Tento článek se zaměří na využití JOINů. Začneme tím, že si povíme něco o tom, jak budou probíhat JOINy a proč potřebujete JOIN data. Poté se podíváme na typy JOIN, které máme k dispozici, a jak je používat.
PŘIPOJTE SE K ZÁKLADŮM
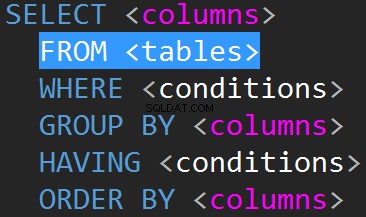
JOINy v TSQL se obvykle provádějí na řádku FROM.
Než se dostaneme k čemukoli jinému, skutečně velká otázka zní — „Proč musíme dělat JOINy a jak vlastně budeme provádět naše JOINy?“
Jak se ukázalo, každá databáze, se kterou kdy pracujeme, bude mít svá data rozdělena do více tabulek. Existuje pro to mnoho různých důvodů:
- Zachování integrity dat
- Úspora uloženého místa
- Rychlejší úpravy dat
- Flexibilnější dotazy
Každá databáze, se kterou budete pracovat, tedy bude potřebovat, aby se tato data spojila, aby skutečně dávala smysl.
Máte například samostatné tabulky pro objednávky a pro zákazníky. Otázka, která zní:„Jak vlastně propojíme všechna data? To je přesně to, co JOINy udělají.
JAK FUNGUJÍ PŘIPOJENÍ
Představte si případ, kdy máme dva samostatné stoly a tyto stoly se spojí vytvořením spoje.
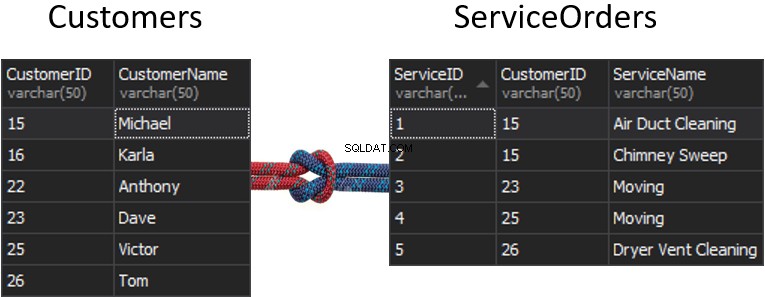
Co se stane se švem, když z každé tabulky dostaneme jeden sloupec, který bude použit pro párování, a ten určí, jaké řádky budou nebo nebudou vráceny? Například máme Customers na levé straně a ServiceOrders na pravé straně. Pokud chceme získat všechny zákazníky a jejich objednávky, musíme tyto dva stoly spojit dohromady. K tomu musíme vybrat jeden sloupec, který bude fungovat jako šev, a samozřejmě, že sloupec, který budeme používat, je CustomerID.
Mimochodem, CustomerID je známý jako Primární klíč pro levou tabulku, která jednoznačně identifikuje každý jednotlivý řádek v tabulce Zákazníci.
V tabulce ServiceOrders máme také sloupec CustomerID, který je známý jako Zahraniční klíč . Cizí klíč je jednoduše sloupec, který je navržen tak, aby ukazoval na jinou tabulku. V našem případě ukazuje zpět na tabulku Zákazníci. To je způsob, jakým shromáždíme všechna tato data tím, že poskytneme ten šev.
V těchto tabulkách máme následující párování:2 objednávky pro 15 a 1 objednávka pro 23, 25 a 26. 16 a 22 jsou vynechány.
Jedna velká věc, kterou je třeba poznamenat, je, že můžeme PŘIPOJIT více stolů . Ve skutečnosti je zcela běžné PŘIPOJIT více tabulek dohromady, abyste získali jakoukoli formu informací. Pokud se podíváte na nejběžnější databázi, možná budete muset spojit čtyři, pět, šest a více tabulek, abyste získali informace, které hledáte. Bude užitečné mít databázový diagram.
Abychom vám pomohli ve většině databázových prostředí, všimnete si, že sloupce navržené pro JOINed mají stejný název.
