Relační databáze představují data organizace v tabulkách, které používají sloupce s různými datovými typy, které jim umožňují ukládat platné hodnoty. Vývojáři a správci databází potřebují znát a rozumět vhodnému datovému typu pro každý sloupec pro lepší výkon dotazů.
Tento článek se bude zabývat oblíbenými datovými typy VARCHAR() a NVARCHAR(), jejich srovnáním a recenzemi výkonu v SQL Server.
VARCHAR [ ( n | max ) ] v SQL
VARCHAR datový typ představuje neunicode datový typ řetězce proměnné délky. Můžete do něj ukládat písmena, čísla a speciální znaky.
- N představuje velikost řetězce v bajtech.
- Sloupec datového typu VARCHAR ukládá maximálně 8000 znaků mimo Unicode.
- Datový typ VARCHAR zabírá 1 bajt na znak. Pokud explicitně neurčíte hodnotu pro N, zabere to 1bajtové úložiště.
Poznámka:Nezaměňujte N s hodnotou představující počet znaků v řetězci.
Následující dotaz definuje datový typ VARCHAR se 100 bajty dat.
DECLARE @text AS VARCHAR(100) ='VARCHAR data type';
SELECT @text AS Output ,DATALENGTH(@text) AS Length
Vrátí délku 17 kvůli 1 bajtu na znak, včetně znaku mezery.
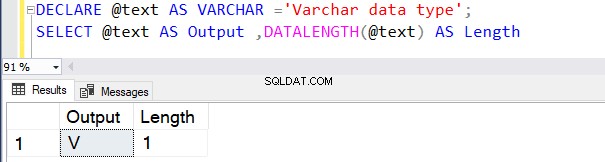
Následující dotaz definuje datový typ VARCHAR bez jakékoli hodnoty N . Proto SQL Server považuje výchozí hodnotu za 1 bajt, jak je uvedeno níže.
DECLARE @text AS VARCHAR ='VARCHAR data type';
SELECT @text AS Output ,DATALENGTH(@text) AS Length
Můžeme také použít VARCHAR pomocí funkce CAST nebo CONVERT. Například ve dvou níže uvedených příkladech jsme deklarovali proměnnou o délce 100 bajtů a později jsme použili operátor CAST.
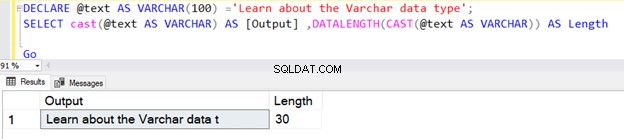
První dotaz vrací délku 30, protože jsme nezadali N v datovém typu VARCHAR operátoru CAST. Výchozí délka je 30.
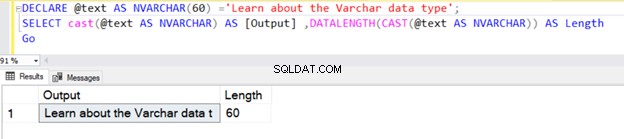
DECLARE @text AS VARCHAR(100) ='Learn about the VARCHAR data type';
SELECT cast(@text AS VARCHAR) AS [Output] ,DATALENGTH(CAST(@text AS VARCHAR)) AS Length
Go
Pokud je však délka řetězce menší než 30, přebírá skutečnou velikost řetězce.

NVARCHAR [ ( n | max ) ] v SQL
NVARCHAR datový typ je pro Unicode datový typ znaku s proměnnou délkou. Zde N odkazuje na znakovou sadu národního jazyka a používá se k definování řetězce Unicode. Můžete uložit znaky, které nejsou Unicode i Unicode (japonské kanji, korejské hangul atd.).
- N představuje velikost řetězce v bajtech.
- Může uložit maximálně 4000 znaků Unicode a Non-Unicode.
- Datový typ VARCHAR zabírá 2 bajty na znak. Pokud pro N nezadáte žádnou hodnotu, zabere to 2 bajty.
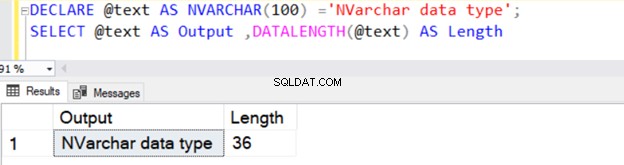
Následující dotaz definuje datový typ VARCHAR se 100 bajty dat.
