Odstraňování a prevence fragmentace indexu je již dlouho součástí běžných operací údržby databáze, a to nejen na serveru SQL Server, ale na mnoha platformách. Fragmentace indexu ovlivňuje výkon z mnoha důvodů a většina lidí mluví o účincích náhodných malých bloků I/O, které se mohou fyzicky stát diskovým úložištím, jako o něčem, čemu je třeba se vyhnout. Obecným problémem ohledně fragmentace indexu je to, že ovlivňuje výkon skenování omezením velikosti vstupů/výstupů pro čtení napřed. Na základě tohoto omezeného chápání problémů, které fragmentace indexu způsobuje, někteří lidé začali šířit myšlenku, že fragmentace indexu u zařízení SSD (Solid State Storage) nezáleží a že fragmentaci indexu můžete do budoucna prostě ignorovat.
Z několika důvodů tomu tak však není. Tento článek vysvětlí a předvede jeden z těchto důvodů:fragmentace indexu může nepříznivě ovlivnit volbu plánu provádění pro dotazy. K tomu dochází, protože fragmentace indexu obecně vede k tomu, že index má více stránek (tyto stránky navíc pocházejí z rozdělení stránky operace, jak je popsáno v tomto příspěvku na tomto webu), a proto má optimalizátor dotazů SQL Server za použití tohoto indexu vyšší náklady.
Podívejme se na příklad.