PŘIPOJTE SE K SYNTAXI
Třetí revize databázového dotazovacího jazyka SQL (SQL-92) upravuje syntaxi JOIN:
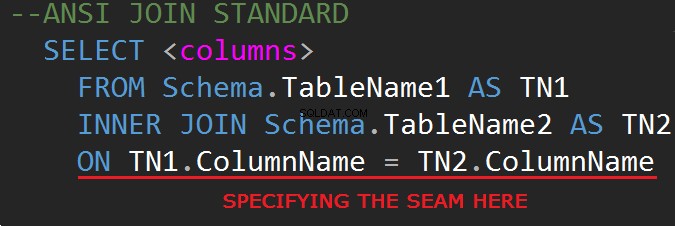
JOINy je možné provádět na řádku WHERE:
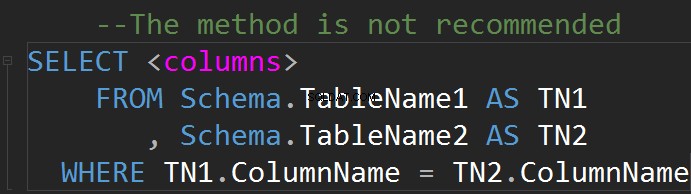
Relace má obvykle jednoduchou grafickou interpretaci ve formě tabulky.
Osvědčené postupy a konvence
- Názvy tabulek aliasů.
- Používejte dvoudílné pojmenování sloupců
- Každé JOIN umístěte na samostatný řádek
- Umístěte tabulky v logickém pořadí
TYPY PŘIPOJENÍ
SQL Server poskytuje následující typy spojení JOIN:
- VNITŘNÍ PŘIPOJENÍ
- VNĚJŠÍ PŘIPOJENÍ
- VLASTNÍ PŘIPOJENÍ
- PROVOZNÍ PŘIPOJENÍ
Další informace o tomto tématu najdete v tomto článku o typech připojení na SQL Server a zjistěte, jak snadné je psát takové dotazy pomocí SQL Complete.
INNER JOIN
Prvním typem spojení JOIN, které můžeme chtít provést, je INNER JOIN. Obvykle autoři označují tento typ SQL Server JOINs jako běžný nebo jednoduchý JOIN. Jen vynechávají předponu VNITŘNÍ. Tento typ JOIN kombinuje dvě tabulky dohromady a vrátí pouze řádky z obou stran, které si odpovídají .
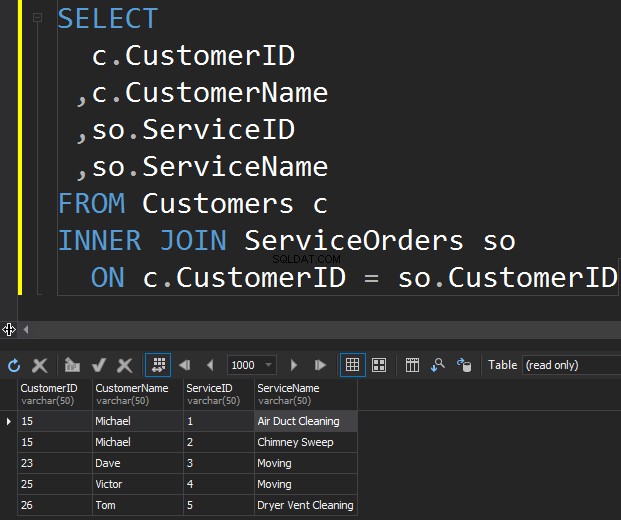
Nevidíme zde Kláru a Anthonyho, protože jejich CustomerID se v obou tabulkách neshoduje. Chci také zdůraznit skutečnost, že operace JOINvrátí zákazníka pokaždé, když odpovídá objednávce . Existují dvě objednávky pro Michaela a jedna pro Davea, Victora a Toma.
Shrnutí:
- INNER JOIN vrátí řádky pouze v případě, že v obou tabulkách existuje alespoň jeden řádek, který odpovídá podmínce JOIN.
- INNER JOIN eliminuje řádky, které se neshodují s řádkem z druhé tabulky
VNĚJŠÍ PŘIPOJENÍ
Vnější spojení JOIN se liší, protože vracejí řádky z tabulek nebo zobrazení, i když se neshodují. Tento typ JOIN je užitečný, pokud potřebujete získat všechny zákazníky, kteří nikdy nezadali objednávku. Nebo pokud například hledáte produkt, který nebyl nikdy objednán.
