V roce 2014 jsem napsal článek s názvem Performance Tuning the Whole Query Plan. Zabýval se způsoby, jak najít relativně malý počet odlišných hodnot ze středně velkého souboru dat, a dospěl k závěru, že rekurzivní řešení by mohlo být optimální. Tento následný příspěvek se znovu zabývá otázkou pro SQL Server 2019 pomocí většího počtu řádků.
Testovací prostředí
Budu používat databázi 50GB Stack Overflow 2013, ale bude stačit jakákoli velká tabulka s nízkým počtem různých hodnot.
Budu hledat odlišné hodnoty v BountyAmount sloupec dbo.Votes tabulka, prezentovaná v pořadí výše odměny vzestupně. Tabulka Hlasů má necelých 53 milionů řádků (přesněji 52 928 720). Existuje pouze 19 různých částek odměny, včetně NULL .
Databáze Stack Overflow 2013 je dodávána bez indexů bez klastrů, aby se minimalizovala doba stahování. Na Id je seskupený index primárního klíče sloupec dbo.Votes stůl. Je nastaven na kompatibilitu SQL Server 2008 (úroveň 100), ale začneme s modernějším nastavením SQL Server 2017 (úroveň 140):
ALTER DATABASE StackOverflow2013
SET COMPATIBILITY_LEVEL = 140;
Testy byly provedeny na mém notebooku pomocí SQL Server 2019 CU 2. Tento stroj má čtyři CPU i7 (hyperthreaded až 8) se základní rychlostí 2,4 GHz. Má 32 GB RAM, přičemž 24 GB je k dispozici pro instanci SQL Server 2019. Prahová hodnota nákladů pro paralelismus je nastavena na 50.
Každý výsledek testu představuje nejlepší z deseti běhů se všemi požadovanými daty a indexovými stránkami v paměti.
1. Seskupený index úložiště řádků
Chcete-li nastavit základní linii, prvním spuštěním je sériový dotaz bez jakéhokoli nového indexování (a nezapomeňte, že je to s databází nastavenou na úroveň kompatibility 140):
SELECT DISTINCT
V.BountyAmount
FROM dbo.Votes AS V
ORDER BY
V.BountyAmount
OPTION (MAXDOP 1);
To prohledá seskupený index a pomocí agregace hash v režimu řádků najde odlišné hodnoty BountyAmount :
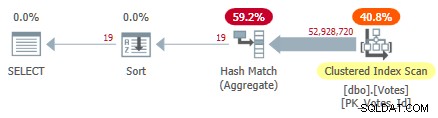 Serial Clustered Index Plan
Serial Clustered Index Plan
To trvá 10 500 ms dokončit za použití stejného času CPU. Pamatujte, že toto je nejlepší čas na více než deset běhů se všemi daty v paměti. Automaticky vytvořené vzorové statistiky pro BountyAmount byly vytvořeny při prvním spuštění.
Přibližně polovina uplynulého času se stráví skenováním seskupených indexů a asi polovina se shromažďuje Hash Match Aggregate. Třídění má ke zpracování pouze 19 řádků, takže spotřebuje pouze 1 ms nebo tak. Všichni operátoři v tomto plánu používají provádění v režimu řádků.
Odebrání MAXDOP 1 nápověda dává paralelní plán:
 Paralelní seskupený indexový plán
Paralelní seskupený indexový plán
Toto je plán, který optimalizátor zvolí bez jakýchkoliv nápověd v mé konfiguraci. Výsledky vrací za 4 200 ms s použitím celkem 32 800 ms CPU (při DOP 8).
2. Neshlukovaný index
Prohledejte celou tabulku a najděte pouze BountyAmount se zdá neefektivní, takže je přirozené zkusit přidat neshlukovaný index pouze do jednoho sloupce, který tento dotaz potřebuje:
CREATE NONCLUSTERED INDEX b ON dbo.Votes (BountyAmount);
Vytvoření tohoto indexu chvíli trvá (1m 40s). MAXDOP 1 dotaz nyní používá Stream Aggregate, protože optimalizátor může použít neklastrovaný index k prezentaci řádků v BountyAmount objednávka:
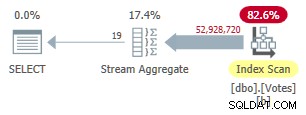 Sériový plán režimu neklastrovaných řádků
Sériový plán režimu neklastrovaných řádků
Toto trvá 9 300 ms (spotřebuje stejné množství času CPU). Užitečné vylepšení původních 10 500 ms, ale sotva otřesné.
