Úvod
Úložiště dotazů je nová funkce představená v SQL Server 2016, která umožňuje správcům databází historicky kontrolovat dotazy a jejich přidružené plány pomocí GUI dostupného v SQL Server Management Studio a také analyzovat výkon dotazů pomocí určitých pohledů Dynamic Management. Query Store je možnost konfigurace v rozsahu databáze a je k dispozici pro použití, pokud je úroveň kompatibility dané databáze 130.
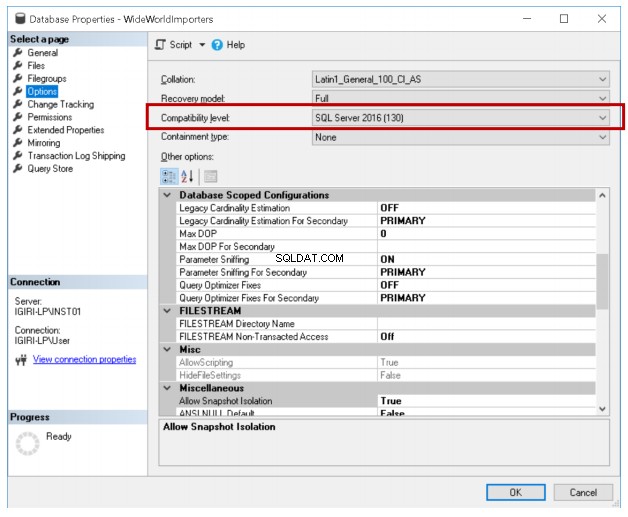
Query Store je podobný technologiím v databázové platformě Oracle jako Automatic Workload Repository (AWR). AWR zachycuje statistiky výkonu v ještě větším měřítku než Query Store a umožňuje správci databáze historicky analyzovat výkon. Koncepty jako doba uchování a limity ukládání shromážděných dat jsou dostupné v architektuře AWR stejně jako v Query Store. Při povolení úložiště dotazů jsou k dispozici následující možnosti konfigurace klíče:
- Provozní režim: Určuje, zda bude Query Store přijímat nově zachycená data (Režim čtení) nebo pouze ukládat stará data dostupná pro sestavy (režim pouze pro čtení)
- Interval vyprázdnění dat: Určuje, jak často jsou vyrovnávací paměti úložiště dotazů vyprázdněny na disk. Připomeňme, že data Query Store jsou uložena v databázi, kde je Query Store povoleno. Výchozí hodnota je 15 minut.
- Interval shromažďování statistik: Určuje, jak často se shromažďují statistiky za běhu úložiště dotazů.
- Maximální velikost: Určuje, jak moc může úložiště statistik Query Store růst. Ve výchozím nastavení je to 100 MB.
- Režim zachycení úložiště dotazů: Určuje granularitu zachycování dotazů. Dostupné možnosti jsou ALL, AUTO a NONE. Výchozí hodnota je AUTO.
- Režim čištění podle velikosti: Určuje, zda úložiště dotazů po dosažení maximální velikosti vyprázdní stará data.
- Práh zastaralého dotazu: Určuje počet dní, po které Query Store uchovává data. Výchozí hodnota je nastavena na třicet dní.
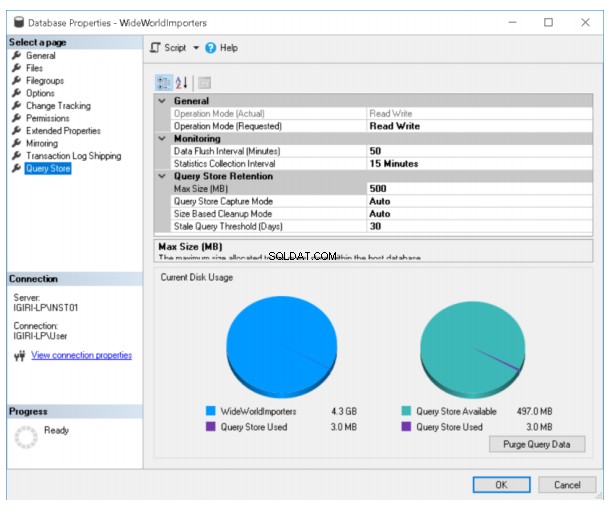
Obr. 2 Možnosti úložiště dotazů
Query store je funkce v rozsahu databáze, kterou lze povolit buď pomocí GUI (SQL Server Management Studio) nebo spuštěním následujícího příkazu:
ALTER DATABASE [WideWorldImporters] SET QUERY_STORE =ON;
Telemetrie dotazů shromážděná službou Query Store je uložena v systémových tabulkách v databázi, kde bylo povoleno úložiště dotazů.
