Jedním z mnoha vylepšení plánu provádění v SQL Server 2012 bylo přidání informací o rezervaci vláken a využití pro plány paralelního provádění. Tento příspěvek se zabývá přesně tím, co tato čísla znamenají, a poskytuje další pohled na pochopení paralelního provádění.
Zvažte následující dotaz spuštěný proti rozšířené verzi databáze AdventureWorks:
SELECT
BP.ProductID,
cnt = COUNT_BIG(*)
FROM dbo.bigProduct AS BP
JOIN dbo.bigTransactionHistory AS BTH
ON BTH.ProductID = BP.ProductID
GROUP BY BP.ProductID
ORDER BY BP.ProductID; Optimalizátor dotazů zvolí plán paralelního provádění:
Průzkumník plánů zobrazuje podrobnosti o použití paralelního vlákna v popisku kořenového uzlu. Chcete-li zobrazit stejné informace v SSMS, klikněte na kořenový uzel plánu, otevřete okno Vlastnosti a rozbalte ThreadStat uzel. Při použití stroje s osmi logickými procesory dostupnými pro SQL Server jsou informace o využití vláken z typického spuštění tohoto dotazu uvedeny níže, Plan Explorer vlevo, SSMS zobrazení vpravo:
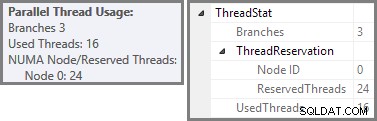
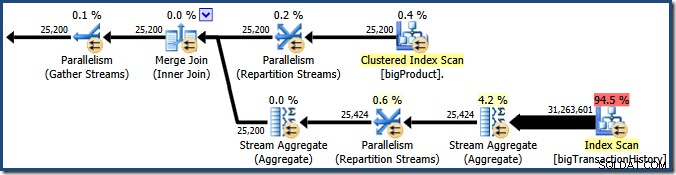
Snímek obrazovky ukazuje, že prováděcí stroj rezervoval 24 vláken pro tento dotaz a použil 16 z nich. Ukazuje také, že plán dotazů má tři větve , i když přesně neříká, co je to pobočka. Pokud jste četli můj článek Simple Talk o paralelním provádění dotazů, budete vědět, že větve jsou části plánu paralelních dotazů ohraničené operátory výměny. Níže uvedený diagram vykresluje hranice a čísluje větve (kliknutím zvětšíte):

Větev dvě (oranžová)
Podívejme se nejprve na větev dvě trochu podrobněji:
Při stupni paralelismu (DOP) osm je v této větvi plánu dotazů spuštěno osm vláken. Je důležité pochopit, že toto je celý plán provádění pokud jde o těchto osm vláken – nemají žádné znalosti o širším plánu.
V plánu sériového provádění jediné vlákno čte data ze zdroje dat, zpracovává řádky prostřednictvím řady operátorů plánu a vrací výsledky do cíle (což může být například okno s výsledky dotazu SSMS nebo databázová tabulka).
V pobočce u plánu paralelního provádění je situace velmi podobná:každé vlákno čte data ze zdroje, zpracovává řádky prostřednictvím řady operátorů plánu a vrací výsledky do cíle. Rozdíly jsou v tom, že cílem je operátor výměny (paralelnosti) a zdrojem dat může být také výměna.
V oranžové větvi je zdrojem dat Clustered Index Scan a cílem je pravá strana výměny toků přerozdělení. Pravá strana burzy je známá jako strana výrobce , protože se připojuje k pobočce, která přidává data do ústředny.
Osm vláken v oranžové větvi spolupracuje při skenování tabulky a přidávání řádků do výměny. Výměna sestavuje řádky do paketů o velikosti stránky. Jakmile je paket plný, je posunut přes ústřednu na druhou stranu. Pokud má burza k dispozici další prázdný paket k vyplnění, proces pokračuje, dokud nejsou zpracovány všechny řádky zdroje dat (nebo dokud burze nedojdou prázdné pakety).
