Jedním z nejběžnějších problémů, ke kterým dochází při spouštění souběžných transakcí, je problém s nečistým čtením. Nečisté čtení nastane, když je jedné transakci povoleno číst data, která jsou upravována jinou transakcí, která běží souběžně, ale která se ještě nezavázala.
Pokud se transakce, která upravuje data, sama potvrdí, problém s nečistým čtením nenastane. Pokud je však transakce, která upravuje data, vrácena zpět poté, co druhá transakce data přečetla, tato transakce obsahuje špinavá data, která ve skutečnosti neexistují.
Jako vždy se před experimentováním s novým kódem ujistěte, že máte dobrou zálohu. Pokud si nejste jisti, přečtěte si tento článek o zálohování databází MS SQL.
Pojďme to pochopit pomocí příkladu. Předpokládejme, že máme tabulku s názvem ‚Produkt‘, která ukládá ID, název a položku ItemsinStock pro produkt.
Tabulka vypadá takto:
[id tabulky=20 /]
Předpokládejme, že máte online systém, kde může uživatel nakupovat produkty a zároveň si produkty prohlížet. Podívejte se na následující obrázek.
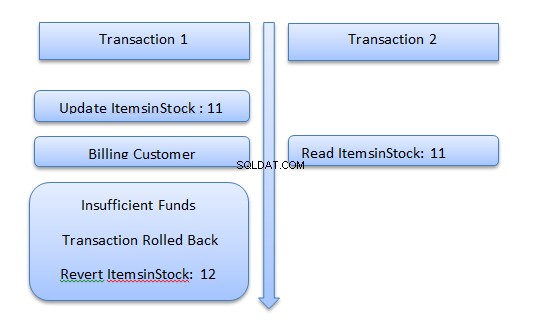
Zvažte scénář, kdy se uživatel pokouší koupit produkt. Transakce 1 provede za uživatele úkol nákupu. Prvním krokem v transakci bude aktualizace položky ItemsinStock.
Před transakcí je na skladě 12 položek; transakce to aktualizuje na 11. Transakce bude nyní komunikovat s externí fakturační bránou.
Pokud v tomto okamžiku další transakce, řekněme Transakce 2, bude mít hodnotu ItemsInStock pro notebooky, bude mít hodnotu 11. Pokud se však následně ukáže, že uživatel za Transakcí 1 nemá na svém účtu dostatek finančních prostředků, Transakce 1 bude odrolována. zpět a hodnota pro sloupec ItemsInStock se vrátí na 12.
Transakce 2 má však hodnotu 11 pro sloupec ItemsInStock. Toto jsou špinavá data a problém se nazývá špinavé čtení.
Pracovní příklad problému se špinavým čtením
Pojďme se podívat na problém špinavého čtení v akci na serveru SQL Server. Jako vždy nejprve vytvořte naši tabulku a přidejte do ní nějaká fiktivní data. Na svém databázovém serveru spusťte následující skript.
CREATE DATABASE pos;
USE pos;
CREATE TABLE products
(
Id INT PRIMARY KEY,
Name VARCHAR(50) NOT NULL,
ItemsinStock INT NOT NULL
)
INSERT into products
VALUES
(1, 'Laptop', 12),
(2, 'iPhone', 15),
(3, 'Tablets', 10)Nyní otevřete dvě instance SQL Server Management Studio vedle sebe. V každém z těchto případů provedeme jednu transakci.
