Přehled tradiční obnovy
Stejně jako u všech relačních databázových systémů zaručuje SQL Server trvanlivost dat implementací obnovy po havárii. Trvanlivost ve zkratce ACID, která odkazuje na charakteristiky transakcí v relačních databázích, znamená, že si můžeme být jisti, že pokud databáze náhle selže, naše data jsou v bezpečí.
SQL Server implementuje tuto schopnost pomocí protokolu transakcí. Změny provedené všemi operacemi manipulace s daty v SQL Serveru jsou zachyceny v transakčním protokolu předtím, než jsou aplikovány na datové soubory (prostřednictvím procesu kontrolního bodu) v případě, že je potřeba vrátit se zpět nebo vrátit vpřed.
Třífázový proces zotavení z havárie na serveru SQL Server je následující:
Analýza – SQL Server čte transakční protokol od posledního kontrolního bodu do konce transakčního protokolu
Opakovat – SQL Server přehraje protokol od nejstarší nepotvrzené transakce do konce protokolu
Vrátit zpět – SQL Server čte protokol od konce protokolu po nejstarší nepotvrzenou transakci a vrátí všechny transakce, které byly aktivní během havárie
Zkušení správci databází by v určité fázi své kariéry měli skličující zkušenost s bezmocným čekáním na dokončení obnovy po havárii na velmi velké databázi. Transakční ROLLBACK využívá podobný mechanismus jako proces obnovy po havárii. Společnost Microsoft výrazně zlepšila proces obnovy v SQL Server 2019.
Urychlené obnovení databáze
Accelerated Database Recovery je nová funkce založená na verzování, která výrazně zvyšuje rychlost obnovy v případě ROLLBACK nebo obnovy po havárii.
V SQL Server 2019 upravují tři nové mechanismy v rámci enginu SQL Server způsob, jakým je zpracována obnova, a efektivně zkracují dobu potřebnou k provedení rollback/rollforward.
Persistent Version Store (PVS) – Zachycuje verze řádků v dané databázi. Trvalé úložiště verzí lze definovat v samostatné skupině souborů z důvodu výkonu nebo velikosti
Logický návrat – Používá verze řádků uložené v PVS k provedení rollbacku, když je vyvoláno vrácení pro konkrétní transakci nebo když je vyvolána fáze undo obnovy po havárii.
sLog – Toto možná znamená sekundární protokol . Je to proud protokolu v paměti, který se používá k zachycení operací, které nelze verzovat. Když je v databázi povoleno ADR, sLog se vždy znovu sestaví během fáze analýzy obnovy po havárii. Během opakování fáze, sLog se používá spíše než skutečný transakční protokol, díky čemuž je proces rychlejší, protože je uložen v paměti a obsahuje méně transakcí. Tradiční proces obnovy zpracovává transakce od posledního kontrolního bodu. Záznam sLog se také používá při zpět fáze.
Čistič – Odebere nepotřebné verze řádků z PVS. Microsoft také poskytuje uloženou proceduru pro ruční vynucení vyčištění nepotřebných verzí řádků.
-- LISTING 1: INVOKE THE BACKGROUND CLEANER USE TSQLV4_ADR GO EXECUTE sys.sp_persistent_version_cleanup; USE master GO EXECUTE master.sys.sp_persistent_version_cleanup 'TSQLV4_ADR';
Accelerated Database Recovery je ve výchozím nastavení vypnuto
Skutečnost, že ADR je na SQL Server 2019 ve výchozím nastavení vypnutá, se může některým správcům databází zdát překvapivá, protože se zdá, že jde o tak skvělou funkci. ADR používá verzování v databázi uživatelů, ve které je povoleno. To může výrazně ovlivnit velikost databáze. Kromě toho možná budete muset naplánovat růst databáze a také možné umístění PVS, abyste zajistili dobrý výkon, pokud je povoleno ADR. Dává tedy smysl tuto funkci záměrně povolit.