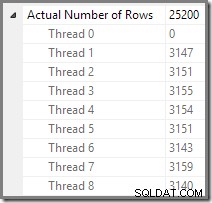
Počet zpracovaných řádků v každém vláknu můžeme vidět pomocí zobrazení Strom plánu v Průzkumníku plánů:
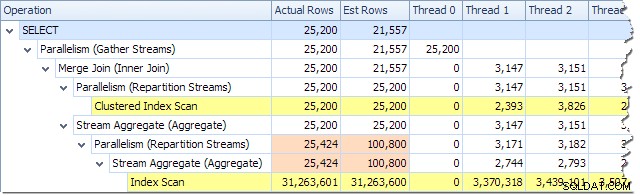
Průzkumník plánů usnadňuje zobrazení toho, jak jsou řádky rozděleny mezi vlákna pro všechny fyzické operace v plánu. V SSMS jste omezeni na zobrazení distribuce řádků pro operátora jednoho plánu. Chcete-li to provést, klikněte na ikonu operátora, otevřete okno Vlastnosti a rozbalte uzel Skutečný počet řádků. Níže uvedený obrázek ukazuje informace SSMS pro uzel Repartition Streams na hranici mezi oranžovou a fialovou větví:
Větev tři (zelená)
Větev tři je podobná větvi dva, ale obsahuje další operátor Stream Aggregate. Zelená větev má také osm vláken, celkem jich je tedy zatím šestnáct. Osm vláken se zelenými větvemi čte data z Nonclustered Index Scan, provádí nějakou agregaci a předává výsledky produkční straně jiné výměny Repartition Streams.
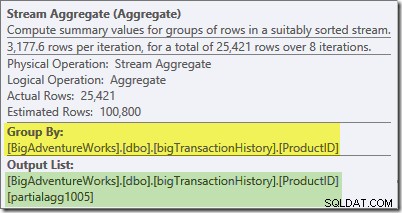
Popisek nástroje Plan Explorer pro Stream Aggregate ukazuje, že se seskupuje podle ID produktu a vypočítává výraz označený partialagg1005 :
Karta Výrazy ukazuje, že výraz je výsledkem počítání řádků v každé skupině:

Stream Aggregate počítá částečně (také známý jako „místní“) agregát. Částečný (neboli místní) kvalifikátor jednoduše znamená, že každé vlákno počítá agregaci na řádcích, které vidí. Řádky z Index Scan jsou distribuovány mezi vlákna pomocí schématu založeného na poptávce:neexistuje žádná pevná distribuce řádků předem; vlákna obdrží řadu řádků ze skenování, když o ně požádají. Které řádky skončí na kterých vláknech je v podstatě náhodné, protože to závisí na problémech s načasováním a dalších faktorech.
Každé vlákno vidí jiné řádky ze skenu, ale řádky se stejným ID produktu může být viděn více než jedním vláknem. Agregát je „částečný“, protože mezisoučty pro konkrétní skupinu ID produktů se mohou objevit ve více než jednom vláknu; je „místní“, protože každé vlákno počítá svůj výsledek pouze na základě řádků, které náhodou obdrží. Řekněme například, že v tabulce je 1 000 řádků pro produkt ID #1. Jedno vlákno může náhodou vidět 432 těchto řádků, zatímco jiné 568. Obě vlákna budou mít částečné počet řádků pro produkt ID #1 (432 v jednom vláknu, 568 ve druhém).
Částečná agregace je optimalizací výkonu, protože snižuje počet řádků dříve, než by bylo jinak možné. V zelené větvi vede časná agregace k menšímu počtu řádků, které jsou sestavovány do paketů a přenášeny přes výměnu Repartition Stream.
Větev 1 (fialová)

Fialová větev má ještě osm nití, takže jich je zatím dvacet čtyři. Každé vlákno v této větvi čte řádky ze dvou výměn Repartition Streams a zapisuje řádky do výměny Gather Streams. Tato větev se může zdát komplikovaná a neznámá, ale pouze čte řádky ze zdroje dat a odesílá výsledky do cíle, jako každý jiný plán dotazů.
Pravá strana plánu ukazuje data čtená z druhé strany dvou výměn Repartition Streams zobrazených v oranžové a zelené větvi. Tato (levá) strana burzy je známá jako spotřebitel straně, protože zde připojená vlákna čte (spotřebovává) řádky. Osm fialových větví jsou spotřebitelé dat na dvou výměnách toků rozdělení.
Na levé straně fialové větve se zobrazují řádky zapisované do producenta straně výměny Gather Streams. stejných osm vláken (což jsou spotřebitelé na burzách Repartition Streams) provádějí producent roli zde.
Každé vlákno ve fialové větvi spouští každý operátor ve větvi, stejně jako jediné vlákno provádí každou operaci v plánu sériového provádění. Hlavní rozdíl je v tom, že souběžně běží osm vláken, z nichž každé pracuje na jiném řádku v daný okamžik a používá různé instance operátorů plánu dotazů.
