Jaké problémy zvážíme?
Pokud server oznámí „na jednotce E již není místo“ – není potřeba žádná hloubková analýza. Nebudeme uvažovat chyby, jejichž řešení je zřejmé z textu zprávy a pro které Google okamžitě hodí odkaz na MSDN s řešením.
Pojďme se podívat na problémy, které pro Google nejsou zřejmé, jako je například náhlý pokles výkonu nebo absence připojení. Zvažte hlavní nástroje pro přizpůsobení a analýzu. Podívejme se, kde se nacházejí protokoly a další užitečné informace. Ve skutečnosti se pokusím shromáždit v jednom článku všechny potřebné informace pro rychlý začátek.
Především
Začneme nejčastějšími otázkami a zvážíme je samostatně.
Pokud vaše databáze náhle, bez zjevného důvodu, začala pracovat pomalu, ale nic jste nezměnili – nejprve aktualizujte statistiky a znovu vytvořte indexy.
Na internetu existuje mnoho podobných metod, jsou uvedeny příklady skriptů. Předpokládám, že všechny tyto metody jsou pro profesionály. No, popíšu nejjednodušší způsob:k jeho implementaci potřebujete pouze myš.
Zkratky
- SSMS je aplikace Microsoft SQL Server Management Studio. Od verze 2016 je k dispozici zdarma na webu MS jako samostatná aplikace. docs.microsoft.com/en-us/sql/ssms/download-sql-server-management-studio-ssms
- Profiler je aplikace „SQL Server Profiler“ nainstalovaná s SSMS.
- Performance Monitor je modul snap-in ovládacího panelu, který umožňuje sledovat počítadla výkonu, zaznamenávat a prohlížet historii měření.
Aktualizace statistik pomocí „plánu služeb“:
- spustit SSMS;
- připojit k požadovanému serveru;
- rozbalte strom v Object Inspector:Management\Maintenance Plans (Service Plans);
- klikněte pravým tlačítkem na uzel a vyberte „Průvodce plánem údržby“;
- v průvodci označte požadované úkoly:znovu sestavit index a aktualizovat statistiky
- můžete označit oba úkoly najednou nebo vytvořit dva plány údržby s jedním úkolem v každém (viz „důležité poznámky“ níže);
- dále zkontrolujeme požadovanou DB (nebo několik databází). Děláme to pro každý úkol (pokud jsou vybrány dva úkoly, zobrazí se dva dialogy s výběrem databáze);
- Další, Další, Dokončit.
Po těchto akcích bude vytvořen (neproveden) „plán údržby“. Můžete jej spustit ručně kliknutím pravým tlačítkem myši a výběrem „Provést“. Případně nakonfigurujete spouštění prostřednictvím SQL Agent.
Důležité poznámky:
- Aktualizace statistik je neblokující operace. Můžete to provést v pracovním režimu.
- Obnovení indexu je operace blokování. Provozovat jej můžete pouze mimo pracovní dobu. Existuje výjimka — edice Enterprise serveru umožňuje provedení „online přestavby“. Tuto možnost lze povolit v nastavení úlohy. Upozorňujeme, že zaškrtnutí je ve všech edicích, ale funguje pouze v Enterprise.
- Tyto úkoly je samozřejmě nutné provádět pravidelně. Navrhuji jednoduchý způsob, jak určit, jak často to děláte:
– Při prvních problémech proveďte plán údržby;
– Pokud to pomohlo, počkejte, až se problémy objeví znovu (obvykle do další měsíční uzávěrky/výpočtu mzdy/atd. hromadných transakcí);
– Výsledná doba normálního provozu bude vaším referenčním bodem;
– Například nakonfigurujte provádění plánu údržby dvakrát tak často.
Server je pomalý – co byste měli dělat?
Prostředky používané serverem
Jako každý jiný program potřebuje server čas procesoru, data na disku, velikost paměti RAM a šířku pásma sítě.
Správce úloh vám pomůže posoudit nedostatek daného zdroje v první aproximaci, bez ohledu na to, jak hrozné to může znít.
CPU Načíst
Využití si může ověřit i školák ve Správci. Musíme se jen ujistit, že pokud je načten procesor, pak je to proces sqlserver.exe.
Pokud je to váš případ, musíte přejít na analýzu aktivity uživatele, abyste pochopili, co přesně způsobilo zatížení (viz níže).
Disk Loa d
Mnoho lidí se dívá pouze na zatížení CPU, ale zapomíná, že DBMS je úložiště dat. Objemy dat rostou, výkon procesoru se zvyšuje, zatímco rychlost HDD je téměř stejná. U SSD je situace lepší, ale ukládání terabajtů na ně je drahé.
Ukazuje se, že se často setkávám se situacemi, kdy se úzkým hrdlem stává diskový systém spíše než CPU.
Pro disky jsou důležité následující metriky:
- průměrná délka fronty (nevyřízené I/O operace, počet);
- rychlost čtení a zápisu (v Mb/s).