Ukázkové dotazy a výchozí přehledy
Zatím vše, co jsem napsal, je dostupné z mnoha jiných zdrojů; některé z nich lze nalézt v sekci reference.
V této části se podíváme trochu hlouběji na to, co vlastně můžeme dělat s Query Store, jakmile jej povolíme pomocí jednoduchých příkladů. Podívejme se na následující dva dotazy:
Výpis 1:Načítání záznamů pomocí specifického filtru
použijte WideWorldImportersgoselecta.ContactPersonID,a.OrderDate,a.DeliveryMethodID,a.Comments,b.OrderedOutersfromPurchasing.PurchaseOrders ainner join Purchasing.PurchaseOrderLines bon a.PurchaseOrderLines bon a.PurchaseOrderLines bon a.PurchaseOrderLines bonder a.PurchaseOup. před>Výpis 2:Načítání záznamů pomocí rozsahu
použijte WideWorldImportersgoselecta.ContactPersonID,a.OrderDate,a.DeliveryMethodID,a.Comments,b.OrderedOutersfromPurchasing.PurchaseOrders ainner join Purchasing.PurchaseOrderLines bon a.PurchaseOrderLines bon a.Purchase%BurchaseOup. /před>Věnujte pozornost alternativní verzi těchto dotazů psaných velkými písmeny:
Výpis 1:Načítání záznamů pomocí specifického filtru (velká písmena)
POUŽÍVEJTE WIDEWORLDIMPORTERSGOSELECTA.CONTACTPERSONID,A.ORDERDATE,A.DELIVERYMETHODID,A.COMMENTS,B.ORDEREDOUTERSFROMPURCHASING.PURCHASEORDERS AINNER JOIN PURCHASING.PURCHASEORDERLINESORDERLINES=BON A.PURCHASEORDERLINES=ORDERCHORDERLIHEIDRE=před>Výpis 2:Načítání záznamů pomocí rozsahu (velká písmena)
POUŽÍVEJTE WIDEWORLDIMPORTERSGOSELECTA.CONTACTPERSONID,A.ORDERDATE,A.DELIVERYMETHODID,A.COMMENTS,B.ORDEREDOUTERSFROMPURCHASING.PURCHASEORDERS AINNER PŘIPOJTE SE K NÁKUPU.PURCHASEORDERLINESORDERLINES BON A.PURCHASEORDERLINES<0GUIDORDERCHRELI%'; /před>Jak vidíte, spustili jsme tyto dotazy několikrát pomocí klíčového slova GO. Máme tedy nějaké rozumné množství dat, se kterými můžeme pracovat. První věc, kterou bychom si měli být vědomi při používání Query Store k analýze výkonu, je to, že v SQL Server 2016 Query Store je integrováno šest výchozích sestav, jak je znázorněno na obr. 3.
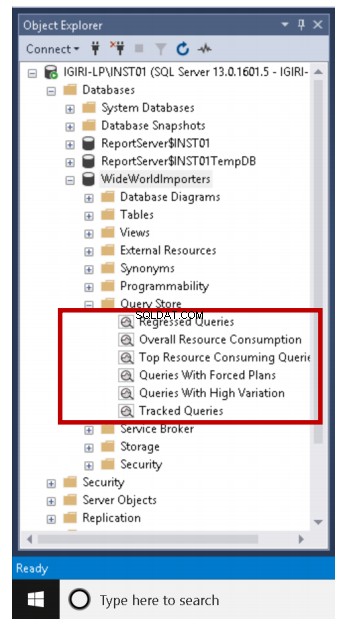
Obr. 3 Přehledy úložiště dotazů
Názvy sestav jsou podrobně popsány v předchozích článcích a také v dokumentaci společnosti Microsoft. Data poskytovaná těmito sestavami jsou získávána z klíčových pohledů dynamické správy uvedených níže:
DMV statistiky plánu
- sys.query_store_query_text – obsahuje jedinečné texty dotazů provedených proti databázi
- sys.query_store_plan – obsahuje odhadovaný plán pro dotaz se statistikou doby kompilace
- sys.query_context_settings – obsahuje některé jedinečné kombinace plánu ovlivňující nastavení, podle kterých jsou dotazy prováděny
- sys.query_store_query – položky dotazů, které jsou sledovány a vynucovány samostatně v úložišti dotazů
DMV statistiky doby běhu
- sys.query_store_runtime_stats_interval – Query Store rozděluje čas do automaticky generovaných časových oken (intervalů) a ukládá agregované statistiky o tomto intervalu pro každý realizovaný plán
- sys.query_store_runtime_stats – obsahuje agregované runtime statistiky pro realizované plány
Mnohem více podrobností o použití těchto DMV je k dispozici v odkazované dokumentaci společnosti Microsoft. V tomto článku budeme jednoduše používat většinou GUI.
