Stále se držíte nadřazeného/podřízeného designu, nebo byste chtěli vyzkoušet něco nového, jako je SQL Server hierarchyID? No, je to opravdu nové, protože hierarchieID je součástí SQL Serveru od roku 2008. Novinka samotná samozřejmě není přesvědčivý argument. Všimněte si však, že Microsoft přidal tuto funkci, aby lépe reprezentovala vztahy jedna k mnoha s více úrovněmi.
Možná se divíte, jaký je to rozdíl a jaké výhody získáte z používání hierarchieID namísto obvyklých vztahů rodič/dítě. Pokud jste tuto možnost nikdy nezkoumali, možná to pro vás bude překvapivé.
Pravdou je, že jsem tuto možnost nezkoumal od jejího vydání. Nicméně, když jsem to konečně udělal, zjistil jsem, že je to skvělá inovace. Je to lépe vypadající kód, ale má v sobě mnohem víc. V tomto článku se dozvíme o všech těchto skvělých příležitostech.
Než se však ponoříme do zvláštností používání SQL Server hierarchyID, ujasněme si jeho význam a rozsah.
Co je SQL Server HierarchyID?
SQL Server hierarchyID je vestavěný datový typ určený k reprezentaci stromů, které jsou nejběžnějším typem hierarchických dat. Každá položka ve stromu se nazývá uzel. Ve formátu tabulky je to řádek se sloupcem datového typu hierarchieID.
Obvykle demonstrujeme hierarchie pomocí návrhu tabulky. Sloupec ID představuje uzel a další sloupec představuje rodič. S SQL Server HierarchyID potřebujeme pouze jeden sloupec s datovým typem hierarchieID.
Když zadáte dotaz na tabulku se sloupcem hierarchieID, uvidíte hexadecimální hodnoty. Je to jeden z vizuálních obrazů uzlu. Dalším způsobem je řetězec:
„/“ znamená kořenový uzel;
„/1/“, „/2/“, „/3/“ nebo „/n/“ představují děti – přímí potomci 1 až n;
„/1/1/“ nebo „/1/2/“ jsou „děti dětí – „vnoučata“. Řetězec jako „/1/2/“ znamená, že první dítě z kořene má dvě děti, což jsou zase dvě vnoučata kořene.
Zde je ukázka toho, jak to vypadá:
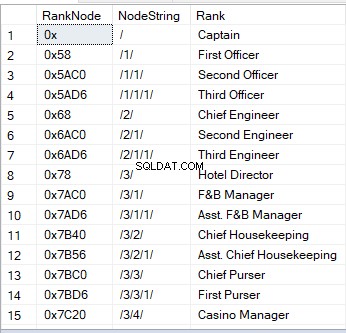
Na rozdíl od jiných datových typů mohou sloupce hierarchieID využívat vestavěné metody. Pokud máte například sloupec hierarchieID s názvem RankNode , můžete mít následující syntaxi:
RankNode.
Metody SQL Server HierarchyID
Jednou z dostupných metod je IsDescendantOf . Vrátí 1, pokud je aktuální uzel potomkem hodnoty hierarchieID.
Kód můžete napsat touto metodou podobnou té níže:
SELECT
r.RankNode
,r.Rank
FROM dbo.Ranks r
WHERE r.RankNode.IsDescendantOf(0x58) = 1Další metody používané s hierarchyID jsou následující:
- GetRoot – statická metoda, která vrací kořen stromu.
- GetDescendant – vrátí podřízený uzel rodiče.
- GetAcestor – vrací hierarchické ID představující n-tého předka daného uzlu.
- GetLevel – vrátí celé číslo, které představuje hloubku uzlu.
- ToString – vrací řetězec s logickou reprezentací uzlu. ToString je volána implicitně, když dojde ke konverzi z hierarchieID na typ řetězce.
- GetReparentedValue – přesune uzel ze starého rodiče na nového rodiče.
- Parse – funguje jako opak ToString . Převádí zobrazení řetězce hierarchyID hodnotu na šestnáctkovou.
