Správce databáze se vždy snaží vyladit výkon dotazů SQL Server. Prvním krokem při ladění výkonu dotazu je analýza plánu provádění dotazu. Za určitých podmínek může SQL Server Query Optimizer vytvořit různé plány provádění. V tomto bodě bych rád přidal několik poznámek o SQL Server Query Optimizer. SQL Server Query Optimizer je nákladově orientovaný optimalizátor, který analyzuje plány provádění a rozhoduje o optimálním plánu provádění pro dotaz. Významným klíčovým slovem pro SQL Server Query Optimizer je optimální plán provádění, který nemusí být nutně nejlepším plánem provádění. To je důvod, proč, pokud se SQL Server Query Optimizer pokusí najít nejlepší plán provádění pro každý dotaz, zabere to čas navíc a poškodí výkon SQL Server Engine. V SQL Server 2016 přidal Microsoft do SQL Server Management Studio novou schopnost s názvem Compare Showplan. Tato funkce nám umožňuje porovnat dva různé prováděcí plány. Zároveň můžeme tuto možnost použít offline, což znamená, že nepotřebujeme připojovat instanci SQL Serveru. Představte si, že napíšete dotaz a tento dotaz funguje dobře v prostředí TEST, ale v PROD (produkčním prostředí) funguje velmi špatně. Abychom tento problém zvládli, musíme porovnat plány provádění. Před touto funkcí jsme otevírali dvě SQL Server Management Studio a přinášeli prováděcí plány vedle sebe, ale tato metoda byla velmi nepohodlná.
Jak porovnat dva prováděcí plány?
V této ukázce použijeme databázi AdventureWorks a porovnáme dva plány provádění, které mají rozdílnou verzi modelu odhadu mohutnosti, a tento rozdíl zjistíme pomocí Porovnat plán zobrazení.
Nejprve otevřeme nové okno dotazu v SQL Server Management Studio a klikneme na Zahrnout skutečný plán provedení a poté proveďte následující dotaz.
SELECT
soh.[SalesPersonID]
,p.[FirstName] + ' ' + COALESCE(p.[MiddleName], '') + ' ' + p.[LastName] AS [FullName]
,e.[JobTitle]
,st.[Name] AS [SalesTerritory]
,soh.[SubTotal]
,YEAR(DATEADD(m, 6, soh.[OrderDate])) AS [FiscalYear]
FROM [Sales].[SalesPerson] sp
INNER JOIN [Sales].[SalesOrderHeader] soh
ON sp.[BusinessEntityID] = soh.[SalesPersonID]
INNER JOIN [Sales].[SalesTerritory] st
ON sp.[TerritoryID] = st.[TerritoryID]
INNER JOIN [HumanResources].[Employee] e
ON soh.[SalesPersonID] = e.[BusinessEntityID]
INNER JOIN [Person].[Person] p
ON p.[BusinessEntityID] = sp.[BusinessEntityID]
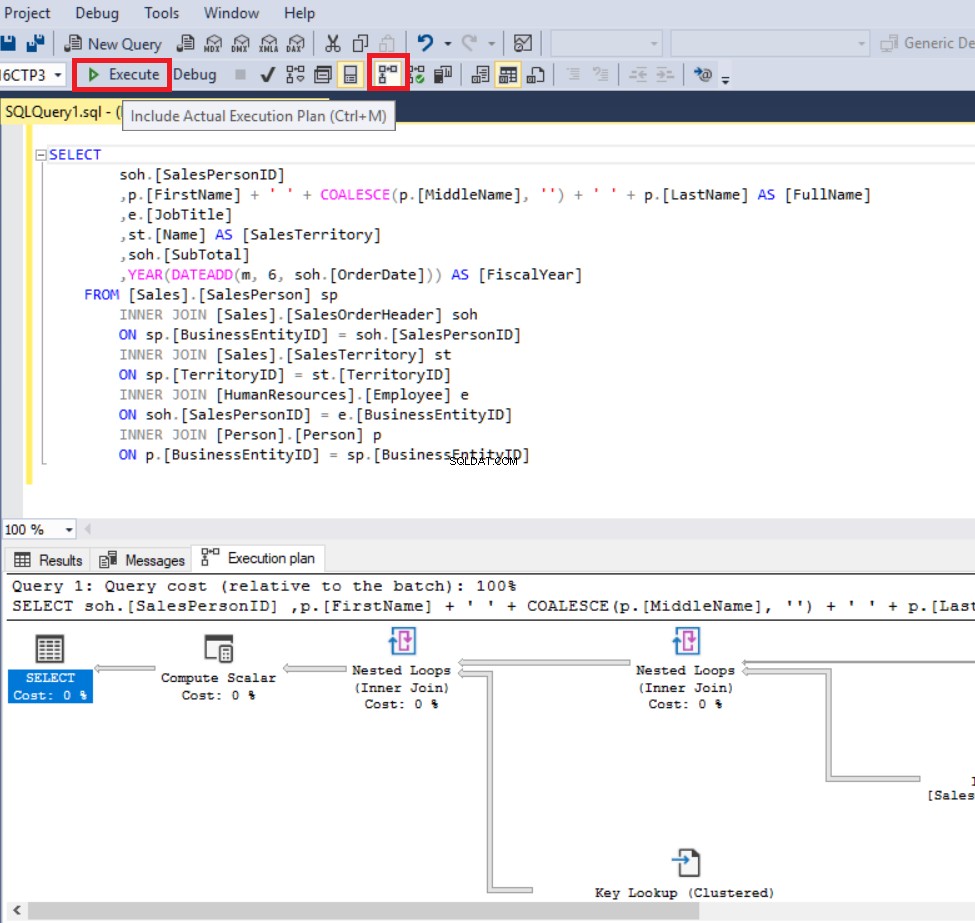
V tomto kroku uložíme náš první plán provádění. Klikněte pravým tlačítkem na libovolné místo v prováděcím plánu a klikněte na Uložit plán provádění jako a uložte plán provádění jako ExecutionPlan_CE140.sqlplan.
