Indexovaná zobrazení lze vytvořit v jakékoli edici SQL Server, ale pokud z nich chcete co nejlépe využít, je třeba mít na paměti řadu chování.
Automatické statistiky vyžadují nápovědu NOEXPAND
SQL Server může automaticky vytvářet statistiky, které pomáhají s odhadem mohutnosti a rozhodováním na základě nákladů během optimalizace dotazů. Tato funkce funguje s indexovanými pohledy i se základními tabulkami, ale pouze v případě, že je pohled explicitně pojmenován v dotazu a NOEXPAND nápověda je specifikována. (Ke každému indexu v pohledu je vždy přidružen objekt statistiky, jedná se zde o automatické generování a udržování statistik, které nejsou spojeny s indexem.)
Pokud jste zvyklí pracovat s nepodnikovými edicemi SQL Serveru, možná jste si tohoto chování dříve nevšimli. Nižší edice SQL Serveru vyžadují NOEXPAND nápověda k vytvoření plánu dotazů, který přistupuje k indexovanému zobrazení. Když NOEXPAND je zadáno, automatické statistiky se vytvářejí na indexovaných pohledech přesně tak, jak se to děje u běžných tabulek.
Příklad – Standard Edition s NOEXPAND
Pomocí SQL Server 2012 Standard Edition a ukázkové databáze Adventure Works nejprve vytvoříme pohled, který spojí dvě prodejní tabulky a vypočítá celkové množství objednávky na zákazníka a produkt:
VYTVOŘIT ZOBRAZENÍ dbo.CustomerOrdersWITH SCHEMABINDING ASSELECT SOH.CustomerID, SOD.ProductID, OrderQty =SUMA(SOD.OrderQty), NumRows =COUNT_BIG(*)FROM Sales.SalesOrderDetail AS SODJOINderlessOSOales. .SalesOrderIDGROUP BY SOH.CustomerID, SOD.ProductID;
Aby tento pohled podporoval statistiku, musíme ji zhmotnit přidáním jedinečného seskupeného indexu. Je zaručeno, že kombinace ID zákazníka a ID produktu bude v pohledu jedinečná (podle definice), takže ji použijeme jako klíč. V indexu bychom mohli zadat dva sloupce v obou směrech, ale za předpokladu, že očekáváme, že bude filtrováno více dotazů podle produktu, uděláme ID produktu jako hlavní sloupec. Tato akce také vytvoří statistiku indexu s histogramem sestaveným z hodnot ID produktu.
VYTVOŘTE UNIKÁTNÍ CLUSTERED INDEX cuq NA dbo.CustomerOrders (ProductID, CustomerID);
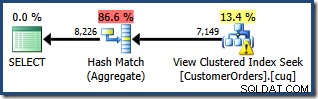
Nyní jsme požádáni, abychom napsali dotaz, který ukazuje celkové množství objednávek na zákazníka pro konkrétní řadu produktů. Očekáváme, že plán provádění využívající indexované zobrazení bude efektivní strategií, protože se vyhne spojení a bude pracovat s daty, která jsou již částečně agregovaná. Protože používáme SQL Server Standard Edition, musíme explicitně specifikovat zobrazení a použít NOEXPAND nápověda k vytvoření plánu dotazů, který přistupuje k indexovanému zobrazení:
VYBERTE CO.CustomerID, SUM(CO.OrderQty)FROM dbo.CustomerOrders JAKO CO S (NOEXPAND)WHERE CO.ProductID MEZI 711 A 718GROUP BY CO.CustomerID;