Serverová verze Správce úloh zpravidla (v závislosti na verzi systému) zobrazuje obojí. Pokud ne, spusťte modul snap-in Sledování výkonu (sledování systému). Zajímají nás následující čítače:
- Fyzický (logický) disk/průměrná doba čtení (zápisu)
- Fyzický (logický) disk/průměrná délka diskové fronty
- Fyzický (logický) disk/rychlost disku
Pro více podrobností si můžete přečíst manuály výrobce například zde:social.technet.microsoft.com/wiki/contents/articles/3214.monitoring-disk-usage.aspx.
Zkrátka:
- Fronta by neměla přesáhnout 1. Krátké dávky jsou povoleny, pokud rychle odezní. Shluky se mohou lišit v závislosti na vašem systému. Pro jednoduché zrcadlení RAID dvou HDD je fronta větší než 10-20 problém. U skvělé knihovny se super cachováním jsem viděl shluky až 600–800, které byly okamžitě vyřešeny, aniž by způsobily zpoždění.
- Normální směnný kurz závisí také na typu diskového systému. Obvyklý (desktopový) HDD přenáší rychlostí 50-100 MB/s. Dobrá disková knihovna – 500 MB/s a více. U malých náhodných operací je rychlost nižší. Toto může být váš referenční bod.
- Tyto parametry je třeba posuzovat jako celek. Pokud vaše knihovna přenáší 50 MB/s a fronta 50 operací se seřadí — zjevně je něco v nepořádku s hardwarem. Pokud se fronta seřadí, když se přenos blíží maximu – s největší pravděpodobností za to nemohou disky – prostě nemohou udělat víc – musíme hledat způsob, jak snížit zátěž.
- Zatížení by mělo být kontrolováno samostatně na discích (pokud jich je několik) a porovnáno s umístěním souborů na serveru. Správce úloh může zobrazit nejaktivněji používané soubory. To lze použít k zajištění toho, že zatížení je způsobeno DBMS.
Co může způsobit problémy se systémem disku:
- problémy s hardwarem
- vyhořela mezipaměť, výkon dramaticky klesl;
- systém disku používá něco jiného;
- Nedostatek paměti RAM. Výměna. Сaching se rozpadl, výkon klesl (viz část o RAM níže).
- Zatížení uživatelů se zvýšilo. Je potřeba vyhodnotit práci uživatelů (problematický dotaz/nová funkcionalita/nárůst počtu uživatelů/nárůst množství dat/atd).
- Fragmentace dat databáze (viz přestavění indexu výše), fragmentace systémových souborů.
- Diskový systém dosáhl svých maximálních možností.
V případě poslední možnosti – nevyhazovat hardware najednou. Někdy můžete ze systému získat o něco více, pokud k problému přistoupíte moudře. Zkontrolujte, zda umístění systémových souborů vyhovuje doporučeným požadavkům:
- Nesměšujte soubory OS s databázovými datovými soubory. Uložte je na různá fyzická média, aby systém nekonkuroval DBMS o I/O.
- Databáze se skládá ze dvou typů souborů:dat (*.mdf, *.ndf) a protokolů (*.ldf).
Datové soubory se zpravidla většinou používají ke čtení. Protokoly slouží k zápisu (přičemž zápis je po sobě jdoucí). Proto se doporučuje ukládat protokoly a data na různá fyzická média, aby protokolování nepřerušovalo čtení dat (zápis má zpravidla přednost před čtením). - MS SQL může pro zpracování dotazů používat „dočasné tabulky“. Jsou uloženy v systémové databázi tempdb. Pokud máte velké zatížení souborů této databáze, můžete se pokusit ji vykreslit na fyzicky oddělené médium.
Shrneme-li problém s umístěním souboru, použijte princip „rozděl a panuj“. Vyhodnoťte, ke kterým souborům se přistupuje, a zkuste je distribuovat na různá média. Využijte také funkce systémů RAID. Například čtení RAID-5 je rychlejší než zápis – což je dobré pro datové soubory.
Pojďme prozkoumat, jak získat informace o výkonu uživatelů:kdo co vyrábí a kolik zdrojů spotřebovává
Úkoly auditování uživatelské aktivity jsem rozdělil do následujících skupin:
- Úkoly analýzy konkrétního požadavku.
- Úkoly analýzy zatížení z aplikace za specifických podmínek (například když uživatel klikne na tlačítko v aplikaci třetí strany kompatibilní s databází).
- Úkoly analýzy současné situace.
Podívejme se podrobně na každou z nich.
Upozornění
Analýza výkonu vyžaduje hluboké pochopení struktury a principů fungování databázového serveru a operačního systému. To je důvod, proč čtení pouze těchto článků z vás neudělá profesionála.
Uvažovaná kritéria a čítače v reálných systémech na sobě velmi závisí. Například vysoká zátěž HDD je často způsobena nedostatkem paměti RAM. I když provedete nějaká měření, nestačí to k rozumnému posouzení problémů.