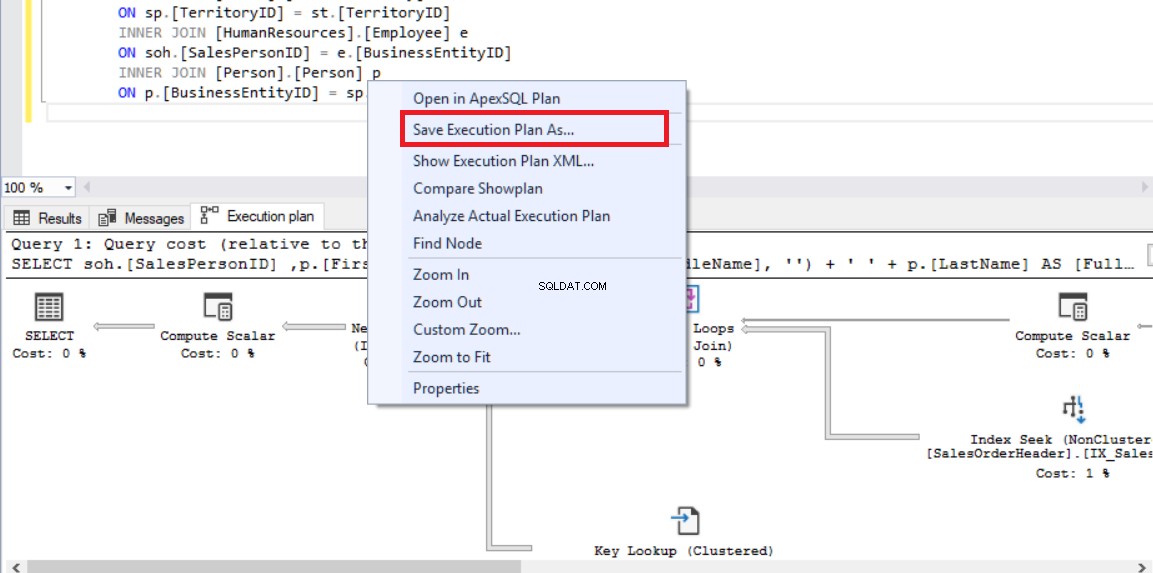
Nyní otevřeme novou kartu dotazu v SQL Server Management Studio a provedeme níže uvedený dotaz. V tomto dotazu přidáme na konec dotazu nápovědu k dotazu FORCE_LEGACY_CARDINALITY_ESTIMATION, která nutí používat starší verzi modelu odhadu mohutnosti.
Úkol Odhad mohutnosti je předpovědět, kolik řádků náš dotaz vrátí.
