Tento článek je dvanáctou částí série o pojmenovaných tabulkových výrazech. Doposud jsem se zabýval odvozenými tabulkami a CTE, což jsou výrazy pojmenovaných tabulek s rozsahem příkazů, a pohledy, což jsou opakovaně použitelné pojmenované tabulkové výrazy. Tento měsíc představím funkce s inline tabulkovou hodnotou neboli iTVF a popíšu jejich výhody ve srovnání s jinými pojmenovanými tabulkovými výrazy. Porovnávám je také s uloženými procedurami, především se zaměřuji na rozdíly ve výchozí strategii optimalizace a plánuji chování ukládání do mezipaměti a opětovného použití. Pokud jde o optimalizaci, je toho hodně, co je potřeba vyřešit, takže diskuzi zahájím tento měsíc a budu v ní pokračovat příští měsíc.
Ve svých příkladech použiji ukázkovou databázi nazvanou TSQLV5. Skript, který jej vytváří a naplňuje, najdete zde a jeho ER diagram zde.
Co je vložená funkce s hodnotou tabulky?
Ve srovnání s dříve pokrytými pojmenovanými tabulkovými výrazy se iTVF podobají převážně pohledům. Stejně jako pohledy jsou iTVF vytvářeny jako trvalý objekt v databázi, a proto je mohou znovu použít uživatelé, kteří mají oprávnění s nimi komunikovat. Hlavní výhodou iTVF oproti zobrazení je fakt, že podporují vstupní parametry. Nejjednodušší způsob, jak popsat iTVF, je jako parametrizovaný pohled, ačkoli technicky jej vytvoříte pomocí příkazu CREATE FUNCTION a nikoli pomocí příkazu CREATE VIEW.
Je důležité nezaměňovat iTVF s vícepříkazovými tabulkovými funkcemi (MSTVF). První z nich je inlinable pojmenovaný tabulkový výraz založený na jediném dotazu podobném pohledu a je zaměřen na tento článek. Poslední jmenovaný je programový modul, který vrací proměnnou tabulky jako svůj výstup s tokem více příkazů v těle, jehož účelem je naplnit vrácenou proměnnou tabulky daty.
Syntaxe
Zde je syntaxe T-SQL pro vytvoření iTVF:
CREATE [OR ALTER] FUNCTION [
[ (
TABULKA VRÁCENÍ
[ S
AS
NÁVRAT
V syntaxi si všimněte možnosti definovat vstupní parametry.
Účel atributu SCHEMABIDNING je stejný jako u pohledů a měl by být vyhodnocen na základě podobných úvah. Podrobnosti naleznete v 10. části seriálu.
Příklad
Jako příklad pro iTVF předpokládejme, že potřebujete vytvořit znovu použitelný výraz pojmenované tabulky, který přijímá jako vstupy ID zákazníka (@custid) a číslo (@n) a vrací požadovaný počet nejnovějších objednávek z tabulky Sales.Orders. pro vstupního zákazníka.
Tuto úlohu nemůžete implementovat pomocí pohledu, protože pohledy nepodporují vstupní parametry. Jak již bylo zmíněno, iTVF si můžete představit jako parametrizovaný pohled a jako takový je pro tento úkol tím správným nástrojem.
Před implementací samotné funkce je zde kód pro vytvoření podpůrného indexu v tabulce Sales.Orders:
USE TSQLV5; GO CREATE INDEX idx_nc_cid_odD_oidD_i_eid ON Sales.Orders(custid, orderdate DESC, orderid DESC) INCLUDE(empid);
A zde je kód k vytvoření funkce s názvem Sales.GetTopCustOrders:
CREATE OR ALTER FUNCTION Sales.GetTopCustOrders ( @custid AS INT, @n AS BIGINT ) RETURNS TABLE AS RETURN SELECT TOP (@n) orderid, orderdate, empid FROM Sales.Orders WHERE custid = @custid ORDER BY orderdate DESC, orderid DESC; GO
Stejně jako u základních tabulek a pohledů, když po načtení dat, zadáte iTVFs v klauzuli FROM příkazu SELECT. Zde je příklad žádosti o tři nejnovější objednávky pro zákazníka 1:
SELECT orderid, orderdate, empid FROM Sales.GetTopCustOrders(1, 3);
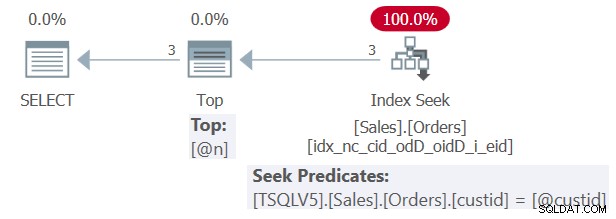
Tento příklad budu označovat jako Dotaz 1. Plán pro Dotaz 1 je znázorněn na obrázku 1.
