[ Část 1 | Část 2 | Část 3 ]
V duchu nedávných žvástů Granta Fritcheyho a úsilí Erin Stellato, myslím, že předtím, než jsme se potkali, se chci pustit do rozjetého vlaku, abych zatroubil a propagoval myšlenku zbavit se stopy ve prospěch Extended Events. Když někdo řekne sledovat , většina lidí si okamžitě pomyslí Profiler . Zatímco Profiler je svou vlastní speciální noční můrou, dnes jsem chtěl mluvit o výchozím trasování SQL Serveru.
V našem prostředí je povolena na všech 200+ produkčních serverech a shromažďuje spoustu odpadu, který nikdy nebudeme zkoumat. Ve skutečnosti je tolik odpadu, že důležité události, které bychom mohli považovat za užitečné pro odstraňování problémů, se ze trasovacích souborů vyvalí dříve, než k tomu vůbec dostaneme příležitost. Začal jsem tedy zvažovat možnost vypnutí, protože:
- není to zadarmo (režie pozorovatele na samotnou aktivitu trasování, I/O spojené se zápisem do trasovacích souborů a prostor, který zabírají);
- na většině serverů se na to nikdy nedívalo; na jiných, zřídka; a,
- je snadné znovu zapnout pro konkrétní, izolované řešení problémů.
Hodnotu výchozího trasování ovlivňuje několik dalších věcí. Není nijak konfigurovatelný — nemůžete změnit, které události shromažďuje, nemůžete přidávat filtry a nemůžete ovládat, kolik souborů uchovává (5), jak velké mohou být (20 MB každý) , nebo kde jsou uloženy (SERVERPROPERTY('ErrorLogFileName') ). Jsme tedy zcela vydáni na milost a nemilost pracovní zátěži – na žádném daném serveru nemůžeme předvídat, jak daleko mohou data jít (události s většími TextData hodnoty mohou například zabírat mnohem více místa a rychleji vytlačit starší události). Někdy se může vrátit o týden, jindy jen o minuty zpět.
Analýza aktuálního stavu
Spustil jsem následující kód proti 224 produkčním instancím, abych pochopil, jaký druh hluku vyplňuje výchozí trasování v našem prostředí. Toto je pravděpodobně složitější, než je potřeba, a není to ani tak složité jako poslední dotaz, který jsem použil, ale je to slušný výchozí bod pro analýzu rozdělení typů událostí na vysoké úrovni, které jsou aktuálně zachycovány:
;WITH filesrc ([path]) AS
(
SELECT REVERSE(SUBSTRING(p, CHARINDEX(N'\', p), 260)) + N'log.trc'
FROM (SELECT REVERSE([path]) FROM sys.traces WHERE is_default = 1) s(p)
),
tracedata AS
(
SELECT Context = CASE
WHEN DDL = 1 THEN
CASE WHEN LEFT(ObjectName,8) = N'_WA_SYS_'
THEN 'AutoStat: ' + DBType
WHEN LEFT(ObjectName,2) IN (N'PK', N'UQ', N'IX') AND ObjectName LIKE N'%[_#]%'
THEN UPPER(LEFT(ObjectName,2)) + ': tempdb'
WHEN ObjectType = 17747 AND ObjectName LIKE N'TELEMETRY%'
THEN 'Telemetry'
ELSE 'Other DDL in ' + DBType END
WHEN EventClass = 116 THEN
CASE WHEN TextData LIKE N'%checkdb%' THEN 'DBCC CHECKDB'
-- several more of these ...
ELSE UPPER(CONVERT(nchar(32), TextData)) END
ELSE DBType END,
EventName = CASE WHEN DDL = 1 THEN 'DDL' ELSE EventName END,
EventSubClass,
EventClass,
StartTime
FROM
(
SELECT DDL = CASE WHEN t.EventClass IN (46,47,164) THEN 1 ELSE 0 END,
TextData = LOWER(CONVERT(nvarchar(512), t.TextData)),
EventName = e.[name],
t.EventClass,
t.EventSubClass,
ObjectName = UPPER(t.ObjectName),
t.ObjectType,
t.StartTime,
DBType = CASE WHEN t.DatabaseID = 2 OR t.ObjectName LIKE N'#%' THEN 'tempdb'
WHEN t.DatabaseID IN (1,3,4) THEN 'System database'
WHEN t.DatabaseID IS NOT NULL THEN 'User database' ELSE '?' END
FROM filesrc CROSS APPLY sys.fn_trace_gettable(filesrc.[path], DEFAULT) AS t
LEFT OUTER JOIN sys.trace_events AS e ON t.EventClass = e.trace_event_id
) AS src WHERE (EventSubClass IS NULL)
OR (EventSubClass = CASE WHEN DDL = 1 THEN 1 ELSE EventSubClass END) -- ddl_phase
)
SELECT [Instance] = @@SERVERNAME,
EventName,
Context,
EventCount = COUNT(*),
FirstSeen = MIN(StartTime),
LastSeen = MAX(StartTime)
INTO #t FROM tracedata
GROUP BY GROUPING SETS ((), (EventName, Context)); (Predikát EventSubClass je zde proto, aby zabránil dvojitému započítání událostí DDL.Pro mapu hodnot EventClass jsem je uvedl v této odpovědi na Stack Exchange.)