Stream Aggregate v této větvi je globální agregát. Kombinuje dílčí (místní) agregace vypočítané v zelené větvi (vzpomeňte si na příklad počtu 432 v jednom vláknu a 568 ve druhém) a vytváří kombinovaný součet pro každé ID produktu. Popisek nástroje Plan Explorer zobrazuje výraz globálního výsledku označený Expr1004:
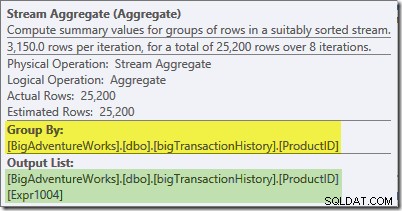
Správný globální výsledek na ID produktu se vypočítá sečtením dílčích souhrnů, jak ukazuje karta Výrazy:
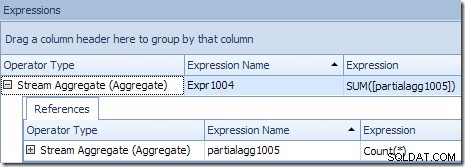
Abychom pokračovali v našem (imaginárním) příkladu, správný výsledek 1 000 řádků pro produkt ID #1 se získá sečtením dvou mezisoučtů 432 a 568.
Každé z osmi vláken fialové větve čte data ze spotřebitelské strany dvou burz Gather Streams, počítá globální agregáty, provádí spojení sloučení na ID produktu a přidává řádky do výměny Gather Streams zcela vlevo od fialové větve. Základní proces se příliš neliší od běžného sériového plánu; rozdíly jsou v tom, odkud se řádky čtou, kam se odesílají a jak jsou řádky rozděleny mezi vlákna…
Rozdělení řádků výměny
Pozorného čtenáře bude v tuto chvíli zajímat několik podrobností. Jak fialová větev zvládá vypočítat správné výsledky na ID produktu ale zelená větev nemohla (výsledky pro stejné ID produktu byly rozloženy do mnoha vláken)? Pokud existuje osm samostatných sloučení spojení (jedno na vlákno), jak SQL Server zaručuje, že řádky, které se spojí, skončí ve stejné instanci připojení?
Na obě tyto otázky lze odpovědět pohledem na způsob, jakým si dva přerozdělovací toky vyměňují řádky tras ze strany producenta (v zelené a oranžové větvi) na stranu spotřebitele (ve fialové větvi). Nejprve se podíváme na burzu Repartition Streams lemující oranžovou a fialovou větev:
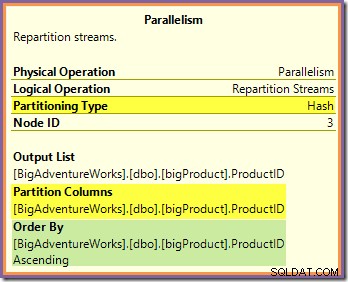
Tato výměna směruje příchozí řádky (z oranžové větve) pomocí hashovací funkce aplikované na sloupec ID produktu. Výsledkem je, že všechny řádky pro konkrétní ID produktu jsou zaručené aby byly směrovány do stejného vlákna s fialovými větvemi. Oranžová a fialová vlákna o tomto směrování nic nevědí; to vše je řešeno interně burzou.
Oranžová vlákna vědí pouze to, že vracejí řádky nadřazenému iterátoru, který o ně požádal (produkční strana výměny). Stejně tak všechna fialová vlákna „vědí“, že čtou řádky ze zdroje dat. Výměna určuje, do kterého paketu půjde příchozí řádek s oranžovým vláknem, a může to být kterýkoli z osmi kandidátských paketů. Podobně burza určí, ze kterého paketu se má číst řádek, aby se uspokojil požadavek na čtení z fialového vlákna.
Buďte opatrní, abyste nezískali mentální představu o konkrétním oranžovém (výrobním) vláknu, které je přímo spojeno s konkrétním fialovým (spotřebitelským) vláknem. Takto tento plán dotazů nefunguje. Oranžový výrobce může skončí odesláním řádků všem fialovým spotřebitelům – směrování zcela závisí na hodnotě sloupce ID produktu v každém řádku, který zpracovává.
Všimněte si také, že paket řádků na burze se přenese pouze tehdy, když je plný (nebo když na straně producenta dojdou data). Představte si výměnné plnící pakety po řadě, přičemž řady pro konkrétní paket mohou pocházet z libovolného (oranžového) vlákna na straně výrobce. Jakmile je paket plný, je předán spotřebitelské straně, kde z něj může začít číst konkrétní spotřebitelské (fialové) vlákno.