 Obrázek 1:Plán pro dotaz 1
Obrázek 1:Plán pro dotaz 1
Co je inline o iTVF?
Pokud vás zajímá zdroj výrazu inline ve funkcích s inline tabulkou to má co do činění s tím, jak se optimalizují. Koncept vkládání je použitelný pro všechny čtyři druhy pojmenovaných tabulkových výrazů, které T-SQL podporuje, a zčásti zahrnuje to, co jsem popsal v části 4 série jako zrušení vnoření/substituce. Pokud potřebujete opakování, nezapomeňte znovu navštívit příslušnou sekci v části 4.
Jak můžete vidět na obrázku 1, díky skutečnosti, že funkce byla vložena, byl SQL Server schopen vytvořit optimální plán, který přímo spolupracuje s indexy základní tabulky. V našem případě plán provede vyhledávání v podpůrném indexu, který jste vytvořili dříve.
iTVF posouvají koncept vkládání o krok dále tím, že ve výchozím nastavení používají optimalizaci vkládání parametrů. Paul White popisuje optimalizaci vkládání parametrů ve svém skvělém článku Parameter Sniffing, Embedding, and the RECOMPILE Options. S optimalizací vkládání parametrů jsou odkazy na parametry dotazu nahrazeny doslovnými hodnotami konstant z aktuálního provádění a poté se optimalizuje kód s konstantami.
V plánu na obrázku 1 si všimněte, že predikát vyhledávání operátoru Index Seek i horní výraz operátoru Top ukazují vložené hodnoty konstant literálu 1 a 3 z aktuálního provádění dotazu. Nezobrazují parametry @custid a @n.
U iTVF se ve výchozím nastavení používá optimalizace vkládání parametrů. U uložených procedur jsou parametrizované dotazy ve výchozím nastavení optimalizovány. Chcete-li požádat o optimalizaci vkládání parametrů, musíte do dotazu uložené procedury přidat OPTION(RECOMPILE). Více podrobností o optimalizaci iTVF versus uložené procedury, včetně důsledků, již brzy.
Úprava dat prostřednictvím iTVF
Připomeňme si z části 11 série, že pokud jsou splněny určité požadavky, pojmenované tabulkové výrazy mohou být cílem modifikačních příkazů. Tato schopnost platí pro iTVF podobně jako pro zobrazení. Zde je například kód, který můžete použít k odstranění tří posledních objednávek zákazníka 1 (ve skutečnosti to nespouštějte):
DELETE FROM Sales.GetTopCustOrders(1, 3);
Konkrétně v naší databázi by pokus o spuštění tohoto kódu selhal kvůli vynucení referenční integrity (dotčené objednávky náhodou mají související řádky objednávek v tabulce Sales.OrderDetails), ale je to platný a podporovaný kód.
iTVF vs. uložené procedury
Jak již bylo zmíněno dříve, výchozí strategie optimalizace dotazů pro iTVF se liší od strategie pro uložené procedury. U iTVF je výchozím nastavením použití optimalizace vkládání parametrů. U uložených procedur je výchozím nastavením optimalizace parametrizovaných dotazů při použití sniffování parametrů. Chcete-li získat vkládání parametrů pro dotaz uložené procedury, musíte přidat OPTION(RECOMPILE).
Stejně jako mnoho optimalizačních strategií a technik má vkládání parametrů své výhody a nevýhody.
Hlavní výhodou je, že umožňuje zjednodušení dotazů, což může někdy vést k efektivnějším plánům. Některá z těchto zjednodušení jsou opravdu fascinující. Paul to demonstruje pomocí uložených procedur ve svém článku a já to předvedu příští měsíc s iTVF.