Odebrání MAXDOP 1 nápověda poskytuje paralelní plán s místní agregací (po vláknu):
 Paralelní plán režimu neklastrovaných řádků
Paralelní plán režimu neklastrovaných řádků
To se provede za 3 400 ms s využitím 25 800 ms času CPU. Mohli bychom být schopni lépe s kompresí řádků nebo stránek na novém indexu, ale chci přejít k zajímavějším možnostem.
3. Batch Mode on Row Store (BMOR)
Nyní nastavte databázi do režimu kompatibility SQL Server 2019 pomocí:
ALTER DATABASE StackOverflow2013 SET COMPATIBILITY_LEVEL = 150;
To dává optimalizátoru svobodu vybrat si dávkový režim v řádku úložiště, pokud to považuje za vhodné. To může poskytnout některé výhody spouštění v dávkovém režimu bez potřeby indexu úložiště sloupců. Podrobné technické podrobnosti a nezdokumentované možnosti naleznete ve vynikajícím článku Dmitrije Pilugina na toto téma.
Optimalizátor bohužel stále volí provádění plně v režimu řádků pomocí agregací proudu pro sériové i paralelní testovací dotazy. Abychom získali dávkový režim v plánu provádění úložiště řádků, můžeme přidat nápovědu k podpoře agregace pomocí hash match (které lze spustit v dávkovém režimu):
SELECT DISTINCT
V.BountyAmount
FROM dbo.Votes AS V
ORDER BY
V.BountyAmount
OPTION (HASH GROUP, MAXDOP 1); To nám dává plán se všemi operátory spuštěnými v dávkovém režimu:
 Sériový dávkový režim v plánu úložiště řádků
Sériový dávkový režim v plánu úložiště řádků
Výsledky jsou vráceny za 2 600 ms (všechny CPU jako obvykle). To je již rychlejší než paralelní plán režimu řádků (uplynulo 3 400 ms) při použití mnohem menšího CPU (2 600 ms oproti 25 800 ms).
Odebrání MAXDOP 1 nápověda (ale ponechte HASH GROUP ) poskytuje paralelní dávkový režim v plánu úložiště řádků:
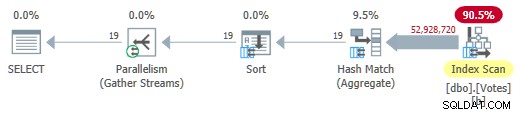 Paralelní dávkový režim v plánu řádkového úložiště
Paralelní dávkový režim v plánu řádkového úložiště
To se spustí za pouhých 725 ms pomocí 5 700 ms CPU.
4. Dávkový režim v obchodě Column Store
Paralelní dávkový režim ve výsledku ukládání řádků je působivé zlepšení. Můžeme udělat ještě lépe, když poskytneme reprezentaci dat ve sloupcovém úložiště. Aby vše ostatní zůstalo stejné, přidám nonclustered sloupec uložit index pouze na sloupec, který potřebujeme:
CREATE NONCLUSTERED COLUMNSTORE INDEX nb ON dbo.Votes (BountyAmount);
Toto je naplněno ze stávajícího neclusterovaného indexu b-tree a jeho vytvoření trvá pouze 15 s.
SELECT DISTINCT
V.BountyAmount
FROM dbo.Votes AS V
ORDER BY V.BountyAmount
OPTION (MAXDOP 1); Optimalizátor zvolí plán plně dávkového režimu včetně prohledávání indexu úložiště sloupců:
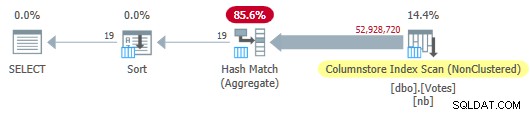 Plán obchodu se sériovým sloupcem
Plán obchodu se sériovým sloupcem
Spustí se za 115 ms za použití stejného množství času CPU. Optimalizátor vybere tento plán bez jakýchkoli rad ohledně konfigurace mého systému, protože odhadované náklady plánu jsou pod prahovou hodnotou pro paralelismus .
