Úvod
Určitě jste již slyšeli termín "Collation" v SQL Server. Collation je konfigurace, která určuje, jak se provádí řazení znakových dat. Toto je důležité nastavení, které má obrovský dopad na to, jak se databázový stroj SQL Server chová při práci se znakovými daty. V tomto článku se snažíme diskutovat o porovnávání obecně a ukázat několik příkladů řešení porovnávání.
Kde najdu porovnávání?
Porovnání SQL můžete najít na úrovni serveru, databáze a sloupce. Další důležitou věcí je vědět, že nastavení řazení nemusí být stejné na úrovni serveru, databáze a sloupce. Můžete také aktualizovat své dotazy tak, aby používaly konkrétní řazení. Právě v tuto chvíli si uvědomíte důležitost konfigurace správného řazení ve vašem prostředí, protože existuje velká možnost neočekávaných problémů, pokud není řazení konzistentní.
Jaké různé typy porovnávání jsou k dispozici?
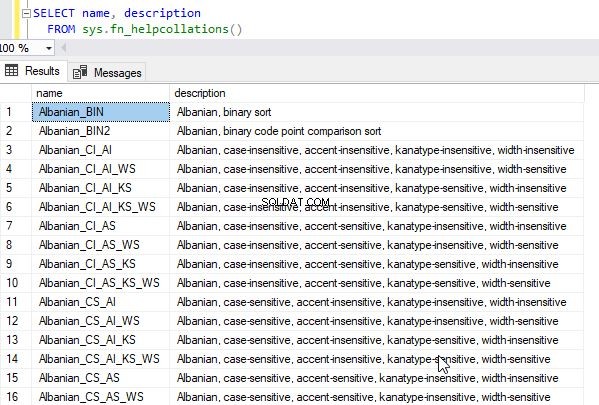
Úplný seznam dostupných porovnávání můžete získat dotazem na systémovou funkci sys.fn_helpcollations()
select * from sys.fn_helpcollations()
Tím se vrátí následující výstup.
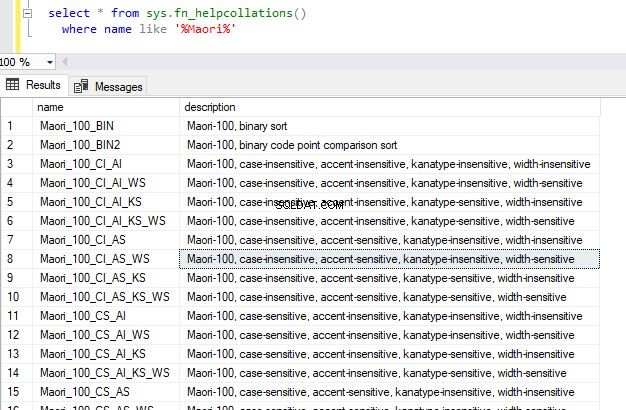
Pokud hledáte konkrétní řazení podle jazyka, můžete název dále filtrovat. Pokud například hledáte řazení podporované maorským jazykem, můžete použít následující dotaz.
select * from sys.fn_helpcollations()
where name like '%Maori%' Tím se vrátí následující výstup.
Tímto způsobem můžete zkontrolovat podporovaná kolace pro řazení podle vašeho výběru. Při pouhém dotazu na systémovou funkci fn_helpcollations() bylo vráceno celkem 5508 řádků, což znamená, že existuje mnoho podporovaných porovnávání. Všimněte si, že to pokrývá většinu jazyků po celém světě.
Jaké různé možnosti vidíte v názvu řazení?
Například v tomto řazení:Maori_100_CS_AI_KS_WS_SC_UTF8 můžete v názvu řazení vidět různé možnosti.
CS – rozlišují se malá a velká písmena
AI – necitlivé na přízvuk
KS – typově citlivé kana
WS – citlivé na šířku
SC – doplňkové znaky
UTF8 – Kódovací standard
Na základě typu vybrané možnosti řazení bude databázový stroj SQL Server fungovat odlišně při práci se znakovými daty pro operace řazení a vyhledávání. Pokud například použijete možnost rozlišovat malá a velká písmena v řazení SQL, databázový stroj se bude chovat jinak pro operaci dotazu hledající „Adam“ nebo „adam“. Za předpokladu, že máte tabulku nazvanou „sample“ a je tam sloupec křestního jména s uživatelem „adam“. Dotaz níže nevrátí žádné výsledky, pokud neexistuje řádek s křestním jménem „Adam“. Důvodem je možnost „CS-Case sensitive“ v řazení.
select * from sample
where firstname like '%Adam%' Pomocí tohoto jednoduchého příkladu můžete pochopit význam výběru správné možnosti řazení SQL. Před výběrem řazení se ujistěte, že rozumíte požadavkům aplikace.