První věc, kterou musíme udělat, je vytvořit vhodnou testovací databázi a datovou sadu, která se použije k prozkoumání toho, jak může fragmentace indexu ovlivnit výběr plánu dotazů na serveru SQL Server. Následující skript vytvoří databázi se dvěma tabulkami s identickými daty, jednou silně fragmentovanou a druhou minimálně fragmentovanou.
USE master;
GO
DROP DATABASE FragmentationTest;
GO
CREATE DATABASE FragmentationTest;
GO
USE FragmentationTest;
GO
CREATE TABLE GuidHighFragmentation
(
UniqueID UNIQUEIDENTIFIER DEFAULT NEWID() PRIMARY KEY,
FirstName nvarchar(50) NOT NULL,
LastName nvarchar(50) NOT NULL
);
GO
CREATE NONCLUSTERED INDEX IX_GuidHighFragmentation_LastName
ON GuidHighFragmentation(LastName);
GO
CREATE TABLE GuidLowFragmentation
(
UniqueID UNIQUEIDENTIFIER DEFAULT NEWSEQUENTIALID() PRIMARY KEY,
FirstName nvarchar(50) NOT NULL,
LastName nvarchar(50) NOT NULL
);
GO
CREATE NONCLUSTERED INDEX IX_GuidLowFragmentation_LastName
ON GuidLowFragmentation(LastName);
GO
INSERT INTO GuidHighFragmentation (FirstName, LastName)
SELECT TOP 100000 a.name, b.name
FROM master.dbo.spt_values AS a
CROSS JOIN master.dbo.spt_values AS b
WHERE a.name IS NOT NULL
AND b.name IS NOT NULL
ORDER BY NEWID();
GO 70
INSERT INTO GuidLowFragmentation (UniqueID, FirstName, LastName)
SELECT UniqueID, FirstName, LastName
FROM GuidHighFragmentation;
GO
ALTER INDEX ALL ON GuidLowFragmentation REBUILD;
GO Po opětovném sestavení indexu se můžeme podívat na úrovně fragmentace pomocí následujícího dotazu:
