl určen) – jednoduše se přesuneme na řadu, která je jedna před polovinou počtu, a poté vezmeme další jednu nebo dvě řady podle toho, zda byl počet lichý nebo sudý. Děkujeme Itziku Ben-Ganovi za upozornění na tento přístup.
DECLARE @c BIGINT = (SELECT COUNT(*) FROM dbo.EvenRows);
SELECT AVG(1.0 * val)
FROM (
SELECT val FROM dbo.EvenRows
ORDER BY val
OFFSET (@c - 1) / 2 ROWS
FETCH NEXT 1 + (1 - @c % 2) ROWS ONLY
) AS x;
Ale který z nich funguje lépe?
Ověřili jsme, že všechny výše uvedené metody poskytují očekávané výsledky v našem malém stolku a víme, že verze SQL Server 2012 má nejčistší a nejlogičtější syntaxi. Ale který z nich byste měli používat ve svém rušném produkčním prostředí? Můžeme sestavit mnohem větší tabulku ze systémových metadat a zajistit, že máme spoustu duplicitních hodnot. Tento skript vytvoří tabulku s 10 000 000 nejedinečnými celými čísly:
USE tempdb; GO CREATE TABLE dbo.obj(id INT IDENTITY(1,1), val INT); CREATE CLUSTERED INDEX x ON dbo.obj(val, id); INSERT dbo.obj(val) SELECT TOP (10000000) o.[object_id] FROM sys.all_columns AS c CROSS JOIN sys.all_objects AS o CROSS JOIN sys.all_objects AS o2 WHERE o.[object_id] > 0 ORDER BY c.[object_id];
V mém systému by měl být medián pro tuto tabulku 146 099 561. Mohu to vypočítat docela rychle bez ruční kontroly 10 000 000 řádků pomocí následujícího dotazu:
SELECT val FROM
(
SELECT val, rn = ROW_NUMBER() OVER (ORDER BY val)
FROM dbo.obj
) AS x
WHERE rn IN (4999999, 5000000, 5000001); Výsledky:
val rn ---- ---- 146099561 4999999 146099561 5000000 146099561 5000001
Nyní tedy můžeme vytvořit uloženou proceduru pro každou metodu, ověřit, že každá z nich produkuje správný výstup, a poté měřit metriky výkonu, jako je trvání, CPU a čtení. Všechny tyto kroky provedeme se stávající tabulkou a také s kopií tabulky, která nemá užitek z seskupeného indexu (vypustíme ji a znovu vytvoříme tabulku jako hromadu).
Vytvořil jsem sedm procedur implementujících výše uvedené metody dotazu. Pro stručnost je zde nebudu vypisovat, ale každý se jmenuje dbo.Median_<version> , např. dbo.Median_2000_A , dbo.Median_2000_B atd. odpovídající výše popsaným přístupům. Spustíme-li těchto sedm procedur pomocí bezplatného SQL Sentry Plan Explorer, zde je to, co pozorujeme z hlediska trvání, CPU a čtení (všimněte si, že mezi spuštěními spouštíme DBCC FREEPROCCACHE a DBCC DROPCLEANBUFFERS):
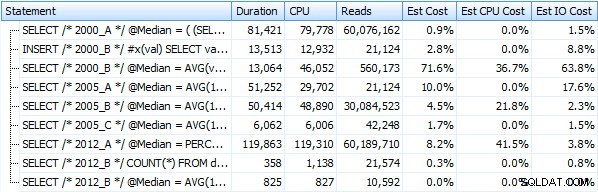
A tyto metriky se příliš nezmění, pokud místo toho pracujeme proti hromadě. Největší procentuální změnou byla metoda, která byla stále nejrychlejší:trik se stránkováním pomocí OFFSET / FETCH:
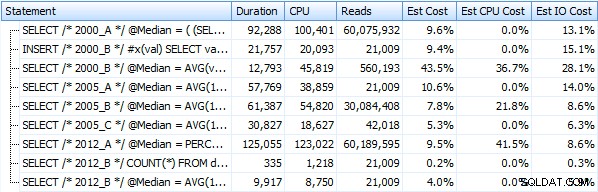
Zde je grafické znázornění výsledků. Aby to bylo jasnější, zvýraznil jsem nejpomalejšího hráče červeně a nejrychlejšího zeleně.
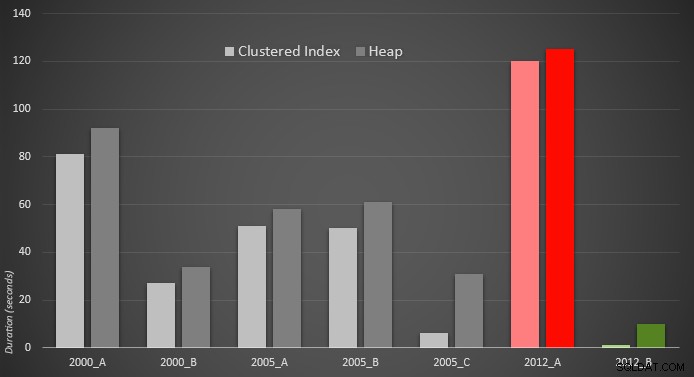
Překvapilo mě, že v obou případech PERCENTILE_CONT() – který byl navržen pro tento typ výpočtu – je ve skutečnosti horší než všechna ostatní dřívější řešení. Myslím, že to jen ukazuje, že i když někdy novější syntaxe může usnadnit naše kódování, ne vždy to zaručí, že se výkon zlepší. Byl jsem také překvapen, když jsem viděl OFFSET / FETCH se ukázaly být tak užitečné ve scénářích, které se obvykle nezdají být vhodné pro jeho účel – stránkování.
V každém případě doufám, že jsem ukázal, jaký přístup byste měli použít v závislosti na vaší verzi SQL Serveru (a že výběr by měl být stejný, ať už máte nebo nemáte podpůrný index pro výpočet).