Tento článek používá jednoduchý dotaz k prozkoumání některých hlubokých interních informací týkajících se aktualizačních dotazů.
Ukázková data a konfigurace
Níže uvedený ukázkový skript pro vytváření dat vyžaduje tabulku čísel. Pokud ještě jeden z nich nemáte, níže uvedený skript lze použít k jeho efektivnímu vytvoření. Výsledná tabulka čísel bude obsahovat jeden celočíselný sloupec s čísly od jednoho do jednoho milionu:
WITH Ten(N) AS
(
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
)
SELECT TOP (1000000)
n = IDENTITY(int, 1, 1)
INTO dbo.Numbers
FROM Ten T10,
Ten T100,
Ten T1000,
Ten T10000,
Ten T100000,
Ten T1000000;
ALTER TABLE dbo.Numbers
ADD CONSTRAINT PK_dbo_Numbers_n
PRIMARY KEY CLUSTERED (n)
WITH (SORT_IN_TEMPDB = ON, MAXDOP = 1, FILLFACTOR = 100); Skript níže vytvoří seskupenou ukázkovou datovou tabulku s 10 000 ID, s přibližně 100 různými daty zahájení na ID. Sloupec koncového data je zpočátku nastaven na pevnou hodnotu '99991231'.
CREATE TABLE dbo.Example
(
SomeID integer NOT NULL,
StartDate date NOT NULL,
EndDate date NOT NULL
);
GO
INSERT dbo.Example WITH (TABLOCKX)
(SomeID, StartDate, EndDate)
SELECT DISTINCT
1 + (N.n % 10000),
DATEADD(DAY, 50000 * RAND(CHECKSUM(NEWID())), '20010101'),
CONVERT(date, '99991231', 112)
FROM dbo.Numbers AS N
WHERE
N.n >= 1
AND N.n <= 1000000
OPTION (MAXDOP 1);
CREATE CLUSTERED INDEX
CX_Example_SomeID_StartDate
ON dbo.Example
(SomeID, StartDate)
WITH (MAXDOP = 1, SORT_IN_TEMPDB = ON); Zatímco body uvedené v tomto článku platí obecně pro všechny aktuální verze SQL Serveru, níže uvedené konfigurační informace lze použít k zajištění podobných plánů provádění a efektů výkonu:
- SQL Server 2012 Service Pack 3 x64 Developer Edition
- Max. paměť serveru nastavena na 2048 MB
- Čtyři logické procesory dostupné instanci
- Žádné příznaky trasování nejsou povoleny
- Výchozí úroveň izolace potvrzeného čtení
- Možnosti databáze RCSI a SI jsou zakázány
Hash Aggregate Spills
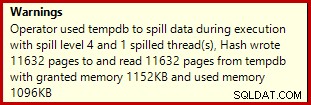
Pokud výše uvedený skript pro vytváření dat spustíte s povolenými skutečnými plány provádění, může se agregace hash přenést do databáze tempdb a vygenerovat ikonu varování:

Při spuštění na SQL Server 2012 Service Pack 3 se další informace o úniku zobrazí v popisku:
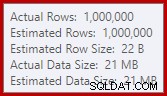
Tento únik může být překvapivý, vzhledem k tomu, že odhady vstupních řádků pro hash Match jsou přesně správné:
Jsme zvyklí porovnávat odhady na vstupu pro řazení a spojení hash (pouze vstup sestavení), ale dychtivé agregace hash se liší. Agregát hash funguje tak, že shromažďuje seskupené řádky výsledků v tabulce hash, takže je to počet výstupů řádky, které jsou důležité:
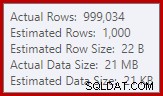
Odhad mohutnosti v SQL Server 2012 dělá poměrně špatný odhad počtu různých očekávaných hodnot (1 000 oproti 999 034 skutečným); hash agregát se v důsledku toho rekurzivně přelévá na úroveň 4 za běhu. „Nový“ odhad mohutnosti dostupný v SQL Serveru 2014 a novějším náhodou vytváří přesnější odhad pro výstup hash v tomto dotazu, takže v takovém případě neuvidíte přelití hash:

Počet skutečných řádků se pro vás může mírně lišit, vzhledem k použití generátoru pseudonáhodných čísel ve skriptu. Důležitým bodem je, že úniky Hash Aggregate závisí na počtu jedinečných výstupních hodnot, nikoli na velikosti vstupu.