Strategie indexování SQL Server HierarchyID
Chcete-li zajistit, aby dotazy na tabulky používající hierarchiiID běžely co nejrychleji, musíte sloupec indexovat. Existují dvě strategie indexování:
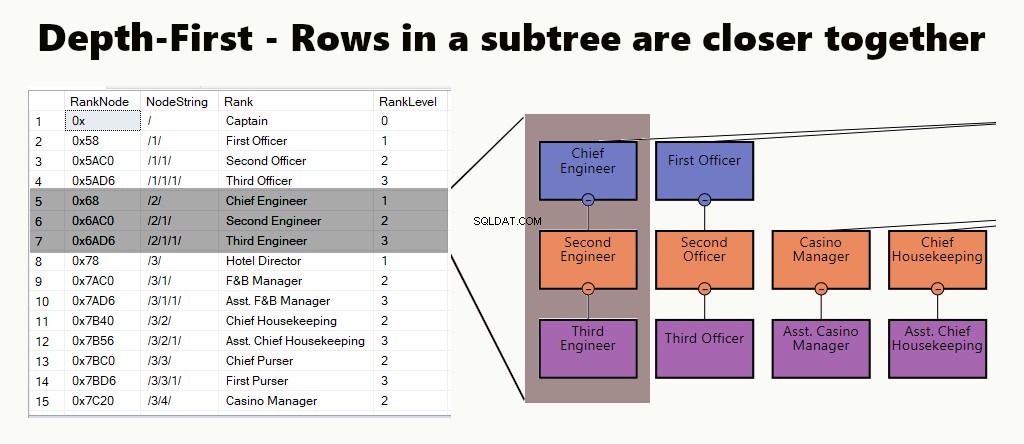
HLOUBKA-PRVNÍ
V indexu na prvním místě hloubky jsou řádky podstromu blíže k sobě. Hodí se pro dotazy, jako je hledání oddělení, jeho podjednotek a zaměstnanců. Dalším příkladem je manažer a jeho zaměstnanci uloženi blíže u sebe.
V tabulce můžete implementovat hloubkový index vytvořením seskupeného indexu pro uzly. Dále provedeme jeden z našich příkladů, přesně tak.
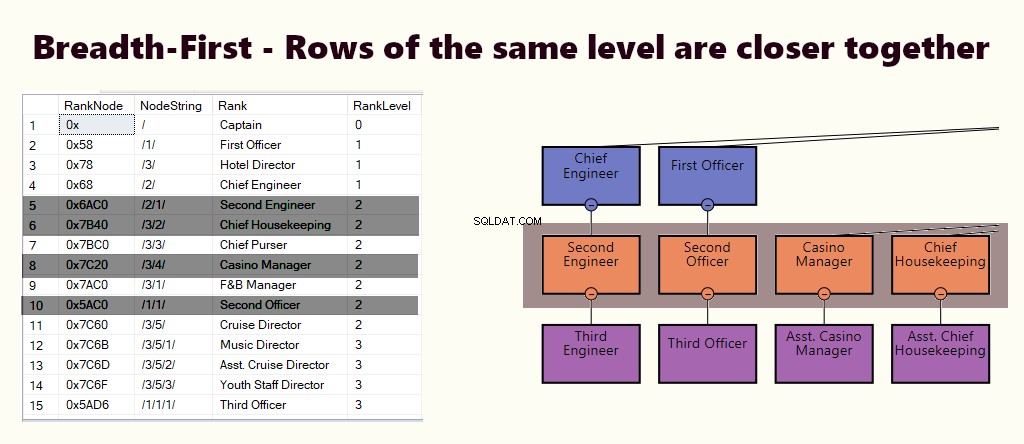
PRVNÍ ŠÍŘKA
V indexu na šířku jsou řádky stejné úrovně blíže u sebe. Vyhovuje dotazům, jako je vyhledání všech přímo podřízených zaměstnanců manažera. Pokud je většina dotazů podobná této, vytvořte seskupený index založený na (1) úrovni a (2) uzlu.
Záleží na vašich požadavcích, zda potřebujete hloubkový index, šířkový index nebo obojí. Musíte najít rovnováhu mezi důležitostí typu dotazů a příkazy DML, které provádíte v tabulce.
Omezení SQL Server HierarchyID
Použití hierarchieID bohužel nemůže vyřešit všechny problémy:
- SQL Server nemůže uhodnout, co je potomkem rodiče. Musíte definovat strom v tabulce.
- Pokud nepoužijete jedinečné omezení, vygenerovaná hodnota hierarchieID nebude jedinečná. Řešení tohoto problému je odpovědností vývojáře.
- Vztahy nadřazených a podřízených uzlů nejsou vynucovány jako vztah cizího klíče. Před odstraněním uzlu se tedy zeptejte na všechny existující potomky.
Vizualizace hierarchií
Než budeme pokračovat, zvažte ještě jednu otázku. Při pohledu na sadu výsledků s řetězci uzlů vám připadá vizualizace hierarchie pro vaše oči náročná?
Pro mě je to velké ano, protože nemládnu.
Z tohoto důvodu budeme spolu s našimi databázovými tabulkami používat Power BI a Hierarchy Chart od Akvelonu. Pomohou zobrazit hierarchii v organizačním schématu. Doufám, že to usnadní práci.
A teď pojďme k věci.
Použití SQL Server HierarchyID
HierarchyID můžete použít s následujícími obchodními scénáři:
- Organizační struktura
- Složky, podsložky a soubory
- Úkoly a dílčí úkoly v projektu
- Stránky a podstránky webu
- Geografické údaje se zeměmi, regiony a městy
I když je váš obchodní scénář podobný výše uvedenému a zřídkakdy se dotazujete napříč sekcemi hierarchie, nepotřebujete hierarchiiID.
Vaše organizace například zpracovává mzdy zaměstnanců. Potřebujete přístup do podstromu, abyste mohli zpracovat něčí mzdovou agendu? Vůbec ne. Pokud však zpracováváte provize lidí v systému multilevel marketingu, může to být jinak.
