Řekněme, že chcete najít všechny pacienty, kteří nikdy nebyli očkováni proti chřipce. Nebo v AdventureWorks2012 , podobná otázka by mohla znít:„ukaž mi všechny zákazníky, kteří nikdy nezadali objednávku.“ Vyjádřeno pomocí NOT IN , vzor, který vidím až příliš často, by vypadal asi takto (používám zvětšené tabulky záhlaví a podrobností z tohoto skriptu od Jonathana Kehayiase (@SQLPoolBoy)):
SELECT CustomerID FROM Sales.Customer WHERE CustomerID NOT IN ( SELECT CustomerID FROM Sales.SalesOrderHeaderEnlarged );
Když vidím tento vzorec, krčím se. Ale ne z důvodů výkonu – koneckonců to v tomto případě vytváří dostatečně slušný plán:
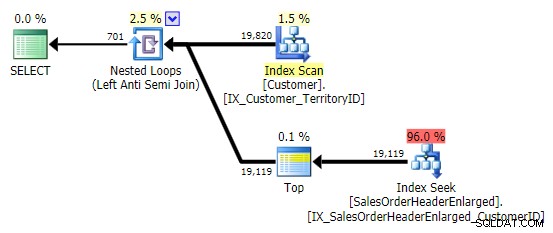
Hlavním problémem je, že výsledky mohou být překvapivé, pokud má cílový sloupec hodnotu NULL (SQL Server to zpracuje jako levé anti semi spojení, ale nemůže vám spolehlivě říci, zda je NULL na pravé straně rovna – nebo ne rovna – odkaz na levé straně). Optimalizace se také může chovat jinak, pokud má sloupec hodnotu NULL, i když ve skutečnosti žádné hodnoty NULL neobsahuje (Gail Shaw o tom hovořila již v roce 2010).
V tomto případě cílový sloupec nemá hodnotu null, ale chtěl jsem zmínit potenciální problémy s NOT IN – Tyto problémy mohu důkladněji prozkoumat v budoucím příspěvku.
Verze TL;DR
Místo NOT IN , použijte korelovaný NOT EXISTS pro tento vzor dotazu. Vždy. Jiné metody mu mohou konkurovat z hlediska výkonu, když jsou všechny ostatní proměnné stejné, ale všechny ostatní metody přinášejí buď problémy s výkonem, nebo jiné problémy.
Alternativy
Jakými jinými způsoby tedy můžeme napsat tento dotaz?
VNĚJŠÍ POUŽITÍ
Jedním ze způsobů, jak můžeme vyjádřit tento výsledek, je použití korelovaného OUTER APPLY .
SELECT c.CustomerID FROM Sales.Customer AS c OUTER APPLY ( SELECT CustomerID FROM Sales.SalesOrderHeaderEnlarged WHERE CustomerID = c.CustomerID ) AS h WHERE h.CustomerID IS NULL;
Logicky se jedná také o levé anti semi spojení, ale výsledný plán postrádá levý anti semi join operátor a zdá se být o dost dražší než NOT IN ekvivalent. Je to proto, že se již nejedná o levý anti semi spoj; ve skutečnosti se zpracovává jiným způsobem:vnější spojení přináší všechny odpovídající a neodpovídající řádky a *pak* se použije filtr k odstranění shod:
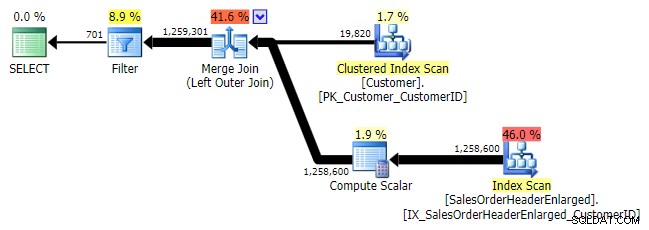
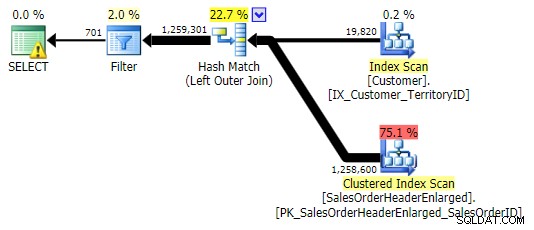
LEVÉ VNĚJŠÍ PŘIPOJENÍ
Typičtější alternativou je LEFT OUTER JOIN kde pravá strana je NULL . V tomto případě by dotaz byl:
SELECT c.CustomerID FROM Sales.Customer AS c LEFT OUTER JOIN Sales.SalesOrderHeaderEnlarged AS h ON c.CustomerID = h.CustomerID WHERE h.CustomerID IS NULL;
To vrátí stejné výsledky; ale stejně jako OUTER APPLY používá stejnou techniku spojení všech řad a teprve poté eliminaci shod:
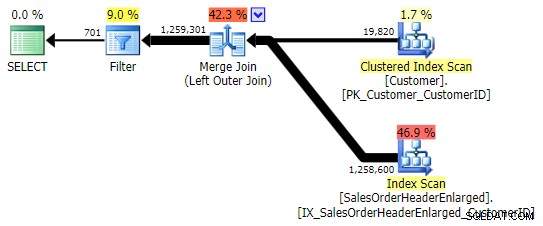