Experiment:Přípravná fáze
Nastavili jsme experiment, abychom prozkoumali novou funkci a viděli dopad ADR na velikost protokolu transakcí a také na rychlost ROLLBACK. V našem experimentu vytvoříme dvě identické databáze pomocí jedné zálohovací sady a poté povolíme ADR pouze na jedné z těchto databází. Výpis 2 ukazuje přípravné fáze pro úkol.
[rozbalit název =”Kód”]
-- LISTING 2: PREPARE THE DATABASES AND CONFIGURE ADR
-- 2a. Backup a sample database and restore as two identical databases
BACKUP DATABASE TSQLV4 TO DISK='TSQLV4.BAK' WITH COMPRESSION;
-- Restore Database TSQLV4_NOADR (ADR will not be enabled)
RESTORE DATABASE TSQLV4_NOADR FROM DISK='TSQLV4.BAK' WITH
MOVE 'TSQLV4' TO 'C:\MSSQL\DATA\TSQLV4_NOADR.MDF',
MOVE 'TSQLV4_log' TO 'E:\MSSQL\LOG\TSQLV4_NOADR_LOG.LDF';
-- Restore Database TSQLV4_ADR (ADR will be enabled)
RESTORE DATABASE TSQLV4_ADR FROM DISK='TSQLV4.BAK' WITH
MOVE 'TSQLV4' TO 'C:\MSSQL\DATA\TSQLV4_ADR.MDF',
MOVE 'TSQLV4_log' TO 'E:\MSSQL\LOG\TSQLV4_ADR_LOG.LDF';
-- 2b. Enable ADR in TSQLV4_ADR
USE [master]
GO
-- First create a separate filegroup and add a file to the filegroup
ALTER DATABASE [TSQLV4_ADR] ADD FILEGROUP [ADR_FG];