Specifikace aktualizace
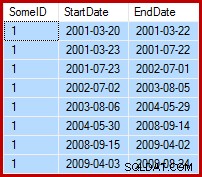
Úkolem je aktualizovat ukázková data tak, aby koncová data byla nastavena na den před následujícím počátečním datem (na SomeID). Například prvních několik řádků ukázkových dat může před aktualizací vypadat takto (všechna data ukončení nastavena na 9999-12-31):

Po aktualizaci pak takto:
1. Baseline Update Query
Jeden přiměřeně přirozený způsob, jak vyjádřit požadovanou aktualizaci v T-SQL, je následující:
UPDATE dbo.Example WITH (TABLOCKX)
SET EndDate =
ISNULL
(
(
SELECT TOP (1)
DATEADD(DAY, -1, E2.StartDate)
FROM dbo.Example AS E2 WITH (TABLOCK)
WHERE
E2.SomeID = dbo.Example.SomeID
AND E2.StartDate > dbo.Example.StartDate
ORDER BY
E2.StartDate ASC
),
CONVERT(date, '99991231', 112)
)
OPTION (MAXDOP 1); Plán provádění (skutečného) po provedení je:
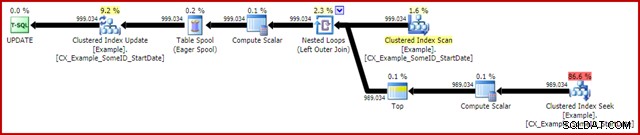
Nejpozoruhodnější funkcí je použití Eager Table Spool k zajištění Halloweenské ochrany. To je nutné pro správnou funkci zde kvůli samopřipojení cílové tabulky aktualizace. Výsledkem je, že vše napravo od zařazování je spuštěno až do konce a ukládají se všechny informace potřebné k provádění změn v pracovní tabulce tempdb. Jakmile je operace čtení dokončena, obsah pracovní tabulky se přehraje, aby se změny aplikovaly v iterátoru aktualizace klastrovaného indexu.
Výkon
Abychom se zaměřili na maximální výkonnostní potenciál tohoto plánu provádění, můžeme stejný aktualizační dotaz spustit vícekrát. Je zřejmé, že pouze první spuštění povede k jakýmkoli změnám v datech, ale to se ukazuje jako nepodstatné. Pokud vám to vadí, můžete před každým spuštěním obnovit sloupec data ukončení pomocí následujícího kódu. Obecné body, které uvedu, nezávisí na počtu skutečně provedených změn dat.
UPDATE dbo.Example WITH (TABLOCKX) SET EndDate = CONVERT(date, '99991231', 112);
Při deaktivovaném shromažďování plánu provádění, všech požadovaných stránkách ve fondu vyrovnávacích pamětí a bez resetování hodnot data ukončení mezi spuštěními se tento dotaz obvykle spustí přibližně za 5700 ms na mém notebooku. Výstup statistiky IO je následující:(čtení dopředu a čítače LOB byly nulové a jsou z prostorových důvodů vynechány)
Table 'Example'. Scan count 999035, logical reads 6186219, physical reads 0 Table 'Worktable'. Scan count 1, logical reads 2895875, physical reads 0
Počet skenování představuje, kolikrát byla operace skenování zahájena. Pro tabulku Příklad je to 1 pro prohledávání klastrového indexu a 999 034 pro pokaždé, když je korelované hledání klastrovaného indexu odraženo. Pracovní stůl používaný Eager Spool má skenovací operaci spuštěnou pouze jednou.
Logické čtení
Zajímavější informací ve výstupu IO je počet logických čtení:přes 6 milionů pro tabulku Příklad a téměř 3 miliony pro pracovní stůl.
Příklad logického čtení tabulky je většinou spojen s hledáním a aktualizací. Hledání zahrnuje 3 logická čtení pro každou iteraci:1 každé pro kořenovou, střední a listovou úroveň indexu. Aktualizace rovněž stojí 3 přečtení při každém řádku se aktualizuje, když motor prochází b-strom dolů, aby našel cílový řádek. Clustered Index Scan má na svědomí pouze několik tisíc přečtení, jedno na stránku číst.