Chcete-li získat paralelní plán, můžeme buď snížit prahovou hodnotu nákladů, nebo použít nezdokumentovanou nápovědu:
SELECT DISTINCT
V.BountyAmount
FROM dbo.Votes AS V
ORDER BY
V.BountyAmount
OPTION (USE HINT ('ENABLE_PARALLEL_PLAN_PREFERENCE')); V každém případě je paralelní plán:
 Plán paralelního sloupce
Plán paralelního sloupce
Uplynulý čas dotazu je nyní 30 ms při spotřebě 210 ms CPU.
5. Dávkový režim ve sloupcovém obchodě s Push Down
Současná nejlepší doba provedení 30 ms je působivá, zvláště ve srovnání s původními 10 500 ms. Nicméně je trochu ostuda, že musíme předat téměř 53 milionů řádků (v 58 868 dávkách) ze skenování do agregátu hash Match.
Bylo by hezké, kdyby SQL Server mohl posouvat agregaci dolů do skenování a přímo vracet odlišné hodnoty z úložiště sloupců. Možná si myslíte, že potřebujeme vyjádřit DISTINCT jako GROUP BY získat Grouped Aggregate Pushdown, ale to je logicky nadbytečné a v žádném případě to není celý příběh.
Se současnou implementací SQL Serveru skutečně potřebujeme vypočítat agregaci aktivovat agregovaný pokles. Více než to, musíme použít agregovaný výsledek nějak, nebo ho optimalizátor prostě odstraní jako nepotřebný.
Jedním ze způsobů, jak napsat dotaz, abyste dosáhli souhrnného rozšíření, je přidat logicky nadbytečný požadavek na sekundární objednávání:
SELECT
V.BountyAmount
FROM dbo.Votes AS V
GROUP BY
V.BountyAmount
ORDER BY
V.BountyAmount,
COUNT_BIG(*) -- New!
OPTION (MAXDOP 1); Sériový plán je nyní:
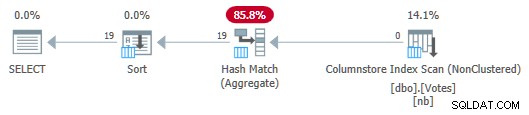 Serial Column Store Plan with Aggregate Push Down
Serial Column Store Plan with Aggregate Push Down
Všimněte si, že ze skenování do agregátu se nepředávají žádné řádky! Pod kryty částečné souhrny BountyAmount hodnoty a jejich přidružené počty řádků jsou předány do Hash Match Aggregate, který sečte dílčí agregáty a vytvoří požadovaný konečný (globální) agregát. To je velmi efektivní, jak potvrzuje uplynulý čas 13 ms (to vše je čas CPU). Pro připomenutí, předchozí sériový plán trval 115 ms.
Pro doplnění sady můžeme získat paralelní verzi stejným způsobem jako dříve:
 Paralelní sloupcový plán obchodu s Aggregate Push Down
Paralelní sloupcový plán obchodu s Aggregate Push Down
Toto trvá 7 ms celkem za použití 40 ms CPU.
Je škoda, že musíme počítat a používat agregát, který nepotřebujeme, jen abychom se dostali dolů. Možná to bude v budoucnu vylepšeno, takže DISTINCT a GROUP BY bez agregátů lze posunout dolů ke skenování.