ALTER DATABASE [TSQLV4_ADR] ADD FILE ( NAME = N'TSQLV4_ADR01', FILENAME = N'C:\MSSQL\Data\TSQLV4_ADR01.ndf' ,
SIZE = 8192KB , FILEGROWTH = 65536KB ) TO FILEGROUP [ADR_FG]
GO
-- Enable ADR
ALTER DATABASE TSQLV4_ADR SET ACCELERATED_DATABASE_RECOVERY = ON (PERSISTENT_VERSION_STORE_FILEGROUP = ADR_FG);
GO
-- 2c. Check if all ADR is enabled as planned
SELECT name
, compatibility_level
, snapshot_isolation_state_desc
, recovery_model_desc
, target_recovery_time_in_seconds
, is_accelerated_database_recovery_on FROM SYS.DATABASES
WHERE name LIKE 'TSQLV4_%';
-- 2d. Check sizes of all files in the databases
SELECT DB_NAME(database_id) AS database_name
, name AS file_name
, physical_name
, (size * 8)/1024 AS [size (MB)]
, type_desc
FROM SYS.master_files
WHERE DB_NAME(database_id) LIKE 'TSQLV4_%';
-- 2e. Check size of log used
CREATE TABLE ##LogSpaceUsage (database_name VARCHAR(50)
, database_id INT, total_log_size_in_bytes BIGINT
, used_log_space_in_bytes BIGINT
, used_log_space_in_percent BIGINT
, log_space_in_bytes_since_last_backup BIGINT)
INSERT INTO ##LogSpaceUsage
EXEC sp_MSforeachdb @command1='
IF ''?'' LIKE ("TSQLV4_%")
SELECT DB_NAME(database_id), * FROM ?.SYS.dm_db_log_space_usage;'