Účelem článků je uvést to podstatné na jednoduchých příkladech. Moje doporučení byste neměli považovat za vodítko. Doporučuji vám je používat jako tréninkové úkoly, které mohou vysvětlit tok myšlenek.
Doufám, že se naučíte, jak racionalizovat své závěry o výkonu serveru v číslech.
Místo toho, abyste řekli „server se zpomaluje“, uvedete konkrétní hodnoty konkrétních indikátorů.
Analyzujte P kloubní R equest
První bod je docela jednoduchý, pojďme se u něj krátce zastavit. Zvážíme některé méně zřejmé problémy.
Kromě výsledků dotazu umožňuje SSMS získat další informace o provádění dotazu:
- Plán dotazů získáte kliknutím na tlačítka „Zobrazit odhadovaný plán provedení“ a „Zahrnout skutečný plán provedení“. Rozdíl mezi nimi je v tom, že plán odhadu je sestaven bez provedení dotazu. Dojde tak k odhadu informace o počtu zpracovaných řádků. Ve skutečném plánu budou jak odhadovaná, tak skutečná data. Silné nesrovnalosti těchto hodnot naznačují, že statistiky nejsou relevantní. Rozbor plánu je však námětem na jiný článek – hlouběji zatím zacházet nebudeme.
- Můžeme získat měření nákladů na procesor a diskových operací serveru. K tomu je nutné povolit volbu SET. Můžete to udělat buď v dialogovém okně „Možnosti dotazu“ takto:
Nebo pomocí přímých příkazů SET v dotazu:
SET STATISTICS IO ON
SET STATISTICS TIME ON
SELECT * FROM Production.Product p
JOIN Production.ProductDocument pd ON p.ProductID = pd.ProductID
JOIN Production.ProductProductPhoto ppp ON p.ProductID = ppp.ProductIDV důsledku toho získáme data o čase stráveném kompilací a prováděním a také o počtu operací na disku.
Time of SQL Server parsing and compilation:
CPU time = 16 ms, elapsed time = 89 ms.
SQL Server performance time:
CPU time = 0 ms, time spent = 0 ms.
SQL Server performance time:
CPU time = 0 ms, time spent = 0 ms.
(32 row(s) affected)
The «ProductProductPhoto» table. The number of views is 32, logic reads – 96, physical reads 5, read-ahead reads 0, lob of logical reads 0, lob of physical reads 0, lob of read-ahead reads 0.
The ‘Product’ table. The number of views is 0, logic reads – 64, physical reads – 0, read-ahead reads – 0, lob of logical reads – 0, lob of physical reads – 0, lob of readahead reads – 0.
The «ProductDocument» table. The number of views is 1, logical reads – 3, physical reads – 1, read-ahead reads -, lob of logical reads – 0, lob of physical reads – 0, lob of readahead reads – 0.
Time of SQL activity:
CPU time = 15 ms, spent time = 35 ms.Chtěl bych vás upozornit na dobu kompilace, logické čtení 96 a fyzické čtení 5. Při provádění stejného dotazu podruhé a později může dojít ke snížení fyzického čtení a rekompilace nemusí být vyžadována. Díky této skutečnosti se často stává, že dotaz je během druhého a dalších časů proveden rychleji než poprvé. Důvod, jak víte, je v ukládání dat do mezipaměti a sestavených plánech dotazů.
- Tlačítko «Zahrnout statistiku klienta» zobrazuje informace o výměně sítě, množství provedených operací a celkovou dobu provádění, včetně nákladů na výměnu sítě a zpracování klientem. Příklad ukazuje, že první provedení dotazu trvá déle:
- V SSMS 2016 je tlačítko «Zahrnout statistiku dotazů v reálném čase». Zobrazuje obrázek jako v případě plánu dotazu, ale obsahuje nenáhodné číslice zpracovávaných řádků, které se na obrazovce při provádění dotazu mění. Obrázek je velmi jasný – blikající šipky a běžící čísla, hned vidíte, kde se plýtvá časem. Tlačítko funguje také pro SQL Server 2014 a novější.
Abych to shrnul:
- Zkontrolujte náklady na CPU pomocí SET STATISTICS TIME ON.
- Operace s diskem:ZAPNĚTE STATISTICS IO. Nezapomeňte, že čtení logiky je operace čtení dokončená v diskové mezipaměti bez fyzického přístupu k systému disku. „Fyzické čtení“ zabere mnohem více času.
- Vyhodnoťte objem síťového provozu pomocí «Zahrnout statistiku klienta».
- Analyzujte algoritmus provádění dotazu podle prováděcího plánu pomocí «Zahrnout skutečný plán provádění» a «Zahrnout statistiku dotazů v reálném čase».
Analyzujte zatížení aplikace
Zde použijeme SQL Server Profiler. Po spuštění a připojení k serveru je nutné vybrat protokol událostí. Chcete-li to provést, spusťte profilování pomocí standardní šablony trasování. Na stránce Obecné na kartě Použít šablonu vyberte Standardní (výchozí) a klikněte na Spustit .
