Všechny mé letošní příspěvky se týkaly trhavých reakcí na statistiky čekání, ale v tomto příspěvku se od tohoto tématu odchýlím, abych hovořil o konkrétním mém medvědovi:počítadle výkonu očekávané životnosti stránky (kterému budu říkat PLE ).
Co znamená PLE?
Na internetu jsou nejrůznější nesprávná prohlášení o očekávané délce života stránky a nejkřiklavější jsou ta, která uvádějí, že hodnota 300 je prahová hodnota, ze které byste se měli obávat.
Abyste pochopili, proč je toto tvrzení tak zavádějící, musíte pochopit, co PLE vlastně je.
Definice PLE je očekávaná doba v sekundách, po kterou stránka datového souboru načtená do fondu vyrovnávací paměti (mezipaměť stránek datových souborů v paměti) zůstane v paměti, než bude vytlačena z paměti, aby se uvolnilo místo pro jiná data. stránka souboru. Dalším způsobem, jak uvažovat o PLE, je okamžité měření tlaku na oblast vyrovnávací paměti, aby se uvolnilo místo pro stránky čtené z disku. Pro obě tyto definice je lepší vyšší číslo.
Co je to dobrý práh PLE?
PLE 300 znamená, že celý váš fond vyrovnávacích pamětí je efektivně proplachován a znovu načítán každých pět minut. Když společnost Microsoft poprvé poskytla prahovou hodnotu pro PLE 300, kolem roku 2005/2006, mohlo toto číslo dávat větší smysl, protože průměrné množství paměti na serveru bylo mnohem nižší.
V dnešní době, kdy servery běžně mají 64 GB, 128 GB a vyšší množství paměti, by zhruba takové množství dat načtených z disku každých pět minut bylo pravděpodobně příčinou ochromujícího problému s výkonem
Ve skutečnosti pak, v době, kdy se PLE pohybuje na nebo pod 300, je váš server již v hrozné tísni. Začali byste mít obavy, mnohem dříve, než bude PLE tak nízké.
Jakou hranici tedy použít, když byste se měli obávat?
No, o to právě jde. Nemohu vám dát práh, protože toto číslo se bude u každého lišit. Pokud opravdu, ale opravdu chcete použít číslo, můj kolega Jonathan Kehayias přišel se vzorcem:
(Vyrovnávací paměť v GB / 4) x 300I toto číslo je poněkud libovolné a váš počet najetých kilometrů se bude lišit.
Nerada doporučuji nějaká čísla. Moje rada je, abyste změřili své PLE, když je výkon na požadované úrovni – to je prahovou hodnotu, kterou používáte.
Takže se začínáte bát, jakmile PLE klesne pod tuto hranici? Ne. Začnete se bát, když PLE klesne pod tuto hranici a zůstane pod touto hranicí, nebo pokud prudce klesne a vy nevíte proč.
Je to proto, že některé operace způsobí pokles PLE (např. spuštění DBCC CHECKDB nebo přestavby indexu to někdy mohou udělat) a nejsou důvodem k obavám. Ale pokud uvidíte velký pokles PLE a nevíte, co to způsobuje, pak byste se měli znepokojovat.
Možná se ptáte, jak DBCC CHECKDB může způsobit pokles PLE, když se projeví nepříznivě a usilovně se snaží vyhnout vyprázdnění fondu vyrovnávacích pamětí daty, které používá (vysvětlení viz tento příspěvek na blogu). Je to proto, že přidělení paměti pro provedení dotazu pro DBCC CHECKDB je chybně vypočítán nástrojem Query Optimizer a může způsobit velké snížení velikosti zásobníku vyrovnávacích pamětí (paměť pro udělení grantu je odcizena z fondu vyrovnávacích pamětí) a následný pokles PLE.
Jak monitorujete PLE?
Tohle je ten ošemetný kousek. Většina lidí přejde přímo do Buffer Manager performance objekt v PerfMon a sledovat Page life expectancy čelit. Je to správný přístup? S největší pravděpodobností ne.
Řekl bych, že velká většina dnešních serverů používá architekturu NUMA, a to má hluboký vliv na to, jak monitorujete PLE.
Když je zapojen NUMA, fond vyrovnávacích pamětí se rozdělí na uzly vyrovnávací paměti, přičemž na každý uzel NUMA může SQL Server „vidět“ jeden uzel vyrovnávací paměti. Každý uzel bufferu sleduje PLE samostatně a Buffer Manager:Page life expectancy čítač je průměr vyrovnávacího uzlu PLE. Pokud pouze sledujete celkový fond vyrovnávacích pamětí PLE, pak tlak na jeden z uzlů vyrovnávacích pamětí může být maskován průměrováním (probírám to v příspěvku na blogu zde).