Nalezení řazení na instanci SQL Server
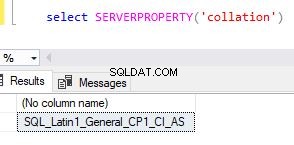
Porovnání serveru můžete získat v SQL Server Management Studio (SSMS) kliknutím pravým tlačítkem na instanci SQL, poté kliknutím na možnost „Vlastnosti“ a zaškrtnutím karty „Obecné“. Toto řazení je vybráno ve výchozím nastavení při instalaci SQL Server.
Alternativně můžete k nalezení hodnoty řazení použít volbu serverproperty.
select SERVERPROPERTY('collation'),
Nalezení řazení databáze SQL
V SSMS klikněte pravým tlačítkem na databázi SQL a přejděte na „Vlastnosti“. Podrobnosti o řazení můžete zkontrolovat na kartě „Obecné“, jak je uvedeno níže.
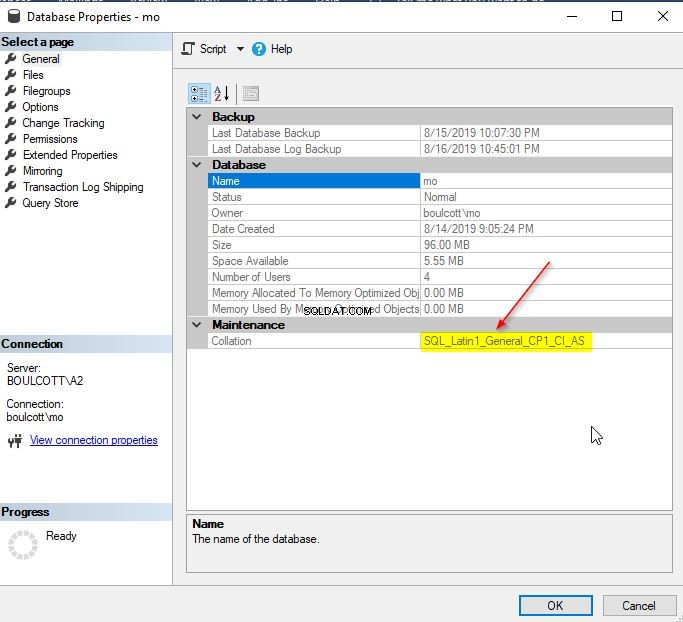
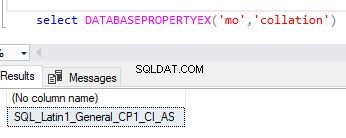
Případně můžete použít funkci databasepropertyex k získání podrobností o řazení databáze.
select DATABASEPROPERTYEX('Your DB Name','collation')
Nalezení řazení sloupce v tabulce
V SSMS přejděte na tabulku, poté na sloupce a nakonec klikněte pravým tlačítkem na jednotlivé sloupce a zobrazte „Vlastnosti“. Pokud je sloupec znakového datového typu, uvidíte podrobnosti o řazení.
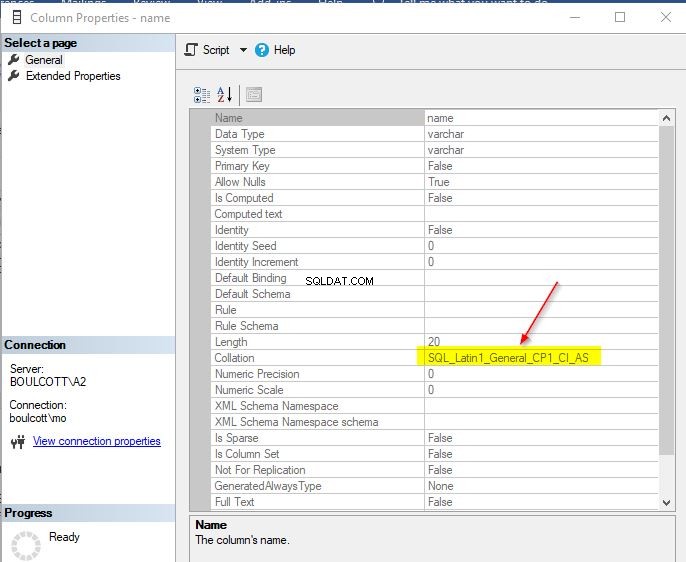
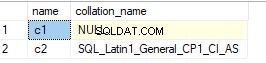
Pokud však zároveň zkontrolujete hodnotu pro datový typ bez znaků, bude hodnota řazení null. Níže je snímek obrazovky sloupce, který má datový typ int.