Hlavním mínusem optimalizace vkládání parametrů je, že nezískáte efektivní ukládání plánů do mezipaměti a chování při opětovném použití jako u parametrizovaných plánů. S každou odlišnou kombinací hodnot parametrů získáte odlišný řetězec dotazu, a tedy samostatnou kompilaci, která vede k samostatnému plánu uloženému v mezipaměti. S iTVF s konstantními vstupy můžete získat chování při opětovném použití plánu, ale pouze v případě, že se opakují stejné hodnoty parametrů. Je zřejmé, že dotaz uložené procedury s OPTION(RECOMPILE) znovu nepoužije plán, ani když na požádání opakuje stejné hodnoty parametrů.
Předvedu tři případy:
- Znovu použitelné plány s konstantami vyplývající z výchozí optimalizace vkládání parametrů pro dotazy iTVF s konstantami
- Znovu použitelné parametrizované plány vyplývající z výchozí optimalizace dotazů parametrizovaných uložených procedur
- Neopakovaně použitelné plány s konstantami vyplývajícími z optimalizace vkládání parametrů pro dotazy uložené procedury s OPTION(RECOMPILE)
Začněme případem #1.
Použijte následující kód k dotazu na naši iTVF s @custid =1 a @n =3:
SELECT orderid, orderdate, empid FROM Sales.GetTopCustOrders(1, 3);
Připomínáme, že by se jednalo o druhé spuštění stejného kódu, protože jste jej již jednou provedli se stejnými hodnotami parametrů dříve, což má za následek plán zobrazený na obrázku 1.
Použijte následující kód k dotazu na iTVF s @custid =2 a @n =3 jednou:
SELECT orderid, orderdate, empid FROM Sales.GetTopCustOrders(2, 3);
Tento kód budu označovat jako Dotaz 2. Plán pro Dotaz 2 je znázorněn na obrázku 2.
 Obrázek 2:Plán pro dotaz 2
Obrázek 2:Plán pro dotaz 2
Připomeňme, že plán na obrázku 1 pro Dotaz 1 odkazoval na konstantní ID zákazníka 1 v predikátu vyhledávání, zatímco tento plán odkazuje na konstantní ID zákazníka 2.
Ke kontrole statistik provádění dotazu použijte následující kód:
SELECT Q.plan_handle, Q.execution_count, T.text, P.query_plan FROM sys.dm_exec_query_stats AS Q CROSS APPLY sys.dm_exec_sql_text(Q.plan_handle) AS T CROSS APPLY sys.dm_exec_query_plan(Q.plan_handle) AS P WHERE T.text LIKE '%Sales.' + 'GetTopCustOrders(%';
Tento kód generuje následující výstup:
plan_handle execution_count text query_plan ------------------- --------------- ---------------------------------------------- ---------------- 0x06000B00FD9A1... 1 SELECT ... FROM Sales.GetTopCustOrders(2, 3); <ShowPlanXML...> 0x06000B00F5C34... 2 SELECT ... FROM Sales.GetTopCustOrders(1, 3); <ShowPlanXML...> (2 rows affected)
Jsou zde vytvořeny dva samostatné plány:jeden pro dotaz s ID zákazníka 1, který byl použit dvakrát, a druhý pro dotaz s ID zákazníka 2, který byl použit jednou. S velkým počtem různých kombinací hodnot parametrů skončíte s velkým počtem kompilací a plánů uložených v mezipaměti.
Pokračujme případem č. 2:výchozí optimalizační strategie parametrizovaných dotazů uložených procedur. Pomocí následujícího kódu zapouzdřte náš dotaz do uložené procedury s názvem Sales.GetTopCustOrders2:
CREATE OR ALTER PROC Sales.GetTopCustOrders2 ( @custid AS INT, @n AS BIGINT ) AS SET NOCOUNT ON; SELECT TOP (@n) orderid, orderdate, empid FROM Sales.Orders WHERE custid = @custid ORDER BY orderdate DESC, orderid DESC; GO
Pomocí následujícího kódu spusťte uloženou proceduru s @custid =1 a @n =3 dvakrát:
EXEC Sales.GetTopCustOrders2 @custid = 1, @n = 3; EXEC Sales.GetTopCustOrders2 @custid = 1, @n = 3;
První spuštění spustí optimalizaci dotazu, výsledkem je parametrizovaný plán zobrazený na obrázku 3:
 Obrázek 3:Plán prodeje.GetTopCustOrders2 proc
Obrázek 3:Plán prodeje.GetTopCustOrders2 proc
Sledujte odkaz na parametr @custid v predikátu vyhledávání a na parametr @n v horním výrazu.