SELECT
OBJECT_NAME(ps.object_id) AS table_name,
i.name AS index_name,
ps.index_id,
ps.index_depth,
avg_fragmentation_in_percent,
fragment_count,
page_count,
avg_page_space_used_in_percent,
record_count
FROM sys.dm_db_index_physical_stats(
DB_ID(),
NULL,
NULL,
NULL,
'DETAILED') AS ps
JOIN sys.indexes AS i
ON ps.object_id = i.object_id
AND ps.index_id = i.index_id
WHERE index_level = 0;
GO Výsledky:

Zde vidíme, že naše GuidHighFragmentation tabulka je z 99 % fragmentovaná a využívá o 31 % více místa na stránce než GuidLowFragmentation tabulky v databázi, přestože mají stejných 7 000 000 řádků dat. Pokud provedeme základní agregační dotaz pro každou z tabulek a porovnáme prováděcí plány na výchozí instalaci (s výchozími možnostmi konfigurace a hodnotami) SQL Server pomocí SentryOne Plan Explorer:
-- Aggregate the data from both tables SELECT LastName, COUNT(*) FROM GuidLowFragmentation GROUP BY LastName; GO SELECT LastName, COUNT(*) FROM GuidHighFragmentation GROUP BY LastName; GO


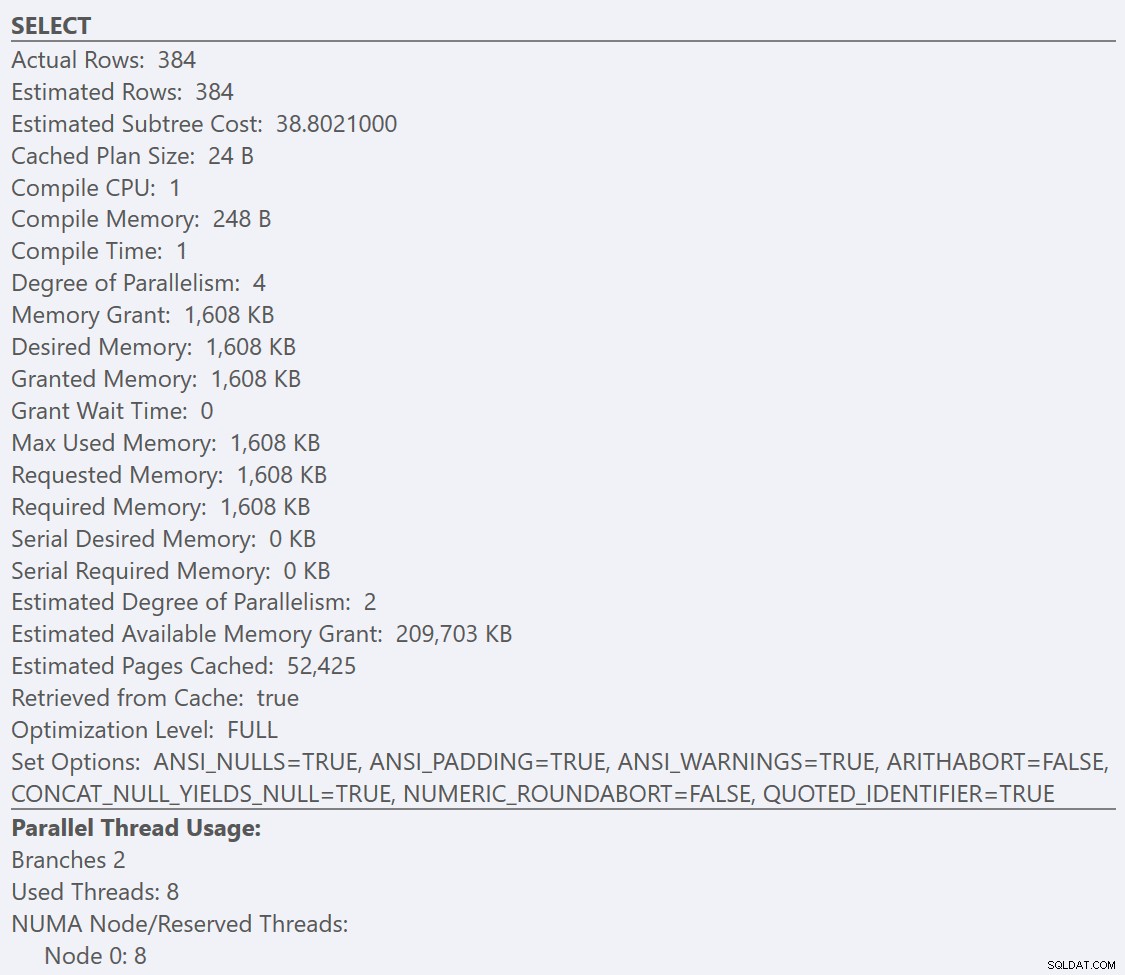

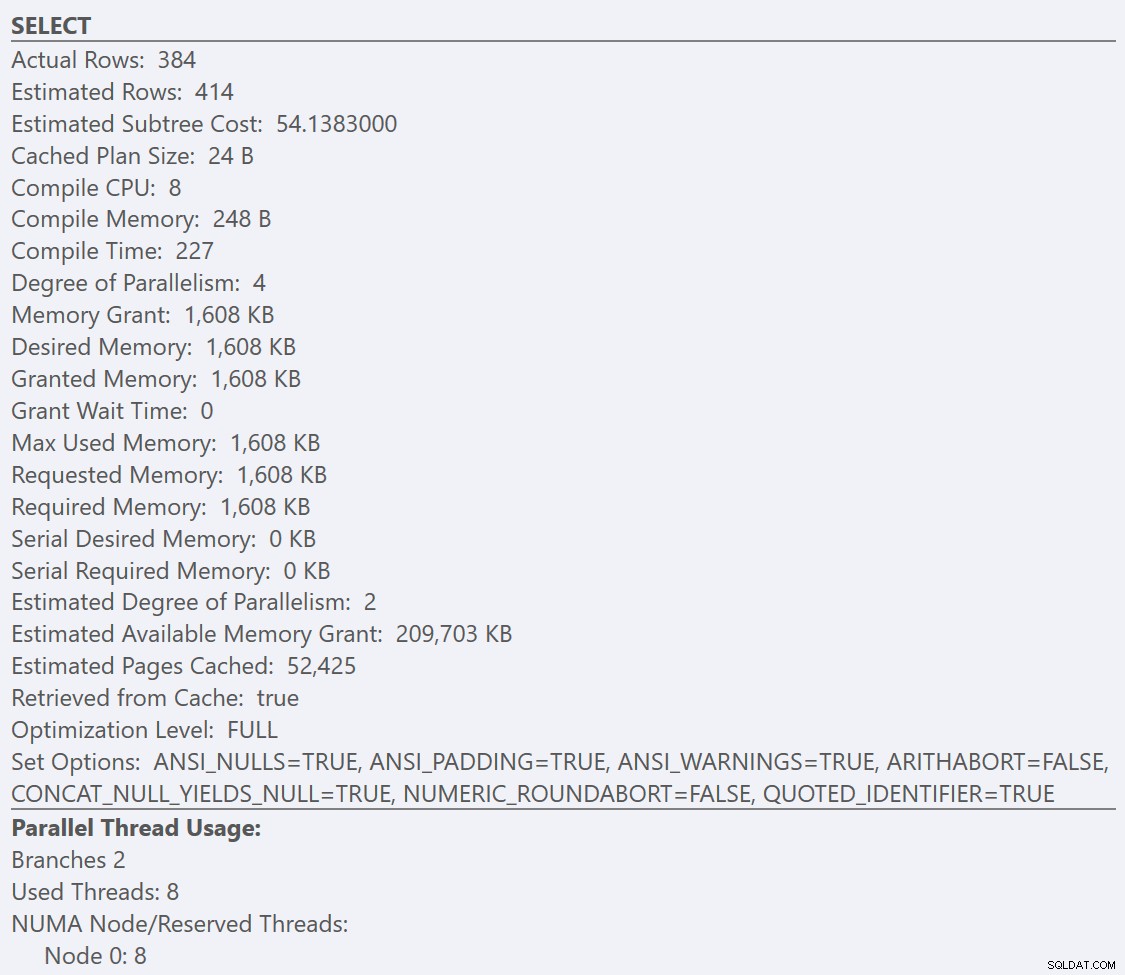
Pokud se podíváme na popisky z SELECT operátor pro každý plán, plán pro GuidLowFragmentation tabulka má cenu dotazu 38,80 (třetí řádek dolů od horní části popisku) oproti ceně dotazu 54,14 pro plán pro plán GuidHighFragmentation.
