Úvod
Tento tutoriál obsahuje informace o SQL (DDL, DML), které jsem nasbíral během svého profesního života. To je minimum, které potřebujete vědět při práci s databázemi. Pokud je potřeba použít složité SQL konstrukce, pak většinou surfuji po knihovně MSDN, kterou lze snadno najít na internetu. Podle mého názoru je velmi obtížné udržet si vše v hlavě a mimochodem, není to potřeba. Doporučuji, abyste znali všechny hlavní konstrukce používané ve většině relačních databází, jako je Oracle, MySQL a Firebird. Přesto se mohou lišit v datových typech. Například pro vytváření objektů (tabulek, omezení, indexů atd.) můžete pro práci s databázemi jednoduše použít integrované vývojové prostředí (IDE) a není třeba studovat vizuální nástroje pro konkrétní typ databáze (MS SQL, Oracle , MySQL, Firebird atd.). To je výhodné, protože můžete vidět celý text a nemusíte procházet četnými kartami, abyste vytvořili například index nebo omezení. Pokud neustále pracujete s databázemi, je tvorba, úprava a hlavně přestavba objektu pomocí skriptů mnohem rychlejší než ve vizuálním režimu. Kromě toho je podle mého názoru v režimu skriptu (s patřičnou přesností) jednodušší specifikovat a ovládat pravidla pro pojmenovávání objektů. Kromě toho je vhodné použít skripty, když potřebujete přenést změny databáze z testovací databáze do produkční databáze.
SQL je rozdělen do několika částí. Ve svém článku zopakuji ty nejdůležitější:
DDL – Data Definition Language
DML – Data Manipulation Language, který zahrnuje následující konstrukce:
- SELECT – výběr dat
- INSERT – nové vložení dat
- AKTUALIZACE – aktualizace dat
- DELETE – smazání dat
- MERGE – slučování dat
Všechny konstrukce vysvětlím na studijních případech. Navíc si myslím, že programovací jazyk, zejména SQL, by se měl pro lepší pochopení studovat v praxi.
Toto je návod krok za krokem, kde je třeba při čtení provádět příklady. Pokud však potřebujete znát velení podrobně, pak surfujte po internetu, například MSDN.
Při vytváření tohoto tutoriálu jsem ke spouštění skriptů použil databázi MS SQL Server, verze 2014, a MS SQL Server Management Studio (SSMS).
Stručně o MS SQL Server Management Studio (SSMS)
SQL Server Management Studio (SSMS) je nástroj Microsoft SQL Server pro konfiguraci, správu a správu databázových komponent. Obsahuje editor skriptů a grafický program, který pracuje s objekty a nastaveními serveru. Hlavním nástrojem SQL Server Management Studio je Object Explorer, který umožňuje uživateli prohlížet, načítat a spravovat objekty serveru. Tento text je částečně převzat z Wikipedie.
Chcete-li vytvořit nový editor skriptů, použijte tlačítko Nový dotaz:
Pro přepnutí z aktuální databáze můžete použít rozbalovací nabídku:
Chcete-li provést určitý příkaz nebo sadu příkazů, zvýrazněte jej a stiskněte tlačítko Execute nebo F5. Pokud je v editoru pouze jeden příkaz nebo potřebujete provést všechny příkazy, nic nezvýrazňujte.
Po provedení skriptů, které vytvářejí objekty (tabulky, sloupce, indexy), vyberte odpovídající objekt (například Tabulky nebo Sloupce) a poté kliknutím na tlačítko Obnovit v místní nabídce zobrazte změny.
Ve skutečnosti je to vše, co potřebujete vědět k provedení zde uvedených příkladů.
Teorie
Relační databáze je sada vzájemně propojených tabulek. Obecně je databáze soubor, který ukládá strukturovaná data.
Database Management System (DBMS) je sada nástrojů pro práci s konkrétními typy databází (MS SQL, Oracle, MySQL, Firebird atd.).
Poznámka: Stejně jako v našem každodenním životě říkáme „Oracle DB“ nebo jen „Oracle“, což ve skutečnosti znamená „Oracle DBMS“, pak v tomto tutoriálu budu používat termín „databáze“.
Tabulka je sada sloupců. Velmi často můžete slyšet následující definice těchto pojmů:pole, řádky a záznamy, což znamená totéž.
Tabulka je hlavním objektem relační databáze. Všechna data jsou uložena řádek po řádku ve sloupcích tabulky.
Pro každou tabulku i pro její sloupce je potřeba zadat název, podle kterého požadovanou položku najdete.
Název objektu, tabulky, sloupce a indexu může mít minimální délku – 128 symbolů.
Poznámka: V databázích Oracle může mít název objektu minimální délku – 30 symbolů. V konkrétní databázi je tedy nutné vytvořit vlastní pravidla pro názvy objektů.
SQL je jazyk, který umožňuje spouštění dotazů v databázích přes DBMS. V konkrétním DBMS může mít jazyk SQL svůj vlastní dialekt.
DDL a DML – podjazyk SQL:
- Jazyk DDL slouží k vytváření a úpravě struktury databáze (mazání tabulek a odkazů);
- Jazyk DML umožňuje manipulaci s daty tabulky a jejími řádky. Slouží také pro výběr dat z tabulek, přidávání nových dat a také aktualizaci a mazání aktuálních dat.
V SQL je možné použít dva typy komentářů (jednořádkové a oddělované):
- jednořádkový komentář
a
/* komentář s oddělovači */
To je k teorii vše.
DDL – Data Definition Language
Podívejme se na ukázkovou tabulku s údaji o zaměstnancích zastoupených způsobem známým osobě, která není programátor.
| ID zaměstnance | Celé jméno | Datum narození | Pozice | Oddělení | |
| 1000 | Jan | 19.02.1955 | example@sqldat.com | CEO | Administrace |
| 1001 | Daniel | 03.12.1983 | example@sqldat.com | programátor | IT |
| 1002 | Mike | 07.06.1976 | example@sqldat.com | Účetní | Oddělení účtů |
| 1003 | Jordánsko | 17.04.1982 | example@sqldat.com | Senior programátor | IT |
V tomto případě mají sloupce následující názvy:ID zaměstnance, Celé jméno, Datum narození, E-mail, Pozice a Oddělení.