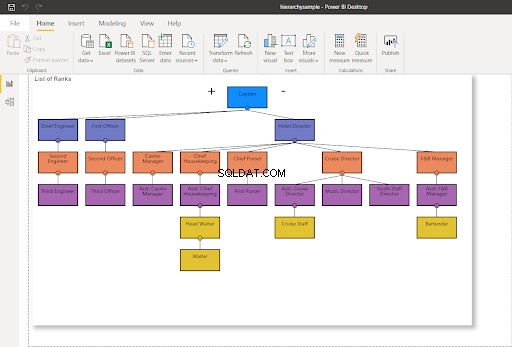
V tomto příspěvku používáme část organizační struktury a řetězce velení na výletní lodi. Struktura byla převzata z organizačního schématu odtud. Podívejte se na to na obrázku 4 níže:

Nyní si můžete představit příslušnou hierarchii. V tomto příspěvku používáme níže uvedené tabulky:
- Nádoby – je tabulka pro seznam výletních lodí.
- Pořadí – je tabulka hodností posádky. Zde vytváříme hierarchie pomocí hierarchieID.
- Posádka – je seznam posádky každého plavidla a jejich hodnosti.
Struktura tabulky každého případu je následující:
CREATE TABLE [dbo].[Vessel](
[VesselId] [int] IDENTITY(1,1) NOT NULL,
[VesselName] [varchar](20) NOT NULL,
CONSTRAINT [PK_Vessel] PRIMARY KEY CLUSTERED
(
[VesselId] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
CREATE TABLE [dbo].[Ranks](
[RankId] [int] IDENTITY(1,1) NOT NULL,
[Rank] [varchar](50) NOT NULL,
[RankNode] [hierarchyid] NOT NULL,
[RankLevel] [smallint] NOT NULL,
[ParentRankId] [int] -- this is redundant but we will use this to compare
-- with parent/child
) ON [PRIMARY]
GO
CREATE UNIQUE NONCLUSTERED INDEX [IX_RankId] ON [dbo].[Ranks]
(
[RankId] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO
CREATE UNIQUE CLUSTERED INDEX [IX_RankNode] ON [dbo].[Ranks]
(
[RankNode] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO
CREATE TABLE [dbo].[Crew](
[CrewId] [int] IDENTITY(1,1) NOT NULL,
[CrewName] [varchar](50) NOT NULL,
[DateHired] [date] NOT NULL,
[RankId] [int] NOT NULL,
[VesselId] [int] NOT NULL,
CONSTRAINT [PK_Crew] PRIMARY KEY CLUSTERED
(
[CrewId] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
ALTER TABLE [dbo].[Crew] WITH CHECK ADD CONSTRAINT [FK_Crew_Ranks] FOREIGN KEY([RankId])
REFERENCES [dbo].[Ranks] ([RankId])
GO
ALTER TABLE [dbo].[Crew] CHECK CONSTRAINT [FK_Crew_Ranks]
GO
ALTER TABLE [dbo].[Crew] WITH CHECK ADD CONSTRAINT [FK_Crew_Vessel] FOREIGN KEY([VesselId])
REFERENCES [dbo].[Vessel] ([VesselId])
GO
ALTER TABLE [dbo].[Crew] CHECK CONSTRAINT [FK_Crew_Vessel]
GOVkládání dat tabulky pomocí SQL Server HierarchyID
Prvním úkolem při důkladném používání hierarchieID je přidat záznamy do tabulky shierarchyID sloupec. Existují dva způsoby, jak to udělat.
Používání řetězců
Nejrychlejším způsobem, jak vložit data pomocí hierarchieID, je použití řetězců. Chcete-li to vidět v akci, přidejte několik záznamů do hodnocení tabulka.
INSERT INTO dbo.Ranks
([Rank], RankNode, RankLevel)
VALUES
('Captain', '/',0)
,('First Officer','/1/',1)
,('Chief Engineer','/2/',1)
,('Hotel Director','/3/',1)
,('Second Officer','/1/1/',2)
,('Second Engineer','/2/1/',2)
,('F&B Manager','/3/1/',2)
,('Chief Housekeeping','/3/2/',2)
,('Chief Purser','/3/3/',2)
,('Casino Manager','/3/4/',2)
,('Cruise Director','/3/5/',2)
,('Third Officer','/1/1/1/',3)
,('Third Engineer','/2/1/1/',3)
,('Asst. F&B Manager','/3/1/1/',3)
,('Asst. Chief Housekeeping','/3/2/1/',3)
,('First Purser','/3/3/1/',3)
,('Asst. Casino Manager','/3/4/1/',3)
,('Music Director','/3/5/1/',3)
,('Asst. Cruise Director','/3/5/2/',3)
,('Youth Staff Director','/3/5/3/',3)Výše uvedený kód přidá 20 záznamů do tabulky Ranks.
Jak můžete vidět, stromová struktura byla definována v INSERT prohlášení výše. Je to snadno rozpoznatelné, když používáme struny. Kromě toho jej SQL Server převede na odpovídající hexadecimální hodnoty.