Ve výchozí konfiguraci pro SQL Server oba tyto dotazy nakonec vygenerují plán paralelního provádění, protože odhadovaná cena dotazu je vyšší než „prahová hodnota nákladů pro paralelismus“ možnost sp_configure výchozí hodnota 5. Důvodem je, že optimalizátor dotazů nejprve vytvoří sériový plán (který může být proveden pouze jedním vláknem) při kompilaci plánu pro dotaz. Pokud odhadovaná cena tohoto sériového plánu překročí nakonfigurovanou hodnotu „práh nákladů pro paralelismus“, vygeneruje se paralelní plán a uloží se do mezipaměti.
Co když však možnost sp_configure „prahová hodnota nákladů pro paralelismus“ není nastavena na výchozí hodnotu 5 a je nastavena vyšší? Je osvědčeným (a správným) postupem zvýšit tuto možnost z výchozí nízké hodnoty 5 na hodnotu z 25 na 50 (nebo dokonce mnohem vyšší), aby malé dotazy nezpůsobovaly další režii související s paralelním chodem.
EXEC sys.sp_configure N'show advanced options', N'1'; RECONFIGURE; GO EXEC sys.sp_configure N'cost threshold for parallelism', N'50'; RECONFIGURE; GO EXEC sys.sp_configure N'show advanced options', N'0'; RECONFIGURE; GO
Po dodržení pokynů osvědčených postupů a zvýšení „prahové hodnoty nákladů pro paralelismus“ na 50 povede opětovné spuštění dotazů ke stejnému plánu provádění pro GuidHighFragmentation tabulka, ale GuidLowFragmentation dotaz na sériové náklady, 44,68, je nyní pod hodnotou „prahové hodnoty pro paralelismus“ (pamatujte, že jeho odhadované náklady na paralelní provoz byly 38,80), takže dostáváme plán sériového provádění:
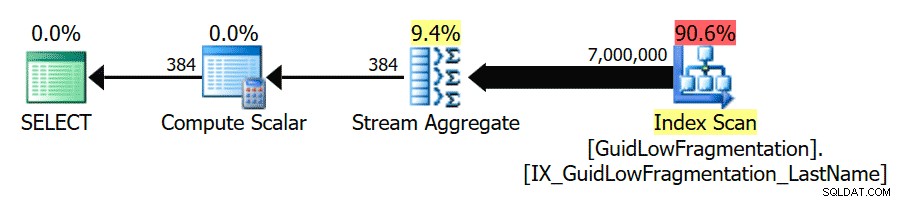
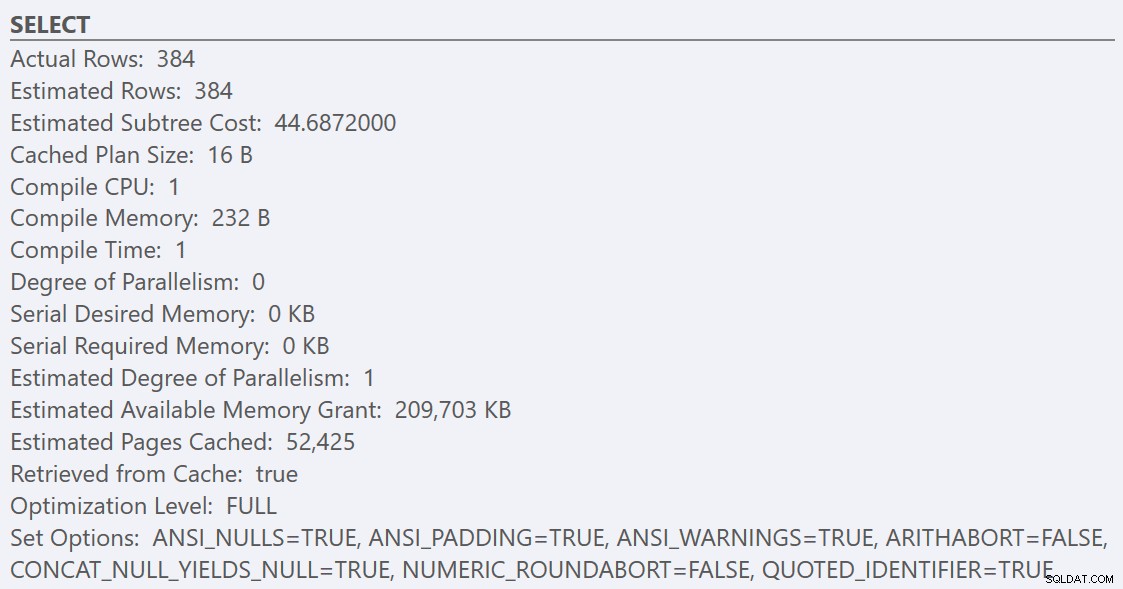
Dodatečný prostor pro stránku v GuidHighFragmentation klastrovaný index udržoval náklady nad nastavením osvědčených postupů pro „prah nákladů pro paralelismus“ a vyústil v paralelní plán.