SELECT
soh.[SalesPersonID]
,p.[FirstName] + ' ' + COALESCE(p.[MiddleName], '') + ' ' + p.[LastName] AS [FullName]
,e.[JobTitle]
,st.[Name] AS [SalesTerritory]
,soh.[SubTotal]
,YEAR(DATEADD(m, 6, soh.[OrderDate])) AS [FiscalYear]
FROM [Sales].[SalesPerson] sp
INNER JOIN [Sales].[SalesOrderHeader] soh
ON sp.[BusinessEntityID] = soh.[SalesPersonID]
INNER JOIN [Sales].[SalesTerritory] st
ON sp.[TerritoryID] = st.[TerritoryID]
INNER JOIN [HumanResources].[Employee] e
ON soh.[SalesPersonID] = e.[BusinessEntityID]
INNER JOIN [Person].[Person] p
ON p.[BusinessEntityID] = sp.[BusinessEntityID]
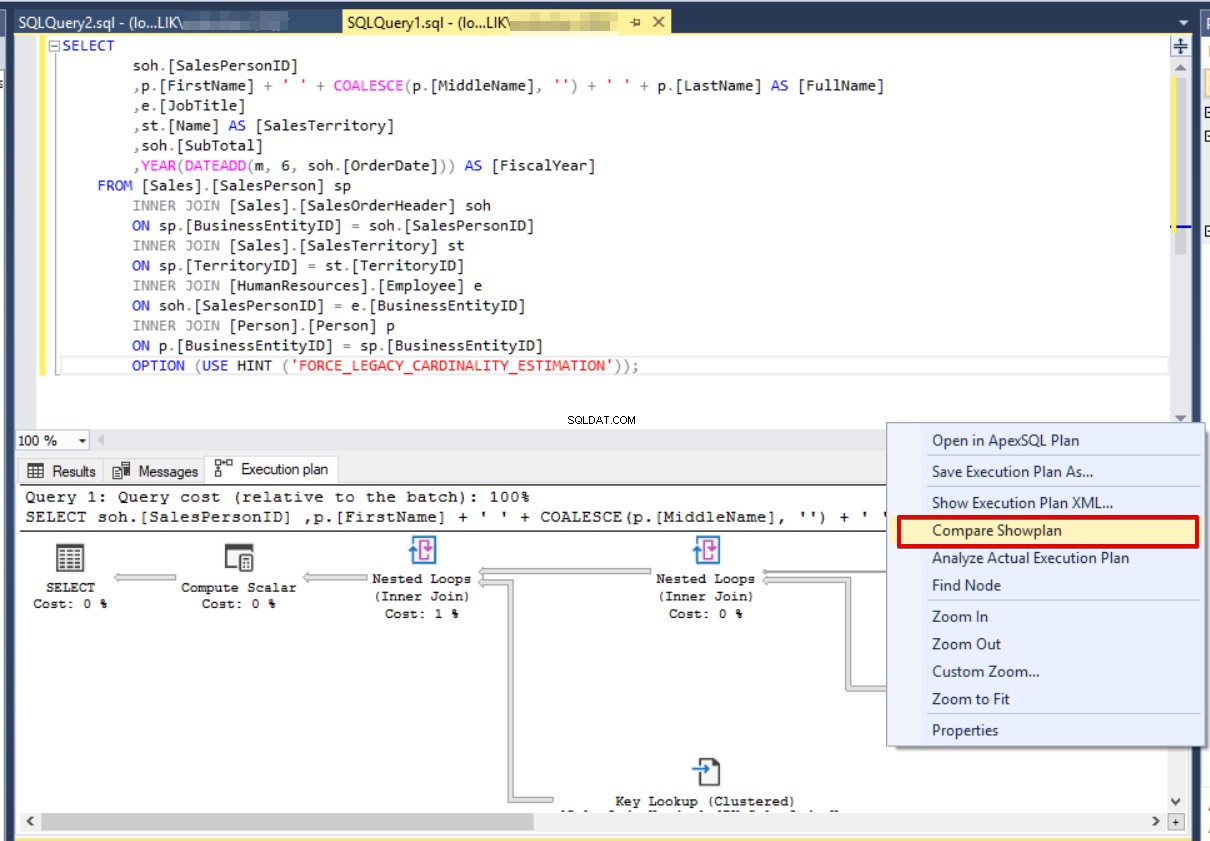
OPTION (USE HINT ('FORCE_LEGACY_CARDINALITY_ESTIMATION')); Klikneme naPorovnat plán zobrazení a vyberte předchozí plán provádění, který byl uložen jako ExecutionPlan_CE140.sqlplan.
Následující obrázek ilustruje první obrazovku srovnávacího plánu provádění SQL Serveru a růžově zvýrazněné oblasti definují podobné operace.
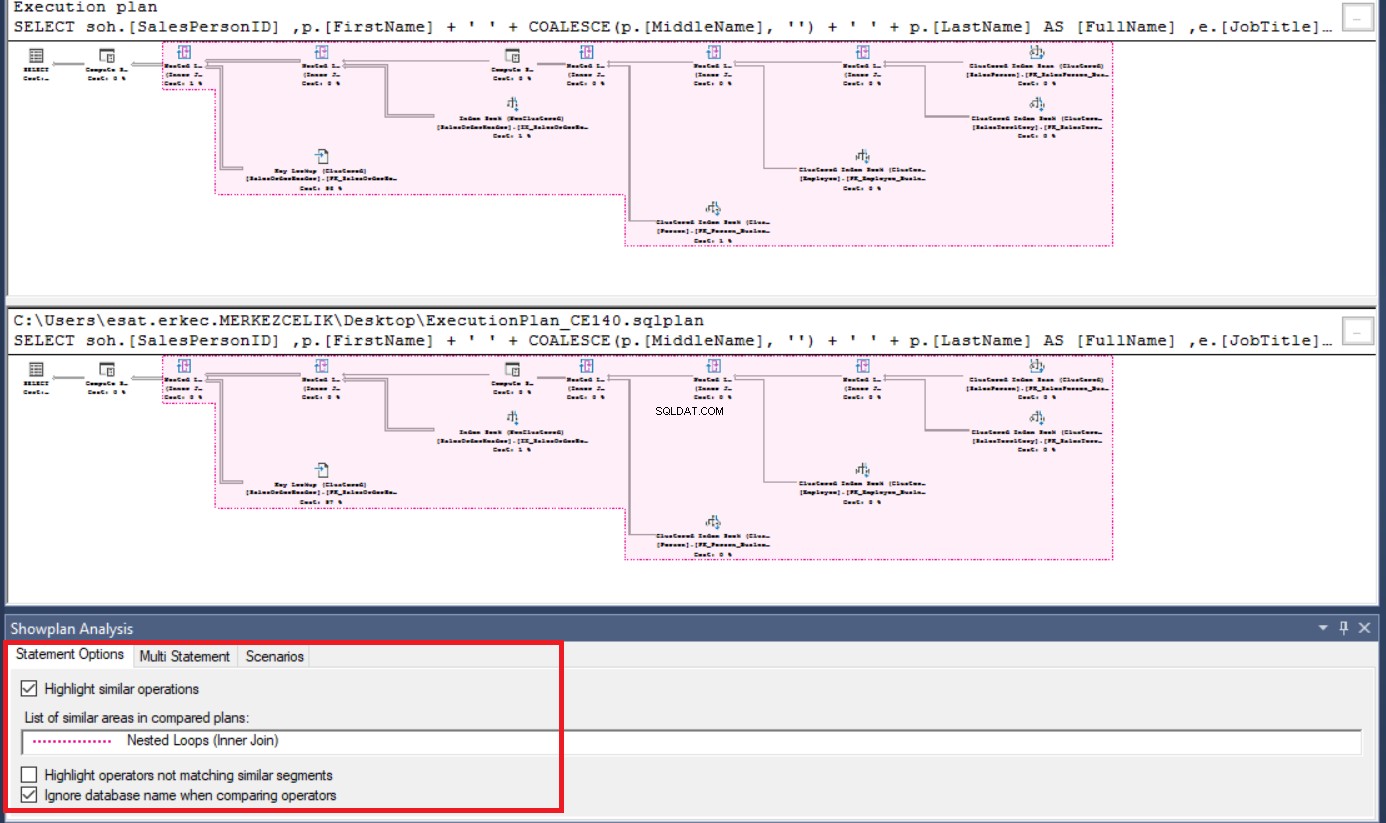
Pokud klepneme na libovolný operátor na obrazovce plánu provádění níže nebo výše, SQL Server Management Studio zvýrazní další podobné operátory. Na pravé straně panelu najdete vlastnosti a podrobnosti o porovnání vlastností.