A výsledky nejsou hezké (typické výsledky z náhodného serveru). Následující text nepředstavuje přesný výstup tohoto dotazu, ale strávil jsem nějaký čas agregováním výsledků do lépe stravitelného formátu, abych zjistil, kolik dat bylo užitečné a kolik bylo šumu (kliknutím zvětšíte):
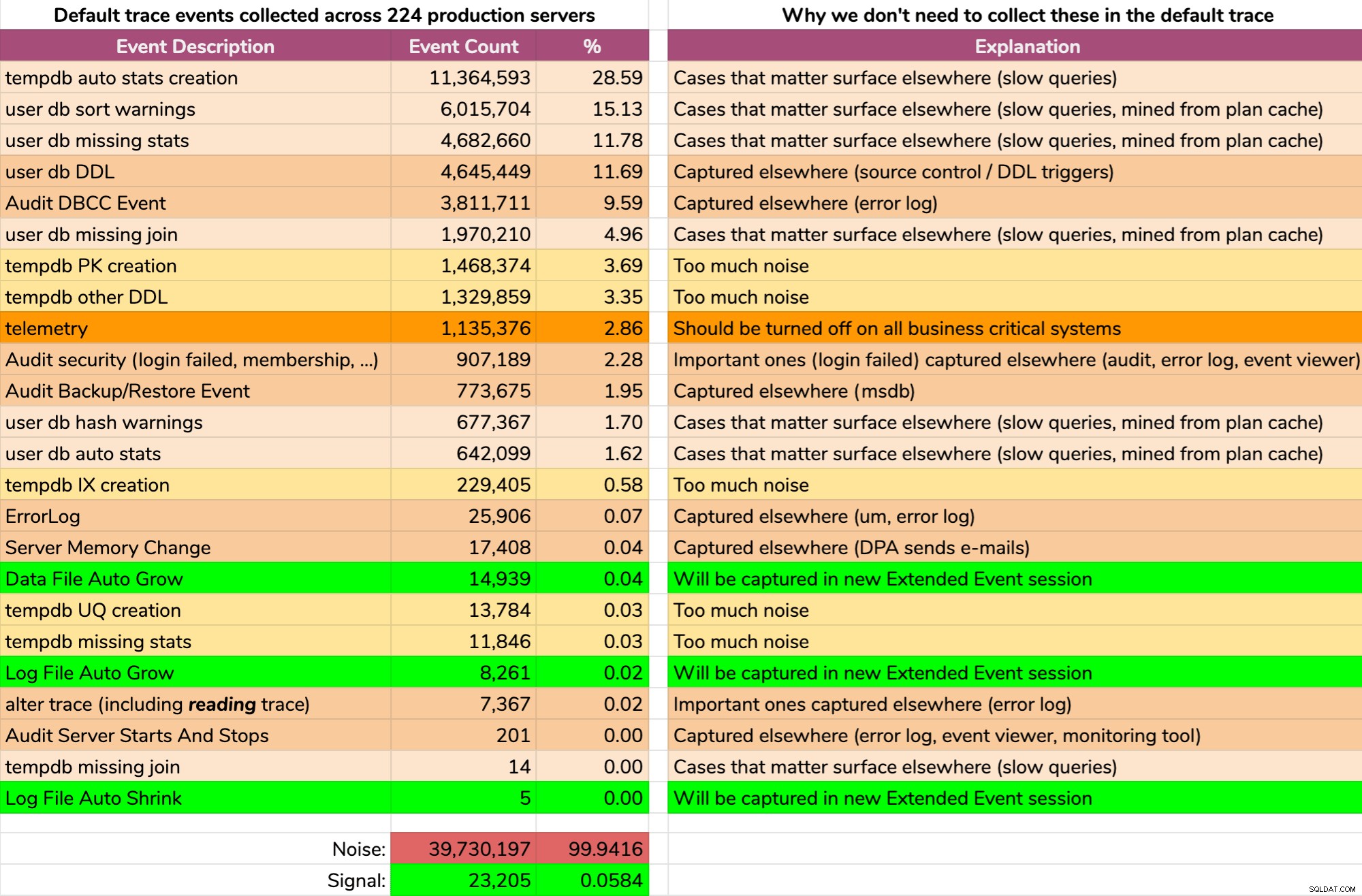
Téměř veškerý hluk (99,94 %). Jediná užitečná věc, kterou jsme kdy potřebovali z výchozího trasování, byly události růstu a zmenšování souborů, protože to byly jediné věci, které jsme jiným způsobem nezachycovali jinde. Ale ani na to se ne vždy můžeme spolehnout, protože data se tak rychle valí pryč.