Způsob, jakým provádíme naše OUTER JOINy, je označení LEFT nebo RIGHT nebo FULL.
Mezi následujícími klauzulemi nejsou žádné rozdíly:
- LEVÉ VNĚJŠÍ PŘIPOJENÍ =LEVÉ PŘIPOJENÍ
- RIGHT OUTER JOIN =SPRÁVNÉ PŘIPOJENÍ
- FULL OUTER JOIN =ÚPLNÉ PŘIPOJENÍ
Doporučil bych však napsat celou klauzuli, protože díky ní bude kód čitelnější.
Pomocí LEFT OUTER JOIN
Není žádný rozdíl mezi LEFT a RIGHT kromě toho, že pouze ukážeme na tabulku, ze které chceme získat další řádky. V následujícím příkladu jsme uvedli zákazníky a jejich objednávky. LEVOU využíváme k získání všech zákazníků, kteří nikdy neobjednali. Požádáme SQL Server, aby nám dal další řádky z levé tabulky.
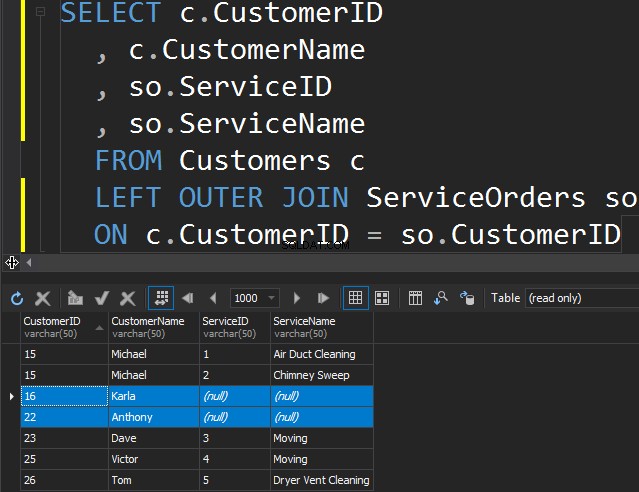
Všimněte si, že Karla a Anthony nezadali žádné objednávky a v důsledku toho dostáváme hodnoty NULL pro ServiceName a ServiceID. SQL Server neví, co tam má umístit, a umístí hodnoty NULL.
Pomocí RIGHT OUTER JOIN
Chcete-li získat méně oblíbenou službu z tabulky ServiceOrders, musíme použít SPRÁVNÝ směr.
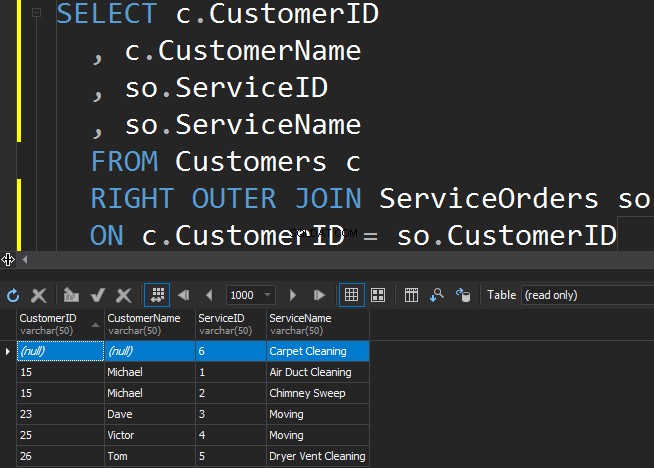
Vidíme, že v tomto případě SQL Server vrátil další řádky ze správné tabulky a služba čištění koberců nebyla nikdy objednána.
Pomocí FULL OUTER JOIN
Tento typ JOIN vám umožňuje získat neodpovídající informace zahrnutím neodpovídajících řádků z obou tabulek.