Alternativně můžete použít ukázkový dotaz níže k zobrazení hodnot řazení pro sloupce.
select sc.name, sc.collation_name from sys.columns sc inner join sys.tables t on sc.object_id=t.object_id where t.name='t1' – enter your table name
Níže je výstup pro dotaz.
Vyzkoušení různých řazení v dotazech SQL
V této části uvidíme, jak se pořadí řazení ovlivní, když se v dotazech použijí různá řazení. Vytvoří se vzorová tabulka se 2 sloupci, jak je uvedeno níže.
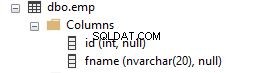
Sloupec fname má výchozí řazení databáze, do které patří. V tomto případě je řazení SQL_Latin1_General_CP1_CI_AS.
K vložení několika záznamů do tabulky použijte dotaz níže. Přiřaďte parametrům své vlastní hodnoty.
insert into emp values (1,'mohammed') insert into emp values (2,'moinudheen') insert into emp values (3,'Mohammed') insert into emp values (4,'Moinudheen') insert into emp values (5,'MOHAMMED') insert into emp values (6,'MOINUDHEEN')
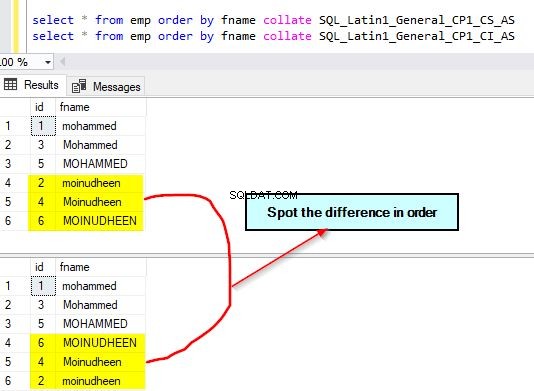
Nyní zadejte dotaz na tabulku emp a seřaďte ji podle sloupce fname pomocí různých řazení. Pro řazení použijeme výchozí řazení sloupce a další řazení rozlišující malá a velká písmena – SQL_Latin1_General_CP1_CS_AS.
select * from emp order by fname collate SQL_Latin1_General_CP1_CS_AS select * from emp order by fname collate SQL_Latin1_General_CP1_CI_AS – this is default
Výstup pro tyto dotazy je uveden níže. Všimněte si rozdílu v použitém řazení. Místo rozlišování malých a velkých písmen používáme rozlišování malých a velkých písmen.
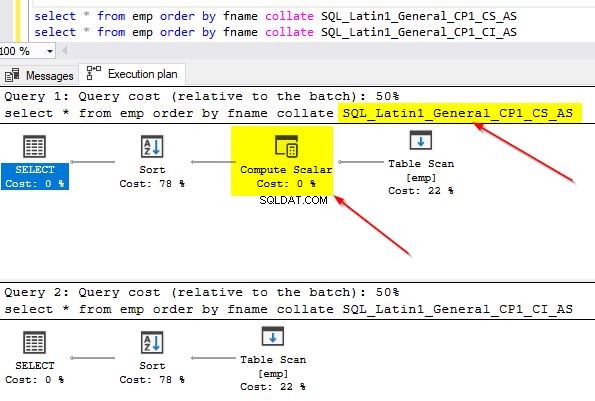
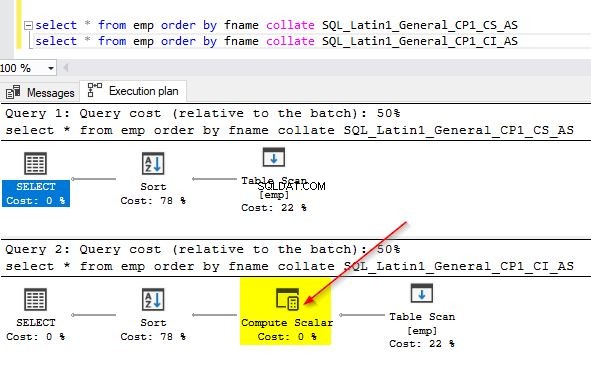
Můžete také zkontrolovat plány dotazů pro oba tyto dotazy, abyste zjistili rozdíl. V prvním plánu dotazů, kde používáme jiné řazení než to ve sloupci, si můžete všimnout dalšího operátoru „Compute Scalar“.