Složitějším způsobem je přidat/upustit filtry nebo události do/z vybrané šablony. Tyto možnosti lze nalézt na druhé záložce dialogového menu. Chcete-li zobrazit celou řadu možných událostí a sloupců, které lze vybrat, vyberte možnost Zobrazit všechny události a Zobrazit všechny sloupce zaškrtávací políčka.

Budeme potřebovat následující události:
- Uložené procedury \ RPC:Dokončeno
- TSQL \ SQL:BatchCompleted
Tyto události monitorují všechna externí volání SQL na server. Objeví se po dokončení zpracování dotazu. Existují podobné události, které sledují spuštění serveru SQL:
- Uložené procedury \ RPC:Spouštění
- TSQL \ SQL:BatchStarting
Tyto procedury však nepotřebujeme, protože neobsahují informace o prostředcích serveru vynaložených na provádění dotazu. Je zřejmé, že takové informace jsou dostupné až po dokončení exekučního procesu. Sloupce s údaji o CPU, čteních a zápisech v událostech *Starting budou tedy prázdné.
Následující události nás mohou také zajímat, ale zatím je neumožníme:
- Uložené procedury \ SP:Starting (*Completed) monitoruje interní volání uložené procedury nikoli od klienta, ale v rámci aktuálního požadavku nebo jiné procedury.
- Uložené procedury \ SP:StmtStarting (*Dokončeno) sleduje začátek každého příkazu v rámci uložené procedury. Pokud je v proceduře cyklus, počet událostí pro příkazy v cyklu se bude rovnat počtu iterací v cyklu.
- TSQL \ SQL:StmtStarting (*Completed) monitoruje začátek každého příkazu v dávce SQL. Pokud je ve vašem dotazu několik příkazů, každý z nich bude obsahovat jednu událost. Funguje tedy pro příkazy umístěné v dotazu.
Tyto události jsou vhodné pro monitorování procesu provádění.
Od C sloupce
Které sloupce vybrat, je jasné z názvu tlačítka. Budeme potřebovat následující:
- TextData, BinaryData obsahují text dotazu.
- CPU, Čtení, Zápis, Trvání zobrazují údaje o spotřebě zdrojů.
- StartTime, EndTime je čas pro zahájení a dokončení procesu provádění. Jsou vhodné pro třídění.
Přidejte další sloupce podle svých preferencí.
Filtry sloupců… otevře dialogové okno pro konfiguraci filtrů událostí. Pokud vás zajímá aktivita konkrétního uživatele, můžete nastavit filtr podle čísla SID nebo uživatelského jména. Bohužel v případě připojení aplikace přes app-server s pull připojením se sledování konkrétního uživatele zkomplikuje.
Filtry můžete použít pro výběr pouze složitých dotazů (Duration>X), dotazů, které způsobují intenzivní zápis (Zápisy>Y), stejně jako výběrů obsahu dotazů atd.
Co dalšího od profilovače potřebujeme? Samozřejmě plán provádění!
K trasování je nutné přidat událost «Performance \ Showplan XML Statistics Profile». Při provádění našeho dotazu získáme následující obrázek:
Text dotazu:
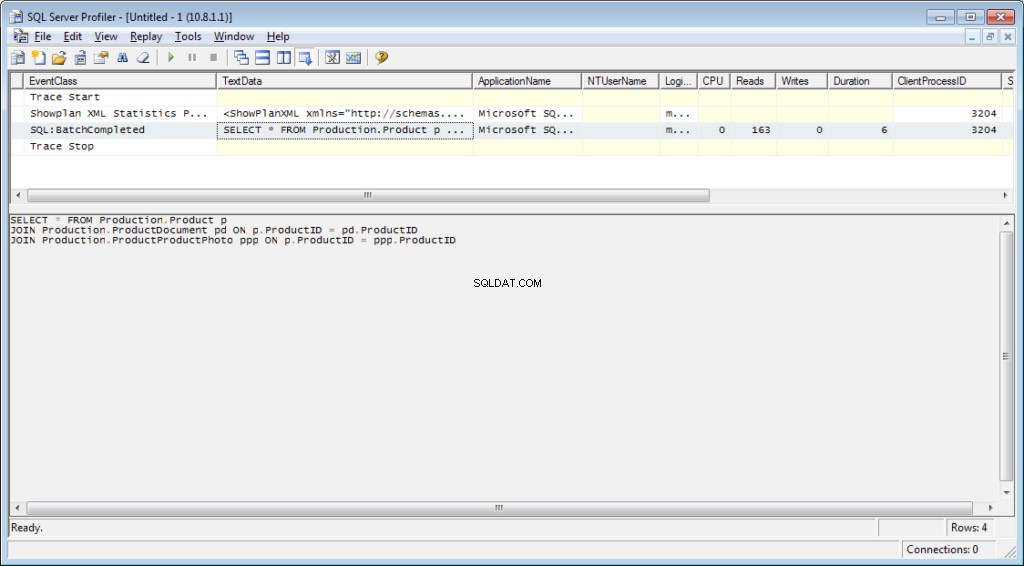
Plán realizace:
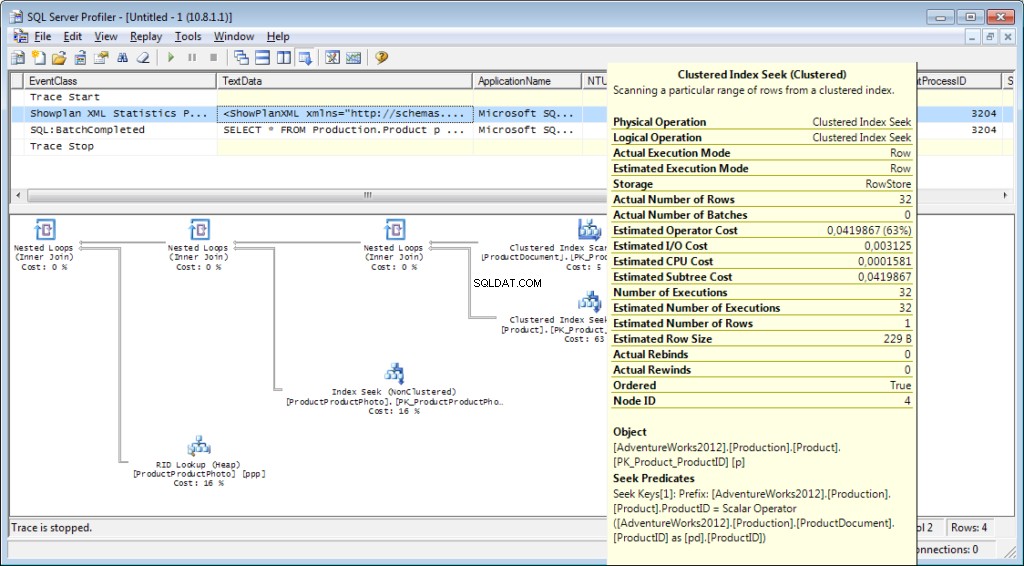
A to není vše
Trasování je možné uložit do souboru nebo databázové tabulky. Nastavení trasování lze uložit jako osobní šablonu pro rychlý běh. Trasování můžete spustit bez profileru, jednoduše pomocí kódu T-SQL a procedur sp_trace_create, sp_trace_setevent, sp_trace_setstatus, sp_trace_getdata. Příklad najdete zde. Tento přístup může být užitečný například pro automatické zahájení ukládání trasování do souboru podle plánu. Můžete mít záludný vrchol v profileru, abyste viděli, jak tyto příkazy používat. Můžete spustit dvě stopy a v jedné z nich sledovat, co se stane, když se spustí druhá. Zkontrolujte, že ve sloupci „ApplicationName“ na samotném profilovači není žádný filtr.
Seznam událostí monitorovaných profilerem je velmi rozsáhlý a neomezuje se na přijímání textů dotazů. Existují události, které sledují fullscan, rekompilaci, autogrow, uváznutí a mnoho dalšího.
Analýza aktivity uživatele na serveru
Existují různé situace. Dotaz může viset na „exekuci“ po dlouhou dobu a není jasné, zda bude dokončen nebo ne. Rád bych problémový dotaz rozebral samostatně; nejdříve však musíme určit, o jaký dotaz jde. Je zbytečné to chytat profilerem – startovací událost jsme již propásli a není jasné, jak dlouho čekat na dokončení procesu.
Pojďme na to
Možná jste slyšeli o „Monitor aktivity“. Jeho vyšší edice mají opravdu bohatou funkcionalitu. Jak nám to může pomoci? Monitor aktivity obsahuje mnoho užitečných a zajímavých funkcí. Vše potřebné získáme ze systémových pohledů a funkcí. Monitor samotný je užitečný, protože na něm můžete nastavit profiler a sledovat, jaké dotazy provádí.
Budeme potřebovat:
- dm_exec_sessions poskytuje informace o relacích připojených uživatelů. V našem článku jsou užitečná pole ta, která identifikují uživatele (login_name, login_time, host_name, program_name, …) a pole s informacemi o vynaložených zdrojích (cpu_time, reads, writes, memory_usage, …)
- dm_exec_requests poskytuje informace o aktuálně prováděných dotazech.
- id_relace je identifikátor relace, který má odkazovat na předchozí zobrazení.
- start_time je čas pro spuštění zobrazení.
- příkaz je pole, které obsahuje typ provedeného příkazu. Pro uživatelské dotazy je to select/update/delete/
- sql_handle, statement_start_offset, statement_end_offset poskytují informace pro načtení textu dotazu:handle a také počáteční a koncovou pozici v textu dotazu, což znamená část, která se právě provádí (pro případ, že váš dotaz obsahuje několik příkazy).