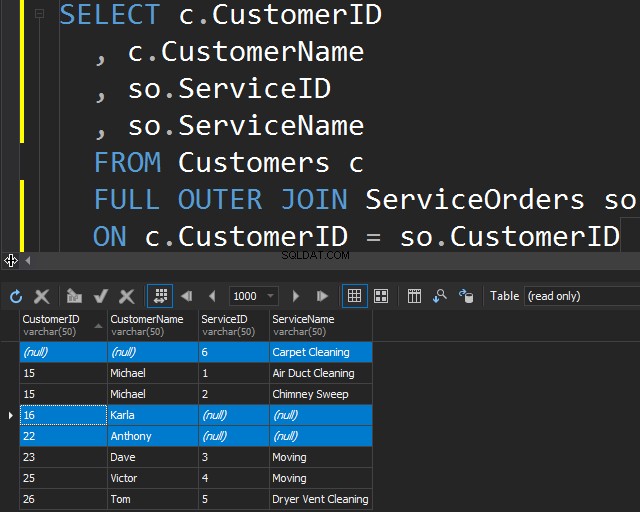
To může být také užitečné, pokud potřebujete provést vyčištění dat.
Shrnutí:
ÚPLNÉ VNĚJŠÍ PŘIPOJENÍ
- Vrátí řádky z obou tabulek, i když se neshodují s příkazem JOIN
VLEVO nebo VPRAVO
- Žádný rozdíl kromě pořadí tabulek v klauzuli FROM
- Směrové body u tabulky, ze kterých lze načíst neodpovídající řádky
VLASTNÍ PŘIPOJENÍ
Dalším typem JOINů, které máme, je SELF JOIN. Toto je pravděpodobně druhý nejméně běžný typ JOIN, který se kdy chystáte provést. SELF JOIN je, když se připojujete ke stolu k sobě samému. Obecně lze říci, že je to známka špatného designu. Chcete-li použít stejnou tabulku dvakrát v jednom dotazu, musí mít tabulka alias. Alias pomáhá procesoru dotazů identifikovat, zda mají sloupce prezentovat data z pravé nebo levé strany. Navíc musíte eliminovat řádky pochodující samy. To se obvykle provádí s neequi spojením.
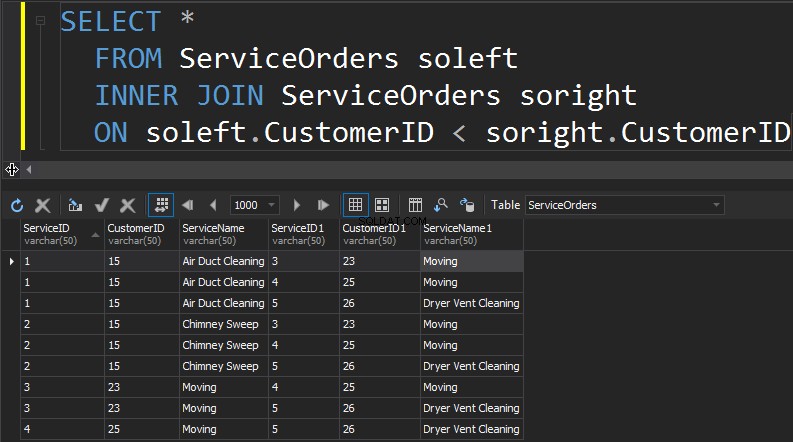
Shrnutí:
- Připojí stůl k sobě
- Obecně známka špatného návrhu a normalizace
- Tabulky musí mít alias
- Je třeba filtrovat řádky, které si odpovídají
KŘÍŽOVÉ PŘIPOJENÍ
Tento typ JOINů nemá ZAPNUTO prohlášení. Každý řádek z každé tabulky se bude shodovat. Toto je také známé jako kartézský produkt (v případě, že CROSS JOIN nemá klauzuli WHERE). Tento typ JOIN jen stěží využijete ve scénářích reálného světa, nicméně je to dobrý způsob, jak generovat testovací data.