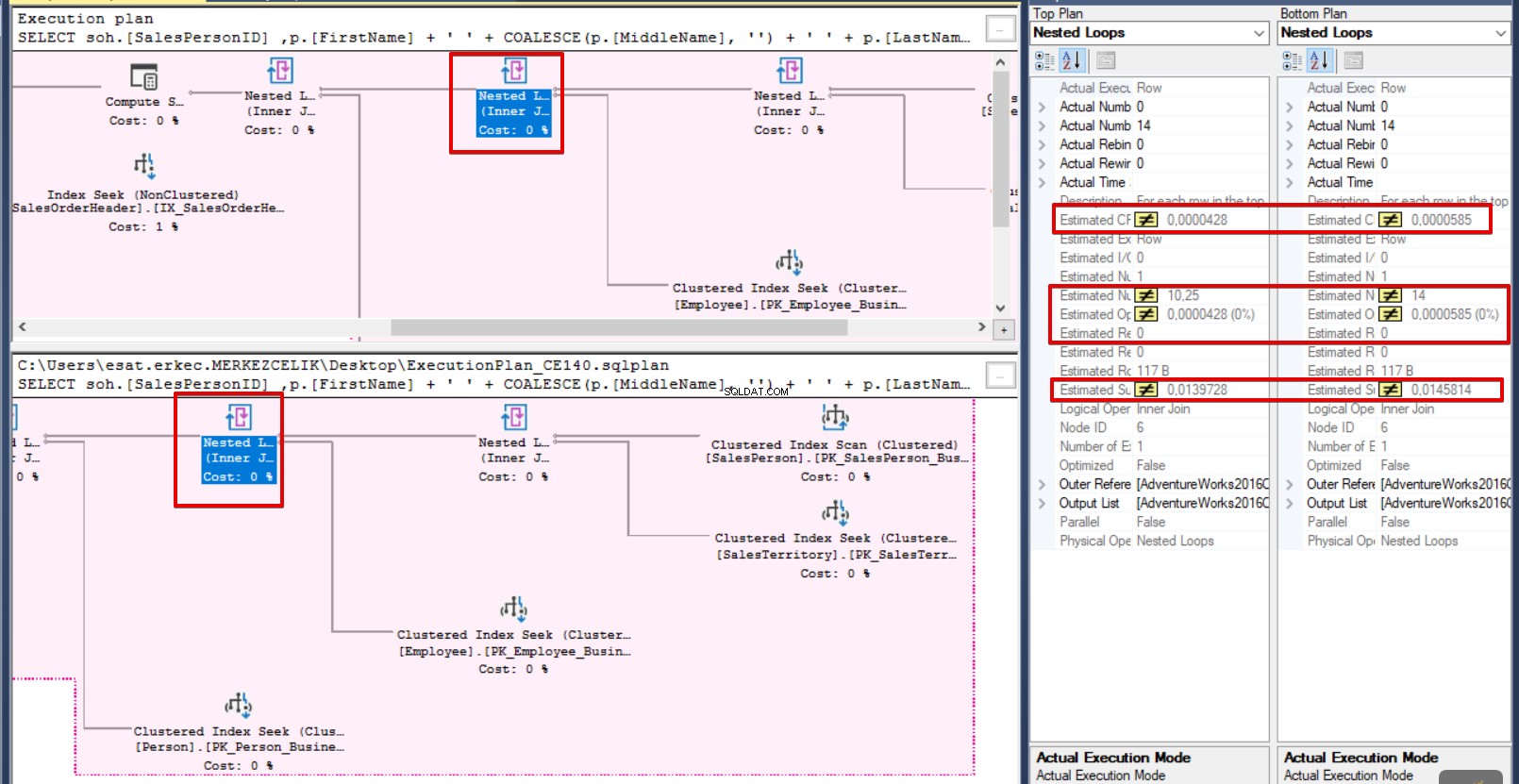
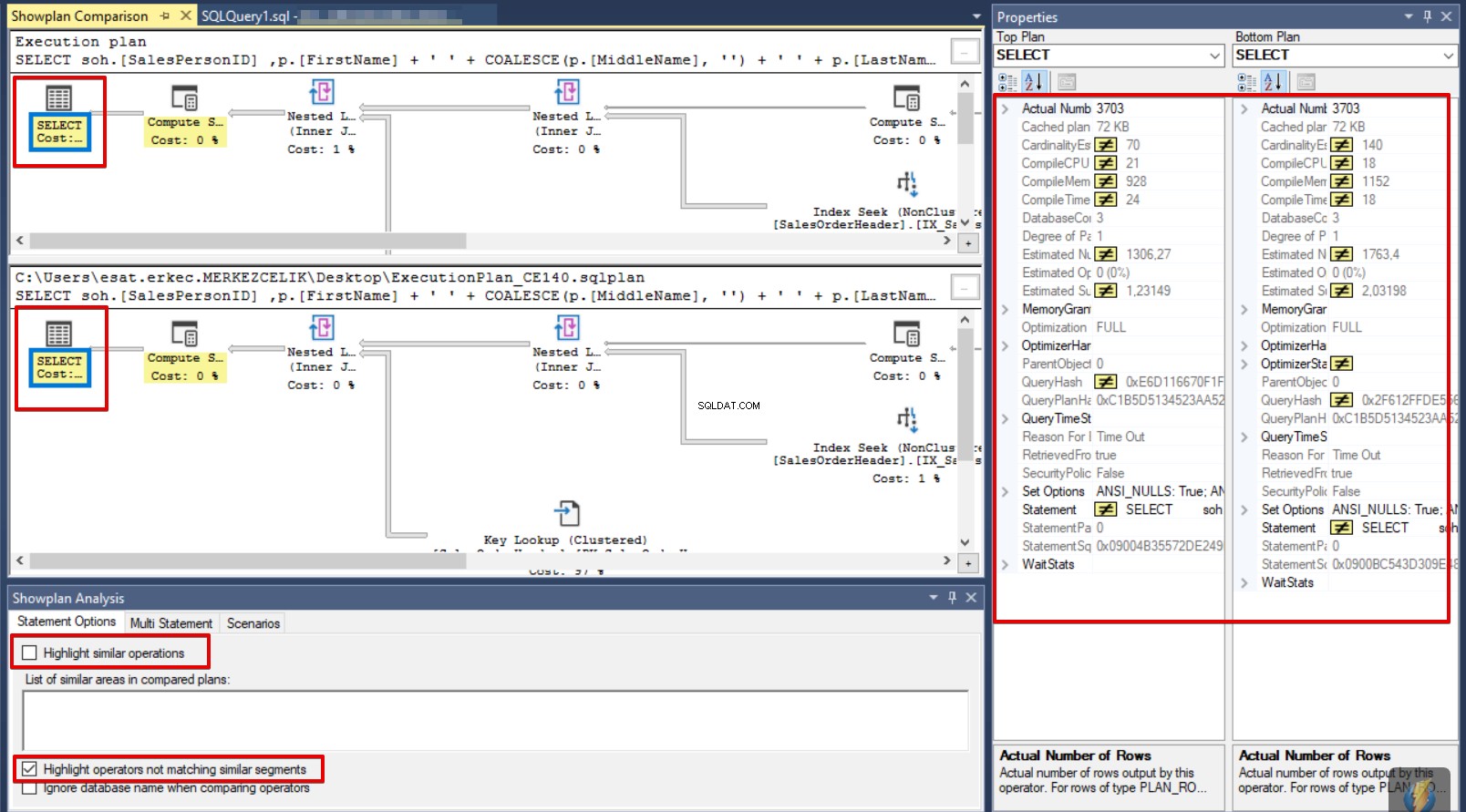
V tomto kroku změníme možnosti analýzy ShowPlan a zvýrazníme neodpovídající operátor. V dolní části obrazovky můžeme vidět Analýzu plánu show panel. Pokud vymažeme možnost Zvýraznit podobné operace a vyberte Zvýrazněte operátory, které neodpovídají podobným segmentům, SQL Server Management Studio zdůrazňuje bezkonkurenční operátor. Poté klikněte na Vybrat operátory v prováděcím plánu níže a výše v panelu. SQL Server Management Studio porovná vlastnosti vybraných operátorů a vloží znaky nerovnosti do neidentických hodnot.