Jak můžete vidět na obr. 4, podíváme se na zprávu o celkové spotřebě zdrojů, zatímco v další části se zúžíme na dotazy, které jsme uvedli dříve, a na data, která můžeme z těchto jednoduchých dotazů získat.
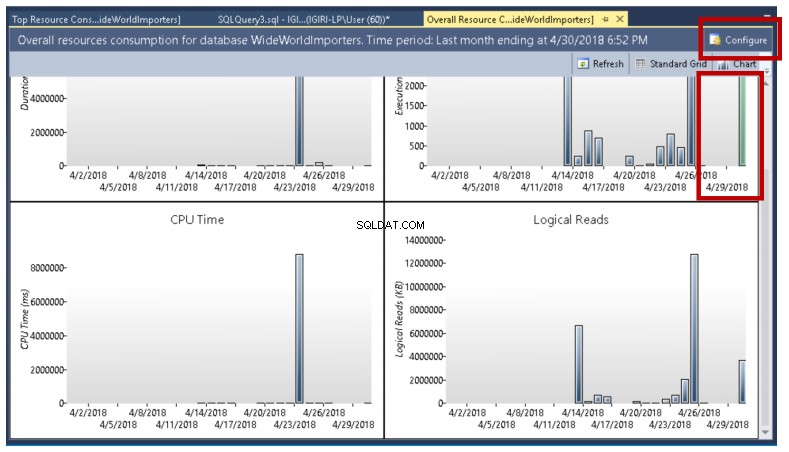
Obr. 4 Zpráva o celkové spotřebě zdrojů
Analýza dotazů pomocí GUI
Při používání přehledů úložiště dotazů by mělo být užitečné považovat několik klíčových věcí:
- Prostředí můžete nakonfigurovat kliknutím na tlačítko zvýrazněné na obr. 4. Obr. 5 nám ukazuje podrobnosti, které můžeme změnit, aby vyhovovaly našemu případu použití:kritéria dat, která mají být vrácena, rozsah dat a sada dat, která se má vrátit. Pokud například chci jasně vidět ID dotazu spojené s dotazy, které kontrolujem, rád bych například zredukoval svůj soubor dat z výchozích 25 nejlepších na 10.
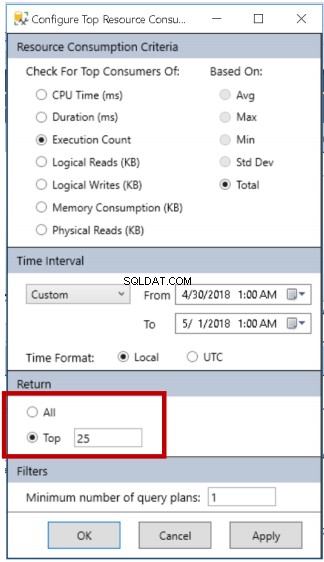
Obr. 5 Možnosti konfigurace sestav
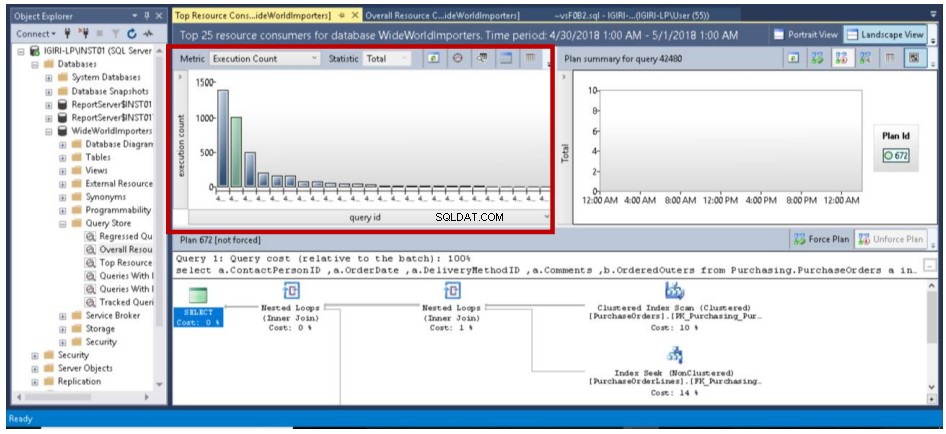
Obr. 6 Top 25 dotazů provedených 1. května 2018
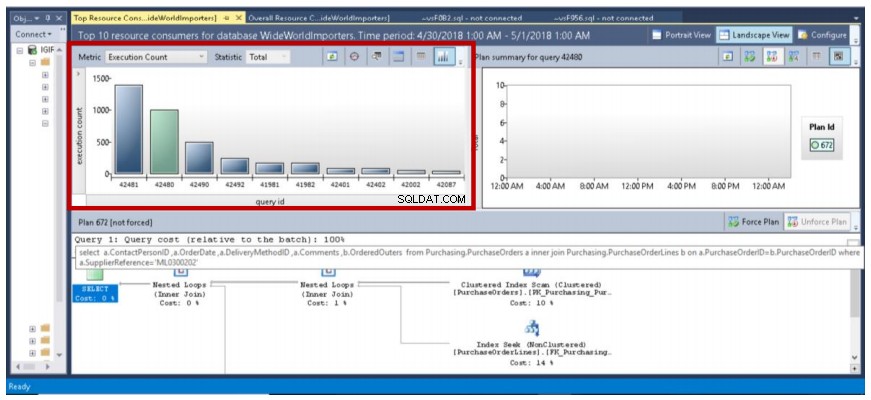
Obr. 7 Top 10 dotazů provedených 1. května 2018