- plan_handle je popisovač vygenerovaného plánu.
- blocking_session_id udává počet relace, která způsobila zablokování, pokud existují bloky, které brání provedení dotazu
- wait_type, wait_time, wait_resource jsou pole s informacemi o důvodu a délce čekání. Pro některé typy čekání, například zámek dat, je nutné dodatečně uvést kód pro blokovaný zdroj.
- percent_complete je procento dokončení. Bohužel je k dispozici pouze pro příkazy s jasně předvídatelným průběhem (například zálohování nebo obnovení).
- Cpu_time, reads, writes, logical_reads, grant_query_memory jsou náklady na zdroje.
- dm_exec_sql_text(sql_handle | plan_handle), sys.dm_exec_query_plan(plan_handle) jsou funkce pro získání textu a plánu provádění. Níže zvážíme příklad jeho použití.
- dm_exec_query_stats je souhrnná statistika provádění dotazů. Zobrazuje dotaz, počet jeho provedení a objem vynaložených prostředků.
Důležité poznámky
Výše uvedený seznam je jen malá část. Kompletní seznam všech systémových pohledů a funkcí je popsán v dokumentaci. Také je zde krásný obrázek ukazující schéma vazeb mezi hlavními objekty.
Text dotazu, jeho plán a statistika provádění jsou data uložená v mezipaměti procedur. Jsou k dispozici během provádění. Dostupnost pak není zaručena a závisí na zatížení mezipaměti. Ano, mezipaměť lze vyčistit ručně. Někdy se doporučuje, když prováděcí plány „vypadly“. Přesto je zde mnoho nuancí.
Pole „příkaz“ nemá pro požadavky uživatelů žádný význam, protože můžeme získat celý text. Je však velmi důležitý pro získávání informací o procesech systému. Zpravidla provádějí některé interní úkoly a nemají text SQL. U takových procesů je informace o příkazu jediným náznakem typu aktivity.
V komentářích k předchozímu článku byl dotaz, v čem je server zapojen, když by neměl fungovat. Odpověď bude pravděpodobně ve smyslu tohoto pole. V mé praxi pole „příkaz“ vždy poskytovalo něco zcela srozumitelného pro aktivní systémové procesy:autoshrink / autogrow / checkpoint / logwriter / atd.
Jak jej používat
Přejdeme k praktické části. Uvedu několik příkladů jeho použití. Možnosti serveru nejsou omezeny – můžete si vymyslet vlastní příklady.
Příklad 1. Jaký proces spotřebovává CPU/čtení/zápis/paměť
Nejprve se podívejte na relace, které spotřebovávají více zdrojů, například CPU. Tyto informace můžete najít v sys.dm_exec_sessions. Data na CPU, včetně čtení a zápisu, jsou však kumulativní. To znamená, že číslo obsahuje součet za celou dobu připojení. Je jasné, že vyšší hodnotu bude mít uživatel, který se připojil před měsícem a nebyl odpojen. Neznamená to, že přetěžují systém.
Tento problém může vyřešit kód s následujícím algoritmem:
- Proveďte výběr a uložte jej do dočasné tabulky
- Počkejte nějakou dobu
- Proveďte výběr podruhé
- Porovnejte tyto výsledky. Jejich rozdíl bude udávat náklady vynaložené v kroku 2.
- Pro usnadnění lze rozdíl vydělit trváním kroku 2, abychom získali průměrné „náklady za sekundu“.
if object_id('tempdb..#tmp') is NULL
BEGIN
SELECT * into #tmp from sys.dm_exec_sessions s
PRINT 'wait for a second to collect statistics at the first run '
-- we do not wait for the next launches, because we compare with the result of the previous launch
WAITFOR DELAY '00:00:01';
END
if object_id('tempdb..#tmp1') is not null drop table #tmp1
declare @d datetime
declare @dd float
select @d = crdate from tempdb.dbo.sysobjects where id=object_id('tempdb..#tmp')
select * into #tmp1 from sys.dm_exec_sessions s
select @dd=datediff(ms,@d,getdate())
select @dd AS [time interval, ms]
SELECT TOP 30 s.session_id, s.host_name, db_name(s.database_id) as db, s.login_name,s.login_time,s.program_name,
s.cpu_time-isnull(t.cpu_time,0) as cpu_Diff, convert(numeric(16,2),(s.cpu_time-isnull(t.cpu_time,0))/@dd*1000) as cpu_sec,
s.reads+s.writes-isnull(t.reads,0)-isnull(t.writes,0) as totIO_Diff, convert(numeric(16,2),(s.reads+s.writes-isnull(t.reads,0)-isnull(t.writes,0))/@dd*1000) as totIO_sec,
s.reads-isnull(t.reads,0) as reads_Diff, convert(numeric(16,2),(s.reads-isnull(t.reads,0))/@dd*1000) as reads_sec,
s.writes-isnull(t.writes,0) as writes_Diff, convert(numeric(16,2),(s.writes-isnull(t.writes,0))/@dd*1000) as writes_sec,
s.logical_reads-isnull(t.logical_reads,0) as logical_reads_Diff, convert(numeric(16,2),(s.logical_reads-isnull(t.logical_reads,0))/@dd*1000) as logical_reads_sec,
s.memory_usage, s.memory_usage-isnull(t.memory_usage,0) as [mem_D],
s.nt_user_name,s.nt_domain
from #tmp1 s
LEFT join #tmp t on s.session_id=t.session_id
order BY
cpu_Diff desc
--totIO_Diff desc
--logical_reads_Diff desc
drop table #tmp
GO
select * into #tmp from #tmp1
drop table #tmp1 V kódu používám dvě tabulky:#tmp – pro první výběr a #tmp1 – pro druhý. Během prvního spuštění skript vytvoří a naplní #tmp a #tmp1 v intervalu jedné sekundy a poté provede další úkoly. Při dalších spuštěních skript použije výsledky předchozího provedení jako základ pro srovnání. Doba trvání kroku 2 se tedy bude rovnat délce čekání mezi spuštěním skriptu.