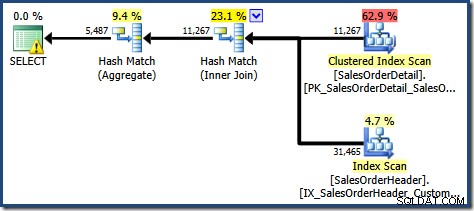
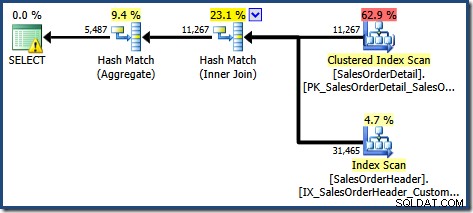
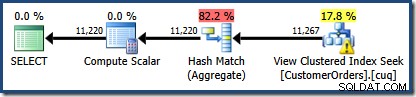
Vytvořený plán provádění ukazuje hledání v indexovaném zobrazení za účelem nalezení řádků pro produkty, které vás zajímají, následované agregací pro výpočet celkového množství na zákazníka:
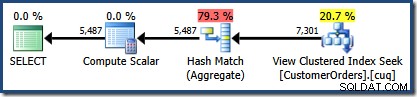
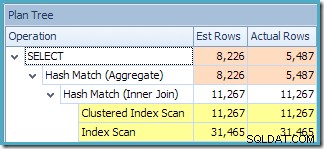
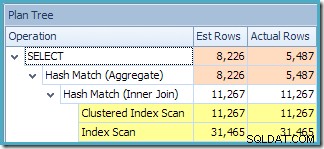
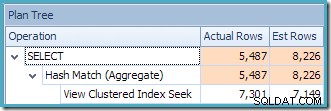
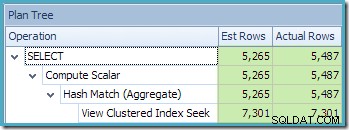
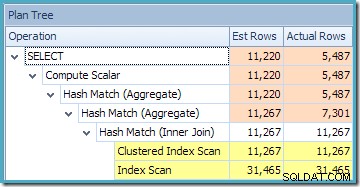
Zobrazení Plan Tree v SQL Sentry Plan Explorer ukazuje, že odhad mohutnosti je přesně správný pro hledání indexovaného zobrazení a velmi dobrý pro výsledek agregace:
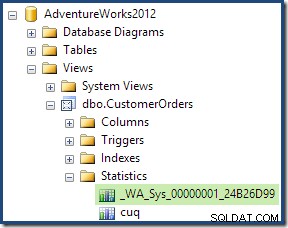
Jako součást procesu kompilace a optimalizace pro tento dotaz SQL Server vytvořil další objekt statistiky ve sloupci Customer ID indexovaného zobrazení. Tato statistika je vytvořena, protože očekávaný počet a distribuce ID zákazníků může být důležitá, například při výběru agregační strategie. Novou statistiku můžeme vidět pomocí Management Studio Object Explorer:
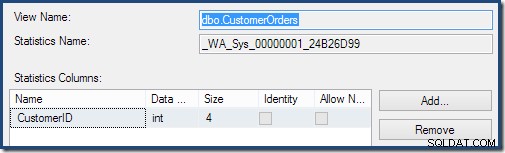
Dvojitým kliknutím na objekt statistiky potvrdíte, že byl vytvořen ze sloupce Číslo zákazníka v zobrazení (nikoli základní tabulka):
Indexovaná zobrazení mohou zlepšit odhad mohutnosti
Stále používáme Standard Edition, nyní vypustíme a znovu vytvoříme indexované zobrazení (což také odstraní statistiky zobrazení) a provedeme dotaz znovu, tentokrát s NOEXPAND nápověda okomentována:
SELECT CO.CustomerID, SUM(CO.OrderQty)FROM dbo.CustomerOrders AS CO --WITH (NOEXPAND)WHERE CO.ProductID BETWEEN 711 AND 718GROUP BY CO.CustomerID;
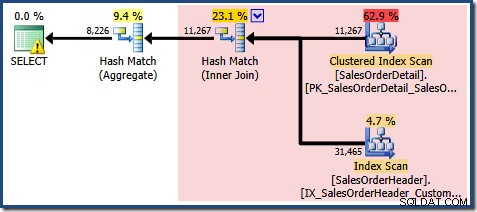
Podle očekávání při použití Standard Edition bez NOEXPAND , výsledný plán dotazů funguje na základních tabulkách spíše než přímo na zobrazení:

Výstražný trojúhelník na kořenovém operátoru ve výše uvedeném plánu nás upozorňuje na potenciálně užitečný index v tabulce Podrobnosti prodejní objednávky, který není pro naše současné účely důležitý. Tato kompilace nevytváří žádné statistiky pro indexované zobrazení. Jedinou statistikou zobrazení po kompilaci dotazu je statistika spojená s seskupeným indexem:
Zobrazení stromu plánu pro dotaz ukazuje, že odhad mohutnosti je správný pro dvě skenování tabulky a spojení, ale o něco horší pro ostatní operátory plánu:
Použití indexovaného zobrazení s NOEXPAND nápověda vedla k přesnějším odhadům pro náš testovací dotaz, protože byly k dispozici kvalitnější informace ze statistik zobrazení – zejména statistik souvisejících s indexem zobrazení.