- Sloupcové grafy zobrazují data většinou s časem na ose x, ale můžete si prohlížet data na základě ID dotazů a zobrazit tak konkrétní datový bod. Každé ID dotazu určuje konkrétní dotaz. Je důležité si uvědomit, že dotaz je jednoznačně identifikován pomocí hashování textu. Dotaz v malých písmenech se tedy liší od stejného dotazu ve velkých písmenech. To by mělo být všeobecně známé:ad-hoc dotazy se týkají mezipaměti plánu a jsou také špatné pro úložiště dotazů, a to jak z hlediska využití prostoru, tak z hlediska správné analýzy.
Obr. 8 Dotaz ve výpisu 1 (malá písmena, dotaz 42480)
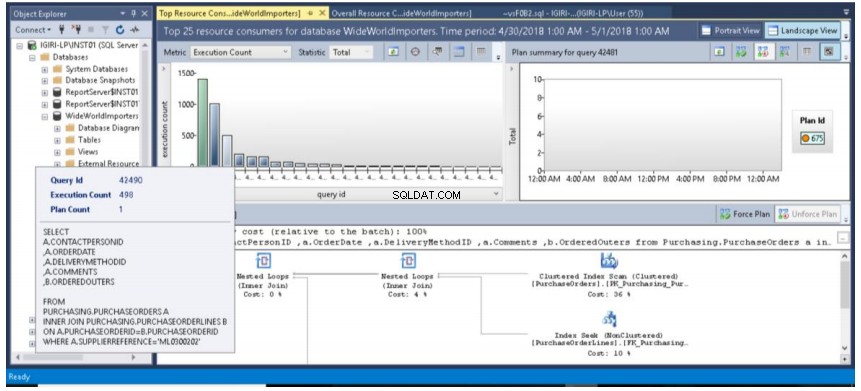
Obr. 9 Dotaz ve výpisu 3 (velká písmena, dotaz 42490)
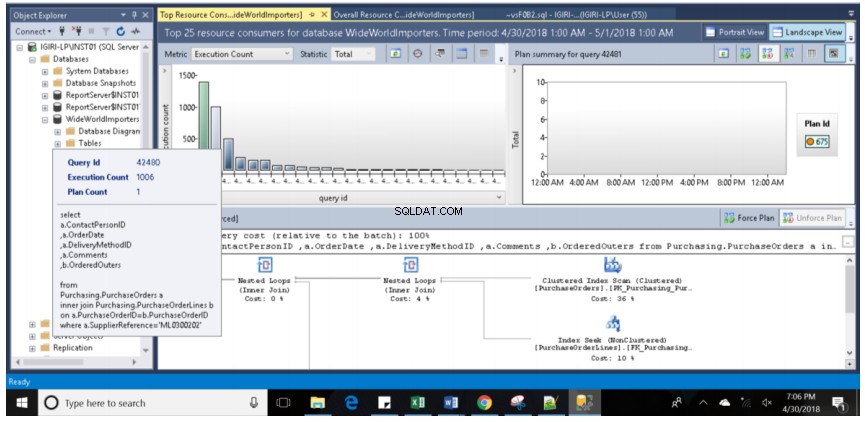
- Třetím důležitým zjištěním je skutečnost, že když je datový bod zvýrazněn zeleně, podrobný plán provádění zobrazený ve spodním panelu se vztahuje k tomuto datovému bodu. Na obr. 7 se tento datový bod vztahuje k dotazu ID 42481, který jsme dříve provedli (úplný dotaz je uveden ve výpisu 2). Po najetí myší na tento datový bod se zobrazí dotaz, jeho ID a počet plánů souvisejících s tímto dotazem (viz obr. 8).