Musíte si však dávat pozor, ve kterém sloupci kontrolujete NULL . V tomto případě CustomerID je logická volba, protože se jedná o spojovací sloupec; náhodou je také indexován. Mohl jsem vybrat SalesOrderID , což je klíč shlukování, takže je také v indexu na CustomerID . Ale mohl jsem si vybrat jiný sloupec, který není v indexu použitém pro spojení (nebo se z něj později odstraní), což vede k jinému plánu. Nebo dokonce sloupec s možností NULL, což vede k nesprávným (nebo alespoň neočekávaným) výsledkům, protože neexistuje způsob, jak rozlišit mezi řádkem, který neexistuje a řádkem, který existuje, ale kde je tento sloupec NULL . A pro čtenáře / vývojáře / poradce při potížích nemusí být zřejmé, že tomu tak je. Otestuji tedy i tyto tři WHERE klauzule:
WHERE h.SalesOrderID IS NULL; -- clustered, so part of index WHERE h.SubTotal IS NULL; -- not nullable, not part of the index WHERE h.Comment IS NULL; -- nullable, not part of the index
První varianta vytváří stejný plán jako výše. Zbývající dva volí hašovací spojení místo slučovacího spojení a užší index v Customer tabulka, i když dotaz nakonec přečte přesně stejný počet stránek a množství dat. Zatímco však h.SubTotal variace vytváří správné výsledky:
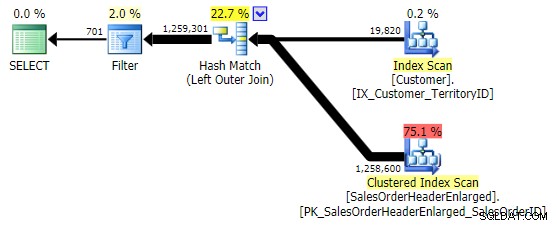
h.Comment varianta nikoli, protože zahrnuje všechny řádky, kde h.Comment IS NULL , stejně jako všechny řádky, které pro žádného zákazníka neexistovaly. Zdůraznil jsem jemný rozdíl v počtu řádků ve výstupu po použití filtru:
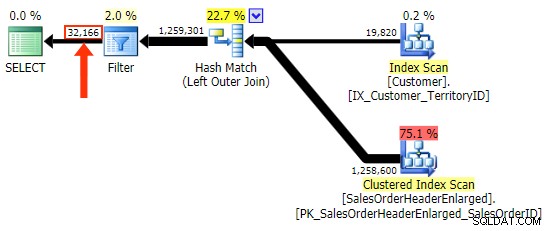
Kromě toho, že musím dávat pozor na výběr sloupců ve filtru, mám další problém s LEFT OUTER JOIN forma spočívá v tom, že není samodokumentační, stejně jako vnitřní spojení ve "starém" tvaru FROM dbo.table_a, dbo.table_b WHERE ... není sebedokumentační. Tím chci říct, že je snadné zapomenout na kritéria spojení, když je přesunete do WHERE klauzule, nebo aby se to spojilo s jinými kritérii filtru. Chápu, že je to dost subjektivní, ale je to tak.
KROMĚ
Pokud nás zajímá pouze sloupec spojení (který je podle definice v obou tabulkách), můžeme použít EXCEPT – alternativa, která se v těchto konverzacích, jak se zdá, příliš neobjevuje (pravděpodobně proto, že – obvykle – potřebujete rozšířit dotaz, aby zahrnoval sloupce, které neporovnáváte):
SELECT CustomerID FROM Sales.Customer AS c EXCEPT SELECT CustomerID FROM Sales.SalesOrderHeaderEnlarged;
To přichází s přesně stejným plánem jako NOT IN výše uvedená varianta:
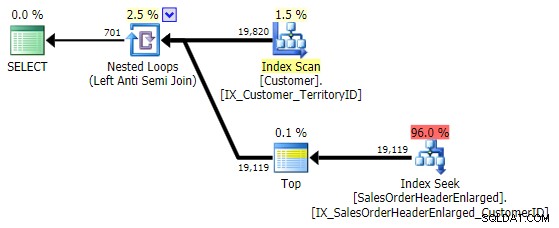
Jedna věc, kterou je třeba mít na paměti, je, že EXCEPT obsahuje implicitní DISTINCT – takže pokud máte případy, kdy chcete více řádků se stejnou hodnotou v tabulce „vlevo“, tento formulář tyto duplikáty odstraní. V tomto konkrétním případě to není problém, jen je třeba mít na paměti – stejně jako UNION versus UNION ALL .