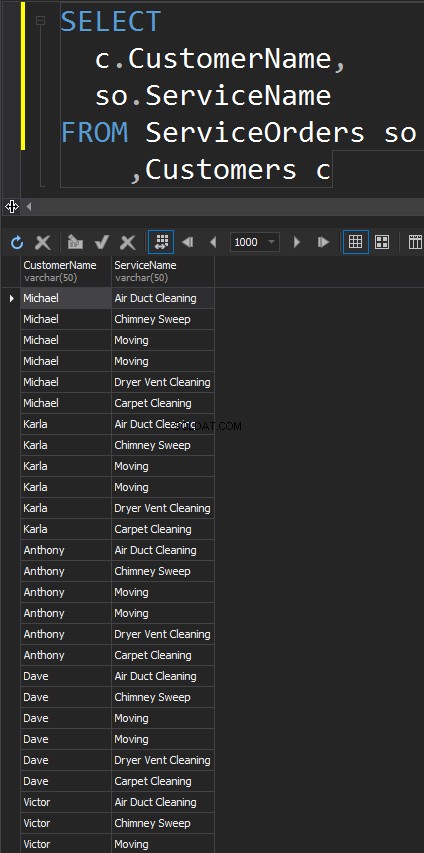
Výsledkem je datová sada, kde se počet řádků v levé tabulce vynásobí počtem řádků v pravé tabulce. Nakonec vidíme, že každý jednotlivý zákazník odpovídá každé jednotlivé službě.
Stejného výsledku dosáhneme, když explicitně použijeme klauzuli CROSS JOIN.
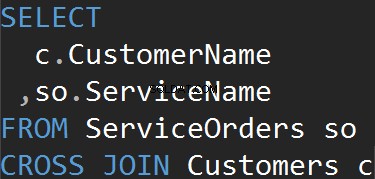
Shrnutí:
- Všechny řádky z každé tabulky se shodují
- Žádný příkaz ON
- Lze použít ke generování testovacích dat
PŘIPOJTE SE K ALGORITHMU
V první části článku jsme probrali logické Operátory JOIN, které SQL Server používá při analýze a vázání dotazu. Jsou to:
- VNITŘNÍ PŘIPOJENÍ
- VNĚJŠÍ PŘIPOJENÍ
- PROVOZNÍ PŘIPOJENÍ
Logické operátory jsou koncepční a liší se od fyzických JOINy. Jinak řečeno, logické JOINy se ve skutečnosti nepřipojují konkrétní sloupce tabulky. Jediný logický JOIN může odpovídat mnoha fyzickým JOINům. SQL Server během optimalizace nahrazuje logické JOINy fyzickými JOINy. SQL Server má následující fyzické operátory JOIN:
- VNOŘENÁ SMYČKA
- SLOUČIT
- HASH
Uživatel nepíše ani nepoužívá tyto typy JOINS. Jsou součástí enginu SQL Serveru a SQL Server je používá interně k implementaci logických JOINů. Když prozkoumáte plán provádění, můžete si všimnout, že SQL Server nahrazuje logické operátory JOIN jedním ze tří fyzických operátorů.
Připojení vnořené smyčky
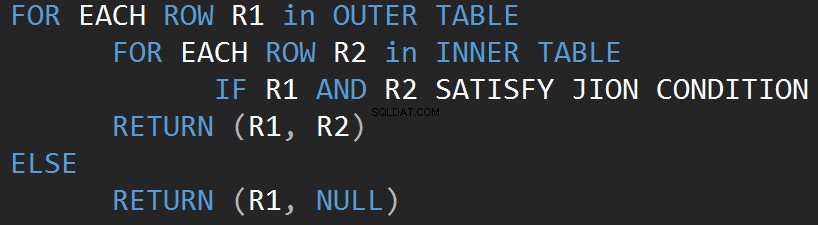
Začněme od nejjednoduššího operátoru, kterým je Nested Loop. Algoritmus porovnává každý jednotlivý řádek jedné tabulky (vnější tabulka) s každým řádkem druhé tabulky (vnitřní tabulka) a hledá řádky, které splňují predikát JOIN.
Následující pseudokód popisuje algoritmus vnitřní vnořené smyčky spojení:

Následující pseudokód popisuje algoritmus vnější vnořené smyčky spojení:
Velikost vstupu přímo ovlivňuje cenu algoritmu. Vstup roste, rostou také náklady. Tento typ algoritmu JOIN je účinný v případě malého vstupu. SQL Server odhaduje predikát JOIN pro každý řádek v obou vstupech.
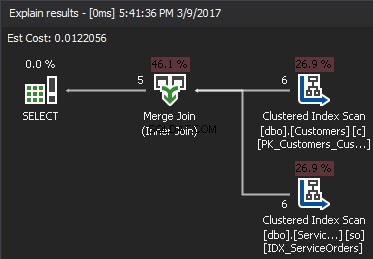
Zvažte následující dotaz jako příklad, který získá zákazníky a jejich objednávky.