Použití Max(), GetAncestor() a GetDescendant()
Použití řetězců vyhovuje úkolu naplnění počátečních dat. Z dlouhodobého hlediska potřebujete kód, aby zvládl vkládání bez zadávání řetězců.
Chcete-li provést tento úkol, získejte poslední uzel používaný rodičem nebo předkem. Toho dosáhneme pomocí funkcí MAX() a GetAncestor() . Viz ukázkový kód níže:
-- add a bartender rank reporting to the Asst. F&B Manager
DECLARE @MaxNode HIERARCHYID
DECLARE @ImmediateSuperior HIERARCHYID = 0x7AD6
SELECT @MaxNode = MAX(RankNode) FROM dbo.Ranks r
WHERE r.RankNode.GetAncestor(1) = @ImmediateSuperior
INSERT INTO dbo.Ranks
([Rank], RankNode, RankLevel)
VALUES
('Bartender', @ImmediateSuperior.GetDescendant(@MaxNode,NULL),
@ImmediateSuperior.GetDescendant(@MaxNode, NULL).GetLevel())Níže jsou body převzaté z výše uvedeného kódu:
- Nejprve potřebujete proměnnou pro poslední uzel a bezprostředního nadřízeného.
- Poslední uzel lze získat pomocí MAX() proti RankNode pro uvedeného rodiče nebo přímého nadřízeného. V našem případě je to asistent F&B Manager s hodnotou uzlu 0x7AD6.
- Dále, abyste zajistili, že se neobjeví žádné duplicitní dítě, použijte @ImmediateSuperior.GetDescendant(@MaxNode, NULL) . Hodnota v @MaxNode je poslední dítě. Pokud není NULL , GetDescendant() vrátí další možnou hodnotu uzlu.
- Poslední, GetLevel() vrátí úroveň nově vytvořeného uzlu.
Dotazování na data
Po přidání záznamů do naší tabulky je čas na dotaz. K dispozici jsou 2 způsoby dotazování na data:
Dotaz na přímé potomky
Když hledáme zaměstnance přímo podřízené manažerovi, potřebujeme vědět dvě věci:
- Hodnota uzlu správce nebo rodiče
- Úroveň zaměstnance pod manažerem
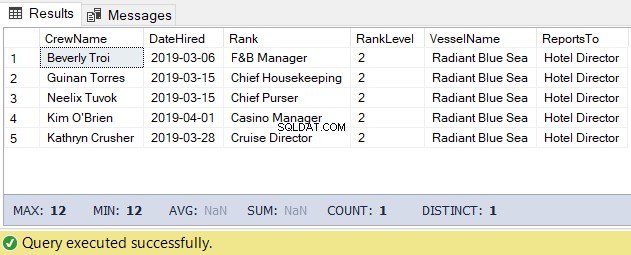
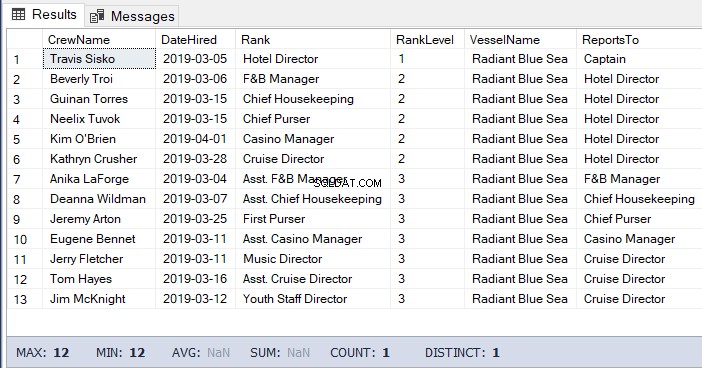
Pro tento úkol můžeme použít níže uvedený kód. Výstupem je seznam posádky pod vedením ředitele hotelu.
-- Get the list of crew directly reporting to the Hotel Director
DECLARE @Node HIERARCHYID = 0x78 -- the Hotel Director's node/hierarchyid
DECLARE @Level SMALLINT = @Node.GetLevel()
SELECT
a.CrewName
,a.DateHired
,b.Rank
,b.RankLevel
,c.VesselName
,(SELECT Rank FROM dbo.Ranks WHERE RankNode = b.RankNode.GetAncestor(1)) AS ReportsTo
FROM dbo.Crew a
INNER JOIN dbo.Ranks b ON a.RankId = b.RankId
INNER JOIN dbo.Vessel c ON a.VesselId = c.VesselId
WHERE b.RankNode.IsDescendantOf(@Node)=1
AND b.RankLevel = @Level + 1 -- add 1 for the level of the crew under the
-- Hotel DirectorVýsledek výše uvedeného kódu je na obrázku 5 následující:
Dotaz na podstromy
Někdy je také potřeba uvést děti a jejich děti až na konec. K tomu potřebujete mít hierarchiiID rodiče.