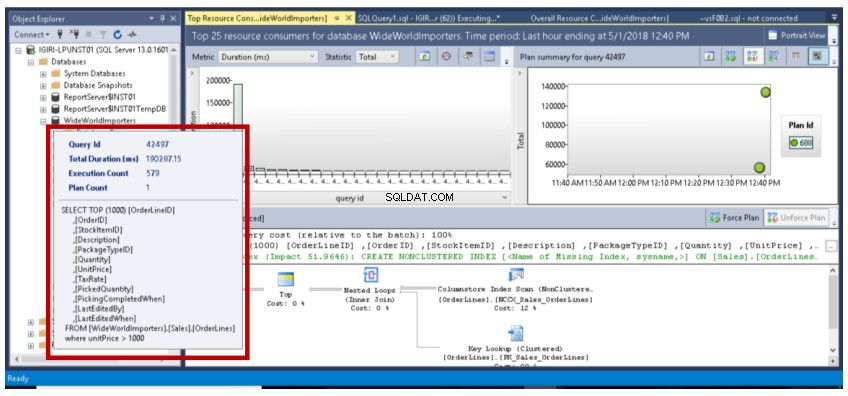
Obr. 10 Podrobnosti dotazu 42481
Náš dotaz byl proveden 1391krát, protože je přesně zachycen úložištěm dotazů a zobrazen na ose y (počet provedení) sloupcového grafu na obr. 10. Sestava se stahovala, zatímco se dávka stále spouštěla. Nemáme tedy úplný počet (1500), který by nás informoval o tom, že při každém provedení dotazu dochází k zachycení dat v reálném čase. Na pravé straně také vidíme plán používaný pro tato vícenásobná provedení (Plán 675). Můžeme to ověřit pomocí dotazu ve výpisu 5.
Zápis 5
POUŽÍVEJTE WideWorldImportersGOSELECT Txt.query_text_id, Txt.query_sql_text, Pl.plan_id, Qry.*FROM sys.query_store_plan AS PlJOIN sys.query_store_query AS Qry ON Pl.query_id =Qry.query_idJOIN_textry.sys Txt ASt .query_text_idwhere Qry.query_id=42481;
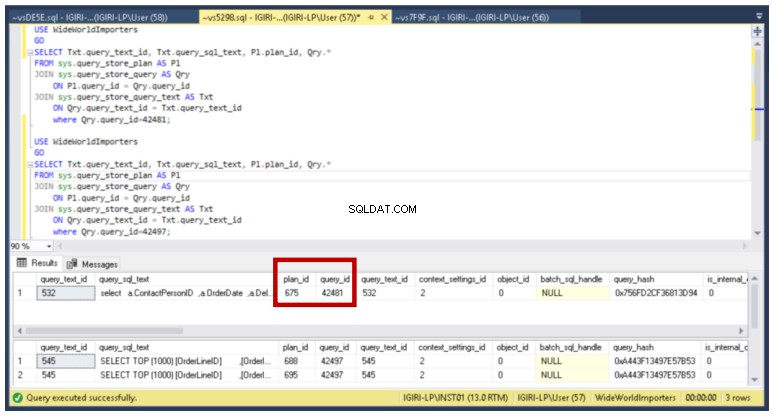
Obr. 11 ID dotazu a ID plánu z DMV
Trocha ladění
Podívejme se na další dotaz.
Když spustíme dotaz ve výpisu 6 a prozkoumáme podrobnosti z Query Store, podrobnosti plánu provádění odhalí, že potřebujeme index, abychom dosáhli 51% zlepšení.