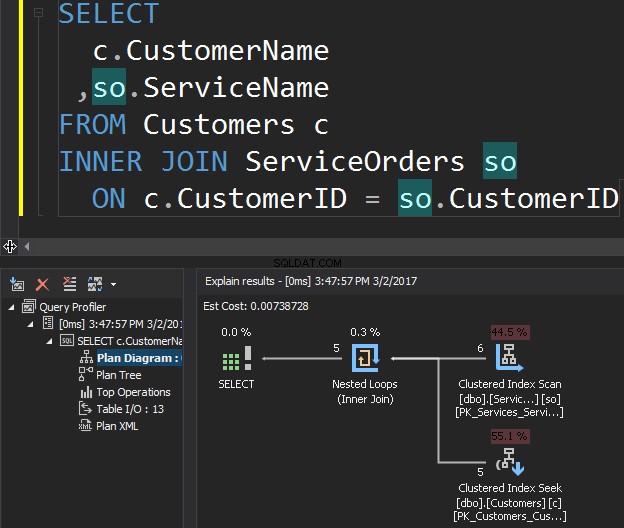
Operátor Clustered Index Scan je vnější vstup a Clustered Index Seek je vnitřní vstup . Operátor Nested Loop skutečně najde shodu. Operátor hledá každý záznam ve vnějším vstupu a najde odpovídající řádky ve vnitřním vstupu. SQL Server provede operaci Clustered Index Scan (vnější vstup) pouze jednou, aby získal všechny relevantní záznamy. Clustered Index Seek se provádí pro každý záznam z vnějšího vstupu. Chcete-li to potvrdit, přejděte kurzorem na ikonu operátora a prozkoumejte nápovědu.
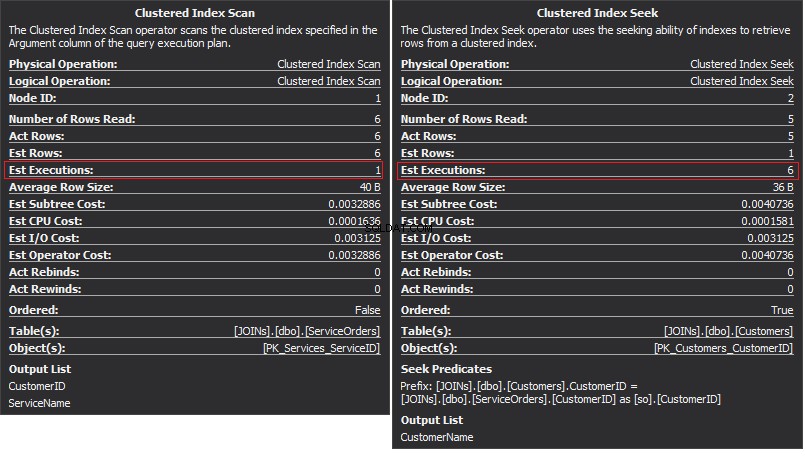
Pojďme mluvit o složitosti. Předpokládejme, že N je číslo řádku pro vnější výstup. M je celkové číslo řádku v SalesOrders stůl. Složitost dotazu je tedy O(NLogM) kde LogM je složitost každého hledání ve vnitřním vstupu. Optimalizátor vybere tento operátor pokaždé, když je vnější vstup malý a vnitřní vstup obsahuje index ve sloupci, který funguje jako šev. Proto jsou indexy a statistiky pro tento typ JOIN zásadní, jinak si SQL Server může omylem myslet, že v jednom ze vstupů není tolik řádků. Je lepší provést jedno skenování tabulky, než provádět hledání indexu 100 000 krát. Zvláště když je velikost vnitřního vstupu větší než 100 kB.
Shrnutí:
Vnořené smyčky
- Složitost:O(NlogM)
- Obvykle se používá, když je jeden stůl malý
- Větší tabulka obsahuje index, který umožňuje její vyhledávání pomocí klíče spojení
Sloučit připojení
Někteří vývojáři zcela nerozumí Hash a Merge JOINs a často je spojují s dotazy s nízkou výkonností.