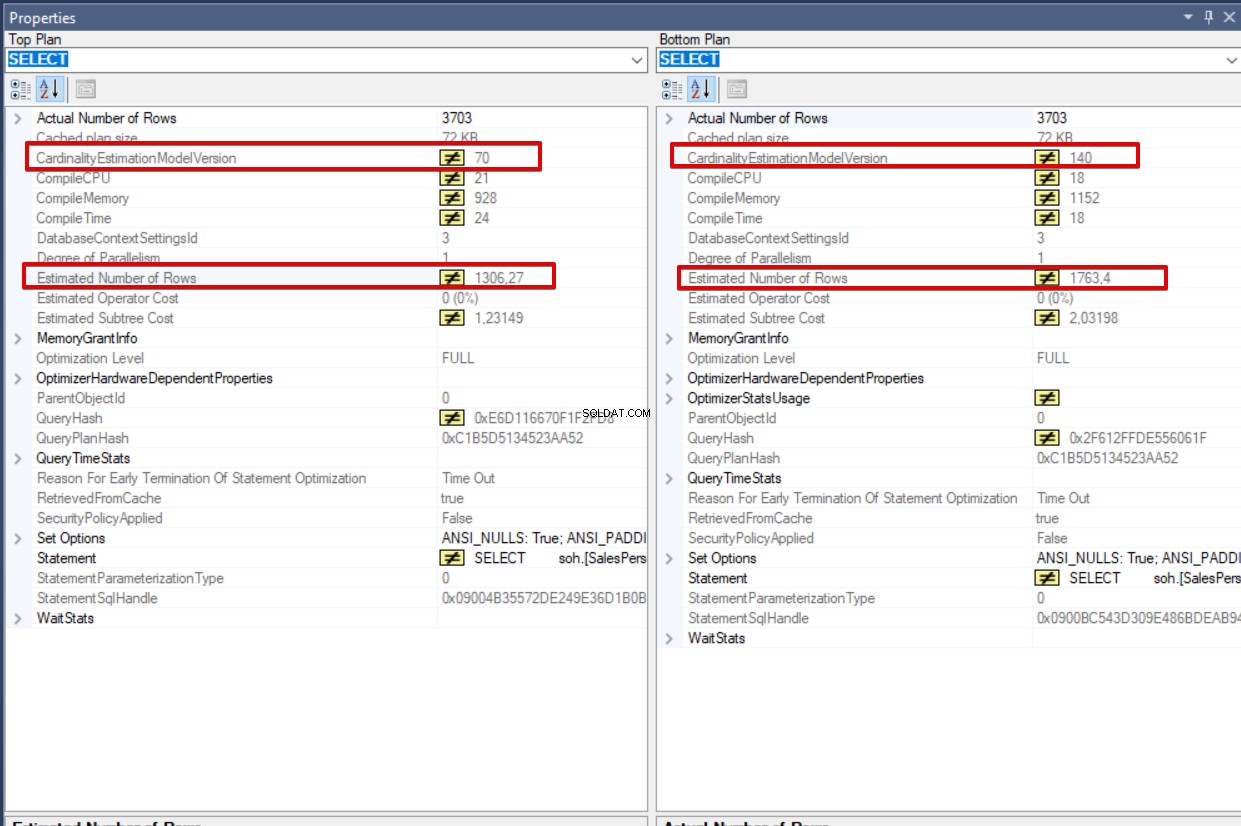
Pokud tuto obrazovku analyzujeme podrobněji, první věcí je Verze modelu odhadu mohutnosti rozdíl. První verze dotazu je 70 a druhá 140. Tento rozdíl ovlivňuje Odhadovaný počet řádků . Hlavním důvodem, který způsobuje rozdílný Odhadovaný počet řádků je jiná verze odhadu mohutnosti. Verze Cardinality Estimation tedy přímo ovlivňuje odhadované metriky dotazu. Pro toto srovnání dotazů můžeme dojít k závěru, že dotaz, jehož verze Cardinality Estimation je 140, funguje lépe, protože odhadovaný počet řádků se blíží skutečnému počtu řádků . Tento případ lze objasnit z níže uvedené tabulky.