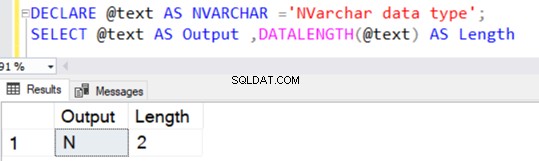
DECLARE @text AS NVARCHAR(100) ='NVARCHAR data type';
SELECT @text AS Output ,DATALENGTH(@text) AS Length
Vrací délku řetězce 36, protože NVARCHAR zabírá 2 bajty na úložiště znaků.
Podobně jako datový typ VARCHAR má NVARCHAR také výchozí hodnotu 1 znak (2 bajty) bez zadání explicitní hodnoty pro N.
Pokud použijeme převod NVARCHAR pomocí funkce CAST nebo CONVERT bez explicitní hodnoty N, výchozí hodnota je 30 znaků, tj. 60 bajtů.
Ukládání hodnot Unicode a Non-Unicode do datového typu VARCHAR
Předpokládejme, že máme tabulku, která zaznamenává zpětnou vazbu zákazníků z e-shopového portálu. Pro tento účel máme SQL tabulku s následujícím dotazem.
CREATE TABLE UserComments
(
ID int IDENTITY (1,1),
[Language] VARCHAR(50),
[comment] VARCHAR(200),
[NewComment] NVARCHAR(200)
)
Do této tabulky vkládáme několik vzorových záznamů v angličtině, japonštině a hindštině. Typ dat pro [Komentář] je VARCHAR a [Nový komentář] je NVARCHAR() .
INSERT INTO UserComments ([Language],[Comment],[NewComment])
VALUES ('English','Hello World', N'Hello World')
INSERT INTO UserComments ([Language],[Comment],[NewComment])
VALUES ('Japanese','こんにちは世界', N'こんにちは世界')
INSERT INTO UserComments ([Language],[Comment],[NewComment])
VALUES ('Hindi','नमस्ते दुनिया', N'नमस्ते दुनिया')
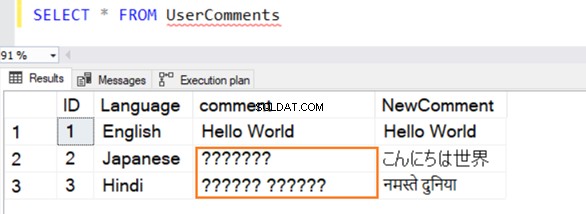
Dotaz se provede úspěšně a při výběru hodnoty z něj zobrazí následující řádky. Pro řádek 2 a 3 nerozpozná data, pokud nejsou v angličtině.
Datové typy VARCHAR a NVARCHAR:Porovnání výkonu
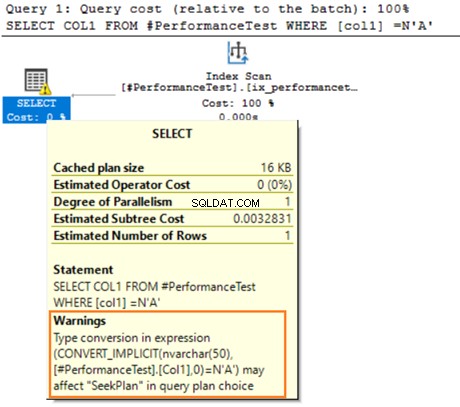
Neměli bychom kombinovat použití datových typů VARCHAR a NVARCHAR v predikátech JOIN nebo WHERE. Zruší platnost stávajících indexů, protože SQL Server vyžaduje stejné datové typy na obou stranách JOIN. SQL Server se v případě neshody pokusí provést implicitní převod pomocí funkce CONVERT_IMPLICIT().
SQL Server používá prioritu datového typu k určení cílového datového typu. NVARCHAR má vyšší prioritu než datový typ VARCHAR. Proto během převodu datového typu SQL Server převede existující hodnoty VARCHAR na NVARCHAR.
CREATE TABLE #PerformanceTest
(
[ID] INT NOT NULL IDENTITY(1, 1) PRIMARY KEY,
[Col1] VARCHAR(50) NOT NULL,
[Col2] NVARCHAR(50) NOT NULL
)
CREATE INDEX [ix_performancetest_col] ON #PerformanceTest (col1)
CREATE INDEX [ix_performancetest_col2] ON #PerformanceTest (col2)
INSERT INTO #PerformanceTest VALUES ('A',N'C')
Nyní provedeme dva příkazy SELECT, které načítají záznamy podle jejich datových typů.