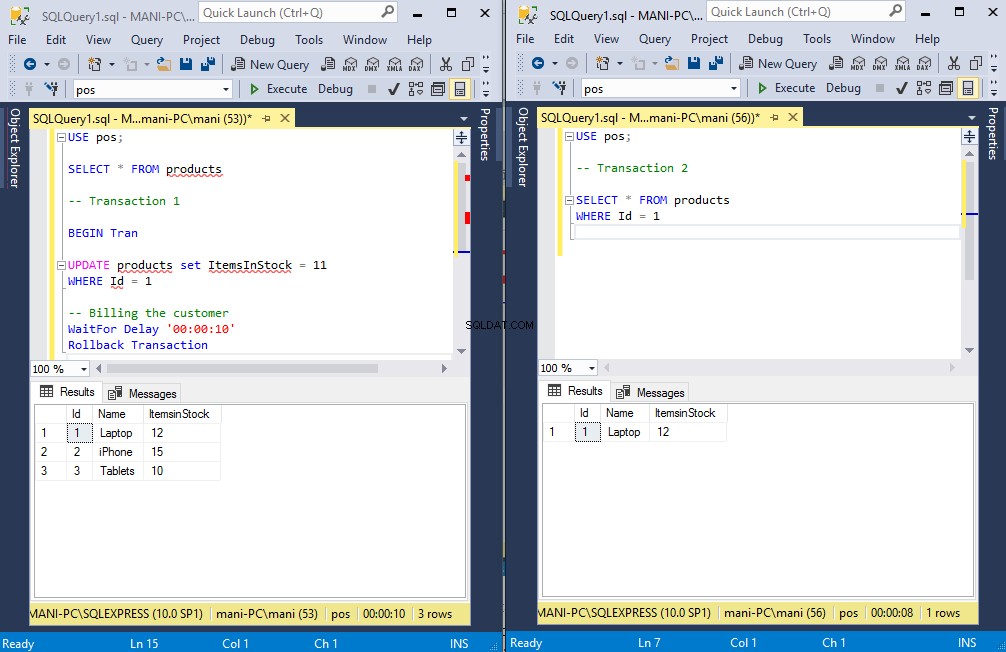
Přidejte následující skript do první instance SSMS.
USE pos;
SELECT * FROM products
-- Transaction 1
BEGIN Tran
UPDATE products set ItemsInStock = 11
WHERE Id = 1
-- Billing the customer
WaitFor Delay '00:00:10'
Rollback TransactionVe výše uvedeném skriptu zahájíme novou transakci, která aktualizuje hodnotu pro sloupec „ItemsInStock“ v tabulce produktů, kde Id je 1. Poté simulujeme zpoždění fakturace zákazníkovi pomocí funkcí „WaitFor“ a „Delay“. Ve skriptu bylo nastaveno zpoždění 10 sekund. Poté transakci jednoduše vrátíme zpět.
Ve druhém případě SSMS jednoduše přidáme následující příkaz SELECT.
USE pos;
-- Transaction 2
SELECT * FROM products
WHERE Id = 1Nyní nejprve spusťte první transakci, tj. spusťte skript v první instanci SSMS, a poté okamžitě spusťte skript v druhé instanci SSMS.
Uvidíte, že obě transakce budou probíhat po dobu 10 sekund a poté uvidíte, že hodnota pro sloupec ‚ItemsInStock‘ pro záznam s ID 1 je stále 12, jak ukazuje druhá transakce. Ačkoli první transakce aktualizovala hodnotu na 11, čekala 10 sekund a poté ji vrátila zpět na 12, druhá transakce ukazuje hodnotu 12, nikoli 11.
Ve skutečnosti se stalo, že když jsme provedli první transakci, aktualizovala se hodnota pro sloupec „ItemsinStock“. Poté počkal 10 sekund a poté transakci vrátil zpět.
Přestože jsme druhou transakci zahájili ihned po první, musela počkat na dokončení první transakce. To je důvod, proč druhá transakce také čekala 10 sekund a proč druhá transakce provedená ihned po dokončení první transakce.
Přečtěte si úroveň oddané izolace
Proč musela transakce 2 čekat na dokončení transakce 1, než byla provedena?
Odpověď zní, že výchozí úroveň izolace mezi transakcemi je „přečtení potvrzeno“. Úroveň izolace Read Committed zajišťuje, že data může transakce číst pouze v případě, že jsou ve stavu potvrzení.
V našem příkladu transakce 1 aktualizovala data, ale nepotvrdila je, dokud nebyla vrácena zpět. To je důvod, proč transakce 2 musela čekat na transakci 1, aby potvrdila data nebo vrátila transakci, než mohla data přečíst.
Nyní, v praktických scénářích, máme často více transakcí probíhajících v jedné databázi současně a nechceme, aby každá transakce musela čekat, až na ni přijde řada. To může databáze velmi zpomalit. Představte si, že kupujete něco online z velkého webu, který dokáže zpracovat pouze jednu transakci najednou!