Každý sloupec této tabulky můžeme popsat jeho datovým typem:
- ID zaměstnance – celé číslo
- Celé jméno – řetězec
- Datum narození – datum
- E-mail – řetězec
- Pozice – řetězec
- Oddělení – řetězec
Typ sloupce je vlastnost, která určuje, jaký datový typ může každý sloupec uložit.
Pro začátek si musíte zapamatovat hlavní datové typy používané v MS SQL:
| Definice | Označení v MS SQL | Popis |
| Řetězec s proměnnou délkou | varchar(N) a nvarchar(N) | Pomocí čísla N můžeme určit maximální možnou délku řetězce pro konkrétní sloupec. Chceme-li například říci, že hodnota sloupce Celé jméno může obsahovat 30 znaků (maximálně), pak je nutné zadat typ nvarchar(30).
Rozdíl mezi varchar a nvarchar je ten, že varchar umožňuje ukládat řetězce ve formátu ASCII, zatímco nvarchar ukládá řetězce ve formátu Unicode, kde každý symbol zabírá 2 bajty. |
| Řetězec pevné délky | char(N) a nchar(N) | Tento typ se liší od řetězce s proměnnou délkou v následujícím:pokud je délka řetězce menší než N symbolů, pak se k délce N vpravo vždy přidávají mezery. V databázi tedy potřebuje přesně N symbolů, kde jeden symbol zabírá 1 bajt pro znak a 2 byty pro nchar. V mé praxi se tento typ příliš nepoužívá. Přesto, pokud to někdo používá, pak má tento typ obvykle formát char(1), tj. když je pole definováno 1 symbolem. |
| Celé číslo | int | Tento typ nám umožňuje používat ve sloupci pouze celé číslo (kladné i záporné). Poznámka:číselný rozsah pro tento typ je následující:od 2 147 483 648 do 2 147 483 647. Obvykle je to hlavní typ používaný k vyhledávání identifikátorů. |
| Číslo s plovoucí desetinnou čárkou | plovoucí | Čísla s desetinnou čárkou. |
| Datum | datum | Slouží k uložení pouze data (datum, měsíc a rok) ve sloupci. Například 15.02.2014. Tento typ lze použít pro následující sloupce:datum příjmu, datum narození atd., když potřebujete zadat pouze datum nebo když čas pro nás není důležitý a můžeme jej vypustit. |
| Čas | čas | Tento typ můžete použít, pokud je nutné uložit čas:hodiny, minuty, sekundy a milisekundy. Máte například 17:38:31,3231603 nebo potřebujete přidat čas odletu letu. |
| Datum a čas | datum a čas | Tento typ umožňuje uživatelům uložit datum i čas. Například máte událost 02/15/2014 17:38:31.323. |
| Indikátor | bit | Tento typ můžete použít k uložení hodnot, jako je ‚Ano‘/‘Ne‘, kde ‚Ano‘ je 1 a ‚Ne‘ je 0. |
Kromě toho není nutné specifikovat hodnotu pole, pokud to není zakázáno. V tomto případě můžete použít hodnotu NULL.
Pro provedení příkladů vytvoříme testovací databázi s názvem ‚Test‘.
Chcete-li vytvořit jednoduchou databázi bez dalších vlastností, spusťte následující příkaz:
Test CREATE DATABASE
Chcete-li odstranit databázi, spusťte tento příkaz:
Test DROP DATABASE
Pro přepnutí do naší databáze použijte příkaz:
POUŽÍVEJTE Test
Případně můžete vybrat Testovat databázi z rozbalovací nabídky v oblasti nabídky SSMS.
Nyní můžeme vytvořit tabulku v naší databázi pomocí popisů, mezer a symbolů azbuky:
VYTVOŘIT TABULKU [Zaměstnanci]( [ID zaměstnance] int, [Celé jméno] nvarchar(30), [Datum narození], [E-mail] nvarchar(30), [Pozice] nvarchar(30), [Oddělení] nvarchar( 30) )
V tomto případě musíme jména zalomit do hranatých závorek […].
Přesto je lepší specifikovat všechny názvy objektů v latině a nepoužívat v názvech mezery. V tomto případě každé slovo začíná velkým písmenem. Například pro pole „EmployeeID“ bychom mohli zadat název PersonnelNumber. V názvu můžete také použít čísla, například PhoneNumber1.
Poznámka: V některých DBMS je vhodnější použít následující formát názvu „PHONE_NUMBER“. Tento formát můžete vidět například v databázích ORACLE. Kromě toho by se název pole neměl shodovat s klíčovými slovy používanými v DBMS.
Z tohoto důvodu můžete zapomenout na syntaxi hranatých závorek a můžete smazat tabulku Zaměstnanci:
DROP TABLE [Zaměstnanci]
Můžete například pojmenovat tabulku se zaměstnanci jako „Zaměstnanci“ a pro její pole nastavit následující názvy:
- ID
- Jméno
- Narozeniny
- Pozice
- Oddělení
Velmi často používáme pro pole identifikátoru ‘ID’.
Nyní vytvoříme tabulku:
VYTVOŘIT TABULKU Zaměstnanci (ID int, jméno nvarchar(30), datum narození, e-mail nvarchar(30), pozice nvarchar(30), oddělení nvarchar(30)
Chcete-li nastavit povinné sloupce, můžete použít možnost NOT NULL.
Pro aktuální tabulku můžete předefinovat pole pomocí následujících příkazů:
-- Pole ID updateALTER TABLE Zaměstnanci ALTER COLUMN ID int NOT NULL-- Pole jména updateALTER TABLE Zaměstnanci ALTER COLUMN Name nvarchar(30) NOT NULL
Poznámka: Obecný koncept jazyka SQL pro většinu DBMS je stejný (z vlastní zkušenosti). Rozdíl mezi DDL v různých DBMS je především v datových typech (mohou se lišit nejen svými názvy, ale také specifickou implementací). Konkrétní implementace SQL (příkazy) jsou navíc stejné, ale mohou existovat drobné rozdíly v dialektu. Znáte-li základy SQL, můžete snadno přecházet z jednoho DBMS na druhý. V tomto případě budete muset pouze porozumět specifikům implementace příkazů v novém DBMS.