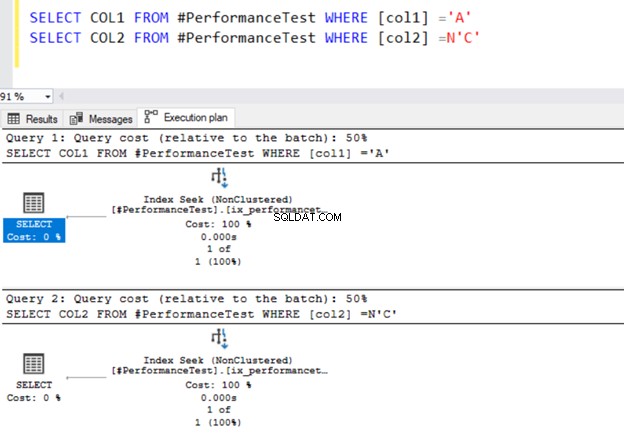
SELECT COL1 FROM #PerformanceTest WHERE [col1] ='A'
SELECT COL2 FROM #PerformanceTest WHERE [col2] =N'C'
Oba dotazy používají operátor hledání indexu a indexy, které jsme definovali dříve.
Nyní přepneme hodnoty datového typu pro porovnání s predikátem WHERE. Sloupec 1 má datový typ VARCHAR, ale specifikujeme N’A’, abychom jej umístili jako datový typ NVARCHAR.
Podobně col2 je datový typ NVARCHAR a my specifikujeme hodnotu ‚C‘, která odkazuje na datový typ VARCHAR.
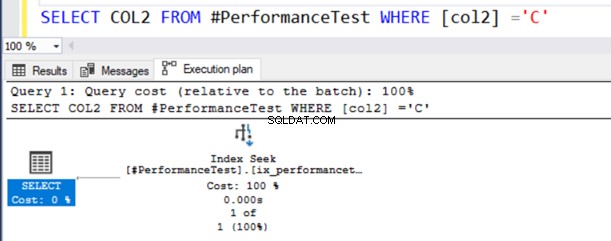
SELECT COL2 FROM #PerformanceTest WHERE [col2] ='C'V plánu skutečného provádění dotazu získáte sken indexu a příkaz SELECT má varovný symbol.
Tento dotaz funguje dobře, protože datový typ NVARCHAR() může mít hodnoty Unicode i jiné než Unicode.
Nyní druhý dotaz používá indexové skenování a zobrazí varovný symbol na operátoru SELECT.
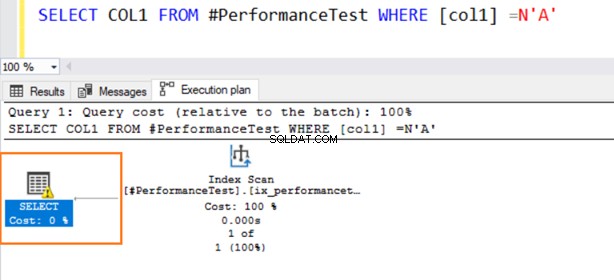
Najeďte myší na příkaz SELECT, který vydá varování o implicitní konverzi. SQL Server nemohl správně použít existující index. Je to kvůli různým algoritmům řazení dat pro datové typy VARCHAR i NVARCHAR.
Pokud má tabulka miliony řádků, SQL Server musí provést další práci a převést data pomocí implicitní konverze dat. Může to negativně ovlivnit výkon vašeho dotazu. Proto byste se při optimalizaci dotazů měli vyvarovat míchání a porovnávání těchto datových typů.
Závěr
Při navrhování databázových tabulek a jejich datových typů sloupců byste měli zkontrolovat své požadavky na data. Obvykle datový typ VARCHAR uspokojuje většinu vašich požadavků na data. Pokud však potřebujete do sloupce uložit datové typy Unicode i jiné než Unicode, můžete zvážit použití NVARCHAR. Než však učiníte konečné rozhodnutí, měli byste si prostudovat jeho dopad na výkon a velikost úložiště.