Burza Repartition Streams lemující zelenou a fialovou větev funguje velmi podobně:
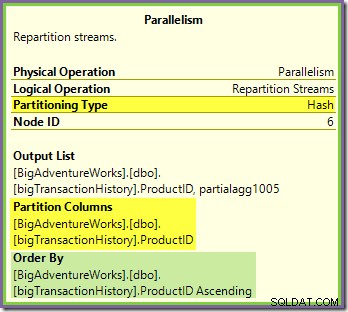
Řádky jsou směrovány do paketů v této výměně pomocí stejné hashovací funkce ve stejném sloupci rozdělení jako u oranžovo-fialové výměny viděné dříve. To znamená, že obě Repartition Streams vyměňuje řádky trasy se stejným ID produktu do stejného vlákna s fialovou větví.
To vysvětluje, jak je Stream Aggregate ve fialové větvi schopen vypočítat globální agregáty – pokud je v konkrétním vlákně fialové větve vidět jeden řádek s konkrétním ID produktu, je zaručeno, že toto vlákno uvidí všechny řádky pro toto ID produktu (a ne jiné vlákno bude).
Společný sloupec rozdělení výměny je také klíčem spojení pro slučovací spojení, takže je zaručeno, že všechny řádky, které se mohou spojit, budou zpracovány stejným (fialovým) vláknem.
Poslední věcí, kterou je třeba poznamenat, je, že obě burzy zachovávají objednávky (také znám jako 'sloučení') výměn, jak je znázorněno v atributu Order By v popisech. To splňuje požadavek sloučení spojení, aby byly vstupní řádky seřazeny na klíčích spojení. Upozorňujeme, že burzy nikdy netřídí řádky samy, lze je pouze nakonfigurovat tak, aby zachovaly stávající objednávka.
Vlákno nula
Poslední část exekučního plánu leží nalevo od burzy Gather Streams. Vždy běží na jediném vláknu – stejném, které se používá ke spuštění celého běžného sériového plánu. Toto vlákno je v plánech provádění vždy označeno jako vlákno 0 a někdy se mu říká vlákno koordinátora (toto označení nepovažuji za zvlášť užitečné).
Vlákno nula čte řádky ze spotřebitelské (levé) strany výměny Gather Streams a vrací je klientovi. V tomto příkladu nejsou žádné nulové iterátory vlákna kromě výměny, ale pokud by existovaly, všechny by běžely na stejném jediném vláknu. Všimněte si, že Gather Streams je také slučovací burza (má atribut Order By):

Složitější paralelní plány mohou zahrnovat zóny sériového provádění jiné, než je ta vlevo od poslední výměny Gather Streams. Tyto sériové zóny nejsou spuštěny v nulovém vláknu, ale to je detail na prozkoumání jindy.
Rezervovaná a použitá vlákna byla znovu navštívena
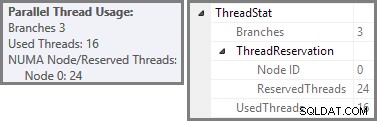
Viděli jsme, že tento paralelní plán obsahuje tři větve. To vysvětluje, proč je SQL Server rezervován 24 vláken (tři větve u DOP 8). Otázkou je, proč je na výše uvedeném snímku obrazovky označeno jako „použité“ pouze 16 vláken.
Odpověď má dvě části. První část se na tento plán nevztahuje, ale i tak je důležité o něm vědět. Počet nahlášených poboček je maximální počet, který lze provádět současně .
Jak možná víte, někteří operátoři plánu „blokují“ – což znamená, že musí spotřebovat všechny své vstupní řádky, než mohou vytvořit první výstupní řádek. Nejjasnějším příkladem operátoru blokování (také známého jako stop-and-go) je řazení. Třídění nemůže vrátit první řádek v seřazeném pořadí, dokud neuvidí každý vstupní řádek, protože poslední vstupní řádek může seřadit jako první.
Operátory s více vstupy (například spojení a sjednocení) mohou blokovat jeden vstup, ale neblokovat druhý vstup. Příkladem je hash join – vstup sestavení blokuje, ale vstup sondy je zřetězen. Vstup sestavení blokuje, protože vytváří hašovací tabulku, proti které se testují řádky sondy.
Přítomnost blokovacích operátorů znamená, že jedna nebo více paralelních větví může zaručit dokončení dříve, než mohou začít ostatní. Pokud k tomu dojde, může SQL Server znovu použít vlákna použitá ke zpracování dokončené větve pro pozdější větev v sekvenci. SQL Server je v rezervaci vláken velmi konzervativní, takže pouze větve, které jsou zaručené dokončit dříve, než začne další, využijte tuto optimalizaci rezervace vlákna. Náš plán dotazů neobsahuje žádné blokující operátory, takže hlášený počet poboček je pouze celkový počet poboček.