Dotaz bude podobný předchozímu kódu, ale bez nutnosti získat úroveň. Viz příklad kódu:
-- Get the list of the crew under the Hotel Director down to the lowest level
DECLARE @Node HIERARCHYID = 0x78 -- the Hotel Director's node/hierarchyid
SELECT
a.CrewName
,a.DateHired
,b.Rank
,b.RankLevel
,c.VesselName
,(SELECT Rank FROM dbo.Ranks WHERE RankNode = b.RankNode.GetAncestor(1)) AS ReportsTo
FROM dbo.Crew a
INNER JOIN dbo.Ranks b ON a.RankId = b.RankId
INNER JOIN dbo.Vessel c ON a.VesselId = c.VesselId
WHERE b.RankNode.IsDescendantOf(@Node)=1Výsledek výše uvedeného kódu:
Přesun uzlů pomocí SQL Server HierarchyID
Další standardní operací s hierarchickými daty je přesunutí potomka nebo celého podstromu k jinému rodiči. Než však budeme pokračovat, všimněte si jednoho možného problému:
Potenciální problém
- Za prvé, přesun uzlů zahrnuje I/O. Jak často přesouváte uzly, může být rozhodujícím faktorem, pokud použijete hierarchiiID nebo obvyklý rodič/dítě.
- Zadruhé, přesunutí uzlu v nadřazeném/podřízeném návrhu aktualizuje jeden řádek. Současně, když přesunete uzel s hierarchiíID, aktualizuje se jeden nebo více řádků. Počet ovlivněných řádků závisí na hloubce úrovně hierarchie. Může se změnit ve významný problém s výkonem.
Řešení
Tento problém můžete vyřešit pomocí návrhu databáze.
Podívejme se na design, který jsme zde použili.
Místo definování hierarchie na posádce tabulky, definovali jsme ji v Hodnocích stůl. Tento přístup se liší od zaměstnance tabulky v AdventureWorks ukázkovou databázi a nabízí následující výhody:
- Členové posádky se pohybují častěji než pozice na plavidle. Tento návrh sníží pohyby uzlů v hierarchii. V důsledku toho minimalizuje výše definovaný problém.
- Definování více než jedné hierarchie v posádce tabulka je složitější, protože dvě plavidla potřebují dva kapitány. Výsledkem jsou dva kořenové uzly.
- Pokud potřebujete zobrazit všechny hodnosti s odpovídajícím členem posádky, můžete použít LEVÉ PŘIPOJENÍ. Pokud není nikdo na palubě pro danou pozici, zobrazí se prázdný slot pro danou pozici.
Nyní přejděme k cíli této části. Přidejte podřízené uzly pod nesprávné rodiče.
Chcete-li si představit, co se chystáme udělat, představte si hierarchii, jako je ta níže. Všimněte si žlutých uzlů.

Přesunout uzel bez potomků
Přesunutí podřízeného uzlu vyžaduje následující:
- Definujte ID hierarchie podřízeného uzlu, který se má přesunout.
- Definujte ID hierarchie starého rodiče.
- Definujte ID hierarchie nového rodiče.
- Použijte UPDATE pomocí GetReparentedValue() fyzicky přesunout uzel.
Začněte přesunutím uzlu bez potomků. V níže uvedeném příkladu přesouváme personál plavby z pozice ředitele plavby do pozice asistenta. Cruise Director.
-- Moving a node with no child node
DECLARE @NodeToMove HIERARCHYID
DECLARE @OldParent HIERARCHYID
DECLARE @NewParent HIERARCHYID
SELECT @NodeToMove = r.RankNode
FROM dbo.Ranks r
WHERE r.RankId = 24 -- the cruise staff
SELECT @OldParent = @NodeToMove.GetAncestor(1)
SELECT @NewParent = r.RankNode