SELECT * FROM ##LogSpaceUsage;
DROP TABLE ##LogSpaceUsage; [/expand]
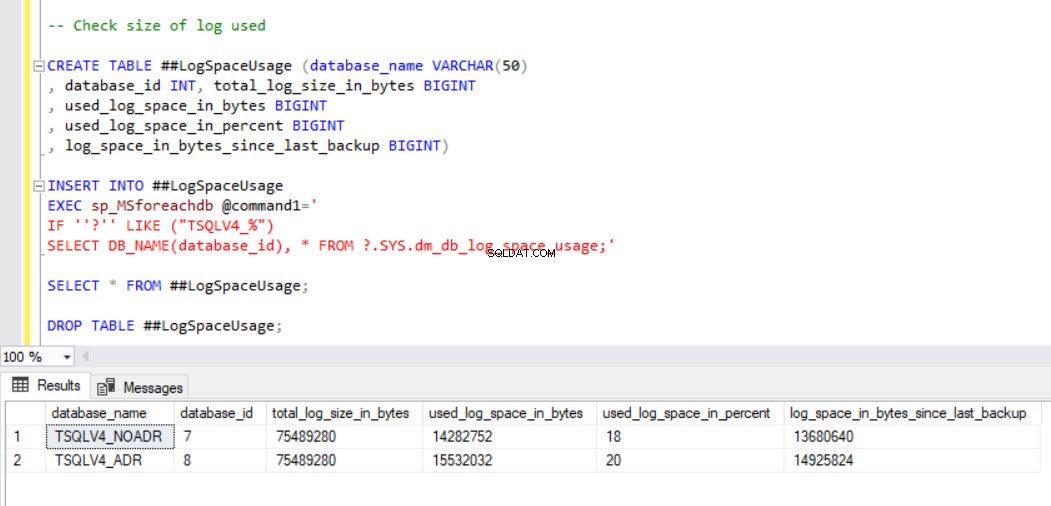
Obr. 1 ukazuje výstup příkazu SQL ve výpisu 2, sekce 2c. Zachytili jsme také velikost databázových souborů a využití souboru protokolu transakcí. (viz obr. 3).
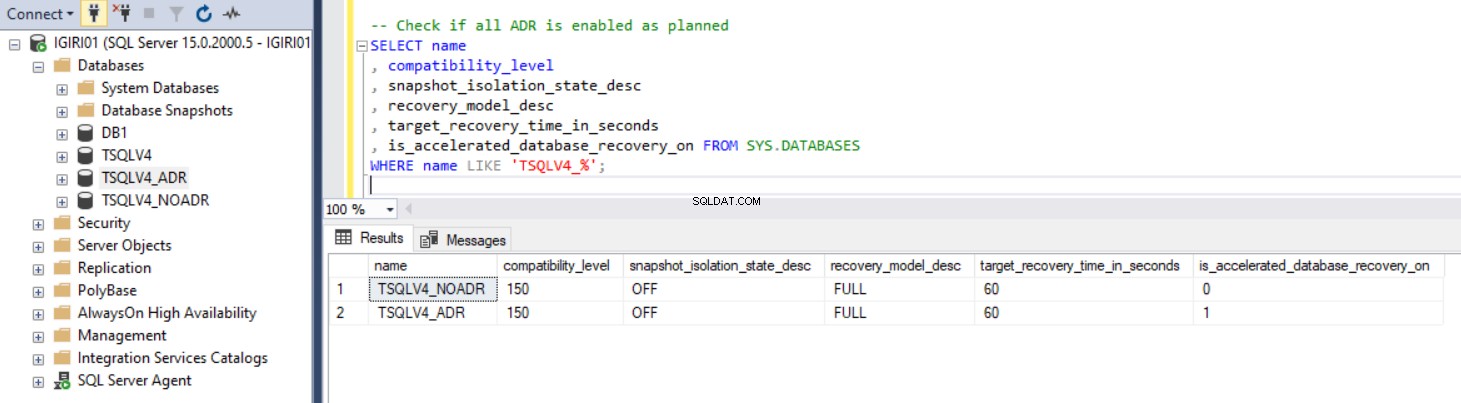
Obr. 1 Potvrďte, že je ADR nakonfigurováno
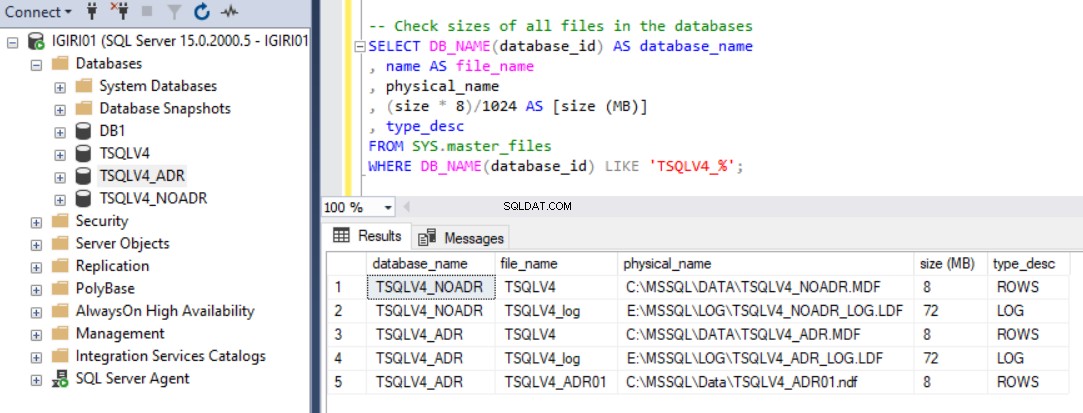
Obr. 2 Zkontrolujte velikosti datových souborů databáze
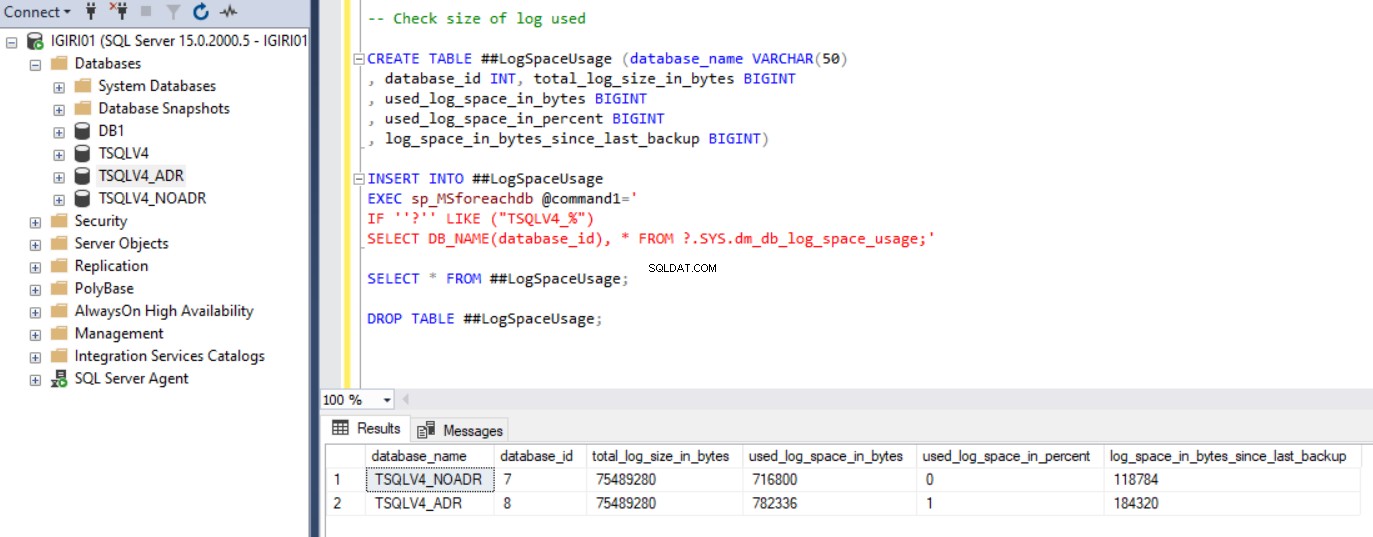
Obr. 3 Zkontrolujte velikost použitého protokolu pro obě databáze
Experiment:Fáze provedení
Jakmile zachytíme podrobnosti, které potřebujeme k pokračování, spustíme kód SQL z výpisů 3 a 4 postupně. Tyto dva výpisy jsou ekvivalentní, ale provádíme je na dvou identických databázích samostatně. Nejprve provedeme INSERT (výpis 3, 3a), poté provedeme DELETE (výpis 3, 3b), který následně vrátíme zpět. Všimněte si, že v INSERT i DELETE jsme operace zapouzdřili do transakcí. Všimněte si také, že INSERT se provede 50krát. V každé fázi provádění, tj. mezi 3a, 3b a 3c, zaznamenáváme použití protokolu transakcí pomocí kódu ve výpisu 2,2e. To je stejné pro sekce 4a, 4b a 4c.