Pomocí následujícího kódu spusťte uloženou proceduru s @custid =2 a @n =3 jednou:
EXEC Sales.GetTopCustOrders2 @custid = 2, @n = 3;
Parametrizovaný plán uložený v mezipaměti zobrazený na obrázku 3 je znovu použit.
Ke kontrole statistik provádění dotazu použijte následující kód:
SELECT Q.plan_handle, Q.execution_count, T.text, P.query_plan FROM sys.dm_exec_query_stats AS Q CROSS APPLY sys.dm_exec_sql_text(Q.plan_handle) AS T CROSS APPLY sys.dm_exec_query_plan(Q.plan_handle) AS P WHERE T.text LIKE '%Sales.' + 'GetTopCustOrders2%';
Tento kód generuje následující výstup:
plan_handle execution_count text query_plan ------------------- --------------- ----------------------------------------------- ---------------- 0x05000B00F1604... 3 ...SELECT TOP (@n)...WHERE custid = @custid...; <ShowPlanXML...> (1 row affected)
Byl vytvořen a uložen do mezipaměti pouze jeden parametrizovaný plán a byl použit třikrát, a to navzdory měnícím se hodnotám ID zákazníka.
Pojďme k případu číslo 3. Jak již bylo zmíněno, s dotazy uložené procedury můžete získat optimalizaci vkládání parametrů při použití OPTION(RECOMPILE). Ke změně dotazu procedury tak, aby zahrnoval tuto možnost, použijte následující kód:
CREATE OR ALTER PROC Sales.GetTopCustOrders2 ( @custid AS INT, @n AS BIGINT ) AS SET NOCOUNT ON; SELECT TOP (@n) orderid, orderdate, empid FROM Sales.Orders WHERE custid = @custid ORDER BY orderdate DESC, orderid DESC OPTION(RECOMPILE); GO
Proveďte proces s @custid =1 a @n =3 dvakrát:
EXEC Sales.GetTopCustOrders2 @custid = 1, @n = 3; EXEC Sales.GetTopCustOrders2 @custid = 1, @n = 3;
Získáte stejný plán znázorněný dříve na obrázku 1 s vloženými konstantami.
Proveďte proces s @custid =2 a @n =3 jednou:
EXEC Sales.GetTopCustOrders2 @custid = 2, @n = 3;
Získáte stejný plán znázorněný dříve na obrázku 2 s vloženými konstantami.
Prozkoumejte statistiky provádění dotazu:
SELECT Q.plan_handle, Q.execution_count, T.text, P.query_plan FROM sys.dm_exec_query_stats AS Q CROSS APPLY sys.dm_exec_sql_text(Q.plan_handle) AS T CROSS APPLY sys.dm_exec_query_plan(Q.plan_handle) AS P WHERE T.text LIKE '%Sales.' + 'GetTopCustOrders2%';
Tento kód generuje následující výstup:
plan_handle execution_count text query_plan ------------------- --------------- ----------------------------------------------- ---------------- 0x05000B00F1604... 1 ...SELECT TOP (@n)...WHERE custid = @custid...; <ShowPlanXML...> (1 row affected)
Počet provedení ukazuje 1, což odráží pouze poslední provedení. SQL Server ukládá do mezipaměti poslední provedený plán, takže může zobrazit statistiky pro toto provedení, ale na žádost plán znovu nepoužije. Pokud zkontrolujete plán zobrazený pod atributem query_plan, zjistíte, že je to plán vytvořený pro konstanty při posledním spuštění, jak je znázorněno dříve na obrázku 2.
Pokud toužíte po menším počtu kompilací a efektivním chování plánu ukládání do mezipaměti a opětovného použití, výchozí přístup optimalizace uložené procedury parametrizovaných dotazů je správnou cestou.