FROM dbo.Ranks r
WHERE r.RankId = 19 -- the assistant cruise director
UPDATE dbo.Ranks
SET RankNode = @NodeToMove.GetReparentedValue(@OldParent,@NewParent)
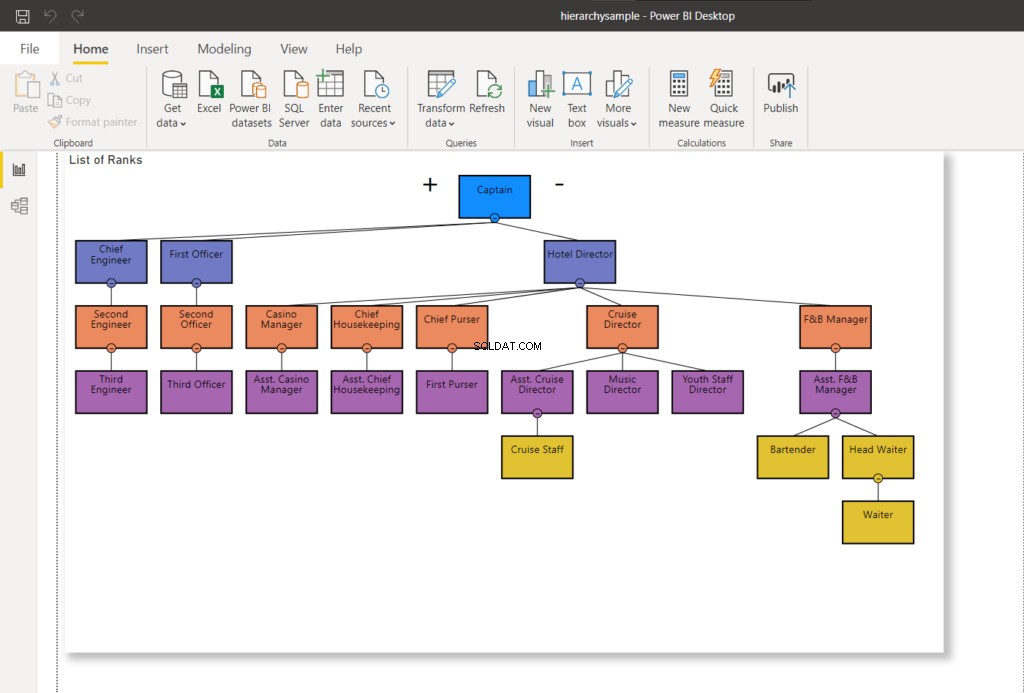
WHERE RankNode = @NodeToMoveJakmile je uzel aktualizován, bude pro uzel použita nová hexadecimální hodnota. Obnovení připojení Power BI k serveru SQL Server – změní se schéma hierarchie, jak je uvedeno níže:
Na obrázku 8 se personál plavby již nehlásí řediteli plavby – změní se na hlášení asistentovi ředitele plavby. Porovnejte to s obrázkem 7 výše.
Nyní přejdeme k další fázi a přesuneme hlavního číšníka na asistenta F&B Manager.
Přesunout uzel s dětmi
V této části je výzva.
Jde o to, že předchozí kód nebude fungovat s uzlem ani s jedním potomkem. Pamatujeme si, že přesunutí uzlu vyžaduje aktualizaci jednoho nebo více podřízených uzlů.
Dále, tím to nekončí. Pokud má nový rodič existujícího potomka, můžeme narazit na duplicitní hodnoty uzlů.
V tomto příkladu musíme tomuto problému čelit:Asst. F&B Manager má podřízený uzel Bartender.
připraveni? Zde je kód:
-- Move a node with at least one child
DECLARE @NodeToMove HIERARCHYID
DECLARE @OldParent HIERARCHYID
DECLARE @NewParent HIERARCHYID
SELECT @NodeToMove = r.RankNode
FROM dbo.Ranks r
WHERE r.RankId = 22 -- the head waiter
SELECT @OldParent = @NodeToMove.GetAncestor(1) -- head waiter's old parent
--> asst chief housekeeping
SELECT @NewParent = r.RankNode
FROM dbo.Ranks r
WHERE r.RankId = 14 -- the assistant f&b manager
DECLARE children_cursor CURSOR FOR
SELECT RankNode FROM dbo.Ranks r
WHERE RankNode.GetAncestor(1) = @OldParent;
DECLARE @ChildId hierarchyid;
OPEN children_cursor
FETCH NEXT FROM children_cursor INTO @ChildId;
WHILE @@FETCH_STATUS = 0
BEGIN
START:
DECLARE @NewId hierarchyid;
SELECT @NewId = @NewParent.GetDescendant(MAX(RankNode), NULL)
FROM dbo.Ranks r WHERE RankNode.GetAncestor(1) = @NewParent; -- ensure
--to get a new id in case there's a
--sibling
UPDATE dbo.Ranks
SET RankNode = RankNode.GetReparentedValue(@ChildId, @NewId)
WHERE RankNode.IsDescendantOf(@ChildId) = 1;
IF @@error <> 0 GOTO START -- On error, retry
FETCH NEXT FROM children_cursor INTO @ChildId;
END
CLOSE children_cursor;
DEALLOCATE children_cursor;Ve výše uvedeném příkladu kódu začíná iterace jako potřeba přenést uzel dolů do potomka na poslední úrovni.
Po jeho spuštění se zobrazí Hodnoky tabulka bude aktualizována. A znovu, pokud chcete změny vidět vizuálně, aktualizujte sestavu Power BI. Uvidíte změny podobné té níže:
Výhody používání SQL Server HierarchyID vs. rodič/dítě
Abychom někoho přesvědčili, aby nějakou funkci používal, potřebujeme znát její výhody.
V této části tedy porovnáme tvrzení pomocí stejných tabulek, jako jsou ty ze začátku. Jeden bude používat hierarchiiID a druhý bude používat přístup rodič/dítě. Výsledná sada bude pro oba přístupy stejná. Očekáváme to pro toto cvičení jako to zobrázku 6 výše.
Nyní, když jsou požadavky přesné, pojďme důkladně prozkoumat výhody.