Obecným pravidlem je, že přesnost statistických informací klesá poměrně rychle, když procházejí a jsou modifikovány operátory plánu dotazů. Jednoduché spojení často není v tomto ohledu špatné, ale informace o výsledku agregace často nejsou lepší než kvalifikovaný odhad. Poskytování přesnějších informací optimalizátoru dotazů pomocí statistik indexovaných zobrazení může být užitečnou technikou ke zvýšení kvality a odolnosti plánu.
Pohled bez NOEXPANDu může vytvořit podřadný plán
Výše uvedený plán dotazů (Standardní verze, bez NOEXPAND ) je ve skutečnosti méně optimální, než kdybychom sami napsali dotaz proti základním tabulkám, než abychom umožnili optimalizátoru dotazů rozšířit pohled. Dotaz níže vyjadřuje stejný logický požadavek, ale neodkazuje na pohled:
SELECT SOH.CustomerID, SUM(OrderQty)FROM Sales.SalesOrderHeader AS SOHJOIN Sales.SalesOrderDetail AS SOD ON SOD.SalesOrderID =SOH.SalesOrderIDWHERE SOD.ProductID BETWEEN 711 ANDOHJOIN> SOHpreGROUP;Tento dotaz vytvoří následující plán provádění:
Tento plán obsahuje o jednu agregační operaci méně než dříve. Když bylo použito rozšíření zobrazení, optimalizátor dotazů bohužel nedokázal odstranit nadbytečnou agregační operaci, což vedlo k méně efektivnímu plánu provádění. Konečný odhad mohutnosti pro nový dotaz je také o něco lepší, než když se na indexované zobrazení odkazovalo bez
NOEXPAND:
Nicméně nejlepší odhady jsou stále ty, které jsou vytvořeny při odkazování na indexované zobrazení pomocí
NOEXPAND(pro usnadnění opakování níže):
Enterprise Edition a View Matching
V instanci Enterprise Edition může být optimalizátor dotazů schopen použít indexované zobrazení, i když dotaz explicitně nezmiňuje zobrazení. Pokud je optimalizátor schopen porovnat část stromu dotazů s indexovaným pohledem, může si to vybrat na základě svého odhadu nákladů na použití pohledu či nikoli. Logika porovnávání zobrazení je přiměřeně chytrá, ale má limity, které lze v praxi docela snadno narazit. I když je párování zobrazení úspěšné, může být optimalizátor stále uveden v omyl nepřesnými odhady nákladů.