Porovnejte stejné příkazy v ORACLE DBMS:
-- vytvořit tabulku CREATE TABLE Employees( ID int, -- V ORACLE je typ int hodnota pro číslo (38) Jméno nvarchar2(30), -- v ORACLE nvarchar2 je identický s nvarchar v MS SQL Datum narození, Email nvarchar2(30), Pozice nvarchar2(30), Oddělení nvarchar2(30) ); -- Aktualizace pole ID a jména (zde používáme MODIFY(…) místo ALTER COLUMNALTER TABLE Zaměstnanci MODIFY(ID int NOT NULL,Name nvarchar2(30) NOT NULL); -- přidejte PK (v tomto případě je konstrukce stejná jako v MS SQL) ALTER TABLE Zaměstnanci ADD CONSTRAINT PK_Employees PRIMÁRNÍ KLÍČ(ID);
ORACLE se liší implementací typu varchar2. Jeho formát závisí na nastavení DB a text můžete uložit např. v UTF-8. Kromě toho můžete zadat délku pole jak v bajtech, tak v symbolech. Chcete-li to provést, musíte použít hodnoty BYTE a CHAR následované polem délky. Například:
NAME varchar2(30 BYTE) – kapacita pole se rovná 30 bajtům NAME varchar2(30 CHAR) – kapacita pole se rovná 30 symbolům
Hodnota (BYTE nebo CHAR), která se má použít ve výchozím nastavení, když pouze uvedete varchar2(30) v ORACLE, bude záviset na nastavení databáze. Často se můžete snadno splést. Doporučuji tedy výslovně specifikovat CHAR, když používáte typ varchar2 (například s UTF-8) v ORACLE (protože je pohodlnější číst délku řetězce v symbolech).
Pokud jsou však v tomto případě v tabulce nějaká data, je pro úspěšné provedení příkazů nutné vyplnit pole ID a Název ve všech řádcích tabulky.
Ukážu to na konkrétním příkladu.
Vložme data do polí ID, Pozice a Oddělení pomocí následujícího skriptu:
VLOŽTE HODNOTY zaměstnanců(ID,Pozice,Oddělení) (1000,'CEO,N'Administration'), (1001,N'Programmer',N'IT'), (1002,N'Accountant',N'Accounts oddělení'), (1003,N'Senior Programmer',N'IT')
V tomto případě příkaz INSERT také vrátí chybu. K tomu dochází, protože jsme nezadali hodnotu pro povinné pole Název.
Pokud by v původní tabulce byla nějaká data, pak by fungoval příkaz „ALTER TABLE Zaměstnanci ALTER ID COLUMN int NOT NULL“, zatímco příkaz „ALTER TABLE Zaměstnanci ALTER COLUMN Name int NOT NULL“ by vrátil chybu, kterou má pole Name hodnoty NULL.
Přidejme hodnoty do pole Název:
VLOŽTE HODNOTY zaměstnanců(ID,Pozice,Oddělení,Jméno) (1000,N'CEO',N'Administration',N'John'), (1001,N'Programmer',N'IT',N'Daniel '), (1002,N'Accountant',N'Accounts dept',N'Mike'), (1003,N'Senior Programmer',N'IT',N'Jordan')
Kromě toho můžete při vytváření nové tabulky pomocí příkazu CREATE TABLE použít NOT NULL.
Nejprve smažeme tabulku:
DOP TABLE Zaměstnanci
Nyní vytvoříme tabulku s povinnými poli ID a Name:
VYTVOŘIT TABULKU Zaměstnanci (ID int NOT NULL, jméno nvarchar(30) NOT NULL, datum narození, e-mail nvarchar(30), pozice nvarchar(30), oddělení nvarchar(30)
Můžete také zadat hodnotu NULL za názvem sloupce, který znamená, že hodnoty NULL jsou povoleny. Toto není povinné, protože tato možnost je nastavena ve výchozím nastavení.
Pokud potřebujete, aby aktuální sloupec nebyl povinný, použijte následující syntaxi:
ALTER TABLE Zaměstnanci ALTER COLUMN Název nvarchar(30) NULL
Případně můžete použít tento příkaz:
ALTER TABLE Zaměstnanci ALTER COLUMN Název nvarchar(30)
Navíc tímto příkazem můžeme buď upravit typ pole na jiný kompatibilní, nebo změnit jeho délku. Rozšiřme například pole Název na 50 symbolů:
ALTER TABLE Zaměstnanci ALTER COLUMN Název nvarchar(50)
Primární klíč
Při vytváření tabulky musíte pro každý řádek zadat jedinečný sloupec nebo sadu sloupců. Pomocí této jedinečné hodnoty můžete identifikovat záznam. Tato hodnota se nazývá primární klíč. Sloupec ID (který obsahuje «osobní číslo zaměstnance» – v našem případě je to jedinečná hodnota pro každého zaměstnance a nelze ji duplikovat) může být primárním klíčem pro naši tabulku Zaměstnanci.
K vytvoření primárního klíče pro tabulku můžete použít následující příkaz:
ALTER TABLE Zaměstnanci ADD CONSTRAINT PK_Employees PRIMÁRNÍ KLÍČ (ID)
‚PK_Employees‘ je název omezení definující primární klíč. Název primárního klíče se obvykle skládá z předpony ‚PK_‘ a názvu tabulky.
Pokud primární klíč obsahuje několik polí, musíte tato pole uvést v závorkách oddělených čárkou:
ALTER TABLE název_tabulky ADD CONSTRAINT název_omezení PRIMÁRNÍ KLÍČ(pole1,pole2,…)
Mějte na paměti, že v MS SQL by všechna pole primárního klíče neměla být NULL.