Když najedete myší na operátor „Compute Scalar“, uvidíte další podrobnosti, jak je uvedeno níže. To je způsobeno implicitní konverzí, která probíhá, protože používáme jiné řazení, než je výchozí, který se používá ve sloupci.
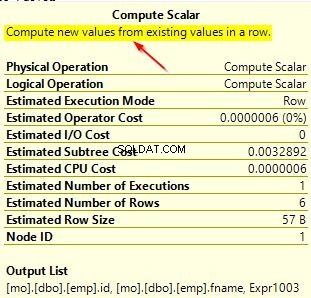
Na tomto malém příkladu můžete vidět druh dopadu na výkon dotazu, když v dotazech explicitně použijete řazení. V naší demo databázi jsme použili jednoduchou tabulku, ale představte si scénář v reálném čase, kde malé změny ve výkonu dotazů mohou způsobit neočekávané výsledky.
Kontrola, zda je možné změnit řazení na úrovni instance
V této části se podíváme na různé scénáře, kdy možná budeme muset změnit výchozí kolace. Můžete nastat situace, kdy vám budou předány servery nebo databáze, které nemusí splňovat vaše standardní zásady, takže možná budete muset změnit řazení. Výchozí řazení serveru SQL Server je SQL_Latin1_General_CP1_CI_AS. Změna řazení na úrovni instance SQL není přímočará. Vyžaduje to skriptování všech objektů v uživatelských databázích, export dat, zrušení uživatelských databází, opětovné sestavení hlavní databáze s novým řazením, vytvoření uživatelských databází a následný import všech dat. Pokud tedy instalujete nové instance SQL, ujistěte se, že jste napoprvé správně provedli řazení, jinak možná budete muset později udělat spoustu nechtěné práce. Podrobné vysvětlení fází změny řazení na úrovni instance přesahuje rozsah tohoto článku kvůli podrobným krokům požadovaným pro každou z fází.
Změna řazení na úrovni databáze
Naštěstí není změna řazení na úrovni databáze tak obtížná jako změna řazení instance. Porovnání můžeme aktualizovat pomocí SSMS i T-SQL. V SSMS klikněte pravým tlačítkem na databázi, přejděte na „Vlastnosti“ a klikněte na kartu „Možnosti“ na levé straně. Zde můžete v rozbalovací nabídce zobrazit možnost změny řazení.
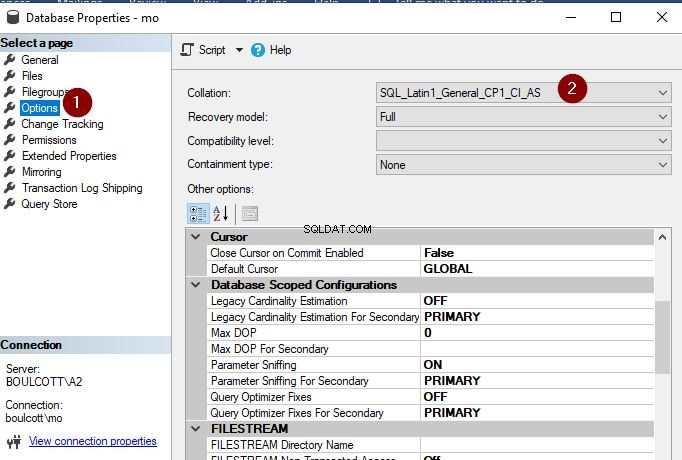
Po dokončení klikněte na „OK“. Právě jsem změnil řazení databáze na SQL_Latin1_General_CP1_CI_AS. Jen se ujistěte, že tuto operaci provádíte, když se databáze nepoužívá, jinak operace selže, jak je uvedeno níže.
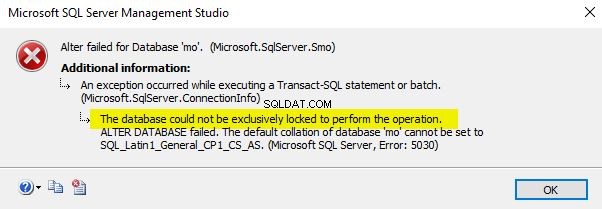
Ke změně řazení databáze pomocí T-SQL použijte pokračující dotaz.