Pracovní stůl Spool je také vnitřně strukturován jako b-strom a počítá více čtení, když cívka lokalizuje pozici vložení, zatímco spotřebovává svůj vstup. Možná je to kontraintuitivní, že zařazování nepočítá žádná logická čtení, když je načítána, aby řídila aktualizaci seskupeného indexu. Je to jednoduše důsledek implementace:logické čtení se započítává vždy, když kód spustí BPool::Get metoda. Zápis do spool volá tuto metodu na každé úrovni indexu; čtení z cívky se řídí jinou cestou kódu, která nevolá BPool::Get vůbec.
Všimněte si také, že výstup statistiky IO hlásí jediný součet pro tabulku Příklad, přestože k ní přistupují tři různé iterátory v plánu provádění (Skenovat, Hledat a Aktualizovat). Tento poslední fakt ztěžuje korelaci logických čtení s iterátorem, který je způsobil. Doufám, že toto omezení bude vyřešeno v budoucí verzi produktu.
2. Aktualizace pomocí čísel řádků
Další způsob, jak vyjádřit aktualizační dotaz, zahrnuje očíslování řádků podle ID a spojení:
WITH Numbered AS
(
SELECT
E.SomeID,
E.StartDate,
E.EndDate,
rn = ROW_NUMBER() OVER (
PARTITION BY E.SomeID
ORDER BY E.StartDate ASC)
FROM dbo.Example AS E
)
UPDATE This WITH (TABLOCKX)
SET EndDate =
ISNULL
(
DATEADD(DAY, -1, NextRow.StartDate),
CONVERT(date, '99991231', 112)
)
FROM Numbered AS This
LEFT JOIN Numbered AS NextRow WITH (TABLOCK)
ON NextRow.SomeID = This.SomeID
AND NextRow.rn = This.rn + 1
OPTION (MAXDOP 1, MERGE JOIN); Plán po provedení je následující:
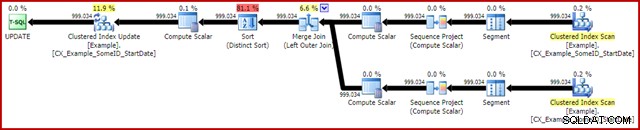
Tento dotaz obvykle běží za 2950 ms na mém notebooku, což je ve srovnání s 5700 ms (za stejných okolností) příznivým pro původní prohlášení o aktualizaci. Výstup statistiky IO je:
Table 'Example'. Scan count 2, logical reads 3001808, physical reads 0 Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0
To ukazuje dvě skenování zahájená pro tabulku Příklad (jedno pro každý iterátor Clustered Index Scan). Logická čtení jsou opět souhrnem všech iterátorů, které přistupují k této tabulce v plánu dotazů. Stejně jako dříve není možné určit, který iterátor (ze dvou skenů a aktualizace) byl zodpovědný za 3 miliony přečtení.
Přesto vám mohu říci, že Clustered Index Scans počítá každý pouze s několika tisíci logickými čteními. Naprostá většina logických čtení je způsobena tím, že aktualizace Clustered Index Update projde indexem B-strom dolů, aby nalezla pozici aktualizace pro každý řádek, který zpracovává. Pro tuto chvíli mě budete muset vzít za slovo; další vysvětlení bude brzy k dispozici.
Nevýhody
To je v podstatě konec dobrých zpráv pro tuto formu dotazu. Funguje mnohem lépe než originál, ale je mnohem méně uspokojivý z řady dalších důvodů. Hlavní problém je způsoben omezením optimalizátoru, což znamená, že nerozpozná, že operace číslování řádků vytváří jedinečné číslo pro každý řádek v oddílu SomeID.