Nápověda k dotazu EXPAND VIEWS
Počínaje vzácnějšími možnostmi mohou nastat případy, kdy dotaz odkazuje na indexovaný pohled, ale lepší plán by bylo možné získat přístupem k základním tabulkám. Za těchto okolností dotaz nápovědou
EXPAND VIEWSlze použít:VYBERTE CO.CustomerID, SUM(CO.OrderQty)FROM dbo.CustomerOrders JAKO COWHERE CO.ProductID BETWEEN 711 A 718GROUP BY CO.CustomerIDOPTION (ROZŠÍŘIT ZOBRAZENÍ);V Enterprise Edition tento dotaz vytvoří stejný plán jako ve Standard Edition, když
NOEXPANDnápověda byla vynechána (včetně operace redundantní agregace):
Kromě toho
EXPAND VIEWSnápověda je podle mého názoru špatně pojmenovaná. SQL Server vždy rozšiřuje definice zobrazení v dotazu, pokudNOEXPANDnápověda je specifikována.EXPAND VIEWShint zakáže pravidla v optimalizátoru, která mohou odpovídat částem rozbaleného stromu zpět k indexovaným pohledům. Pokud neexistuje žádná nápověda, SQL Server nejprve rozšíří pohled na jeho definici základní tabulky a později zvažuje přiřazení zpět k indexovaným pohledům. Lepší název proEXPAND VIEWSnápověda mohla býtDISABLE INDEXED VIEW MATCHING, protože to je to, co dělá.
EXPAND VIEWSnápověda se pravděpodobně nejčastěji používá k zabránění přiřazování dotazu na základní tabulky k indexovanému zobrazení:SELECT SOH.CustomerID, SUM(OrderQty)FROM Sales.SalesOrderHeader AS SOHJOIN Sales.SalesOrderDetail AS SOD ON SOD.SalesOrderID =SOH.SalesOrderIDWHERE SOD.ProductID BETWEEN 711 AND SOHJOIN;>Výsledkem nápovědy k dotazu je stejný plán provádění a odhady, jaké jsme viděli, když jsme používali Standard Edition a stejný dotaz pouze pro základní tabulku:
Párování a statistika podnikových zobrazení
I ve verzi Enterprise Edition se statistiky neindexového zobrazení stále vytvářejí, pouze pokud je
NOEXPANDpoužívá se nápověda. Aby bylo zcela jasné, funkce porovnávání zobrazení pouze pro podniky nikdy nevede k vytváření nebo aktualizaci statistik zobrazení. Toto neintuitivní chování stojí za to trochu prozkoumat, protože může mít překvapivé vedlejší účinky.Nyní provedeme náš základní dotaz proti pohledu na instanci Enterprise Edition bez jakýchkoli nápověd:
VYBERTE CO.CustomerID, SUM(CO.OrderQty)FROM dbo.CustomerOrders JAKO COWHERE CO.ProductID BETWEEN 711 A 718GROUP BY CO.CustomerID;
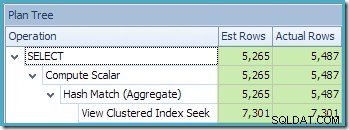
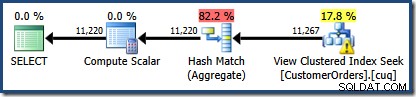
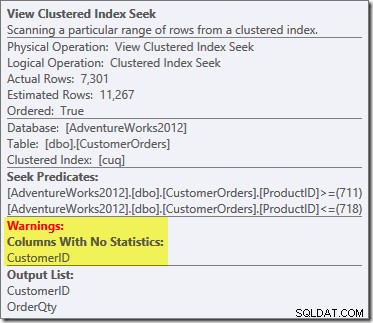
Novinkou je výstražný trojúhelník na View Clustered Index Seek. Popisek zobrazuje podrobnosti:
Nepoužili jsme
NOEXPANDnápověda, takže statistiky ve sloupci Číslo zákazníka v indexovaném zobrazení nebyly automaticky vytvořeny. Statistiky ID zákazníka nejsou v tomto zjednodušeném příkladu ve skutečnosti příliš důležité, ale nebude tomu tak vždy.Zvědavé odhady mohutnosti
Druhou zajímavostí je, že odhady mohutnosti se zdají být horší než jakýkoli případ, s nímž jsme se doposud setkali, včetně příkladů standardní edice.