NEEXISTUJE
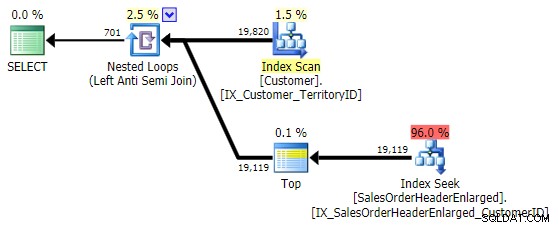
Moje preference pro tento vzor je rozhodně NOT EXISTS :
SELECT CustomerID
FROM Sales.Customer AS c
WHERE NOT EXISTS
(
SELECT 1
FROM Sales.SalesOrderHeaderEnlarged
WHERE CustomerID = c.CustomerID
);
(A ano, používám SELECT 1 místo SELECT * … ne z důvodu výkonu, protože SQL Server se nestará o to, jaké sloupce použijete uvnitř EXISTS a optimalizuje je pryč, ale jednoduše pro objasnění záměru:to mi připomíná, že tento "poddotaz" ve skutečnosti nevrací žádná data.)
Jeho výkon je podobný NOT IN a EXCEPT a vytváří identický plán, ale není náchylný k potenciálním problémům způsobeným hodnotami NULL nebo duplikáty:
Testy výkonu
Provedl jsem množství testů se studenou i teplou mezipamětí, abych potvrdil, že moje dlouhodobá představa o NOT EXISTS být správná volba zůstala pravdou. Typický výstup vypadal takto:
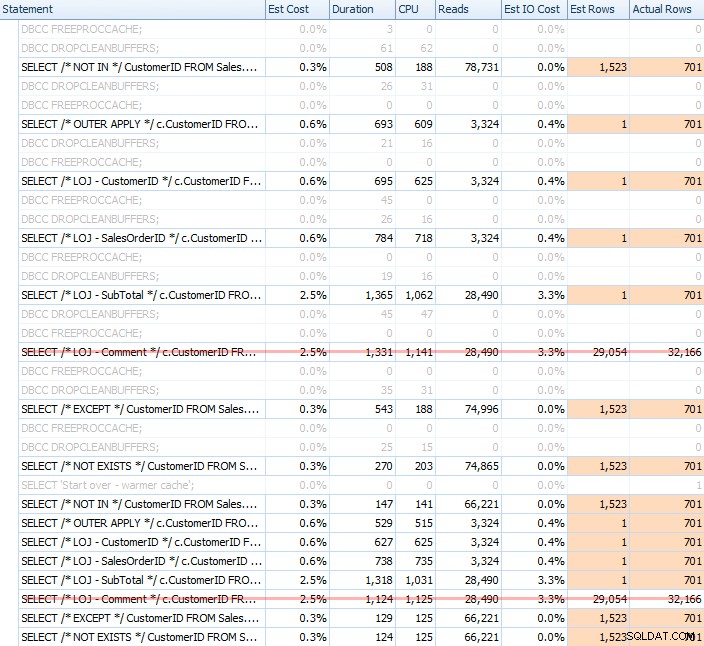
Při zobrazení průměrného výkonu 20 běhů v grafu vyjmu z mixu nesprávný výsledek (zahrnul jsem ho pouze proto, abych ukázal, jak špatné jsou výsledky), a provedl jsem dotazy v různém pořadí v testech, abych se ujistil že jeden dotaz trvale netěžil z práce předchozího dotazu. Pokud se zaměříme na trvání, zde jsou výsledky:
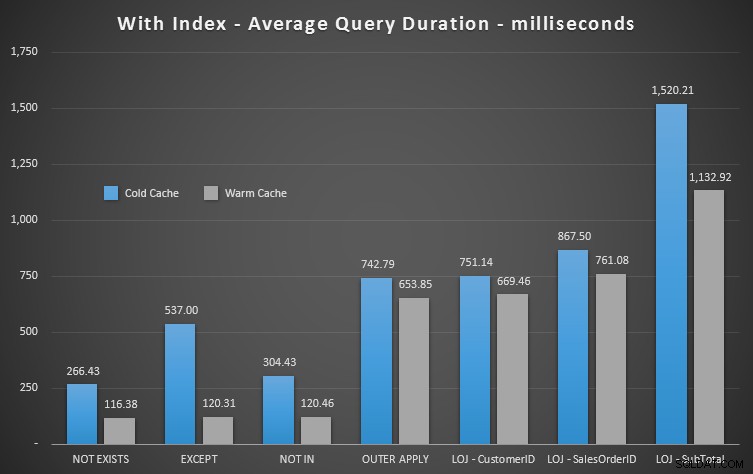
Pokud se podíváme na trvání a ignorujeme čtení, vítězí NOT EXISTS, ale ne o mnoho. EXCEPT a NOT IN nejsou daleko pozadu, ale znovu se musíte podívat na více než na výkon, abyste zjistili, zda jsou tyto možnosti platné, a otestujte je ve svém scénáři.