Tento jednoduchý fakt vede k řadě nežádoucích důsledků. Jednak je sloučení spojení nakonfigurováno tak, aby běželo v režimu spojení mnoho k mnoha. To je důvod pro (nepoužitou) pracovní tabulku ve statistice IO (sloučení many-to-many vyžaduje pracovní tabulku pro duplicitní přetočení klíče spojení). Očekávání spojení many-to-many také znamená, že odhad mohutnosti pro výstup spojení je beznadějně nesprávný:
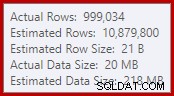
V důsledku toho řazení požaduje příliš mnoho paměti. Vlastnosti kořenového uzlu ukazují, že řazení by chtělo 812 752 KB paměti, ačkoli mu bylo přiděleno pouze 379 440 KB kvůli nastavení omezené maximální paměti serveru (2 048 MB). Řazení ve skutečnosti za běhu využívalo maximálně 58 968 KB:
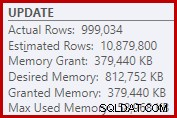
Nadměrné paměťové granty odcizí paměť od jiných produktivních použití a mohou vést k dotazům čekajícím na uvolnění paměti. V mnoha ohledech může být nadměrné přidělení paměti spíše problémem než podceněním.
Omezení optimalizátoru také vysvětluje, proč byla pro dosažení nejlepšího výkonu v dotazu nezbytná nápověda ke sloučení. Bez této nápovědy optimalizátor nesprávně vyhodnotí, že spojení hash by bylo levnější než spojení sloučením s mnoha. Plán spojení hash běží v průměru za 3350 ms.
Jako poslední negativní důsledek si všimněte, že řazení v plánu je odlišné řazení. Nyní existuje několik důvodů pro toto řazení (v neposlední řadě proto, že může poskytnout požadovanou halloweenskou ochranu), ale jde pouze o výrazné Třídit, protože optimalizátor postrádá informace o jedinečnosti. Celkově lze říci, že je těžké mít na tomto plánu realizace kromě výkonu mnoho rád.
3. Aktualizujte pomocí analytické funkce LEAD
Jelikož se tento článek primárně zaměřuje na SQL Server 2012 a novější, můžeme aktualizační dotaz vyjádřit zcela přirozeně pomocí analytické funkce LEAD. V ideálním světě bychom mohli použít velmi kompaktní syntaxi jako:
-- Not allowed
UPDATE dbo.Example WITH (TABLOCKX)
SET EndDate = LEAD(StartDate) OVER (
PARTITION BY SomeID ORDER BY StartDate); Bohužel to není legální. Výsledkem je chybová zpráva 4108, "Funkce v okně se mohou objevit pouze v klauzulích SELECT nebo ORDER BY". To je trochu frustrující, protože jsme doufali v plán provádění, který by se mohl vyhnout samopřipojení (a související aktualizaci Halloween Protection).
Dobrou zprávou je, že se stále můžeme vyhnout samospojení pomocí běžného tabulkového výrazu nebo odvozené tabulky. Syntaxe je trochu podrobnější, ale myšlenka je v podstatě stejná:
WITH CED AS
(
SELECT
E.EndDate,
CalculatedEndDate =
DATEADD(DAY, -1,
LEAD(E.StartDate) OVER (
PARTITION BY E.SomeID
ORDER BY E.StartDate))
FROM dbo.Example AS E
)
UPDATE CED WITH (TABLOCKX)
SET CED.EndDate =
ISNULL
(
CED.CalculatedEndDate,
CONVERT(date, '99991231', 112)
)
OPTION (MAXDOP 1); Plán po provedení je:

To obvykle trvá přibližně 3400 ms na mém notebooku, který je pomalejší než řešení s číslem řádku (2950 ms), ale stále mnohem rychlejší než původní (5700 ms). Jedna věc, která vyčnívá z plánu provádění, je přelévání (opět další informace o přelévání díky vylepšením v SP3):
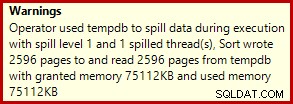
To je docela malý únik, ale stále to může do určité míry ovlivnit výkon. Zvláštní na tom je, že odhad vstupu do řazení je přesně správný:
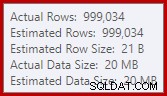
Naštěstí existuje „oprava“ pro tento konkrétní stav v SQL Server 2012 SP2 CU8 (a dalších vydáních – podrobnosti najdete v článku KB). Spuštění dotazu s povolenou opravou a požadovaným příznakem trasování 7470 znamená, že řazení požaduje dostatek paměti, aby bylo zajištěno, že se nikdy nepřesype na disk, pokud nebude překročena odhadovaná velikost vstupního řazení.