6. Rekurzivní společný tabulkový výraz v režimu řádků
Na začátku jsem slíbil, že znovu navštívím rekurzivní řešení CTE používané k nalezení malého počtu duplikátů ve velkém souboru dat. Implementace aktuálního požadavku pomocí této techniky je docela přímočará, i když kód je nutně delší než cokoli, co jsme doposud viděli:
WITH R AS
(
-- Anchor
SELECT
V.BountyAmount
FROM dbo.Votes AS V
ORDER BY
V.BountyAmount ASC
OFFSET 0 ROWS
FETCH FIRST 1 ROW ONLY
UNION ALL
-- Recursive
SELECT
Q1.BountyAmount
FROM
(
SELECT
V.BountyAmount,
rn = ROW_NUMBER() OVER (
ORDER BY V.BountyAmount ASC)
FROM R
JOIN dbo.Votes AS V
ON V.BountyAmount > ISNULL(R.BountyAmount, -1)
) AS Q1
WHERE
Q1.rn = 1
)
SELECT
R.BountyAmount
FROM R
ORDER BY
R.BountyAmount ASC
OPTION (MAXRECURSION 0); Myšlenka má své kořeny v takzvaném indexu skip scan:Najdeme nejnižší hodnotu zájmu na začátku vzestupně seřazeného indexu b-stromu, pak hledáme další hodnotu v pořadí indexu a tak dále. Díky struktuře indexu b-stromu je nalezení další nejvyšší hodnoty velmi efektivní – není potřeba prohledávat duplikáty.
Jediným skutečným trikem je přesvědčit optimalizátor, aby nám umožnil použít TOP v „rekurzivní“ části CTE vrátit jednu kopii každé odlišné hodnoty. Pokud si potřebujete zopakovat podrobnosti, podívejte se prosím na můj předchozí článek.
Prováděcí plán (obecně vysvětlený zde Craigem Freedmanem) je:
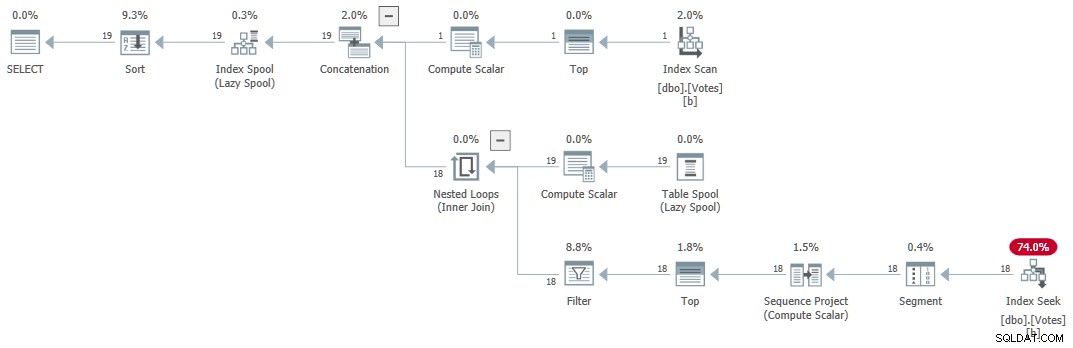 Sériové rekurzivní CTE
Sériové rekurzivní CTE
Dotaz vrátí správné výsledky za 1 ms pomocí 1 ms CPU, podle Sentry One Plan Explorer.
7. Iterativní T-SQL
Podobnou logiku lze vyjádřit pomocí WHILE smyčka. Kód může být snadněji čitelný a pochopitelný než rekurzivní CTE. Také se vyhnete nutnosti používat triky k obejití mnoha omezení rekurzivní části CTE. Výkon je konkurenceschopný kolem 15 ms. Tento kód je poskytován pro zajímavost a není součástí souhrnné tabulky výkonu.