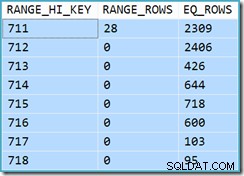
Zpočátku je obtížné zjistit, odkud se vzal odhad mohutnosti pro View Clustered Index Seek (11 267). Očekávali bychom, že odhad bude založen na informacích histogramu ID produktu ze statistik souvisejících se seskupeným indexem zobrazení. Příslušná část tohoto histogramu je uvedena níže:
DBCC SHOW_STATISTICS ('dbo.CustomerOrders', 'cuq') S HISTOGRAMEM;
Vzhledem k tomu, že tabulka nebyla od vytvoření statistiky upravena, očekávali bychom, že odhad bude prostým součtem RANGE_ROWS a EQ_ROWS pro hodnoty ID produktu mezi 711 a 718 (odhad by neměl zahrnovat 28 RANGE_ROWS zobrazených u položky 711 protože tyto řádky existují pod hodnotou klíče 711). Součet zobrazených EQ_ROWS je 7,301. Toto je přesně počet řádků skutečně vrácených zobrazením – odkud tedy pochází odhad 11 267?
Odpověď spočívá ve způsobu, jakým aktuálně funguje párování pohledů. Náš dotaz nespecifikoval
NOEXPANDnápověda, takže počáteční odhady mohutnosti jsou založeny na stromu dotazů s rozšířeným zobrazením. Nejsnáze to zjistíte, když se znovu podíváte na odhadovaný plán pro stejný dotaz pomocíEXPAND VIEWSspecifikováno:
Červeně stínovaná oblast představuje část stromu, která je nahrazena aktivitou přiřazování pohledu. Výstupní kardinalita z této oblasti je 11 267. Nezastíněná část s odhadem 11 220 není ovlivněna párováním pohledů. Toto jsou přesně ty odhady, které jsme chtěli vysvětlit:
Přiřazení pohledu jednoduše nahradilo červeně stínovanou oblast logicky ekvivalentním vyhledáváním v indexovaném pohledu. K přepočtu odhadu mohutnosti nepoužil statistické informace z pohledu.
Do určité míry asi dokážete pochopit, proč by to mohlo fungovat tímto způsobem:obecně není moc důvodů očekávat, že odhad vypočítaný z jedné sady statistických informací je lepší než z jiné. Mohlo by se stát, že statistiky indexovaného zobrazení jsou zde s větší pravděpodobností přesné ve srovnání se statistikami odvozenými po připojení v červeně šrafované oblasti, ale může být složité to zobecnit nebo správně zohlednit, jak rychle různé zdroje statistické informace mohou být zastaralé, protože se mění podkladová data.