Dotaz aktualizace LEAD bez přelití řazení
Pro zpestření níže uvedený dotaz s povolenou opravou používá odvozenou syntaxi tabulky namísto CTE:
UPDATE CED WITH (TABLOCKX)
SET CED.EndDate =
ISNULL
(
CED.CalculatedEndDate, CONVERT(date, '99991231', 112)
)
FROM
(
SELECT
E.EndDate,
CalculatedEndDate =
DATEADD(DAY, -1,
LEAD(E.StartDate) OVER (
PARTITION BY E.SomeID
ORDER BY E.StartDate))
FROM dbo.Example AS E
) AS CED
OPTION (MAXDOP 1, QUERYTRACEON 7470); Nový plán po provedení je:

Odstranění malého úniku zvyšuje výkon z 3400 ms na 3250 ms . Výstup statistiky IO je:
Table 'Example'. Scan count 1, logical reads 2999455, physical reads 0 Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0
Pokud to porovnáte s logickými čteními pro dotaz s číslováním řádků, uvidíte, že se logická čtení snížila z 3 001 808 na 2 999 455 – rozdíl 2 353 čtení. To přesně odpovídá odstranění jediného Clustered Index Scan (jedno čtení na stránku).
Možná si vzpomínáte, jak jsem zmínil, že velká většina logických čtení pro tyto aktualizační dotazy je spojena s aktualizací Clustered Index Update a že skenování bylo spojeno s „pouze několika tisíci čteními“. Nyní to můžeme vidět trochu příměji spuštěním jednoduchého dotazu na počítání řádků v tabulce Příklad:
SET STATISTICS IO ON; SELECT COUNT(*) FROM dbo.Example WITH (TABLOCK); SET STATISTICS IO OFF;
Výstup IO ukazuje přesně rozdíl 2 353 logických čtení mezi číslem řádku a aktualizacemi potenciálních zákazníků:
Table 'Example'. Scan count 1, logical reads 2353, physical reads 0
Další vylepšení?
Dotaz na potenciálního zákazníka (3250 ms) s pevným únikem je stále o něco pomalejší než dotaz s dvojitým číslováním (2950 ms), což může být trochu překvapivé. Intuitivně by se dalo očekávat, že jediné skenování a analytická funkce (Window Spool a Stream Aggregate) bude rychlejší než dvě skenování, dvě sady číslování řádků a spojení.
Bez ohledu na to, věc, která vyčnívá z plánu provádění dotazu pro zájemce, je řazení. Byl také přítomen v dotazu s čísly řádků, kde přispěl Halloweenskou ochranou a také optimalizovaným pořadím řazení pro aktualizaci Clustered Index (která má nastavenou vlastnost DMLRequestSort).
Jde o to, že toto řazení je v plánu dotazů zájemců zcela zbytečné. Není potřeba pro Halloween Protection, protože self-join je pryč. Není potřeba ani pro optimalizované pořadí řazení vložení:řádky se čtou v pořadí klastrových klíčů a v plánu není nic, co by toto pořadí narušovalo. Skutečný problém lze vidět při pohledu na vlastnosti řazení:

Všimněte si tam sekce Řadit podle. Řazení je řazeno podle SomeID a StartDate (sdružené indexové klíče), ale také podle [Uniq1002], což je uniquifier. Je to důsledek toho, že jsme nedeklarovali seskupený index jako jedinečný, i když jsme v dotazu na soubor dat podnikli kroky, abychom zajistili, že kombinace SomeID a StartDate bude ve skutečnosti jedinečná. (Bylo to záměrné, takže bych o tom mohl mluvit.)
I tak se jedná o omezení. Řádky jsou čteny z Clustered Index v pořadí a existují nezbytné interní záruky, aby se optimalizátor mohl bezpečně vyhnout tomuto řazení. Je prostě nedopatřením, že optimalizátor nerozpozná, že příchozí stream je řazen podle uniquifieru a také podle SomeID a StartDate. Uznává, že pořadí (SomeID, StartDate) může být zachováno, ale nikoli (SomeID, StartDate, uniquifier). Znovu doufám, že to bude řešeno v budoucí verzi.