-- LISTING 3: EXECUTE DML IN TSQLV4_NOADR DATABASE -- 3a. Execute INSERT Statement in TSQLV4_NOADR Database USE TSQLV4_NOADR GO BEGIN TRAN SET STATISTICS IO ON; SET STATISTICS TIME ON; SELECT * INTO [Sales].[OrderDetails_noadr] FROM [Sales].[OrderDetails]; GO INSERT INTO [Sales].[OrderDetails_noadr] SELECT * FROM [Sales].[OrderDetails]; GO 50 COMMIT; -- 3b. Execute DELETE in TSQLV4_NOADR Database USE TSQLV4_NOADR GO BEGIN TRAN SET STATISTICS IO ON; SET STATISTICS TIME ON; DELETE FROM [Sales].[OrderDetails_noadr] GO -- 3c. Perform Rollback and Capture Time ROLLBACK;
Obr. 4 a 5 nám ukazují, že operace SELECT INTO trvala o 6 milisekund déle v databázi TSQLV4_ADR, kde jsme povolili Accelerated Database Recovery. Na obr. 6 také vidíme, že máme větší využití transakčního protokolu v databázi TSQLV4_ADR. To mě obzvláště překvapilo, takže jsem experiment několikrát opakoval, abych se ujistil, že tento výsledek získám konzistentně.