Pokud tedy váš server používá NUMA, musíte sledovat individuální Buffer Node:Page life expectancy čítače (pro každý uzel NUMA bude existovat jeden objekt výkonu uzlu vyrovnávací paměti), jinak je dobré sledovat Buffer Manager:Page life expectancy čítač.
Ještě lepší je použít monitorovací nástroj, jako je SQL Sentry Performance Advisor, který zobrazí toto počítadlo jako součást řídicího panelu s přihlédnutím k NUMA uzlům na serveru a umožní vám snadno konfigurovat výstrahy.
Příklady použití nástroje Performance Advisor
Níže je ukázková část snímku obrazovky z Performance Advisor pro systém s jedním uzlem NUMA:
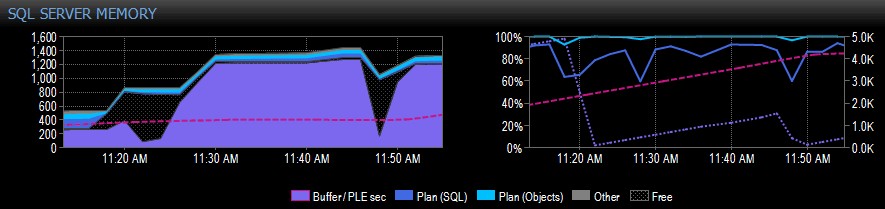
Na pravé straně zachycení je růžová přerušovaná čára PLE mezi 10:30 a asi 11:20 – neustále stoupá až na 5 000 nebo tak nějak, opravdu zdravé číslo. Těsně před 11:20 dochází k velkému poklesu a pak začne znovu stoupat až do 11:45, kde opět klesá.
To je obvykle to, co byste viděli, pokud je fond vyrovnávacích pamětí plný, se všemi použitými stránkami a poté se spustí dotaz, který způsobí načtení velkého množství různých dat z disku, přemístění velké části toho, co je již v paměti, a způsobí prudký pokles PLE. Pokud nevíte, co něco takového způsobilo, měli byste to prozkoumat, jak popisuji níže.
Jako druhý příklad níže uvedený snímek obrazovky pochází z jednoho z našich klientů Remote DBA, kde má server dva uzly NUMA (můžete vidět, že jsou zde dvě fialové čáry PLE) a kde široce používáme Performance Advisor:

Na serveru tohoto klienta se každé ráno kolem 5:00 spustí úloha údržby indexu a kontroly konzistence, která způsobí, že PLE klesne v obou vyrovnávacích uzlech. Toto je očekávané chování, takže není potřeba to zkoumat, dokud se PLE během dne znovu zvedne.
Co můžete udělat s PLE droppingem?
Pokud příčina poklesu PLE není známa, můžete udělat několik věcí:
- Pokud k problému dochází nyní, zjistěte, které dotazy způsobují čtení, pomocí
sys.dm_os_waiting_tasksDMV, abyste viděli, která vlákna čekají na načtení stránek z disku (tj. vlákna čekající naPAGEIOLATCH_SH) a poté tyto dotazy opravte. - Pokud k problému došlo v minulosti, vyhledejte v sys.dm_exec_query_stats DMV dotazy s vysokým počtem fyzických čtení nebo použijte monitorovací nástroj, který vám tyto informace poskytne (např. zobrazení Top SQL v nástroji Performance Advisor) a pak tyto dotazy opravte.
- Srovnejte pokles PLE s naplánovanými úlohami agenta, které provádějí údržbu databáze.
- Hledejte dotazy s velmi velkým přidělením paměti pro provádění dotazů pomocí
sys.dm_exec_query_memory_grantsDMV a poté tyto dotazy opravte.
Můj předchozí příspěvek zde vysvětluje více o #1 a #2 a skript pro prozkoumání čekání vyskytujících se na serveru a odkaz na jejich plány dotazů je zde.
"Opravit ty dotazy" je nad rámec tohoto příspěvku, takže to nechám na jindy nebo jako cvičení pro čtenáře ☺
Shrnutí
Nenechte se chytit do pasti víry v jakoukoli doporučenou hranici PLE, kterou byste si mohli přečíst online. Nejlepší způsob, jak reagovat na změny PLE, je, když PLE klesne pod jakoukoli vaši úroveň pohodlí je a zůstane tam – to je označení problému s výkonem, který byste měli prozkoumat.
V dalším článku ze série proberu další běžnou příčinu ladění výkonu. Do té doby přejeme hodně štěstí při odstraňování problémů!