Na rozdíl od Nested Loop, který přijímá jakýkoli predikát JOIN, spojení Merge Join vyžaduje alespoň jedno spojení equi. Navíc musí být oba vstupy seřazeny na klávesách JOIN.
Pseudokód pro algoritmus MERGE JOIN:
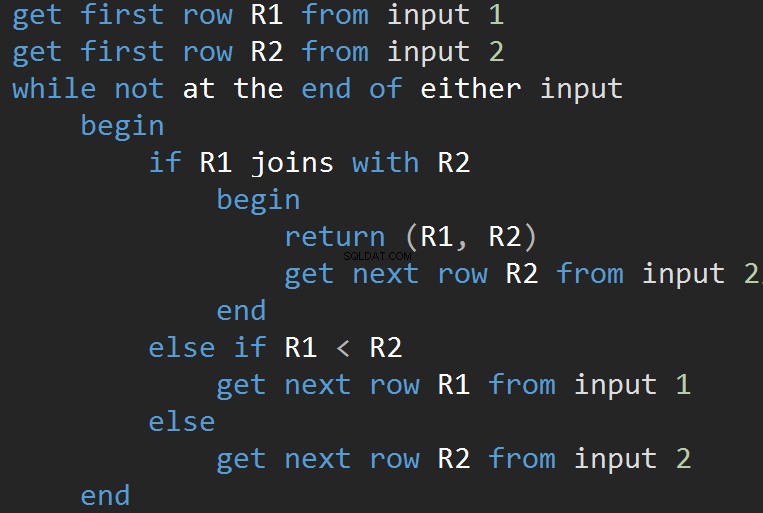
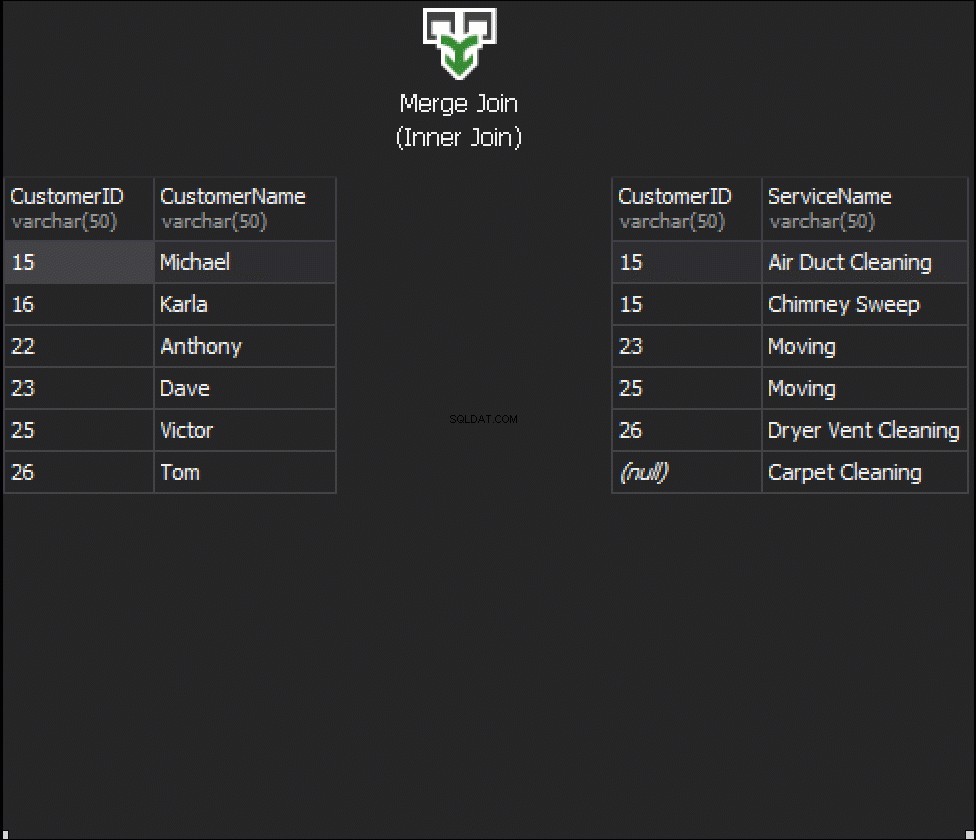
Algoritmus porovnává dva seřazené vstupy. Jeden řádek po druhém. V případě, že je mezi dvěma řádky rovnost, výstupy algoritmu spojí řádky a pokračují. Pokud ne, algoritmus zahodí menší ze dvou vstupů a pokračuje. Na rozdíl od vnořené smyčky jsou zde náklady úměrné součtu počtu vstupních řádků. Z hlediska složitosti – O(N+M). Proto je tento typ JOINů často lepší pro velké vstupy.