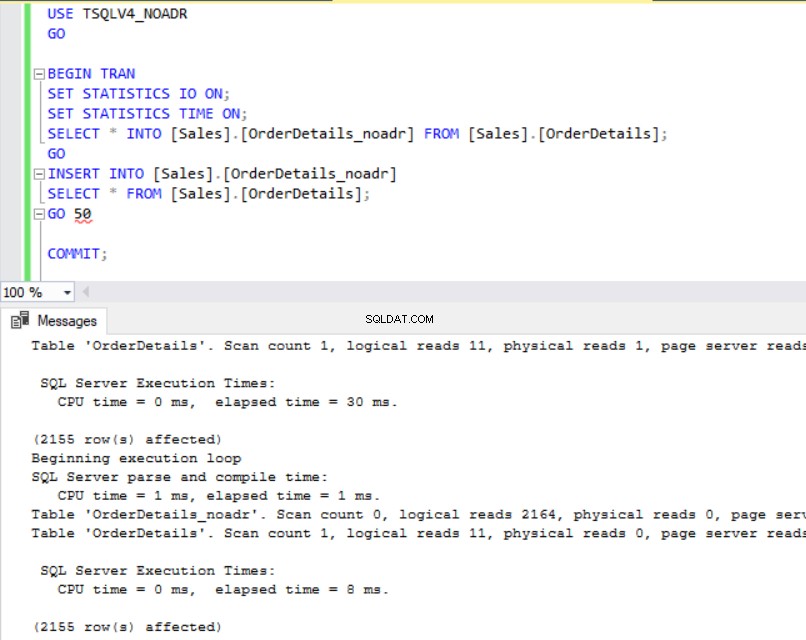
Obr. 4 Vložte čas spuštění pro TSQLV4_NOADR
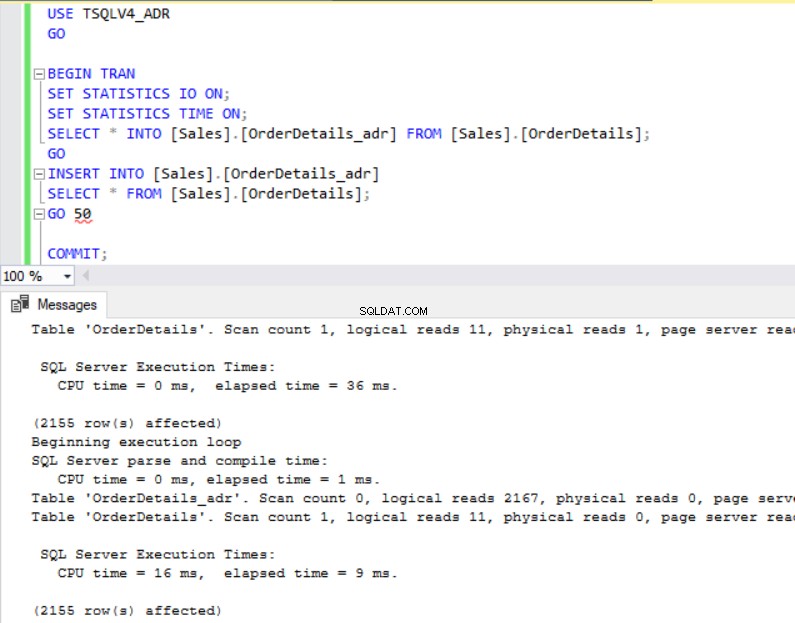
Obr. 5 Vložte čas spuštění pro TSQLV4_ADR
Obr. 6 Použití protokolu transakcí po vložení
-- LISTING 4: EXECUTE DML IN TSQLV4_ADR DATABASE -- 4a. Execute INSERT Statement in TSQLV4_ADR Database USE TSQLV4_ADR GO BEGIN TRAN SET STATISTICS IO ON; SET STATISTICS TIME ON; SELECT * INTO [Sales].[OrderDetails_adr] FROM [Sales].[OrderDetails]; GO INSERT INTO [Sales].[OrderDetails_adr] SELECT * FROM [Sales].[OrderDetails]; GO 50 COMMIT; -- 4b. Execute DELETE in TSQLV4_ADR Database USE TSQLV4_ADR GO BEGIN TRAN SET STATISTICS IO ON; SET STATISTICS TIME ON; DELETE FROM [Sales].[OrderDetails_adr] GO -- 4c. Perform Rollback and Capture Time ROLLBACK;
Obr. 7 a 8 nám ukazují, že dokončení operace DELETE trvalo podstatně déle v databázi TSQLV4_ADR, kde jsme povolili Accelerated Database Recovery, i když byl v obou databázích smazán stejný počet řádků. Tentokrát však máme větší využití protokolu transakcí v databázi TSQLV4_NOADR.