Nyní si představte, že se jednalo o systém, kde jste postupovali podle pokynů osvědčených postupů a zpočátku jste nastavili „práh nákladů pro paralelismus“ na hodnotu 50. Později jste se řídili zavádějící radou, že fragmentaci indexu zcela ignorujete.
Namísto toho, aby to byl základní dotaz, je složitější, ale pokud se také ve vašem systému spouští velmi často a v důsledku fragmentace indexu počet stránek převede náklady na paralelní plán, bude spotřebovávat více CPU a v důsledku toho ovlivnit celkový výkon pracovní zátěže.
Co děláš? Zvyšujete „prah nákladů pro paralelismus“, takže dotaz udržuje plán sériového provádění? Naznačujete dotaz pomocí OPTION (MAXDOP 1) a pouze jej přinutíte k plánu sériového provádění?
Mějte na paměti, že fragmentace indexu pravděpodobně neovlivňuje pouze jednu tabulku ve vaší databázi, ale nyní ji zcela ignorujete; je pravděpodobné, že mnoho klastrovaných a neklastrovaných indexů je fragmentovaných a má vyšší počet stránek, než je nutné, takže náklady na mnoho I/O operací se zvyšují v důsledku rozsáhlé fragmentace indexů, což vede k potenciálně mnoha neefektivním dotazům plány.
Shrnutí
Fragmentaci indexu nemůžete jen tak úplně ignorovat, jak by někteří mohli chtít, abyste věřili. Mezi další nevýhody tohoto provedení vás dostihnou akumulované náklady na provádění dotazů díky posunům plánu dotazů, protože optimalizátor dotazů je optimalizátor založený na nákladech, a proto správně považuje použití těchto fragmentovaných indexů za nákladnější.
Zde uvedené dotazy a scénář jsou zjevně vymyšlené, ale viděli jsme změny realizačního plánu způsobené fragmentací v reálném životě na klientských systémech.
Musíte se ujistit, že řešíte fragmentaci indexů u těch indexů, kde fragmentace způsobuje problémy s výkonem zátěže, bez ohledu na to, jaký hardware používáte.