USE master; GO ALTER DATABASE mo COLLATE SQL_Latin1_General_CP1_CS_AS; GO
Všimli byste si, že změna řazení na úrovni databáze neovlivní řazení existujících sloupců v tabulkách. Předchozí příklady můžete použít ke kontrole dopadu řazení na pořadí řazení pro dotazy níže.
select * from emp order by fname collate SQL_Latin1_General_CP1_CS_AS select * from emp order by fname collate SQL_Latin1_General_CP1_CI_AS – - this is default
Porovnání sloupců fname zůstane původní a zůstane nezměněno i po změně řazení na úrovni databáze.
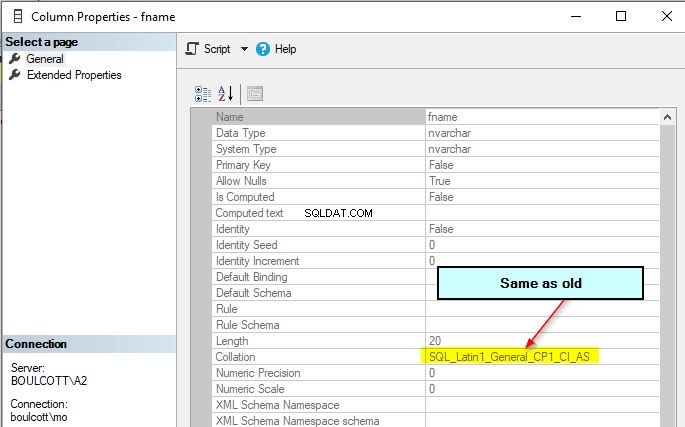
Nové řazení na úrovni databáze však bude použito pro všechny nové sloupce v nových tabulkách, které vytvoříte. Vždy tedy důkladně otestujte změnu databázových řazení, protože má značný dopad na výstup nebo chování dotazů.
Změna řazení na úrovni sloupců
V předchozí části jste si všimli, že i po změně řazení na úrovni databáze zůstává řazení stávajících sloupců v tabulkách nezměněno. V této části uvidíme, jak můžeme změnit řazení stávajících sloupců v tabulkách tak, aby odpovídalo řazení v databázi. V předchozí části jste změnili řazení databáze na SQL_Latin1_General_CP1_CS_AS. Dále chcete identifikovat všechny sloupce v tabulkách uživatelů, které neodpovídají tomuto řazení databáze. Tento skript můžete použít k identifikaci těchto sloupců.
select so.name TableName,sc.name ColumnName, sc.collation_name CollationName from sys.objects so inner join sys.columns sc on so.object_id=sc.object_id where sc.collation_name!='SQL_Latin1_General_CP1_CS_AS' and so.[type] ='U'
Ukázkový výstup z mé demo databáze je uveden níže.
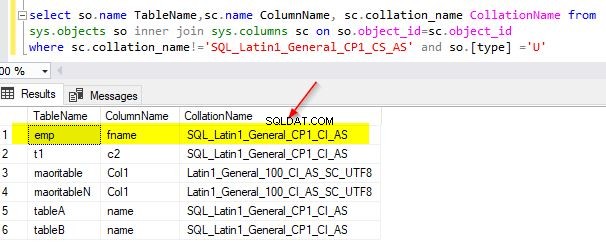
Předpokládejme, že chcete změnit řazení existujícího sloupce fname na „SQL_Latin1_General_CP1_CS_AS“, pak můžete použít tento alter skript níže.
use mo
go
ALTER TABLE dbo.emp ALTER COLUMN fname
nvarchar(20) COLLATE SQL_Latin1_General_CP1_CS_AS NULL;
GO Pokud použijete předchozí příklady, kde jste zkontrolovali výkon dotazu pomocí různých porovnávání, všimnete si, že operátor „výpočetní skalární“ se nepoužívá, když používáme stejné řazení jako databáze. Podívejte se na snímek obrazovky níže. V předchozím příkladu jste si mohli všimnout, že operátor „Výpočetní skalární“ byl použit v prvním plánu provádění. Protože jsme změnili řazení sloupců, aby odpovídalo řazení databází, není potřeba implicitní převod. Ve druhém dotazu uvidíte operátor „Vypočítat skalární“, protože explicitně používá jiné řazení.
select * from emp order by fname collate SQL_Latin1_General_CP1_CS_AS – - this is default select * from emp order by fname collate SQL_Latin1_General_CP1_CI_AS
Můžeme změnit řazení systémových databází?