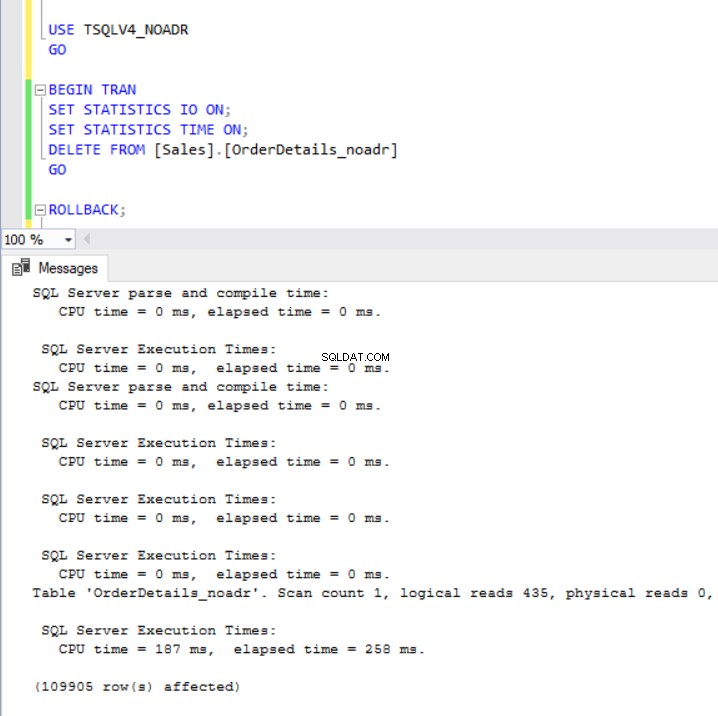
Obr. 7 Vymažte dobu spuštění pro TSQLV4_NOADR
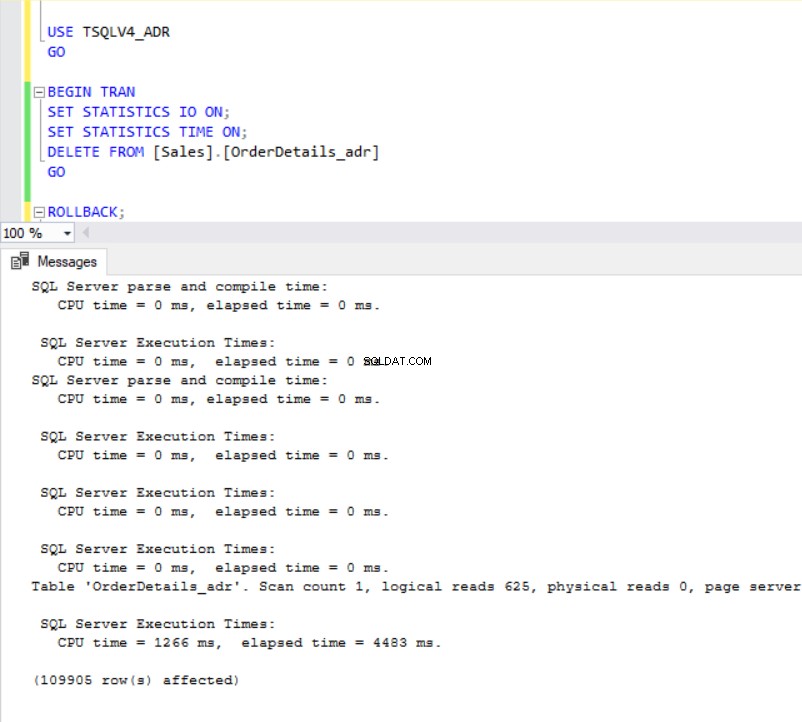
Obr. 8 Odstranit dobu provádění pro TSQLV4_ADR
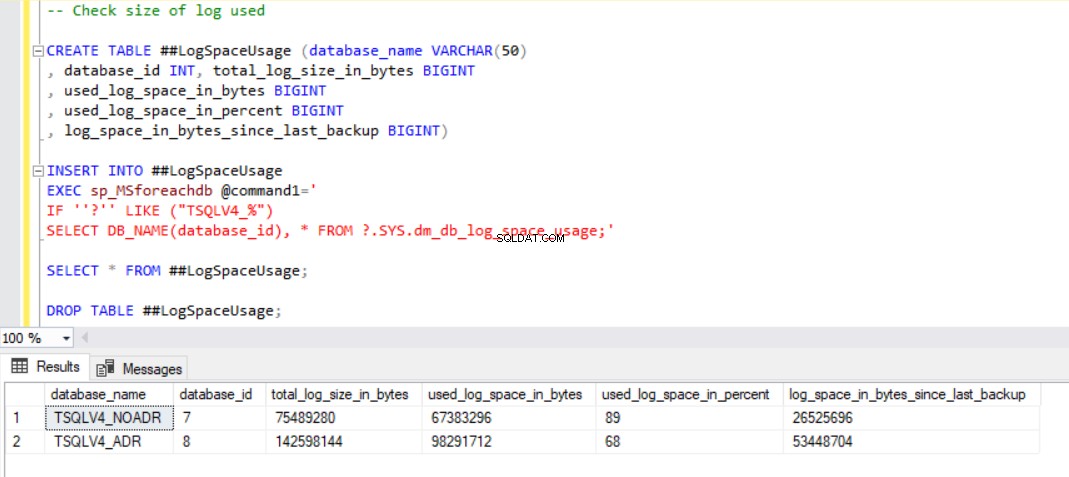
Obr. 9 Použití protokolu transakcí po odstranění
Teď bylo zřejmé, že operace DML v databázích s povoleným ADR trvají déle. To částečně vysvětluje, proč je tato funkce na prvním místě vypnutá. Když se nad tím hluboce zamyslím, dává to smysl, protože SQL Server musí ukládat verze řádků do PVS, zatímco běží operace vložení, aktualizace nebo odstranění. Ať už DML zabere jakoukoli dobu, zjistíme, že vydání ROLLBACK se zapnutým ADR trvá méně než 1 milisekundu (viz obr. 10 – 13). V některých případech může rychlé vrácení zpět kompenzovat režii samotného DML, ale ne ve všech případech!