Abychom to vyřešili, můžeme udělat to, co jsme měli udělat na prvním místě:vytvořit seskupený index jako jedinečný:
CREATE UNIQUE CLUSTERED INDEX CX_Example_SomeID_StartDate ON dbo.Example (SomeID, StartDate) WITH (DROP_EXISTING = ON, MAXDOP = 1);
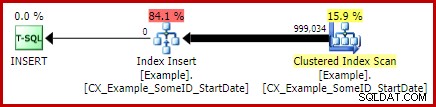
Nechám to jako cvičení pro čtenáře, abych ukázal, že první dva (jiné než LEAD) dotazy z této změny indexování netěží (vynecháno čistě z prostorových důvodů – je toho hodně k pokrytí).
Konečná forma dotazu na aktualizaci potenciálního zákazníka
S jedinečným clusterovaný index na místě, přesně stejný dotaz LEAD (CTE nebo odvozená tabulka, jak chcete) vytváří odhadovaný (před spuštěním) plán, který očekáváme:

To se zdá docela optimální. Jediná operace čtení a zápisu s minimem operátorů mezi nimi. Určitě se zdá mnohem lepší než předchozí verze se zbytečným řazením, které se provedlo za 3250 ms, jakmile byl odstraněn únik, kterému se dalo předejít (za cenu trochu navýšení přidělení paměti).
Plán po provedení (skutečný) je téměř přesně stejný jako plán před provedením:

Všechny odhady jsou přesně správné, kromě výstupu Window Spool, který je mimo o 2 řádky. Statistické IO informace jsou přesně stejné jako před odstraněním řazení, jak byste očekávali:
Table 'Example'. Scan count 1, logical reads 2999455, physical reads 0 Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0
Stručně shrnuto, jediným zjevným rozdílem mezi tímto novým plánem a bezprostředně předchozím je to, že bylo odstraněno řazení (s odhadovaným podílem nákladů téměř 80 %).
Pak může být překvapením, že se nový dotaz – bez řazení – spustí za 5000 ms . To je mnohem horší než 3250 ms s řazením a téměř stejně dlouhé jako 5700 ms původního dotazu na spojení smyčky. Dvouřádkové řešení číslování je stále daleko napřed s 2950 ms.
Vysvětlení
Vysvětlení je poněkud esoterické a týká se způsobu, jakým se zachází se západkami pro nejnovější dotaz. Tento efekt můžeme ukázat několika způsoby, ale nejjednodušší je pravděpodobně podívat se na statistiky čekání a blokování pomocí DMV:
DBCC SQLPERF('sys.dm_os_wait_stats', CLEAR);
DBCC SQLPERF('sys.dm_os_latch_stats', CLEAR);
WITH CED AS
(
SELECT
E.EndDate,
CalculatedEndDate =
DATEADD(DAY, -1,
LEAD(E.StartDate) OVER (
PARTITION BY E.SomeID
ORDER BY E.StartDate))
FROM dbo.Example AS E
)
UPDATE CED WITH (TABLOCKX)
SET CED.EndDate =
ISNULL
(
CED.CalculatedEndDate,
CONVERT(date, '99991231', 112)
)
OPTION (MAXDOP 1);
SELECT * FROM sys.dm_os_latch_stats AS DOLS
WHERE DOLS.waiting_requests_count > 0
ORDER BY DOLS.latch_class;
SELECT * FROM sys.dm_os_wait_stats AS DOWS
WHERE DOWS.waiting_tasks_count > 0
ORDER BY DOWS.waiting_tasks_count DESC; Když není seskupený index jedinečný a v plánu je řazení, nedochází k žádným významným čekáním, pouze k několika čekáním PAGEIOLATCH_UP a očekávaným hodnotám SOS_SCHEDULER_YIELD.
Když je seskupený index jedinečný a seřazení je odstraněno, čekání je:
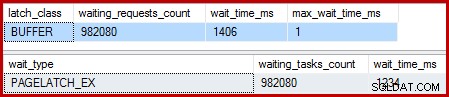
Existuje 982 080 exkluzivních zámků stránek s čekací dobou, která v podstatě vysvětluje celou dobu provádění navíc. Pro zdůraznění, to je téměř jedno čekání na západku na každý aktualizovaný řádek! Můžeme očekávat změnu západky na řádek, ale ne čekání západky , zvláště když je testovací dotaz jedinou aktivitou na instanci. Čekání na západku jsou krátké, ale je jich strašně moc.