Jednodušší kód
Viz kód níže:
-- List down all the crew under the Hotel Director using hierarchyID
SELECT
a.CrewName
,a.DateHired
,b.Rank
,b.RankLevel
,c.VesselName
,d.RANK AS ReportsTo
FROM dbo.Crew a
INNER JOIN dbo.Vessel c ON a.VesselId = c.VesselId
INNER JOIN dbo.Ranks b ON a.RankId = b.RankId
INNER JOIN dbo.Ranks d ON d.RankNode = b.RankNode.GetAncestor(1)
WHERE a.VesselId = 1
AND b.RankNode.IsDescendantOf(0x78)=1Tento příklad potřebuje pouze hodnotu hierarchieID. Hodnotu můžete libovolně změnit, aniž byste změnili dotaz.
Nyní porovnejte příkaz pro rodičovský/podřízený přístup, který vytváří stejnou sadu výsledků:
-- List down all the crew under the Hotel Director using parent/child
SELECT
a.CrewName
,a.DateHired
,b.Rank
,b.RankLevel
,c.VesselName
,d.Rank AS ReportsTo
FROM dbo.Crew a
INNER JOIN dbo.Vessel c ON a.VesselId = c.VesselId
INNER JOIN dbo.Ranks b ON a.RankId = b.RankId
INNER JOIN dbo.Ranks d ON b.RankParentId = d.RankId
WHERE a.VesselId = 1
AND (b.RankID = 4) OR (b.RankParentID = 4 OR b.RankParentId >= 7)Co myslíš? Ukázky kódu jsou až na jeden bod téměř stejné.
KDE klauzule ve druhém dotazu nebude flexibilní pro přizpůsobení, pokud je vyžadován jiný podstrom.
Udělejte druhý dotaz dostatečně obecný a kód bude delší. Jejda!
Rychlejší provedení
Podle Microsoftu jsou „dotazy podstromu výrazně rychlejší s hierarchií ID“ ve srovnání s nadřazeným/podřízeným. Podívejme se, jestli je to pravda.
Používáme stejné dotazy jako dříve. Jedním z důležitých ukazatelů výkonu, který lze použít, je logická čtení z SET STATISTICS IO . Říká, kolik stránek o velikosti 8 kB bude SQL Server potřebovat, aby získal požadovanou sadu výsledků. Čím vyšší je hodnota, tím větší je počet stránek, ke kterým SQL Server přistupuje a které čte, a tím pomaleji běží dotaz. Proveďte SET STATISTICS IO ON a znovu spusťte dva výše uvedené dotazy. Nižší hodnota logických čtení bude vítězem.
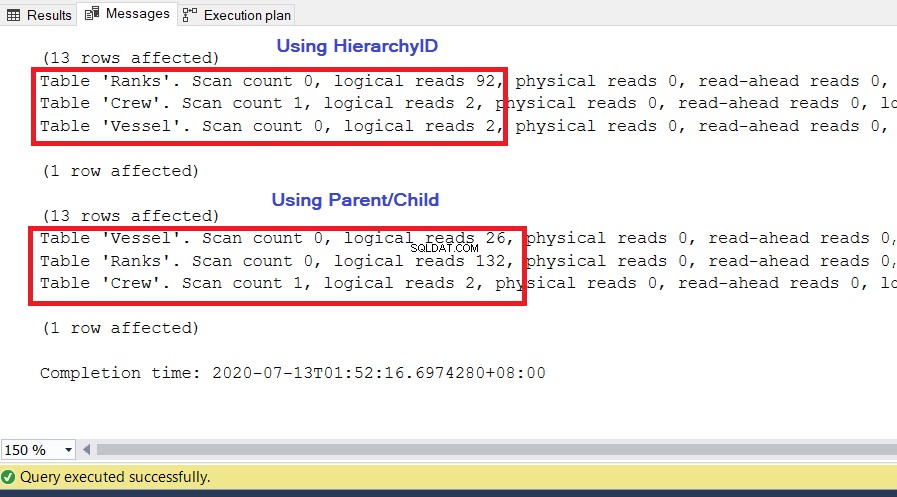
ANALÝZA
Jak můžete vidět na obrázku 10, I/O statistiky pro dotaz s hierarchiíID mají nižší logické čtení než jejich nadřazené/podřízené protějšky. Všimněte si následujících bodů v tomto výsledku:
- Loď tabulka je nejpozoruhodnější ze tří tabulek. Použití hierarchieID vyžaduje pouze 2 * 8 KB =16 KB stránek, které má SQL Server číst z mezipaměti (paměti). Mezitím použití nadřazeného/podřízeného vyžaduje 26 * 8 kB =208 kB stránek – výrazně více než použití hierarchieID.
- Pořadí tabulka, která zahrnuje naši definici hierarchií, vyžaduje 92 * 8 kB =736 kB. Na druhou stranu použití rodič/dítě vyžaduje 132 * 8 kB =1056 kB.
- Posádka tabulka potřebuje 2 * 8KB =16KB, což je stejné pro oba přístupy.