Druhá část odpovědi je, že vlákna lze stále znovu použít, pokud se stanou dokončit před spuštěním vlákna v jiné větvi. V tomto případě je stále rezervován plný počet vláken, ale skutečné využití může být nižší. Kolik vláken skutečně používá paralelní plán, závisí mimo jiné na problémech s načasováním a může se lišit mezi provedeními.
Paralelní vlákna se nezačnou spouštět všechna ve stejnou dobu, ale podrobnosti o tom budou muset počkat na jinou příležitost. Podívejme se znovu na plán dotazů, abychom viděli, jak lze vlákna znovu použít, i když chybí operátory blokování:
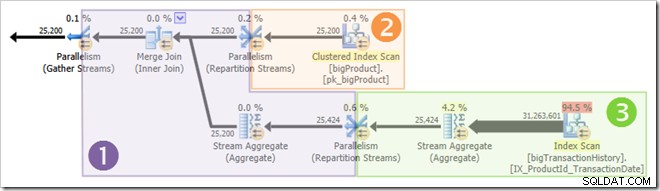
Je jasné, že vlákna ve větvi jedna nelze dokončit dříve, než se spustí vlákna ve větvích dvě nebo tři, takže tam není šance na opětovné použití vlákna. Třetí větev je také nepravděpodobná dokončit před spuštěním první nebo druhé větve, protože má tolik práce (téměř 32 milionů řádků k agregaci).
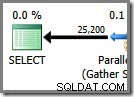
Druhá větev je jiná věc. Relativně malá velikost tabulky produktů znamená, že existuje slušná šance, že pobočka dokončí svou práci před třetí větev se spustí. Pokud čtení tabulky produktů nevede k žádnému fyzickému I/O, nebude trvat příliš dlouho, než osm vláken přečte 25 200 řádků a odešle je na výměnu proudů přerozdělení s oranžově fialovou hranicí.
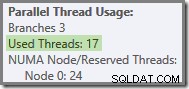
To je přesně to, co se stalo při testovacích jízdách používaných pro snímky obrazovky, které jsme dosud viděli v tomto příspěvku:osm vláken oranžové větve bylo dokončeno dostatečně rychle, aby je bylo možné znovu použít pro zelenou větev. Celkem bylo použito šestnáct jedinečných vláken, takže to uvádí plán provádění.
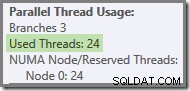
Pokud je dotaz znovu spuštěn s chladnou mezipamětí, zpoždění způsobené fyzickým vstupem/výstupem je dostatečné k tomu, aby se zajistilo, že se vlákna zelené větve spustí před dokončením všech vláken oranžové větve. Žádná vlákna nejsou znovu použita, takže plán provádění hlásí, že všech 24 vyhrazených vláken bylo ve skutečnosti využito:
Obecněji je možný libovolný počet „použitých vláken“ mezi dvěma extrémy (16 a 24 pro tento plán dotazů):
Nakonec si uvědomte, že vlákno, které spouští sériovou část plánu nalevo od posledního Gather Streams, se nepočítá v součtu paralelního vlákna. Nejedná se o další vlákno přidané pro paralelní provádění.
Poslední myšlenky
Krása modelu výměny používaného SQL Serverem k implementaci paralelního provádění spočívá v tom, že veškerá složitost ukládání do vyrovnávací paměti a přesouvání řádků mezi vlákny je skryta uvnitř operátorů výměny (paralelismus). Zbytek plánu je rozdělen do úhledných „větví“ ohraničených výměnami. V rámci pobočky se každý operátor chová stejně jako v sériovém plánu – téměř ve všech případech nemají operátoři poboček povědomí o tom, že širší plán vůbec používá paralelní provádění.
Klíčem k pochopení paralelního provádění je (mentálně) rozdělit paralelní plán na hranice výměny a představit si každou větev jako samostatný DOP sériový plány, všechny provádějí souběžnost na odlišné podmnožině řádků. Pamatujte zejména na to, že každý takový sériový plán provozuje všechny operátory v dané větvi – SQL Server ne spustit každý operátor ve vlastním vláknu!
Pochopení toho nejpodrobnějšího chování vyžaduje trochu přemýšlení, zejména pokud jde o to, jak jsou řádky směrovány v rámci výměn a jak engine zaručuje správné výsledky, ale většina věcí, které stojí za to znát, vyžaduje trochu přemýšlení, ne?