Kromě toho můžete při vytváření tabulky definovat primární klíč. Smažeme tabulku:
DOP TABLE Zaměstnanci
Potom vytvořte tabulku pomocí následující syntaxe:
VYTVOŘIT TABULKU Zaměstnanci (ID int NOT NULL, jméno nvarchar(30) NOT NULL, datum narození, e-mail nvarchar(30), pozice nvarchar(30), oddělení nvarchar(30), OMEZENÍ PK_Employees PRIMÁRNÍ KLÍČ(ID) – popište PK po všech polích jako omezení )
Přidejte data do tabulky:
VLOŽTE HODNOTY zaměstnanců(ID,Pozice,Oddělení,Jméno) (1000,N'CEO',N'Administration',N'John'), (1001,N'Programmer',N'IT',N'Daniel '), (1002,N'Accountant',N'Accounts dept',N'Mike'), (1003,N'Senior programmer',N'IT',N'Jordan')
Ve skutečnosti nemusíte zadávat název omezení. V tomto případě bude přiřazen název systému. Například «PK__Employee__3214EC278DA42077»:
VYTVOŘIT TABULKU Zaměstnanci (ID int NOT NULL, Jméno nvarchar(30) NOT NULL, Datum narození, E-mail nvarchar(30), Pozice nvarchar(30), Oddělení nvarchar(30), PRIMÁRNÍ KLÍČ(ID) )
nebo
VYTVOŘIT TABULKU Zaměstnanci (ID int NOT NULL PRIMÁRNÍ KLÍČ, jméno nvarchar(30) NOT NULL, datum narození, e-mail nvarchar(30), pozice nvarchar(30), oddělení nvarchar(30)
Osobně bych doporučoval u trvalých tabulek výslovně uvést název omezení, protože je snazší s explicitně definovanou a jasnou hodnotou v budoucnu pracovat nebo ji smazat. Například:
ALTER TABLE Zaměstnanci DROP CONSTRAINT PK_Employees
Přesto je pohodlnější použít tuto krátkou syntaxi bez omezení jmen při vytváření dočasných databázových tabulek (název dočasné tabulky začíná # nebo ##.
Shrnutí:
Již jsme analyzovali následující příkazy:
- VYTVOŘIT TABULKU název_tabulky (výpis polí a jejich typů a omezení) – slouží k vytvoření nové tabulky v aktuální databázi;
- DOP TABLE název_tabulky – slouží k vymazání tabulky z aktuální databáze;
- ALTER TABLE table_name ALTER COLUMN název_sloupce … – slouží k aktualizaci typu sloupce nebo k úpravě jeho nastavení (např. když potřebujete nastavit hodnotu NULL nebo NOT NULL);
- ALTER TABLE table_name ADD CONSTRAINT constraint_name PRIMÁRNÍ KLÍČ (pole1, pole2,…) – používá se k přidání primárního klíče do aktuální tabulky;
- ALTER TABLE table_name DROP CONSTRAINT constraint_name – používá se k odstranění omezení z tabulky.
Dočasné stoly
Abstrakce z MSDN. V MS SQL Server existují dva typy dočasných tabulek:lokální (#) a globální (##). Místní dočasné tabulky jsou viditelné pouze pro jejich tvůrce před odpojením instance SQL Server. Jsou automaticky odstraněny po odpojení uživatele od instance SQL Server. Globální dočasné tabulky jsou viditelné všem uživatelům během všech relací připojení po vytvoření těchto tabulek. Tyto tabulky jsou odstraněny, jakmile jsou uživatelé odpojeni od instance SQL Server.
V systémové databázi tempdb se vytvářejí dočasné tabulky, což znamená, že nezahlcujeme hlavní databázi. Navíc je můžete odstranit pomocí příkazu DROP TABLE. Velmi často se používají místní (#) dočasné tabulky.
Chcete-li vytvořit dočasnou tabulku, můžete použít příkaz CREATE TABLE:
VYTVOŘIT TABULKU #Temp( ID int, Název nvarchar(30) )
Dočasnou tabulku můžete odstranit příkazem DROP TABLE:
DROP TABLE #Temp
Kromě toho můžete vytvořit dočasnou tabulku a vyplnit ji daty pomocí syntaxe SELECT … INTO:
VYBERTE ID,Jméno DO #Temp FROM Zaměstnanců
Poznámka: V různých DBMS se implementace dočasných databází může lišit. Například v ORACLE a Firebird DBMS by měla být struktura dočasných tabulek definována předem příkazem CREATE GLOBAL TEMPORARY TABLE. Také je třeba určit způsob ukládání dat. Poté ji uživatel vidí mezi běžnými tabulkami a pracuje s ní jako s konvenční tabulkou.
Normalizace databáze:rozdělení na podtabulky (referenční tabulky) a definování vztahů mezi tabulkami
Naše současná tabulka Zaměstnanci má nevýhodu:uživatel může zadat libovolný text do polí Pozice a Oddělení, což může vracet chyby, protože pro jednoho zaměstnance může zadat „IT“ jako oddělení, zatímco pro jiného zaměstnance může zadat „IT“. oddělení". V důsledku toho nebude jasné, co tím měl uživatel na mysli, zda tito zaměstnanci pracují pro stejné oddělení nebo zda je tam překlep a existují 2 různá oddělení. Navíc v tomto případě nebudeme schopni správně seskupit data pro sestavu, kde potřebujeme zobrazit počet zaměstnanců pro každé oddělení.
Další nevýhodou je objem úložiště a jeho duplikace, tj. pro každého zaměstnance je potřeba zadat celý název oddělení, což vyžaduje místo v databázích pro uložení každého symbolu názvu oddělení.
Třetí nevýhodou je složitost aktualizace dat v terénu, když potřebujete upravit jméno jakékoli pozice – od programátora po junior programátora. V tomto případě budete muset přidat nová data do každého řádku tabulky, kde je pozice „Programátor“.
Aby k takovým situacím nedocházelo, doporučuje se použít normalizaci databáze – rozdělení na podtabulky – referenční tabulky.