Další způsob, jak jsem rozřezal data:nejstarší událost na instanci. Některé instance měly tolik šumu, že nedokázaly udržet výchozí data trasování déle než několik minut! Rozmazal jsem názvy serverů, ale toto jsou skutečná data (toto je 20 serverů s nejkratší historií – kliknutím zvětšíte):
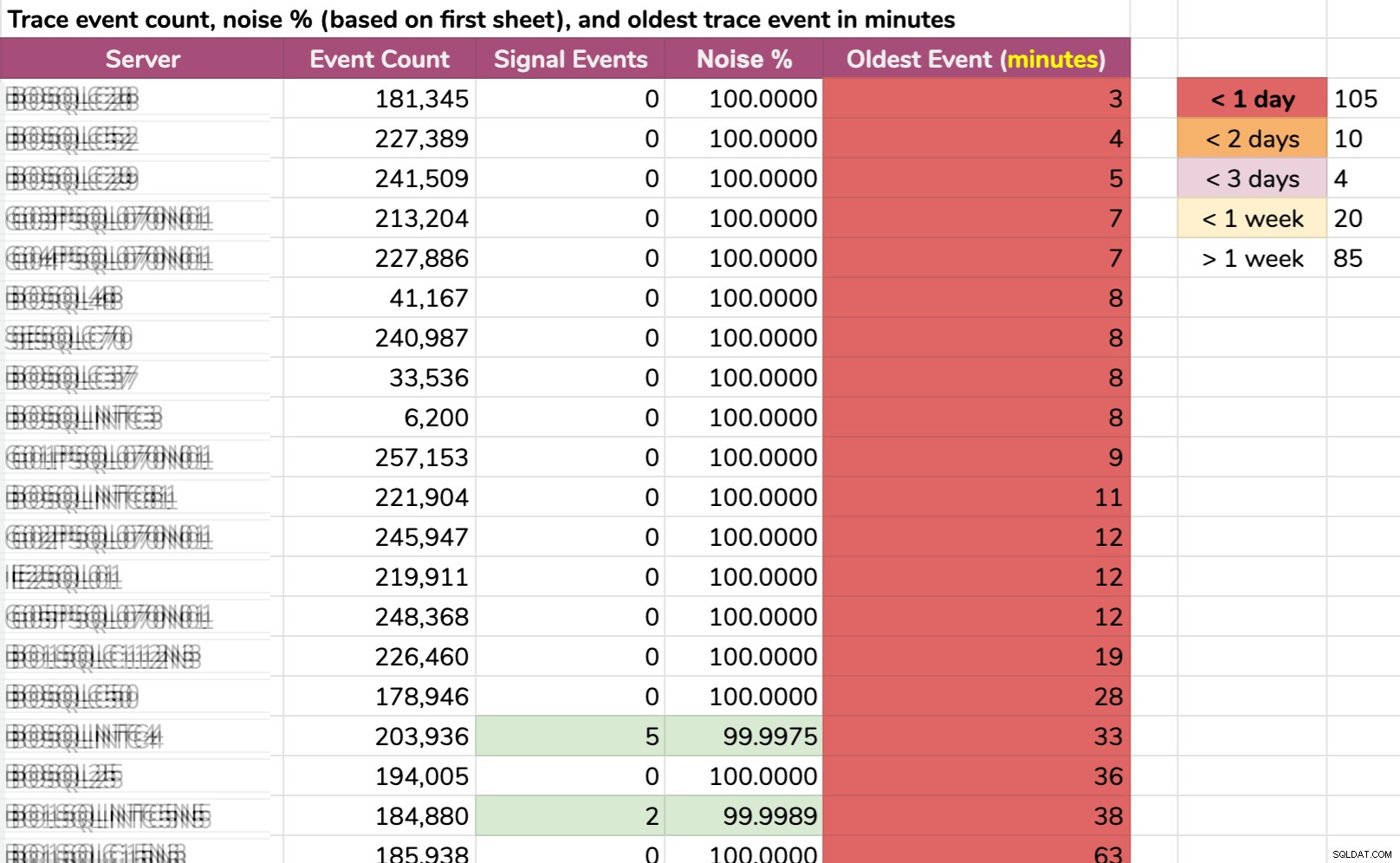
I kdyby se trasování shromažďovalo pouze relevantní informace a stalo se něco zajímavého, museli bychom rychle jednat, abychom to zachytili, v závislosti na serveru. Pokud se to stalo:
- před 20 minutami , pak by již byla odstraněna v 15 případech .