Implementace založená na iTVF má oproti implementaci založené na uložené proceduře velkou výhodu – když potřebujete použít funkci na každý řádek v tabulce a předat sloupce z tabulky jako vstupy. Předpokládejme například, že potřebujete vrátit tři nejnovější objednávky pro každého zákazníka v tabulce Sales.Customers. Žádná konstrukce dotazu vám neumožňuje použít uloženou proceduru na řádek v tabulce. Můžete implementovat iterativní řešení s kurzorem, ale vždy je dobrý den, kdy se můžete kurzorům vyhnout. Kombinací operátora APPLY s voláním iTVF můžete úkol splnit pěkně a čistě, například takto:
SELECT C.custid, O.orderid, O.orderdate, O.empid FROM Sales.Customers AS C CROSS APPLY Sales.GetTopCustOrders( C.custid, 3 ) AS O;
Tento kód generuje následující výstup (zkráceně):
custid orderid orderdate empid ----------- ----------- ---------- ----------- 1 11011 2019-04-09 3 1 10952 2019-03-16 1 1 10835 2019-01-15 1 2 10926 2019-03-04 4 2 10759 2018-11-28 3 2 10625 2018-08-08 3 ... (263 rows affected)
Volání funkce se vloží a odkaz na parametr @custid se nahradí korelací C.custid. Výsledkem je plán znázorněný na obrázku 4.
 Obrázek 4:Plán pro dotaz s APPLY a Sales.GetTopCustOrders iTVF
Obrázek 4:Plán pro dotaz s APPLY a Sales.GetTopCustOrders iTVF
Plán prohledá nějaký index v tabulce Sales.Customers, aby získal sadu ID zákazníků, a použije vyhledávání v podpůrném indexu, který jste vytvořili dříve na Sales.Orders na zákazníka. Od té doby, co byla funkce vložena do vnějšího dotazu, existuje pouze jeden plán, který se změnil na korelované nebo boční spojení. Tento plán je vysoce efektivní, zvláště když je sloupec Custid v Sales.Orders velmi hustý, což znamená, že existuje malý počet odlišných ID zákazníků.
Samozřejmě existují i jiné způsoby, jak tento úkol implementovat, například pomocí CTE s funkcí ROW_NUMBER. Takové řešení obvykle funguje lépe než řešení založené na APPLY, když má sloupec custid v tabulce Sales.Orders nízkou hustotu. Ať tak či onak, konkrétní úloha, kterou jsem použil ve svých příkladech, není pro účely naší diskuse tak důležitá. Chtěl jsem vysvětlit různé optimalizační strategie, které SQL Server používá s různými nástroji.
Až budete hotovi, použijte k vyčištění následující kód:
DROP INDEX IF EXISTS idx_nc_cid_odD_oidD_i_eid ON Sales.Orders;
Shrnutí a další postup
Takže, co jsme se z toho naučili?
iTVF je opakovaně použitelný parametrizovaný výraz pojmenované tabulky.
SQL Server standardně používá strategii optimalizace vkládání parametrů s iTVF a strategii optimalizace parametrizovaných dotazů s dotazy uložené procedury. Přidání OPTION(RECOMPILE) do dotazu uložené procedury může vést k optimalizaci vkládání parametrů.
Chcete-li získat méně kompilací a efektivní ukládání plánů do mezipaměti a chování při opakovaném použití, jsou plány dotazů s parametrizovanými procedurami správnou cestou.
Plány pro dotazy iTVF jsou uloženy v mezipaměti a lze je znovu použít, pokud se opakují stejné hodnoty parametrů.
Můžete pohodlně kombinovat použití operátoru APPLY a iTVF a aplikovat iTVF na každý řádek z levé tabulky a předat sloupce z levé tabulky jako vstupy do iTVF.
Jak již bylo zmíněno, o optimalizaci iTVF je toho hodně co pokrýt. Tento měsíc jsem porovnával iTVF a uložené procedury z hlediska výchozí strategie optimalizace a plánu ukládání do mezipaměti a chování při opětovném použití. Příští měsíc se hlouběji ponořím do zjednodušení vyplývajících z optimalizace vkládání parametrů.