Líné západky
Po provedení dotazu s připojeným debuggerem a analyzátorem je vysvětlení následující.
Clustered Index Scan používá líné západky – optimalizace, která znamená, že zámky se uvolní pouze tehdy, když jiné vlákno vyžaduje přístup ke stránce. Normálně se západky uvolní ihned po čtení nebo zápisu. Líné západky optimalizují případ, kdy by skenování celé stránky jinak získalo a uvolnilo stejnou západku stránky pro každý řádek. Při použití líného latch bez sporu se pro celou stránku použije pouze jeden latch.
Problém je v tom, že zřetězená povaha prováděcího plánu (žádné blokující operátory) znamená, že se čtení překrývá se zápisy. Když se aktualizace Clustered Index Update pokusí získat EX latch pro úpravu řádku, téměř vždy zjistí, že stránka je již latched SH (líná latch přijatá Clustered Index Scan). Tato situace má za následek čekání na blokování.
V rámci přípravy na čekání a přepnutí na další spustitelnou položku v plánovači je kód opatrný, aby uvolnil všechny líné západky. Uvolnění líné západky signalizuje prvnímu způsobilému číšníkovi, kterým je náhodou on sám. Máme tedy podivnou situaci, kdy se vlákno zablokuje, uvolní svou línou západku a poté si signalizuje, že je znovu spustitelné. Vlákno se znovu zvedne a pokračuje, ale až poté, co byla provedena všechna ta promarněná práce pozastavení a přepnutí, signálu a obnovení. Jak jsem řekl dříve, čekání je krátké, ale je jich hodně.
Pokud vím, tento zvláštní sled událostí je záměrný a má dobré interní důvody. I tak ale nelze uniknout tomu, že zde má poměrně dramatický vliv na výkon. Udělám nějaké dotazy ohledně toho a aktualizuji článek, pokud bude možné učinit veřejné prohlášení. Mezitím může být u zřetězených aktualizačních dotazů třeba dávat pozor na nadměrné čekání na samozablokování, i když z pohledu autora dotazu není jasné, co by se s tím mělo dělat.
Znamená to, že přístup dvojitého číslování řádků je to nejlepší, co můžeme pro tento dotaz udělat? Ne tak docela.
4. Ruční halloweenská ochrana
Tato poslední možnost může znít a vypadat trochu bláznivě. Obecnou myšlenkou je zapsat všechny informace potřebné k provedení změn proměnné tabulky a poté provést aktualizaci jako samostatný krok.
Pro lepší popis tomu říkám „manuální HP“ přístup, protože je koncepčně podobný zápisu všech změnových informací do Eager Table Spool (jak je vidět v prvním dotazu) před spuštěním aktualizace z tohoto Spoolu.
Každopádně kód je následující:
DECLARE @U AS table
(
SomeID integer NOT NULL,
StartDate date NOT NULL,
NewEndDate date NULL,
PRIMARY KEY CLUSTERED (SomeID, StartDate)
);
INSERT @U
(SomeID, StartDate, NewEndDate)
SELECT
E.SomeID,
E.StartDate,
DATEADD(DAY, -1,
LEAD(E.StartDate) OVER (
PARTITION BY E.SomeID
ORDER BY E.StartDate))
FROM dbo.Example AS E WITH (TABLOCK)
OPTION (MAXDOP 1);
UPDATE E WITH (TABLOCKX)
SET E.EndDate =
ISNULL
(
U.NewEndDate, CONVERT(date, '99991231', 112)
)
FROM dbo.Example AS E
JOIN @U AS U
ON U.SomeID = E.SomeID
AND U.StartDate = E.StartDate
OPTION (MAXDOP 1, MERGE JOIN); Tento kód záměrně používá proměnnou tabulky abyste se vyhnuli nákladům na automaticky vytvářené statistiky, které by vznikly při použití dočasné tabulky. Zde je to v pořádku, protože znám tvar plánu, který chci, a nezávisí to na odhadech nákladů nebo statistických informacích.