Vytvořme 2 referenční tabulky „Pozice“ a „Oddělení“:
CREATE TABLE Pozice( ID int IDENTITY(1,1) NOT NULL OMEZENÍ PK_Positions PRIMÁRNÍ KLÍČ, Název nvarchar(30) NOT NULL ) CREATE TABLE Oddělení( ID int IDENTITY(1,1) NOT NULL OMEZENÍ PK_Oddělení PRIMÁRNÍ nvarchar(30) NOT NULL )
Všimněte si, že zde jsme použili novou vlastnost IDENTITY. To znamená, že údaje ve sloupci ID budou automaticky vypsány počínaje 1. Při přidávání nových záznamů tedy budou hodnoty 1, 2, 3 atd. přiřazovány postupně. Obvykle se tato pole nazývají autoinkrementační pole. Pouze jedno pole s vlastností IDENTITY může být definováno jako primární klíč v tabulce. Obvykle, ale ne vždy, je takové pole primárním klíčem tabulky.
Poznámka: V různých DBMS se může implementace polí s inkrementátorem lišit. Například v MySQL je takové pole definováno vlastností AUTO_INCREMENT. V ORACLE a Firebirdu můžete tuto funkci emulovat pomocí sekvencí (SEQUENCE). Ale pokud vím, vlastnost GENERATED AS IDENTITY byla přidána do ORACLE.
Vyplňte tyto tabulky automaticky na základě aktuálních údajů v polích Pozice a Oddělení tabulky Zaměstnanci:
-- vyplňte pole Název tabulky Pozice jedinečnými hodnotami z pole Pozice tabulky Zaměstnanci INSERT Pozice(Jméno) VYBERTE DISTINCT Pozice OD Zaměstnanci WHERE Pozice NENÍ NULL – vynechejte záznamy, kde pozice není specifikovánaPro tabulku Oddělení musíte provést stejné kroky:
INSERT Departments (Name) SELECT DISTINCT Department FROM Zaměstnanci, KDE oddělení NENÍ NULLNyní, když otevřeme tabulky Pozice a Oddělení, uvidíme v poli ID očíslovaný seznam hodnot:
VYBRAT * Z pozic
| ID | Jméno |
| 1 | Účetní |
| 2 | CEO |
| 3 | Programátor |
| 4 | Senior programátor |
VYBRAT * Z oddělení
| ID | Jméno |
| 1 | Administrace |
| 2 | Oddělení účtů |
| 3 | IT |
Tyto tabulky budou referenčními tabulkami pro definování pozic a oddělení. Nyní se podíváme na identifikátory pozic a oddělení. Nejprve vytvořte nová pole v tabulce Zaměstnanci pro uložení identifikátorů:
-- přidejte pole pro pozici ID ALTER TABLE Zaměstnanci ADD PositionID int -- přidejte pole pro ID oddělení ALTER TABLE Zaměstnanci ADD DepartmentID int
Typ referenčních polí by měl být stejný jako v referenčních tabulkách, v tomto případě je to int.
Kromě toho můžete přidat několik polí pomocí jednoho příkazu uvedením polí oddělených čárkami:
ALTER TABLE Zaměstnanci PŘIDAT PositionID int, DepartmentID int
Nyní do těchto polí přidáme omezení reference (FOREIGN KEY), aby uživatel nemohl přidávat žádné hodnoty, které nejsou hodnotami ID referenčních tabulek.
ALTER TABLE Zaměstnanci PŘIDAT OMEZENÍ FK_Employees_PositionID CIZÍ KLÍČ(ID pozice) REFERENCE Pozice(ID)
Stejné kroky by měly být provedeny pro druhé pole:
ALTER TABLE Zaměstnanci PŘIDAT OMEZENÍ FK_Employees_DepartmentID CIZÍ KLÍČ (ID oddělení) REFERENCE Oddělení (ID)
Nyní mohou uživatelé do těchto polí vkládat pouze hodnoty ID z odpovídající referenční tabulky. Aby tedy uživatel mohl použít nové oddělení nebo pozici, musí přidat nový záznam do odpovídající referenční tabulky. Vzhledem k tomu, že pozice a oddělení jsou uloženy v referenčních tabulkách v jedné kopii, pak pro změnu jejich názvu je potřeba jej změnit pouze v referenční tabulce.
Název referenčního omezení je obvykle složený. Skládá se z prefixu «FK» následovaného názvem tabulky a názvem pole, které odkazuje na identifikátor referenční tabulky.
Identifikátor (ID) je obvykle interní hodnota používaná pouze pro odkazy. Nezáleží na tom, jakou má hodnotu. Proto se nesnažte zbavit se mezer v posloupnosti hodnot, které se objevují při práci s tabulkou, například když mažete záznamy z referenční tabulky.
V některých případech je možné vytvořit referenci z několika polí:
ALTER TABLE table ADD CONSTRAINT název_podmínky CIZÍ KLÍČ(pole1,pole2,…) REFERENCE referenční tabulka(pole1,pole2,…)
V tomto případě je primární klíč reprezentován sadou několika polí (pole1, pole2, …) v tabulce „reference_table“.
Nyní aktualizujme pole PositionID a DepartmentID hodnotami ID z referenčních tabulek.
K tomu použijeme příkaz UPDATE:
UPDATE e SET PositionID=(SELECT ID FROM Positions WHERE Name=e.Position), DepartmentID=(SELECT ID FROM Departments WHERE Name=e.Department) OD zaměstnanců e
Spusťte následující dotaz:
VYBRAT * ZE zaměstnanců
| ID | Jméno | Narozeniny | Pozice | Oddělení | ID pozice | ID oddělení | |
| 1000 | Jan | NULL | NULL | CEO | Administrace | 2 | 1 |
| 1001 | Daniel | NULL | NULL | Programátor | IT | 3 | 3 |
| 1002 | Mike | NULL | NULL | Účetní | Oddělení účtů | 1 | 2 |
| 1003 | Jordánsko | NULL | NULL | Senior programátor | IT | 4 | 3 |
Jak vidíte, pole PositionID a DepartmentID odpovídají pozicím a oddělením. Můžete tedy odstranit pole Pozice a Oddělení v tabulce Zaměstnanci provedením následujícího příkazu:
ZMĚNIT TABULKU Zaměstnanci PUSTIT SLOUPEK Pozice,Oddělení
Nyní spusťte tento příkaz:
VYBRAT * ZE zaměstnanců
| ID | Jméno | Narozeniny | ID pozice | ID oddělení | |
| 1000 | Jan | NULL | NULL | 2 | 1 |
| 1001 | Daniel | NULL | NULL | 3 | 3 |
| 1002 | Mike | NULL | NULL | 1 | 2 |
| 1003 | Jordánsko | NULL | NULL | 4 | 3 |
Therefore, we do not have information overload. We can define the names of positions and departments by their identifiers using the values in the reference tables:
SELECT e.ID,e.Name,p.Name PositionName,d.Name DepartmentName FROM Employees e LEFT JOIN Departments d ON d.ID=e.DepartmentID LEFT JOIN Positions p ON p.ID=e.PositionID
| ID | Name | PositionName | DepartmentName |
| 1000 | John | CEO | Administration |
| 1001 | Daniel | Programmer | IT |
| 1002 | Mike | Accountant | Accounts dept |
| 1003 | Jordan | Senior programmer | IT |
In the object inspector, we can see all the objects created for this table. Here we can also manipulate these objects in different ways, for example, rename or delete the objects.