Kilobajty stránek mohou být prozatím malou hodnotou, ale máme jen pár záznamů. Dává nám to však představu o tom, jak náročný bude náš dotaz na jakémkoli serveru. Chcete-li zlepšit výkon, můžete provést jednu nebo více z následujících akcí:
- Přidejte vhodné indexy
- Restrukturalizovat dotaz
- Aktualizovat statistiky
Pokud byste provedli výše uvedené a logická čtení se snížila bez přidání dalších záznamů, výkon by se zvýšil. Dokud uděláte logické čtení nižší než u toho, které používá hierarchiiID, bude to dobrá zpráva.
Ale proč se odkazovat na logická čtení místo na uplynulý čas?
Kontrola uplynulého času pro oba dotazy pomocí možnosti NASTAVIT ČAS STATISTIC ZAPNUTÝ odhaluje malý počet milisekundových rozdílů pro naši malou sadu dat. Také váš vývojový server může mít jinou hardwarovou konfiguraci, nastavení SQL Serveru a zátěž. Uplynulý čas kratší než milisekunda vás může oklamat, pokud váš dotaz funguje tak rychle, jak očekáváte, nebo ne.
KOPÁME DÁL
NASTAVTE STATISTIKY IO ZAPNUTO neodhaluje věci, které se dějí „v zákulisí“. V této části zjistíme, proč SQL Server přichází s těmito čísly, když se podíváme na plán provádění.
Začněme plánem provádění prvního dotazu.
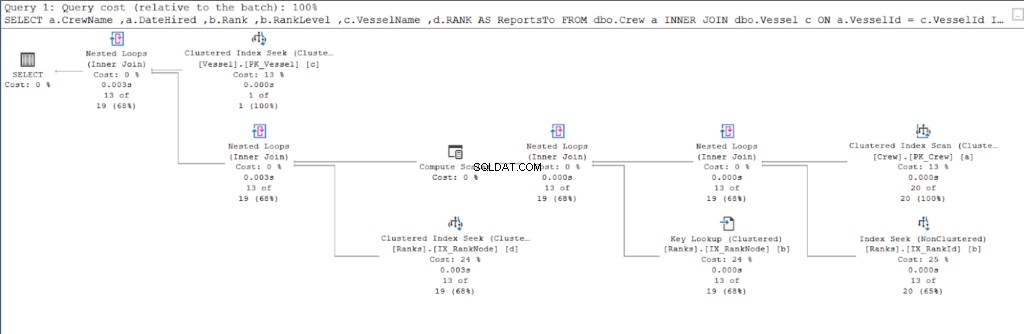
Nyní se podívejte na plán provádění druhého dotazu.
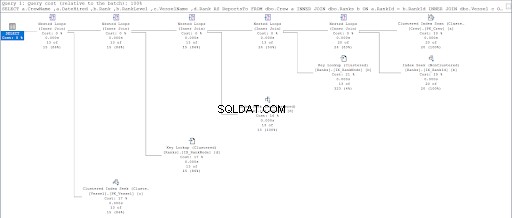
Porovnáním obrázků 11 a 12 vidíme, že SQL Server potřebuje další úsilí, aby vytvořil sadu výsledků, pokud použijete přístup rodič/dítě. KDE klauzule je zodpovědná za tuto komplikaci.
Na vině však může být i provedení stolu. Pro oba přístupy jsme použili stejnou tabulku:Ranks stůl. Pokusil jsem se tedy duplikovat hodnosti tabulky, ale využívají různé seskupené indexy vhodné pro každý postup.
Ve výsledku mělo použití hierarchieID stále méně logických čtení ve srovnání s protějškem nadřazený/podřízený. Nakonec jsme dokázali, že Microsoft měl pravdu, když to tvrdil.
Závěr
Zde jsou hlavní aha momenty pro hierarchiiID:
- HierarchyID je vestavěný datový typ určený pro optimalizovanější reprezentaci stromů, které jsou nejběžnějším typem hierarchických dat.
- Každá položka ve stromu je uzel a hodnoty hierarchieID mohou být v hexadecimálním nebo řetězcovém formátu.
- HierarchyID lze použít pro data organizačních struktur, projektových úkolů, geografických dat a podobně.
- Existují metody pro procházení a manipulaci s hierarchickými daty, jako je GetAcestor (), GetDescendant (). GetLevel (), GetReparentedValue () a další.
- Konvenčním způsobem dotazování na hierarchická data je získat přímé potomky uzlu nebo získat podstromy pod uzlem.
- Použití hierarchieID pro dotazování na podstromy je nejen jednodušší na kódování. Funguje také lépe než rodič/dítě.
Rodičovský/dětský design není vůbec špatný a tento příspěvek ho nemá snižovat. Rozšiřování možností a zavádění nových nápadů je však pro vývojáře vždy velkým přínosem.
Příklady, které jsme zde nabídli, si můžete sami vyzkoušet. Získejte efekty a uvidíte, jak je můžete použít pro svůj další projekt zahrnující hierarchie.
Pokud se vám příspěvek a jeho myšlenky líbí, můžete to šířit dál kliknutím na tlačítka sdílení u preferovaných sociálních médií.