- včera tentokrát , bylo by to pryč na 105 instancích .
- před dvěma dny , bylo by to pryč na 115 instancích .
- před více než týdnem , zmizí ve 139 případech .
Měli jsme také několik serverů na druhém konci, ale ty jsou v tomto kontextu nezajímavé; tyto servery jsou takové jednoduše proto, že se tam neděje nic zajímavého (např. nejsou zaneprázdněny nebo jsou součástí nějaké kritické pracovní zátěže).
Na straně plus…
Zkoumání výchozího trasování odhalilo některé nesprávné konfigurace na několika našich serverech:
- Několik serverů mělo stále povolenou telemetrii . Jsem pro pomoc Microsoftu v určitých prostředích, ale ne za jakékoli režijní náklady na kritické obchodní systémy.
- Některé úkoly synchronizace na pozadí spočívaly v slepém přidávání členů do rolí , znovu a znovu, aniž by kontrolovali, zda již v těchto rolích byli. To samo o sobě není škodlivé, zejména proto, že tyto události již nebudou zaplňovat výchozí trasování, ale pravděpodobně také zaplňují audity šumem a pravděpodobně probíhají další slepé operace opětovného použití ve stejném vzoru.
- Někdo povolil automatické zmenšování někde (dobrý smutek!), takže tohle bylo něco, co jsem chtěl vysledovat a zabránit tomu, aby se to opakovalo (nové XE zachytí i tyto události).
To vedlo k následným úkolům k vyřešení těchto problémů a/nebo přidání podmínek k již existující automatizaci. Můžeme tedy zabránit opakování, aniž bychom se spoléhali na to, že budeme mít to štěstí, že se na ně stane v nějaké budoucí výchozí kontrole trasování, než budou spuštěny.
…ale problém přetrvává
Jinak je vše buď informace, na základě které nemůžeme jednat, nebo, jak je popsáno v grafu výše, události, které již zachycujeme jinde. A opět, jediná data, která mě zajímají z výchozího trasování a která již nezachycujeme jinými prostředky, jsou události související s růstem a zmenšováním souboru (i když výchozí trasování zachycuje pouze automatickou variantu).
Větším problémem ale ve skutečnosti není hlasitost hluku. Zvládnu velké masivní trasovací soubory se spoustou odpadků, protože klauzule WHERE byly vynalezeny přesně pro tento účel. Skutečným problémem je, že důležité události mizely příliš rychle.
Odpověď
Odpověď, alespoň v našem scénáři, byla jednoduchá:deaktivujte výchozí trasování, protože nemá cenu spouštět, pokud se na to nedá spolehnout.
Ale vzhledem k množství hluku výše, co by ho mělo nahradit? Něco?
Možná budete chtít relaci Extended Events, která zachytí vše výchozí zachycená stopa. Pokud ano, Jonathan Kehayias vás pokryl. To by vám poskytlo stejné informace, ale s kontrolou nad věcmi, jako je uchovávání, kam se data ukládají, a jak se budete cítit pohodlněji, možnost odstraňovat některé hlučnější nebo méně užitečné události, postupně, v průběhu času.
Můj plán byl trochu agresivnější a rychle se stal „jednoduchým“ procesem, který na všech serverech v daném prostředí (prostřednictvím CMS) provedl následující:
- vyvinout relaci Extended Events, která zachycuje pouze události změny souboru (ruční i automatické)
- zakázat výchozí trasování
- vytvořte pohled, který našim týmům usnadní používání cílových dat
Všimněte si, že nedoporučuji slepě deaktivovat výchozí trasování , jen vysvětluji, proč jsem se tak rozhodl v našem prostředí. V nadcházejících příspěvcích v této sérii ukážu novou relaci Extended Events, pohled, který odhaluje základní data, kód, který jsem použil k nasazení těchto změn na všechny servery, a potenciální vedlejší účinky, které byste měli mít na paměti.
[ Část 1 | Část 2 | Část 3 ]