Zkuste to spustit, dokonce i na produkčním serveru. Skript vytvoří pouze ‚dočasné tabulky‘ (dostupné v rámci aktuální relace a smazané, když je deaktivován) a nemá žádné vlákno.
Koho nebaví provádět dotaz v MS SSMS, může jej zabalit do aplikace napsané v jejich oblíbeném programovacím jazyce. Ukážu vám, jak to udělat v MS Excel bez jediného řádku kódu.
V nabídce Data se připojte k serveru. Pokud se zobrazí výzva k výběru tabulky, vyberte náhodnou. Klikněte na Další a Dokončit, dokud se nezobrazí dialogové okno Import dat. V tomto okně musíte kliknout na Vlastnosti. Ve vlastnostech je nutné nahradit typ příkazu hodnotou SQL a vložit náš upravený dotaz do textového pole příkazu.
Budete muset dotaz trochu upravit:
- Přidejte „NASTAVIT NOCOUNT ON“
- Nahraďte dočasné tabulky tabulkami proměnných
- Zpoždění bude trvat do 1 sekundy. Pole s průměrnými hodnotami nejsou povinná
Upravený Query for Excel
SET NOCOUNT ON;
declare @tmp table(session_id smallint primary key,login_time datetime,host_name nvarchar(256),program_name nvarchar(256),login_name nvarchar(256),nt_user_name nvarchar(256),cpu_time int,memory_usage int,reads bigint,writes bigint,logical_reads bigint,database_id smallint)
declare @d datetime;
select @d=GETDATE()
INSERT INTO @tmp(session_id,login_time,host_name,program_name,login_name,nt_user_name,cpu_time,memory_usage,reads,writes,logical_reads,database_id)
SELECT session_id,login_time,host_name,program_name,login_name,nt_user_name,cpu_time,memory_usage,reads,writes,logical_reads,database_id
from sys.dm_exec_sessions s;
WAITFOR DELAY '00:00:01';
declare @dd float;
select @dd=datediff(ms,@d,getdate());
SELECT
s.session_id, s.host_name, db_name(s.database_id) as db, s.login_name,s.login_time,s.program_name,
s.cpu_time-isnull(t.cpu_time,0) as cpu_Diff,
s.reads+s.writes-isnull(t.reads,0)-isnull(t.writes,0) as totIO_Diff,
s.reads-isnull(t.reads,0) as reads_Diff,
s.writes-isnull(t.writes,0) as writes_Diff,
s.logical_reads-isnull(t.logical_reads,0) as logical_reads_Diff,
s.memory_usage, s.memory_usage-isnull(t.memory_usage,0) as [mem_Diff],
s.nt_user_name,s.nt_domain
from sys.dm_exec_sessions s
left join @tmp t on s.session_id=t.session_id Výsledek:
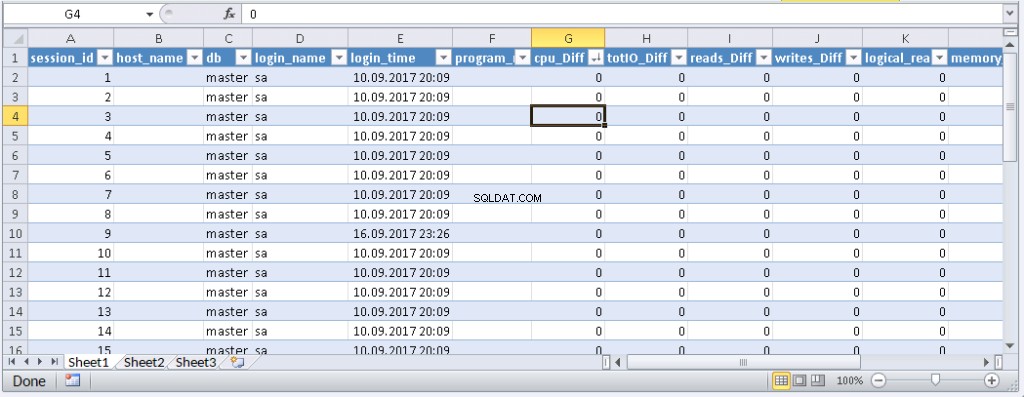
Když se data objeví v Excelu, můžete je třídit, jak potřebujete. Chcete-li aktualizovat informace, klikněte na „Obnovit“. V nastavení sešitu můžete zadat „automatická aktualizace“ v určeném časovém období a „aktualizace na začátku“. Soubor můžete uložit a předat svým kolegům. Vytvořili jsme tedy pohodlný a jednoduchý nástroj.