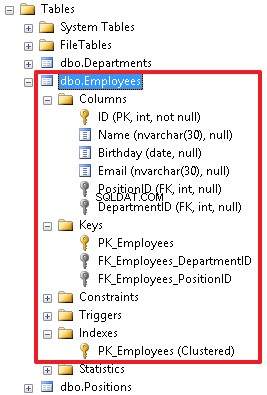
In addition, it should be noted that it is possible to create a recursive reference.
Let’s consider this particular example.
Let’s add the ManagerID field to the table with employees. This new field will define an employee to whom this employee is subordinated.
ALTER TABLE Employees ADD ManagerID int
This field permits the NULL value as well.
Now, we will create a FOREIGN KEY for the Employees table:
ALTER TABLE Employees ADD CONSTRAINT FK_Employees_ManagerID FOREIGN KEY (ManagerID) REFERENCES Employees(ID)
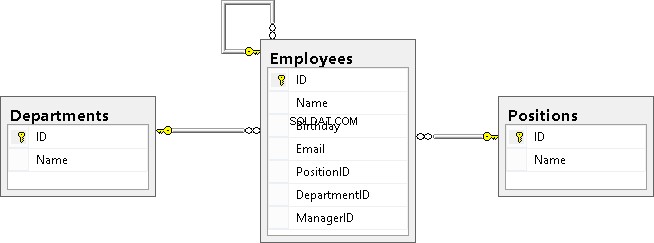
Then create a diagram and check how our tables are linked:
As you can see, the Employees table is linked with the Positions and Departments tables and is a recursive reference.
Finally, I would like to note that reference keys can include additional properties such as ON DELETE CASCADE and ON UPDATE CASCADE. They define the behavior when deleting or updating a record that is referenced from the reference table. If these properties are not specified, then we cannot change the ID of the record in the reference table referenced from the other table. Also, we cannot delete this record from the reference table until we remove all the rows that refer to this record or update the references to another value in these rows.
For example, let’s re-create the table and specify the ON DELETE CASCADE property for FK_Employees_DepartmentID:
DROP TABLE Employees CREATE TABLE Employees( ID int NOT NULL, Name nvarchar(30), Birthday date, Email nvarchar(30), PositionID int, DepartmentID int, ManagerID int, CONSTRAINT PK_Employees PRIMARY KEY (ID), CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY(DepartmentID) REFERENCES Departments(ID) ON DELETE CASCADE, CONSTRAINT FK_Employees_PositionID FOREIGN KEY(PositionID) REFERENCES Positions(ID), CONSTRAINT FK_Employees_ManagerID FOREIGN KEY (ManagerID) REFERENCES Employees(ID) ) INSERT Employees (ID,Name,Birthday,PositionID,DepartmentID,ManagerID)VALUES (1000,N'John','19550219',2,1,NULL), (1001,N'Daniel','19831203',3,3,1003), (1002,N'Mike','19760607',1,2,1000), (1003,N'Jordan','19820417',4,3,1000)
Let’s delete the department with identifier ‘3’ from the Departments table:
DELETE Departments WHERE ID=3
Let’s view the data in table Employees:
SELECT * FROM Employees
| ID | Name | Birthday | PositionID | DepartmentID | ManagerID | |
| 1000 | John | 1955-02-19 | NULL | 2 | 1 | NULL |
| 1002 | Mike | 1976-06-07 | NULL | 1 | 2 | 1000 |
As you can see, data of Department ‘3’ has been deleted from the Employees table as well.
The ON UPDATE CASCADE property has similar behavior, but it works when updating the ID value in the reference table. For example, if we change the position ID in the Positions reference table, then DepartmentID in the Employees table will receive a new value, which we have specified in the reference table. But in this case this cannot be demonstrated, because the ID column in the Departments table has the IDENTITY property, which will not allow us to execute the following query (change the department identifier from 3 to 30):
UPDATE Departments SET ID=30 WHERE ID=3
The main point is to understand the essence of these 2 options ON DELETE CASCADE and ON UPDATE CASCADE. I apply these options very rarely, and I recommend that you think carefully before you specify them in the reference constraint, because If an entry is accidentally deleted from the reference table, this can lead to big problems and create a chain reaction.
Let’s restore department ‘3’:
-- we permit to add or modify the IDENTITY value SET IDENTITY_INSERT Departments ONINSERT Departments(ID,Name) VALUES(3,N'IT') -- we prohibit to add or modify the IDENTITY value SET IDENTITY_INSERT Departments OFF
We completely clear the Employees table using the TRUNCATE TABLE command:
TRUNCATE TABLE Employees
Again, we will add data using the INSERT command:
INSERT Employees (ID,Name,Birthday,PositionID,DepartmentID,ManagerID)VALUES (1000,N'John','19550219',2,1,NULL), (1001,N'Daniel','19831203',3,3,1003), (1002,N'Mike','19760607',1,2,1000), (1003,N'Jordan','19820417',4,3,1000)
Summary:
We have described the following DDL commands:
• Adding the IDENTITY property to a field allows to make this field automatically populated (count field) for the table;
• ALTER TABLE table_name ADD field_list with_features – allows you to add new fields to the table;
• ALTER TABLE table_name DROP COLUMN field_list – allows you to delete fields from the table;
• ALTER TABLE table_name ADD CONSTRAINT constraint_name FOREIGN KEY (fields) REFERENCES reference_table – allows you to determine the relationship between a table and a reference table.