[id tabulky=50 /]
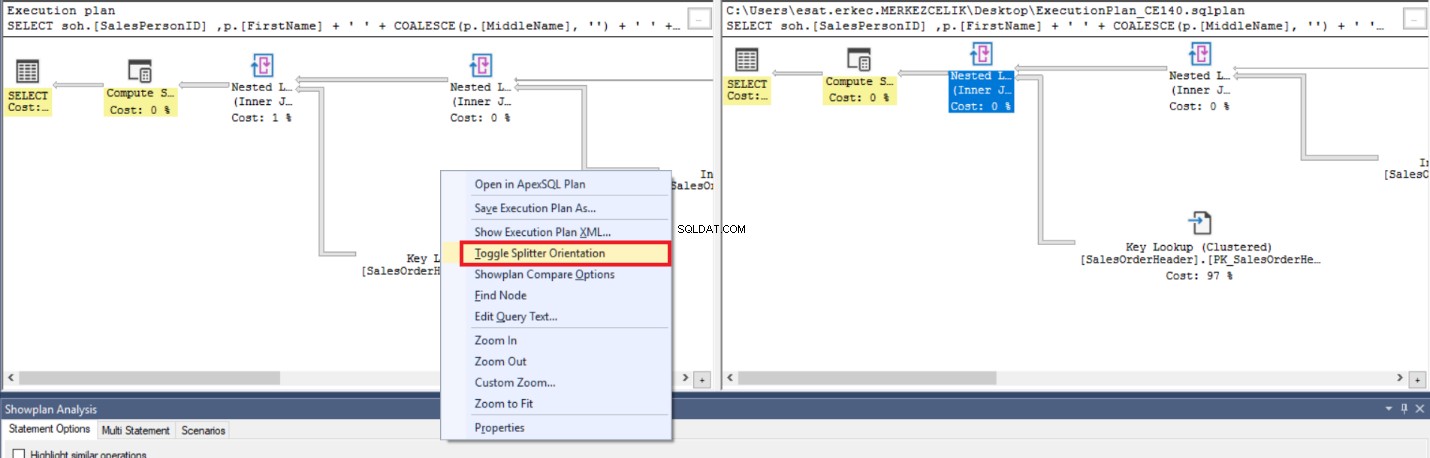
Pokud chceme vidět prováděcí plány vedle sebe na stejné obrazovce, můžeme kliknout na Přepnout orientaci rozdělovače .
Nyní uděláme další ukázku. Podíváme se na níže uvedený dotaz a porovnáme plány provádění před a po vytvoření indexu.
Když se podíváme na plán provádění dotazu níže, doporučuje se vytvořit index bez klastrů.
SELECT [CarrierTrackingNumber] FROM [Sales].[SalesOrderDetail] WHERE [SalesOrderDetailID]=12
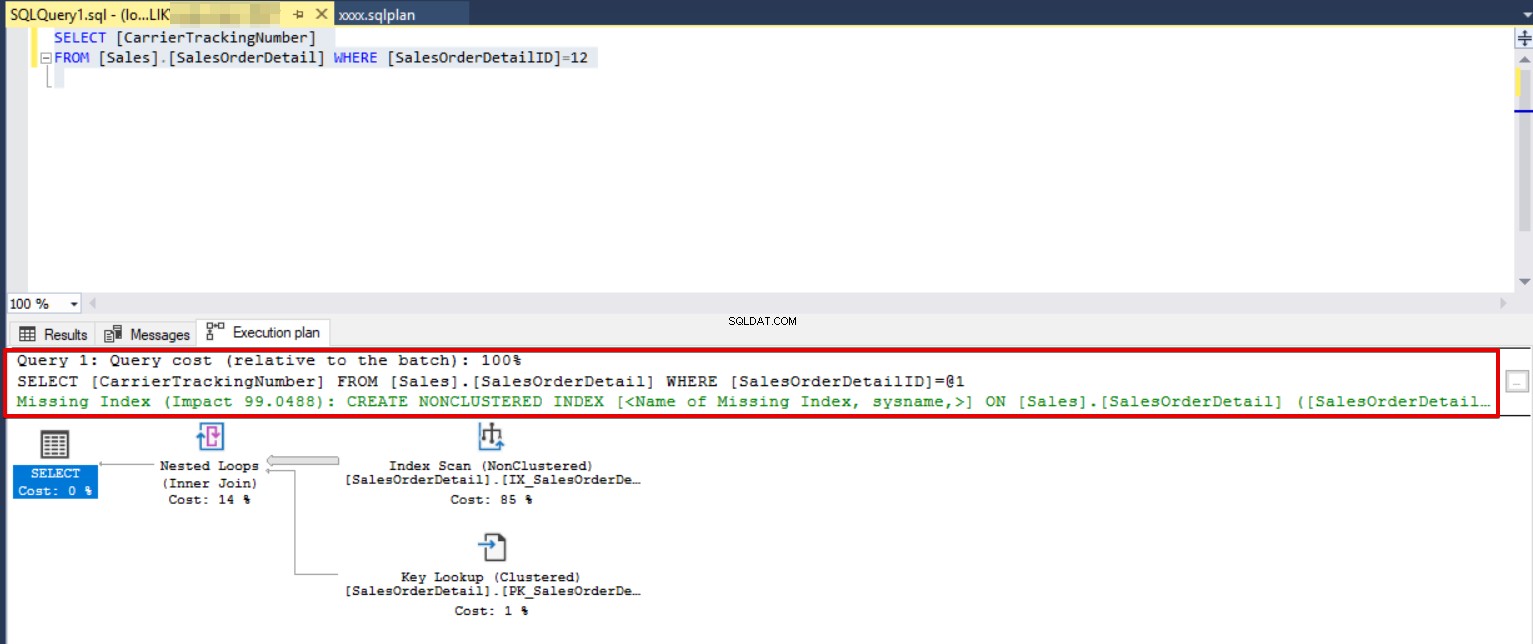
Použijeme doporučený index a znovu provedeme stejný dotaz.