Následující animace ukazuje, jak algoritmus MERGE JOIN ve skutečnosti spojuje řádky tabulky.
Shrnutí
- Složitost:O(N+M)
- Oba vstupy musí být seřazeny podle spojovacího klíče
- Je použit operátor rovnosti
- Výborné pro velké stoly
Hash Join
Hash Join se dobře hodí pro velké tabulky bez použitelného indexu. V prvním kroku – fáze výstavby algoritmus vytvoří v paměti hash index na levém vstupu. Druhý krok se nazývá fáze sondy . Algoritmus prochází vstupem na pravé straně a najde shody pomocí indexu vytvořeného během fáze sestavení. Po pravdě řečeno, není to dobré znamení, když optimalizátor zvolí tento typ algoritmu JOIN.
Existují dva důležité koncepty, které jsou základem tohoto typu JOINů:hashovací funkce a hashovací tabulka.
Hashovací funkce je jakákoli funkce, kterou lze použít k mapování dat proměnné velikosti na data pevné velikosti.
Hashovací tabulka je datová struktura používaná k implementaci asociativního pole, struktury, která dokáže mapovat klíče na hodnoty. Hašovací tabulka používá hašovací funkci k výpočtu indexu do pole segmentů nebo slotů, ze kterých lze nalézt požadovanou hodnotu.
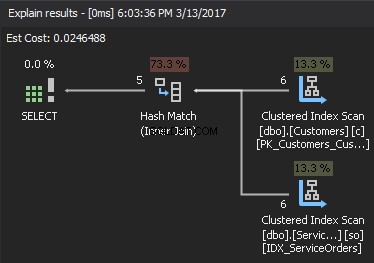
Na základě dostupných statistik vybere SQL Server jako vstup sestavení nejmenší vstup a použije jej k vytvoření hashovací tabulky v paměti. Pokud není dostatek paměti, SQL Server používá místo na fyzickém disku v TempDB. Jakmile je hash tabulka vytvořena, SQL Server získá data ze vstupu sondy (větší tabulka) a porovná je s hashovací tabulkou pomocí funkce hash match. Výsledkem je, že vrátí odpovídající řádky.
Pokud se podíváme na plán provádění, pravým horním prvkem je vstup sestavení a pravý spodní prvek je vstup sondy . V případě, že jsou oba vstupy extrémně velké, náklady jsou příliš vysoké.
Chcete-li odhadnout složitost, předpokládejte následující:
hc – složitost tvorby hashovací tabulky
hm – složitost funkce hash match
N – menší stůl
M – větší stůl
J – přidání složitosti pro dynamický výpočet a vytvoření hashovací funkce
Složitost bude:O(N*hc + M*hm + J)
Optimalizátor používá statistiky k určení mohutnosti hodnoty. Poté dynamicky vytvoří hashovací funkci, která rozdělí data do mnoha segmentů o stejné velikosti. Kvůli dynamické povaze je často obtížné odhadnout složitost procesu vytváření hashovací tabulky a také složitost každé hashovací shody. Plán provádění může dokonce vykazovat nesprávné odhady, protože optimalizátor provádí všechny tyto dynamické operace během doby provádění. V některých případech může plán realizace ukázat, že Nested Loop je dražší než Hash Join, ale ve skutečnosti se Hash Join spouští pomaleji kvůli nesprávnému odhadu nákladů.
Shrnutí
- Složitost:O(N*hc +M*hm +J)
- Typ připojení poslední instance
- K porovnání řádků používá hašovací tabulku a dynamickou funkci hašovací shody
Užitečné produkty:
SQL Complete – pište, zkrášlujte, refaktorujte svůj kód snadno a zvyšte svou produktivitu.