Výpis 6:Neoptimální dotaz
SELECT TOP (1000) [OrderLineID] ,[OrderLineID] ,[StockItemID] ,[Popis] ,[PackageTypeID] ,[Quantity] ,[JednotkováCena] ,[Daňová sazba] ,[Vybrané množství] ,[PickedQuantity] ,[Picked]EditedBCompleting ] ,[LastEditedWhen] OD [WideWorldImporters].[Sales].[OrderLines] where unitPrice> 1000 GO 2000
Obr. 12 Sub-optimální podrobnosti dotazu
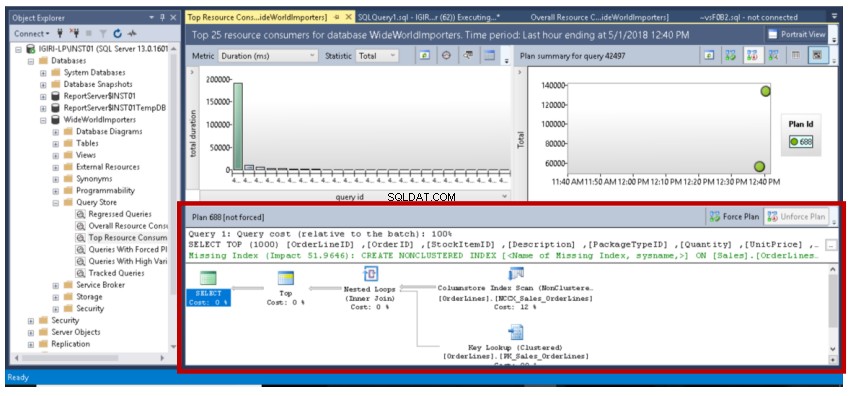
Obr. 13 Suboptimální plán provádění dotazu
Jakmile vytvoříme doporučený index pomocí příkazu ve výpisu 7, způsobíme, že Optimalizátor dotazů vygeneruje nový plán provádění. V tomto případě se očekává, že nový plán provádění zlepší výkon. Existují však případy, kdy určité změny mohou způsobit snížení výkonu, jako jsou významné změny v objemu dat, které účinně znehodnocují statistiky nebo snižují počet indexů a tak dále. U takových dotazů se říká, že došlo k poklesu výkonu a lze je prozkoumat pomocí sestavy Regresed Queries v Query Store.
Výpis 7:Vytvoření indexu
POUŽÍVEJTE [WideWorldImporters]VYTVOŘTE NEZAHRNUTÝ INDEX [Custom_IX_UnitPrice]NA [Sales].[OrderLines] ([UnitPrice])INCLUDE([OrderLineID],[ID objednávky],[ID položky skladu],[ageTQy],[Packity],[Pack ],[TaxRate],[PickedQuantity],[PickingCompletedWhen],[LastEditedBy],[LastEditedWhen])GO
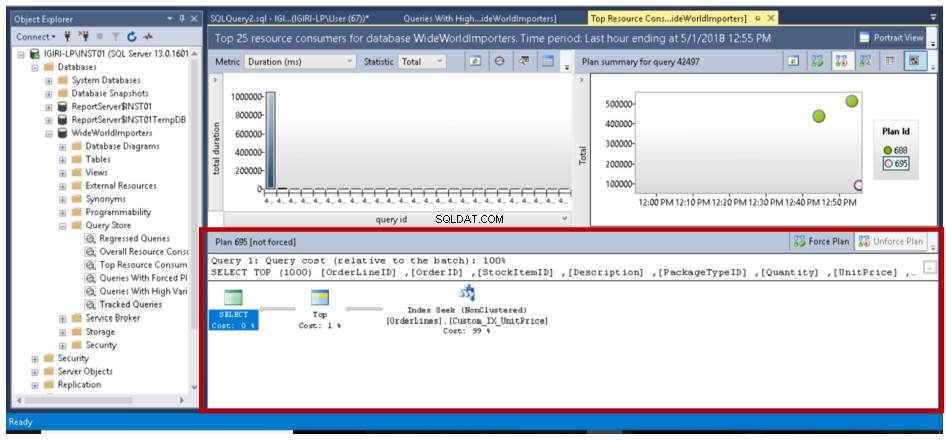
Obr. 14 Optimalizovaný dotaz (změna prováděcího plánu)
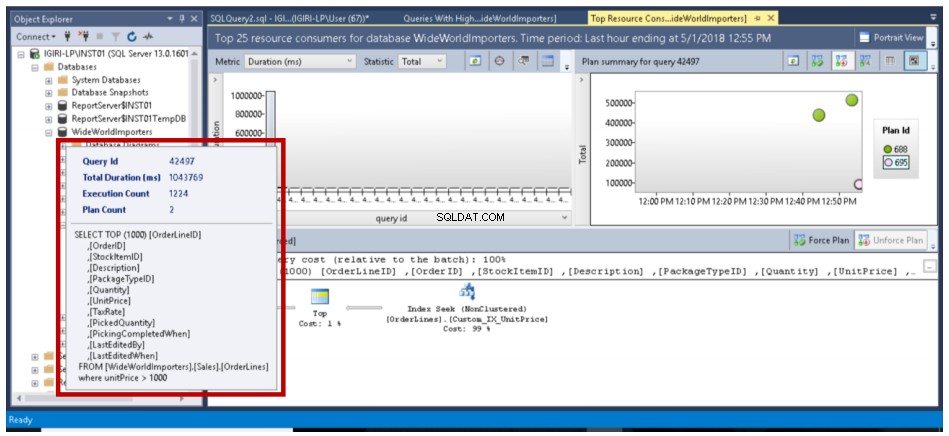
Obr. 15 Optimalizovaný dotaz (dva plány)
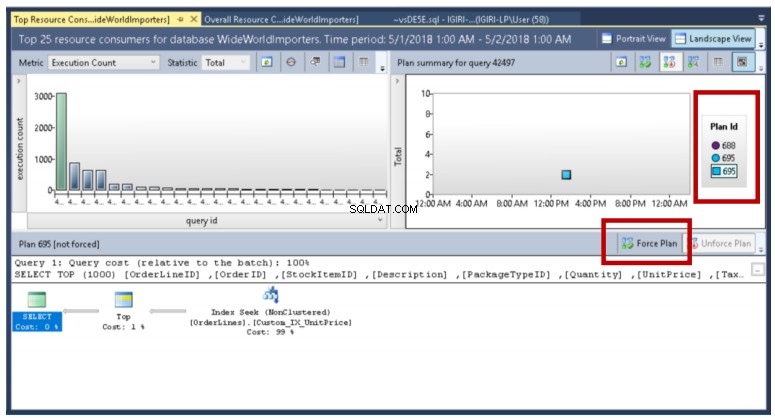
Obr. 16 Optimalizovaný dotaz (Force Plan)
Pokud existuje více plánů pro dotaz, jak je znázorněno na obr. 14 a obr. 16, můžeme optimalizátoru říci, aby vždy použil plán, který si zvolíme, kliknutím na tlačítko Force Plan. V předchozích verzích SQL Server to byl trochu nudný úkol.