CREATE NONCLUSTERED INDEX Index_NC ON [Sales].[SalesOrderDetail] ([SalesOrderDetailID]) GO SELECT [CarrierTrackingNumber] FROM [Sales].[SalesOrderDetail] WHERE [SalesOrderDetailID]=12
V tomto posledním kroku porovnáme prováděcí plány.
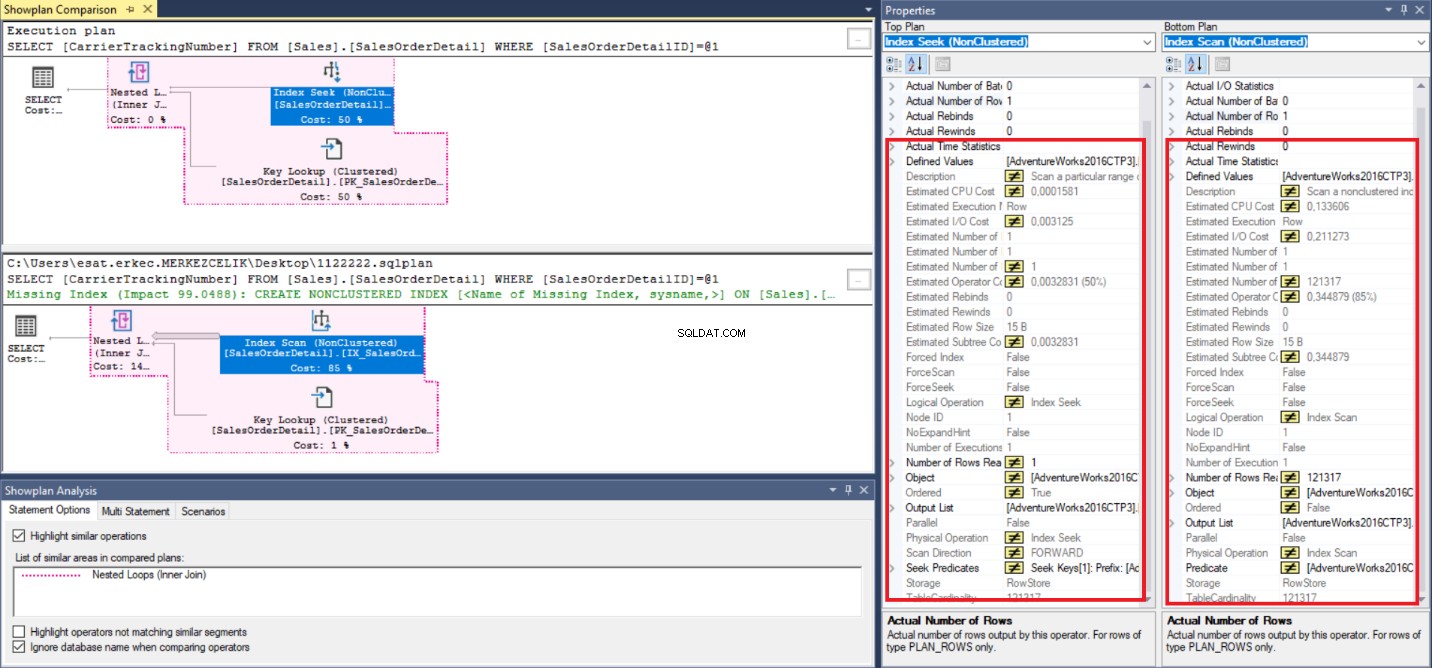
Na obrázku výše můžeme získat několik informací o prováděcích plánech. Ale hlavním rozdílem je logická operace pole. Jedním z nich je Vyhledávání indexu a další je Index Scan a tato diferenciace operací vede k odlišným odhadovaným a skutečným metrickým hodnotám. Operátor Index Seek funguje lépe než operátor Index Scan.
Závěry
Jak jsme zmínili v článku, funkce Compare Showplan nabízí některé výhody pro vývojáře databáze nebo správce. Některé z nich lze počítat jako:
- Jednoduché porovnání rozdílů mezi dvěma prováděcími plány.
- Jednoduché zjišťování problémů s výkonem dotazů v různých verzích SQL Server.
- Jednoduché zjišťování problémů s výkonem dotazů v různých prostředích.
- Jednoduše objasňuje změny plánu provádění před a po vytvoření indexu.
Odkazy
- Odhad mohutnosti (SQL Server)
- Průvodce architekturou zpracování dotazů