SET NOCOUNT ON;
SET STATISTICS XML OFF;
DECLARE @Result table
(
BountyAmount integer NULL UNIQUE CLUSTERED
);
DECLARE @BountyAmount integer;
-- First value in index order
WITH U AS
(
SELECT
V.BountyAmount
FROM dbo.Votes AS V
ORDER BY
V.BountyAmount ASC
OFFSET 0 ROWS
FETCH NEXT 1 ROW ONLY
)
UPDATE U
SET @BountyAmount = U.BountyAmount
OUTPUT Inserted.BountyAmount
INTO @Result (BountyAmount);
-- Next higher value
WHILE @@ROWCOUNT > 0
BEGIN
WITH U AS
(
SELECT
V.BountyAmount
FROM dbo.Votes AS V
WHERE
V.BountyAmount > ISNULL(@BountyAmount, -1)
ORDER BY
V.BountyAmount ASC
OFFSET 0 ROWS
FETCH NEXT 1 ROW ONLY
)
UPDATE U
SET @BountyAmount = U.BountyAmount
OUTPUT Inserted.BountyAmount
INTO @Result (BountyAmount);
END;
-- Accumulated results
SELECT
R.BountyAmount
FROM @Result AS R
ORDER BY
R.BountyAmount; Souhrnná tabulka výkonu
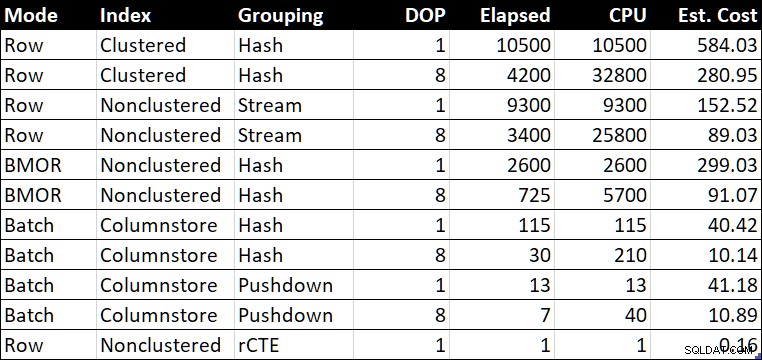 Souhrnná tabulka výkonu (trvání / CPU v milisekundách)
Souhrnná tabulka výkonu (trvání / CPU v milisekundách)
„Odh. Sloupec Cena“ zobrazuje odhad nákladů optimalizátoru pro každý dotaz, jak je nahlášen testovacím systémem.
Závěrečné myšlenky
Najít malý počet odlišných hodnot se může zdát jako docela specifický požadavek, ale v průběhu let jsem se s tím setkal poměrně často, obvykle jako součást ladění většího dotazu.
Několik posledních příkladů bylo výkonově velmi blízko. Mnoho lidí by bylo spokojeno s jakýmkoliv podsekundovým výsledkem, v závislosti na prioritách. Dokonce i sériový dávkový režim s výsledkem ukládání řádků 2 600 ms je dobře srovnatelný s nejlepším paralelním plány v režimu řádků, které jsou dobrým znamením pro výrazné zrychlení pouhým upgradem na SQL Server 2019 a povolením úrovně kompatibility databáze 150. Ne každý bude schopen rychle přejít na úložiště sloupců a stejně to nebude vždy to správné řešení. . Dávkový režim v úložišti řádků poskytuje úhledný způsob, jak dosáhnout některých zisků, které lze pomocí úložiště sloupců dosáhnout, za předpokladu, že dokážete přesvědčit optimalizátor, aby se rozhodl jej použít.
Souhrnný výsledek posunutí agregovaného úložiště sloupců dolů 57 milionů řádků zpracováno za 7 ms (při použití 40 ms CPU) je pozoruhodné, zejména s ohledem na hardware. Výsledek sériového souhrnného posunutí dolů 13 ms je stejně působivé. Bylo by skvělé, kdybych k získání těchto plánů nemusel přidávat nesmyslný souhrnný výsledek.
Pro ty, kteří ještě nemohou přejít na SQL Server 2019 nebo úložiště sloupců, je rekurzivní CTE stále životaschopným a efektivním řešením, pokud existuje vhodný index b-stromu a počet potřebných odlišných hodnot je zaručeně poměrně malý. Bylo by hezké, kdyby SQL Server mohl přistupovat k b-stromu, jako je tento, aniž by musel psát rekurzivní CTE (nebo ekvivalentní iterativní smyčkový kód T-SQL pomocí WHILE ).
Dalším možným řešením problému je vytvoření indexovaného zobrazení. To poskytne odlišné hodnoty s velkou účinností. Nevýhodou, jako obvykle, je, že každá změna podkladové tabulky bude muset aktualizovat počet řádků uložený v materializovaném pohledu.
Každé ze zde uvedených řešení má své místo v závislosti na požadavcích. Mít k dispozici širokou škálu nástrojů je obecně řečeno dobrá věc při ladění dotazů. Většinu času bych zvolil jedno z řešení dávkového režimu, protože jejich výkon bude docela předvídatelný bez ohledu na to, kolik duplikátů je přítomno.