Other constraints – UNIQUE, DEFAULT, CHECK
Using the UNIQUE constraint, you can say that the values for each row in a given field or in a set of fields must be unique. In the case of the Employees table, we can apply this restriction to the Email field. Let’s first fill the Email values, if they are not yet defined:
UPDATE Employees SET Email='example@sqldat.com' WHERE ID=1000 UPDATE Employees SET Email='example@sqldat.com' WHERE ID=1001 UPDATE Employees SET Email='example@sqldat.com' WHERE ID=1002 UPDATE Employees SET Email='example@sqldat.com' WHERE ID=1003
Now, you can impose the UNIQUE constraint on this field:
ALTER TABLE Employees ADD CONSTRAINT UQ_Employees_Email UNIQUE(Email)
Thus, a user will not be able to enter the same email for several employees.
The UNIQUE constraint has the following structure:the «UQ» prefix followed by the table name and a field name (after the underscore), to which the restriction applies.
When you need to add the UNIQUE constraint for the set of fields, we will list them separated by commas:
ALTER TABLE table_name ADD CONSTRAINT constraint_name UNIQUE(field1,field2,…)
By adding a DEFAULT constraint to a field, we can specify a default value that will be inserted if, when inserting a new record, this field is not listed in the list of fields in the INSERT command. You can set this restriction when creating a table.
Let’s add the HireDate field to the Employees table and set the current date as a default value:
ALTER TABLE Employees ADD HireDate date NOT NULL DEFAULT SYSDATETIME()
If the HireDate column already exists, then we can use the following syntax:
ALTER TABLE Employees ADD DEFAULT SYSDATETIME() FOR HireDate
To specify the default value, execute the following command:
ALTER TABLE Employees ADD CONSTRAINT DF_Employees_HireDate DEFAULT SYSDATETIME() FOR HireDate
As there was no such column before, then when adding it, the current date will be inserted into each entry of the HireDate field.
When creating a new record, the current date will be also automatically added, unless we explicitly specify it, i.e. specify in the list of columns. Let’s demonstrate this with an example, where we will not specify the HireDate field in the list of the values added:
INSERT Employees(ID,Name,Email)VALUES(1004,N'Ostin',' example@sqldat.com')
To check the result, run the command:
SELECT * FROM Employees
| ID | Name | Birthday | PositionID | DepartmentID | ManagerID | HireDate | |
| 1000 | John | 1955-02-19 | example@sqldat.com | 2 | 1 | NULL | 2015-04-08 |
| 1001 | Daniel | 1983-12-03 | example@sqldat.com | 3 | 4 | 1003 | 2015-04-08 |
| 1002 | Mike | 1976-06-07 | example@sqldat.com | 1 | 2 | 1000 | 2015-04-08 |
| 1003 | Jordan | 1982-04-17 | example@sqldat.com | 4 | 3 | 1000 | 2015-04-08 |
| 1004 | Ostin | NULL | example@sqldat.com | NULL | NULL | NULL | 2015-04-08 |
The CHECK constraint is used when it is necessary to check the values being inserted in the fields. For example, let’s impose this constraint on the identification number field, which is an employee ID (ID). Let’s limit the identification numbers to be in the range from 1000 to 1999:
ALTER TABLE Employees ADD CONSTRAINT CK_Employees_ID CHECK(ID BETWEEN 1000 AND 1999)
The constraint name is usually as follows:the «CK_» prefix first followed by the table name and a field name, for which constraint is imposed.
Let’s add an invalid record to check if the constraint is working properly (we will get the corresponding error):
INSERT Employees(ID,Email) VALUES(2000,'example@sqldat.com')
Now, let’s change the value being inserted to 1500 and make sure that the record is inserted:
INSERT Employees(ID,Email) VALUES(1500,'example@sqldat.com')
We can also create UNIQUE and CHECK constraints without specifying a name:
ALTER TABLE Employees ADD UNIQUE(Email) ALTER TABLE Employees ADD CHECK(ID BETWEEN 1000 AND 1999)
Still, this is a bad practice and it is desirable to explicitly specify the constraint name so that users can see what each object defines:
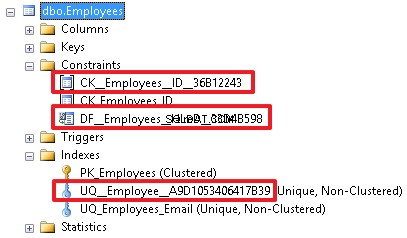
A good name gives us more information about the constraint. And, accordingly, all these restrictions can be specified when creating a table, if it does not exist yet.
Let’s delete the table:
DROP TABLE Employees
Let’s re-create the table with all the specified constraints using the CREATE TABLE command:
CREATE TABLE Employees( ID int NOT NULL, Name nvarchar(30), Birthday date, Email nvarchar(30), PositionID int, DepartmentID int, HireDate date NOT NULL DEFAULT SYSDATETIME(), -- I have an exception for DEFAULT CONSTRAINT PK_Employees PRIMARY KEY (ID), CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY(DepartmentID) REFERENCES Departments(ID), CONSTRAINT FK_Employees_PositionID FOREIGN KEY(PositionID) REFERENCES Positions(ID), CONSTRAINT UQ_Employees_Email UNIQUE (Email), CONSTRAINT CK_Employees_ID CHECK (ID BETWEEN 1000 AND 1999) )
Finally, let’s insert our employees in the table:
INSERT Employees (ID,Name,Birthday,Email,PositionID,DepartmentID)VALUES (1000,N'John','19550219',' example@sqldat.com ',2,1), (1001,N'Daniel','19831203',' example@sqldat.com ',3,3), (1002,N'Mike','19760607',' example@sqldat.com ',1,2), (1003,N'Jordan','19820417',' example@sqldat.com',4,3)
Some words about the indexes created with the PRIMARY KEY and UNIQUE constraints
When creating the PRIMARY KEY and UNIQUE constraints, the indexes with the same names (PK_Employees and UQ_Employees_Email) are automatically created. By default, the index for the primary key is defined as CLUSTERED, and for other indexes, it is set as NONCLUSTERED.