Dalo by se také namítnout, že kdybychom si byli tak jisti, že informace indexovaného zobrazení jsou lepší, použili bychom
NOEXPANDnápověda.Ještě zvědavější odhady mohutnosti
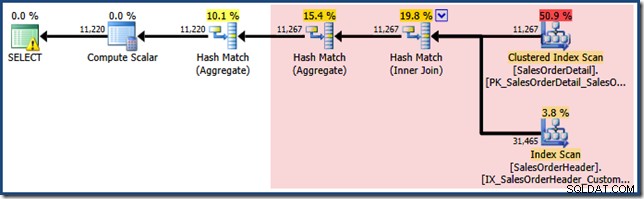
Ještě zajímavější situace nastává u Enterprise Edition, pokud dotaz napíšeme proti základním tabulkám a spoléháme na automatické párování pohledů:
SELECT SOH.CustomerID, SUM(OrderQty)FROM Sales.SalesOrderHeader AS SOHJOIN Sales.SalesOrderDetail AS SOD ON SOD.SalesOrderID =SOH.SalesOrderIDWHERE SOD.ProductID BETWEEN 711 ANDOHJOIN> SOHpreGROUP;
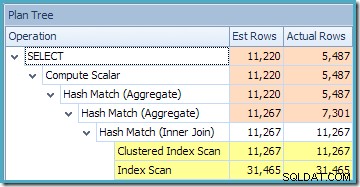
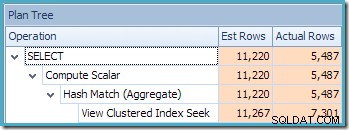
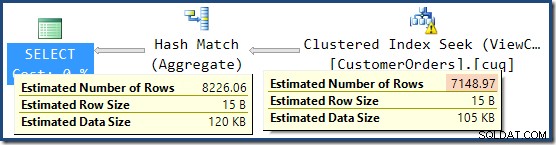
Chybějící upozornění na statistiky je stejné jako dříve a má stejné vysvětlení. Zajímavější funkcí je, že nyní máme nižší odhad počtu řádků vytvořených funkcí View Clustered Index Seek (7 149) a zvýšený odhad počtu řádků vrácených z agregace (8 226).
Abychom to zdůraznili, zdá se, že tento plán dotazů je založen na myšlence, že 7 149 zdrojových řádků lze agregovat a vytvořit tak 8 226 řádků!
Část vysvětlení je stejná jako dříve.
EXPAND VIEWSplán dotazů zobrazující červenou oblast, která bude nahrazena odpovídajícím zobrazením, je uvedena níže:
To vysvětluje, odkud pochází konečný odhad 8 226, ale co odhad 7 149 řádků? Podle výše uvedené logiky se zdá, že pohled by měl ukazovat odhad 11 267 řádků?
Odpověď je, že odhad 7 149 je odhad. Ano, opravdu. Indexované zobrazení obsahuje celkem 79 433 řádků. Procento magického odhadu pro predikát ID produktu BETWEEN je 9 % – což dává 0,09 * 79433 =7148,97 řádků. Plán dotazů SSMS ukazuje, že tento výpočet je přesně správný, dokonce i před zaokrouhlením:
V této situaci se zdá, že optimalizátor SQL Server upřednostnil odhad založený na mohutnosti indexovaného zobrazení před odhadem mohutnosti po připojení z nahrazeného podstromu. Zvědavý.
Shrnutí
Pomocí
NOEXPANDhint zaručuje, že v konečném plánu dotazů bude použit indexovaný pohled, a umožňuje automatické vytváření, udržování a používání neindexových statistik optimalizátorem dotazů. PomocíNOEXPANDtaké zajišťuje, že počáteční odhady mohutnosti jsou založeny na informacích indexovaného zobrazení, nikoli na odvození ze základních tabulek.Pokud
NOEXPANDnení zadáno, jsou odkazy na pohledy vždy nahrazeny jejich definicemi základní tabulky před zahájením kompilace dotazu (a tedy před počátečním odhadem mohutnosti). Pouze v Enterprise SKU mohou být indexované pohledy nahrazeny zpět do stromu dotazů později v procesu optimalizace.
EXPAND VIEWSnápověda k dotazu zabraňuje optimalizátoru provádět porovnávání indexovaného zobrazení Enterprise Edition. To platí bez ohledu na to, zda dotaz původně odkazoval na indexované zobrazení nebo ne. Při provádění shody zobrazení může být za určitých okolností stávající odhad mohutnosti nahrazen odhadem.Statistiky zobrazené jako chybějící v indexovaném pohledu lze vytvořit ručně, ale optimalizátor je obecně nepoužije pro dotazy, které nepoužívají
NOEXPANDnápověda.Použití indexovaných zobrazení může zlepšit odhad mohutnosti, zejména pokud zobrazení obsahuje spojení nebo agregace. Dotazy mají největší šanci těžit z přesnějších statistik zobrazení, pokud
NOEXPANDje zadáno.