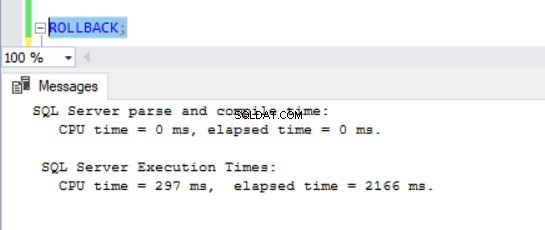
Obr. 10 Doba provedení pro ROLLBACK (po DELETE) na TSQLV4_NOADR
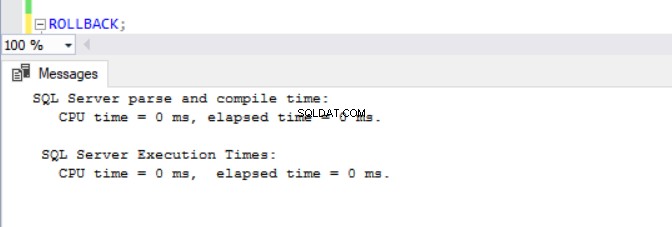
Obr. 11 Doba provedení pro ROLLBACK (po DELETE) na TSQLV4_ADR
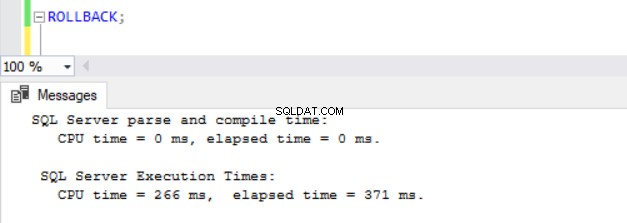
Obr. 12 Doba provedení pro ROLLBACK (po INSERT) na TSQLV4_NOADR
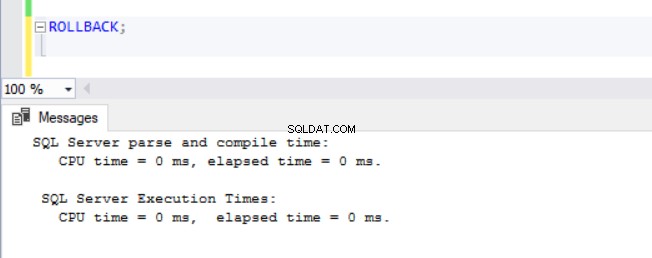
Obr. 13 Doba provedení pro ROLLBACK (po DELETE) na TSQLV4_ADR
Závěr
Accelerated Database Recovery je jednou ze skvělých funkcí vydaných v SQL Server 2019. Nicméně jako za všechny extrémně pěkné věci v životě za to musí někdo zaplatit. ADR může mít v určitých scénářích negativní dopad na výkon, proto je důležité před implementací ADR do produkční databáze pečlivě vyhodnotit svůj scénář. Společnost Microsoft konkrétně doporučuje Accelerated Database Recovery pro databáze podporující pracovní zátěž s velmi dlouho trvajícími transakcemi, nadměrným nárůstem transakčního protokolu nebo častými výpadky souvisejícími s dlouhotrvající obnovou.
Odkazy
Urychlené obnovení databáze
Jak funguje zrychlená obnova databáze?
Urychlené obnovení databáze