It should be noted that the clustered index is not used in all DBMSs. A table can have only one clustered (CLUSTERED) index. It means that the records of the table will be ordered by this index. In addition, we can say that this index has direct access to all the data in the table. This is the main index of the table. A clustered index can help with the optimization of queries. If we want to set the clustered index for another index, then when creating the primary key, we should specify the NONCLUSTERED property:
ALTER TABLE table_name ADD CONSTRAINT constraint_name PRIMARY KEY NONCLUSTERED(field1,field2,…)
Let’s specify the PK_Employees constraint index as nonclustered, while the UQ_Employees_Email constraint index – as clustered. At first, delete these constraints:
ALTER TABLE Employees DROP CONSTRAINT PK_Employees ALTER TABLE Employees DROP CONSTRAINT UQ_Employees_Email
Now, create them with the CLUSTERED and NONCLUSTERED indexes:
ALTER TABLE Employees ADD CONSTRAINT PK_Employees PRIMARY KEY NONCLUSTERED (ID) ALTER TABLE Employees ADD CONSTRAINT UQ_Employees_Email UNIQUE CLUSTERED (Email)
Once it is done, you can see that records have been sorted by the UQ_Employees_Email clustered index:
SELECT * FROM Employees
| ID | Name | Birthday | PositionID | DepartmentID | HireDate | |
| 1003 | Jordan | 1982-04-17 | example@sqldat.com | 4 | 3 | 2015-04-08 |
| 1000 | John | 1955-02-19 | example@sqldat.com | 2 | 1 | 2015-04-08 |
| 1001 | Daniel | 1983-12-03 | example@sqldat.com | 3 | 3 | 2015-04-08 |
| 1002 | Mike | 1976-06-07 | example@sqldat.com | 1 | 2 | 2015-04-08 |
For reference tables, it is better when a clustered index is built on the primary key, as in queries we often refer to the identifier of the reference table to obtain a name (Position, Department). The clustered index has direct access to the rows of the table, and hence it follows that we can get the value of any column without additional overhead.
It is recommended that the clustered index should be applied to the fields that you use for selection very often.
Sometimes in tables, a key is created by the stubbed field. In this case, it is a good idea to specify the CLUSTERED index for an appropriate index and specify the NONCLUSTERED index when creating the stubbed field.
Summary:
We have analyzed all the constraint types that are created with the «ALTER TABLE table_name ADD CONSTRAINT constraint_name …» command:
- PRIMARY KEY;
- FOREIGN KEY controls links and data referential integrity;
- UNIQUE – serves for setting a unique value;
- CHECK – allows monitoring the correctness of added data;
- DEFAULT – allows specifying a default value;
- The «ALTER TABLE table_name DROP CONSTRAINT constraint_name» command allows deleting all the constraints.
Additionally, we have reviewed the indexes:CLUSTERED and UNCLUSTERED.
Creating unique indexes
I am going to analyze indexes created not for the PRIMARY KEY or UNIQUE constraints.
It is possible to set indexes by a field or a set of fields using the following command:
CREATE INDEX IDX_Employees_Name ON Employees(Name)
Also, you can add the CLUSTERED, NONCLUSTERED, and UNIQUE properties as well as specify the order:ASC (by default) or DESC.
CREATE UNIQUE NONCLUSTERED INDEX UQ_Employees_EmailDesc ON Employees(Email DESC)
When creating the nonclustered index, the NONCLUSTERED property can be dropped as it is set by default.
To delete the index, use the command:
DROP INDEX IDX_Employees_Name ON Employees
You can create simple indexes and constraints with the CREATE TABLE command.
At first, delete the table:
DROP TABLE Employees
Then, create the table with all the constraints and indexes using the CREATE TABLE command:
CREATE TABLE Employees( ID int NOT NULL, Name nvarchar(30), Birthday date, Email nvarchar(30), PositionID int, DepartmentID int, HireDate date NOT NULL CONSTRAINT DF_Employees_HireDate DEFAULT SYSDATETIME(), ManagerID int, CONSTRAINT PK_Employees PRIMARY KEY (ID), CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY(DepartmentID) REFERENCES Departments(ID), CONSTRAINT FK_Employees_PositionID FOREIGN KEY(PositionID) REFERENCES Positions(ID), CONSTRAINT FK_Employees_ManagerID FOREIGN KEY (ManagerID) REFERENCES Employees(ID), CONSTRAINT UQ_Employees_Email UNIQUE(Email), CONSTRAINT CK_Employees_ID CHECK(ID BETWEEN 1000 AND 1999), INDEX IDX_Employees_Name(Name) )
Finally, add information about our employees:
INSERT Employees (ID,Name,Birthday,Email,PositionID,DepartmentID,ManagerID)VALUES (1000,N'John','19550219',' example@sqldat.com ',2,1,NULL), (1001,N'Daniel','19831203',' example@sqldat.com ',3,3,1003), (1002,N'Mike','19760607',' example@sqldat.com ',1,2,1000), (1003,N'Jordan','19820417',' example@sqldat.com',4,3,1000)
Keep in mind that it is possible to add values with the INCLUDE command in the nonclustered index. Thus, in this case, the INCLUDE index is a clustered index where the necessary values are linked to the index, rather than to the table. These indexes can improve the SELECT query performance if there are all the required fields in the index. However, it may lead to increasing the index size, as field values are duplicated in the index.
Abstract from MSDN. Here is how the syntax of the command to create indexes looks:
CREATE [ UNIQUE ] [ CLUSTERED | NONCLUSTERED ] INDEX index_name ON
Summary
Indexes can simultaneously improve the SELECT query performance and lead to poor speed for modifying table data. This happens, as you need to rebuild all the indexes for a particular table after each system modification.
The strategy on creating indexes may depend on many factors such as frequency of data modifications in the table.
Conclusion
As you can see, the DDL language is not as difficult as it may seem. I have provided almost all the main constructions. I wish you good luck with studying the SQL language.