Čtení nepotvrzených dat
Odpovědí na tento problém je umožnit vašim transakcím pracovat s nepotvrzenými daty.
Chcete-li číst data bez potvrzení, jednoduše nastavte úroveň izolace transakce na „read uncommitted“. Aktualizujte transakci 2 přidáním úrovně izolace podle níže uvedeného skriptu.
USE pos;
-- Transaction 2
set transaction isolation level read uncommitted
SELECT * FROM products
WHERE Id = 1Pokud nyní spustíte transakci 1 a poté okamžitě spustíte transakci 2, uvidíte, že transakce 2 nebude čekat na transakci 1, aby potvrdila data. Transakce 2 okamžitě přečte špinavá data. To je znázorněno na následujícím obrázku:
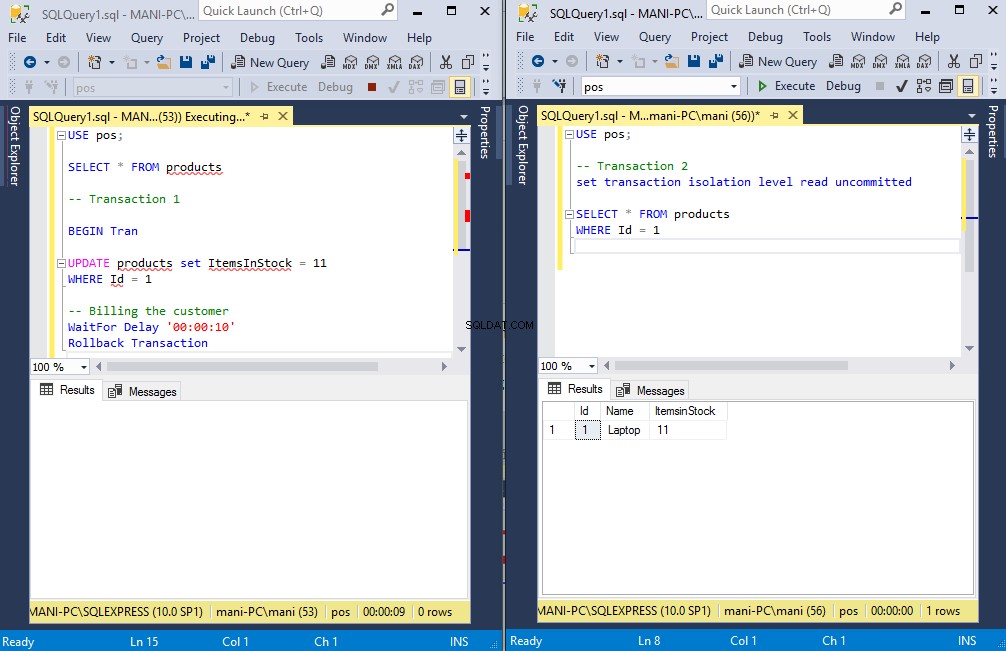
Zde instance nalevo spouští transakci 1 a instance napravo spouští transakci 2.
Nejprve spustíme transakci 1, která aktualizuje hodnotu „ItemsinStock“ pro ID 1 na 11 z 12 a poté čeká 10 sekund, než bude vrácena zpět.
Transakce w mezitím přečte špinavá data, která jsou 11, jak je znázorněno v okně výsledků vpravo. Protože transakce 1 je odvolána, nejedná se o skutečnou hodnotu v tabulce. Skutečná hodnota je 12. Zkuste znovu provést transakci 2 a uvidíte, že tentokrát načte 12.
Read uncommitted je jediná úroveň izolace, která má problém se špinavým čtením. Tato úroveň izolace je nejméně omezující ze všech úrovní izolace a umožňuje číst nepotvrzená data.
Je zřejmé, že používání Read Uncommitted má své klady a zápory, záleží na tom, pro jakou aplikaci se vaše databáze používá. Je zřejmé, že by byl velmi špatný nápad použít toto pro databázi za systémy ATM a dalšími velmi bezpečnými systémy. Pro aplikace, kde je rychlost velmi důležitá (provozování velkých e-commerce obchodů), má však použití Read Uncommitted větší smysl.