Jedinou nevýhodou proměnné tabulky (bez příznaku trasování) je, že optimalizátor obvykle odhadne jeden řádek a pro aktualizaci zvolí vnořené smyčky. Abych tomu zabránil, použil jsem nápovědu ke sloučení. Opět je to dáno tím, že přesně známe tvar plánu, kterého má být dosaženo.
Plán po spuštění pro vložení proměnné tabulky vypadá úplně stejně jako dotaz, který měl problém s čekáním na blokování:

Výhodou tohoto plánu je, že nemění stejnou tabulku, ze které čte. Není vyžadována žádná halloweenská ochrana a neexistuje žádná možnost rušení západky. Kromě toho existují významné vnitřní optimalizace pro objekty tempdb (uzamykání a protokolování) a jsou také použity další běžné optimalizace hromadného načítání. Pamatujte, že hromadné optimalizace jsou k dispozici pouze pro vložení, nikoli pro aktualizace nebo odstranění.
Plán po provedení pro prohlášení o aktualizaci je:
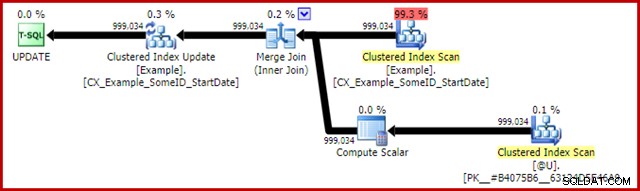
Sloučit spojení zde je efektivní typ one-to-many. Přesněji řečeno, tento plán se kvalifikuje pro speciální optimalizaci, která znamená, že skenování indexu seskupení a aktualizace indexu clusteru sdílejí stejnou sadu řádků. Důležitým důsledkem je, že aktualizace již nemusí vyhledávat řádek k aktualizaci – je již správně umístěn při čtení. To ušetří spoustu logických čtení (a další aktivity) při aktualizaci.
V normálních prováděcích plánech není nic, co by ukazovalo, kde je tato optimalizace sdílené sady řádků použita, ale povolením nedokumentovaného příznaku trasování 8666 se v Aktualizaci a skenování zpřístupní další vlastnosti, které ukazují, že se používá sdílení sady řádků, a že jsou podniknuty kroky k zajištění bezpečnosti aktualizace. z Halloweenského problému.
Výstup statistiky IO pro dva dotazy je následující:
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0 Table 'Example'. Scan count 1, logical reads 2353, physical reads 0 (999034 row(s) affected) Table 'Example'. Scan count 1, logical reads 2353, physical reads 0 Table '#B9C034B8'. Scan count 1, logical reads 2353, physical reads 0
Obě čtení tabulky Příklad zahrnují jediné skenování a jedno logické čtení na stránku (viz výše jednoduchý dotaz na počítání řádků). Tabulka #B9C034B8 je název interního objektu tempdb, který podporuje proměnnou tabulky. Celkové logické čtení pro oba dotazy je 3 * 2353 =7 059. Pracovní stůl je vnitřní úložiště v paměti, které používá Window Spool.
Typická doba provádění tohoto dotazu je 2300 ms . Konečně tu máme něco, co překonává dotaz na dvojité číslování řádků (2950 ms), i když se to může zdát nepravděpodobné.
Poslední myšlenky
Mohou existovat ještě lepší způsoby, jak napsat tuto aktualizaci, které fungují ještě lépe než „ruční řešení HP“ výše. Výsledky výkonu se mohou dokonce lišit na vašem hardwaru a konfiguraci serveru SQL, ale ani jeden z nich není hlavním bodem tohoto článku. To neznamená, že nemám zájem vidět lepší dotazy nebo srovnání výkonu – ano.
Jde o to, že uvnitř SQL Serveru se toho děje mnohem víc, než je odhaleno v plánech provádění. Doufejme, že některé podrobnosti probírané v tomto poměrně dlouhém článku budou pro některé lidi zajímavé nebo dokonce užitečné.
Je dobré mít očekávání ohledně výkonu a vědět, jaké plošné tvary a vlastnosti jsou obecně prospěšné. Tento druh zkušeností a znalostí vám dobře poslouží pro 99 % nebo více dotazů, které budete kdy požádáni, abyste naladili. Někdy je však dobré zkusit něco trochu divného nebo neobvyklého, abyste viděli, co se stane, a potvrdili tato očekávání.