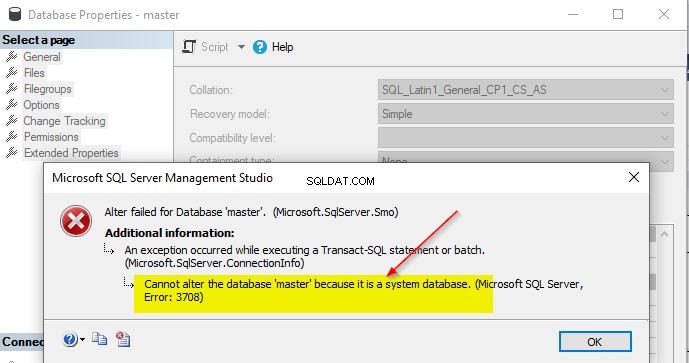
Změna řazení systémových databází není možná. Pokud se pokusíte změnit řazení systémových databází – hlavní, model, msdb nebo tempdb, zobrazí se tato chybová zpráva.
Chcete-li změnit řazení systémových databází, budete muset při změně řazení na úrovni instance SQL Server postupovat podle výše uvedených kroků. Aby se předešlo takovým problémům, je důležité, abyste při první instalaci SQL Serveru získali správné řazení.
Známý problém s konfliktem řazení
Dalším běžným problémem, který můžete najít, je chyba související s konfliktem řazení, zejména při použití dočasných objektů. Dočasné objekty jsou uloženy v databázi tempdb. Databáze tempdb, která je systémovou databází, bude předpokládat řazení instance SQL. Když vytvoříte uživatelské databáze, které mají jiné řazení než instance SQL, narazíte na problémy při používání dočasných objektů. Můžete se také potýkat s problémy při porovnávání sloupců v tabulkách, které mají různá řazení. Nyní již víte, že tabulka může mít sloupce s různým řazením, protože nemůžeme řazení změnit na úrovni tabulky. Běžná chybová zpráva, které si všimnete, je něco jako „Nelze vyřešit konflikt řazení mezi „Collation1“ a „Collation2“ v operaci rovná se. Collation1 a Collation2 může být jakékoli řazení použité v dotazu. Pomocí jednoduchého příkladu můžeme vytvořit ukázku tohoto konfliktu řazení. Pokud jste dokončili předchozí příklady v tomto článku, již budete mít tabulku s názvem „emp“. Stačí vytvořit dočasnou tabulku ve vaší demo databázi a vložit záznamy pomocí poskytnutého vzorového skriptu.
create table #emptemp (id int, fname nvarchar(20)) insert into #emptemp select * from emp
Stačí spustit spojení pomocí obou tabulek a dostanete tuto chybu konfliktu řazení, jak je uvedeno níže.
select e.id, et.fname from emp e inner join #emptemp et on e.fname=et.fname

Všimnete si, že použité řazení uživatelských databází je „SQL_Latin1_General_CP1_CS_AS“ a neshoduje se s řazením na serveru. Chcete-li opravit tento typ chyby, můžete změnit sloupce, které se používají v dočasných objektech, aby se použilo výchozí řazení databáze uživatelů. Můžete použít volbu „database_default“ nebo explicitně zadat porovnávací jméno uživatelské databáze. V tomto příkladu používáme řazení „SQL_Latin1_General_CP1_CS_AS“. Vyzkoušejte jednu z těchto možností
Možnost 1: Použijte volbu database_default
alter table #emptemp alter column fname nvarchar(20) collate database_default
Po dokončení spusťte příkaz select znovu a chyba bude opravena.
Možnost 2: Explicitně použijte řazení databáze uživatelů
alter table #emptemp alter column fname nvarchar(20) collate SQL_Latin1_General_CP1_CS_AS
Po dokončení spusťte příkaz select znovu a chyba bude opravena.
Závěr
V tomto článku jste se dozvěděli o:
• konceptu řazení
• různých dostupných možnostech řazení
• hledání podrobností o řazení pro jakoukoli instanci SQL, databázi a sloupec
• A PRACOVNÍ PŘÍKLAD na vyzkoušení možností řazení v dotazech SQL
• změna řazení na úrovni instance, databáze a sloupce
• JAK změnit řazení systémových databází
• konflikt řazení a jak opravit to
Nyní víte o důležitosti řazení a důležitosti konfigurace správného řazení v instanci SQL a také napříč databázovými objekty. Vždy otestujte různé scénáře ve svém testovacím prostředí, než použijete některou z výše uvedených možností na své produkční systémy.