Jak můžete vidět na obr. 17, Query Store nám umožňuje porovnávat různé plány spojené s dotazem pomocí řady metrik.
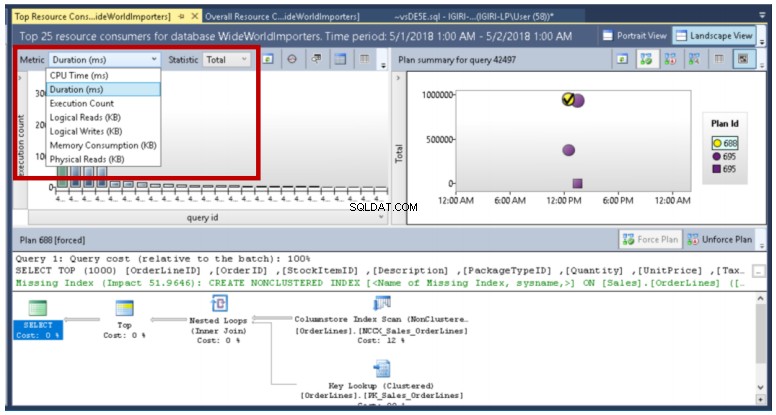
Obr. 17 Porovnání prováděcích plánů
Opět můžeme použít dotaz ve výpisu 8 k ověření plánů spojených s tímto ID dotazu pomocí DMV. (Viz obr. 11)
Výpis 8:Plány spojené s dotazem 42497
POUŽÍVEJTE WideWorldImportersGOSELECT Txt.query_text_id, Txt.query_sql_text, Pl.plan_id, Qry.*FROM sys.query_store_plan AS PlJOIN sys.query_store_query AS Qry ON Pl.query_id =Qry.query_idJOIN_textry.sys Txt ASt .query_text_idwhere Qry.query_id=42497;
Zkoumání variant
Další užitečnou sestavou, kterou nám Query Store využívá, jsou dotazy s vysokou variací. Tento přehled nám ukazuje, jak daleko jsou od sebe požadované metriky pro konkrétní dotaz za dané období. To je velmi užitečné pro historickou analýzu výkonu. Pomocí příkazů ve výpisu 9 generujeme data, která mohou poskytnout obrázek o tom, jak by varianty vypadaly. Kroky v postupu jednoduše vytvoří malou tabulku a poté vloží záznamy pomocí různých velikostí dávek.
Výpis 9:Plány spojené s dotazem 42497
use WideWorldImportersgo-- Vytvořte Tablecreate tabulku tableone(ID int identity(1000,1),FirstName varchar(30),LastName varchar(30),CountryCode char(2),HireDate datetime2 default getdate());-- Vložit záznamy do dávek různých velikostívložit do hodnot tabulky ('Kenneth','Igiri','NG',getdate());GO 10000vložit do hodnot tabulky ('Kwame','Boateng','GH', getdate());GO 10insert into tableone values ('Philip','Onu','NG',getdate());GO 100000insert into tableone values ('Kwesi','Armah','GH', getdate());GO 100
Query Store nám ukazuje podrobnosti, jako jsou minimální a maximální hodnoty těchto metrik pro konkrétní intervaly provádění dotazu, který nás zajímá. V tomto příkladu zjistíme, že je to jednoduše výsledek počtu dávek na provedení (všimněte si, že parametry se ve skutečnosti používají k provedení příkazu INSERT). Ve výrobě mohou být za takové odchylky zodpovědné jiné faktory.