Co když neexistuje žádný podpůrný index?
Výše uvedené dotazy samozřejmě těží z indexu na Sales.SalesOrderHeaderEnlarged.CustomerID . Jak se tyto výsledky změní, pokud tento index vypustíme? Po vypuštění indexu jsem znovu provedl stejnou sadu testů:
DROP INDEX [IX_SalesOrderHeaderEnlarged_CustomerID] ON [Sales].[SalesOrderHeaderEnlarged];
Tentokrát byly mezi různými metodami mnohem menší odchylky z hlediska výkonu. Nejprve ukážu plány pro každou metodu (z nichž většina, nepřekvapivě, naznačuje užitečnost chybějícího indexu, který jsme právě vypustili). Poté ukážu nový graf znázorňující profil výkonu se studenou i teplou mezipamětí.
NENÍ IN, EXCEPT, NOT EXISTS (všechny tři byly totožné)
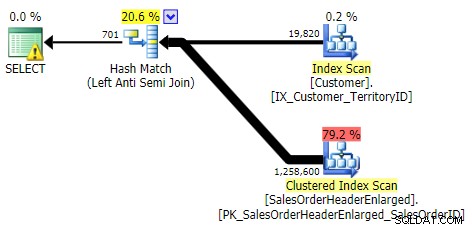
VNĚJŠÍ POUŽITÍ
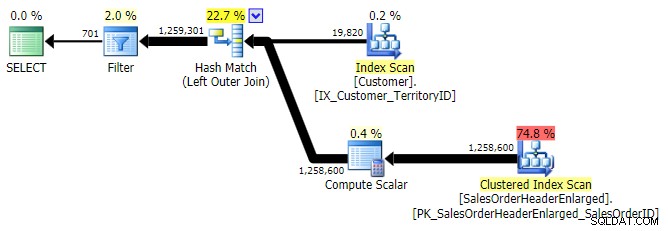
LEVÉ VNĚJŠÍ PŘIPOJENÍ (všechny tři byly shodné s výjimkou počtu řádků)
Výsledky výkonu
Když se podíváme na tyto nové výsledky, okamžitě vidíme, jak užitečný index je. Ve všech případech kromě jednoho (levé vnější spojení, které stejně jde mimo index), jsou výsledky jednoznačně horší, když index vypustíme:
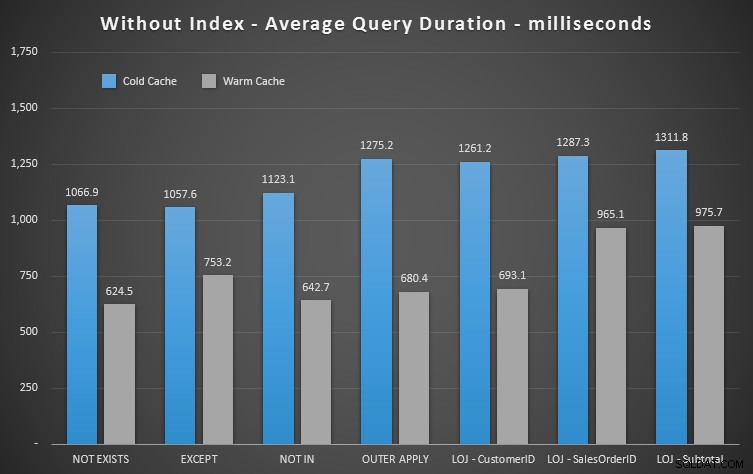
Můžeme tedy vidět, že i když je dopad méně patrný, NOT EXISTS je stále vaším okrajovým vítězem, pokud jde o trvání. A v situacích, kdy jsou ostatní přístupy náchylné k volatilitě schématu, je to také vaše nejbezpečnější volba.
Závěr
To byl jen opravdu zdlouhavý způsob, jak vám sdělit, že pro vzor hledání všech řádků v tabulce A, kde nějaká podmínka v tabulce B neexistuje, NOT EXISTS obvykle bude vaší nejlepší volbou. Ale jako vždy musíte tyto vzory otestovat ve svém vlastním prostředí pomocí schématu, dat a hardwaru a smíchat je se svými vlastními pracovními zátěžemi.