Příklad 2. Na co relace utrácí prostředky?
Nyní zjistíme, co problémové relace skutečně dělají. Chcete-li to provést, použijte sys.dm_exec_requests a funkce pro příjem textu dotazu a plánu dotazů.
Dotaz a plán provádění podle čísla relace
DECLARE @sql_handle varbinary(64) DECLARE @plan_handle varbinary(64) DECLARE @sid INT Declare @statement_start_offset int, @statement_end_offset INT, @session_id SMALLINT -- for the information by a particular user – indicate a session number SELECT @sid=182 -- receive state variables for further processing IF @sid IS NOT NULL SELECT @sql_handle=der.sql_handle, @plan_handle=der.plan_handle, @statement_start_offset=der.statement_start_offset, @statement_end_offset=der.statement_end_offset, @session_id = der.session_id FROM sys.dm_exec_requests der WHERE example@sqldat.com -- print the text of the query being executed DECLARE @txt VARCHAR(max) IF @sql_handle IS NOT NULL SELECT @txt=[text] FROM sys.dm_exec_sql_text(@sql_handle) PRINT @txt -- output the plan of the batch/procedure being executed IF @plan_handle IS NOT NULL select * from sys.dm_exec_query_plan(@plan_handle) -- and the plan of the query being executed within the batch/procedure IF @plan_handle IS NOT NULL SELECT dbid, objectid, number, encrypted, CAST(query_plan AS XML) AS planxml from sys.dm_exec_text_query_plan(@plan_handle, @statement_start_offset, @statement_end_offset)
Vložte číslo relace do dotazu a spusťte jej. After execution, there will be plans on the Results tab (the first one is for the whole query, and the second one is for the current step if there are several steps in the query) and the query text on the Messages tab. To view the plan, you need to click the text that looks like the URL in the row. The plan will be opened in a separate tab. Sometimes, it happens that the plan is opened not in a graphical form, but in the form of XML-text. This may happen because the MS SSMS version is lower than the server. Delete the “Version” and “Build” from the first row and then save the result XML to a file with the .sqlplan extension. After that, open it separately. If this does not help, I remind you that the 2016 studio is officially available for free on the MS website.
It is obvious that the result plan will be an estimated one, as the query is being executed. Still, it is possible to receive some execution statistics. To do this, use the sys.dm_exec_query_stats view with the filter by our handles.
Add this information at the end of the previous query
-- plan statistics IF @sql_handle IS NOT NULL SELECT * FROM sys.dm_exec_query_stats QS WHERE example@sqldat.com_handle
As a result, we will get the information about the steps of the executed query:how many times they were executed and what resources were spent. This information is added to the statistics only after the execution process is completed. The statistics are not tied to the user but are maintained within the whole server. If different users execute the same query, the statistics will be total for all users.
Example 3. Can I see all of them?
Let’s combine the system views we considered with the functions in one query. It can be useful for evaluating the whole situation.
-- receive a list of all current queries SELECT LEFT((SELECT [text] FROM sys.dm_exec_sql_text(der.sql_handle)),500) AS txt --,(select top 1 1 from sys.dm_exec_query_profiles where session_id=der.session_id) as HasLiveStat ,der.blocking_session_id as blocker, DB_NAME(der.database_id) AS База, s.login_name, * from sys.dm_exec_requests der left join sys.dm_exec_sessions s ON s.session_id = der.session_id WHERE der.session_id<>@@SPID -- AND der.session_id>50
The query outputs a list of active sessions and texts of their queries. For system processes, usually, there is no query; however, the command field is filled up. You can see the information about blocks and waits, and mix this query with example 1 in order to sort by the load. Still, be careful, query texts may be large. Their massive selection can be resource-intensive and lead to a huge traffic increase. In the example, I limited the result query to the first 500 characters but did not execute the plan.
Conclusion
It would be great to get Live Query Statistics for an arbitrary session. According to the manufacturer, now, monitoring statistics requires many resources and therefore, it is disabled by default. Its enabling is not a problem, but additional manipulations complicate the process and reduce the practical benefit.
In this article, we analyzed user activity in the following ways:using possibilities MS SSMS, profiler, direct calls to system views. All these methods allow estimating costs on executing a query and getting the execution plan. Each method is suitable for a particular situation. Thus, the best solution is to combine them.