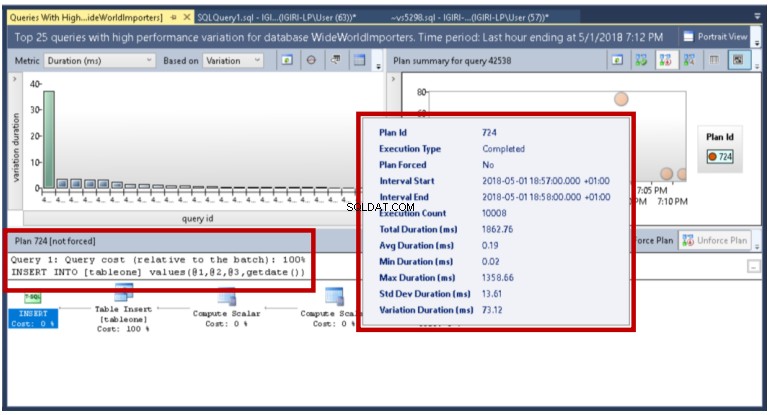
Obr. 18 Variace v trvání
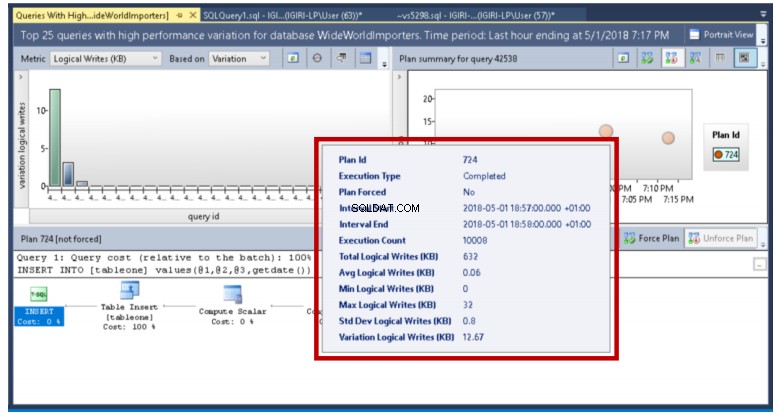
Obr. 19 Variace v logických zápisech
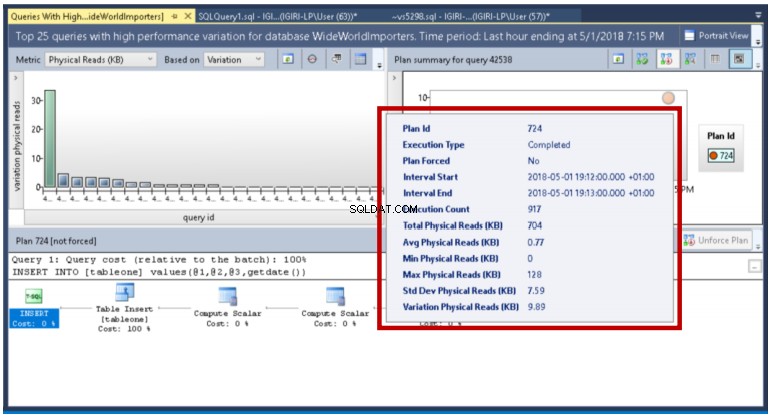
Obr. 20 Variace ve fyzickém čtení
Závěr
V tomto článku jsme zkontrolovali GUI prostředí SQL Server 2016 Query Store a několik věcí, které můžeme odvodit ohledně výkonu naší instance (s ohledem na SQL) pomocí Query Store. Na internetu je několik článků, které ukazují ještě pokročilejší případy použití a mnohem hlubší vysvětlení vnitřností. Tento článek by se měl hodit administrátorům střední úrovně, kteří chtějí získat náskok při používání Query Store pro hodnocení/ladění výkonu.
Odkazy
- Doporučený postup s obchodem s dotazy
- Cristiman, L. (2016) Query Store – Settings and Limits
- Monitorování výkonu pomocí úložiště dotazů
- Dotaz na zobrazení katalogu obchodu
- Dotaz na uložené procedury
- Dotazník – jak funguje a jak jej používat
- Scénáře použití obchodu s dotazy
- Van de Lar, E. (2016) Úložiště dotazů SQL Server 2016:Vynucení plánů provádění pomocí úložiště dotazů
Užitečný nástroj:
dbForge Query Builder pro SQL Server – umožňuje uživatelům rychle a snadno vytvářet složité SQL dotazy prostřednictvím intuitivního vizuálního rozhraní bez ručního psaní kódu.