Úvod do indexů SQL Server
Microsoft SQL Server je považován za jeden ze systémů správy relačních databází (RDBMS ), ve kterém jsou data logicky uspořádána do řádků a sloupců, které jsou uloženy v datových kontejnerech nazývaných tabulky. Fyzicky jsou tabulky uloženy jako stránky o velikosti 8 kB které lze organizovat do tabulek Heap nebo B-Tree Clustered. V Hromadě tabulka, neexistuje žádné pořadí řazení, které řídí pořadí dat uvnitř datových stránek a pořadí stránek v této tabulce, protože v této tabulce není definován žádný klastrovaný index, který by vynucoval mechanismus řazení. Pokud je klastrovaný index definován v jednom sloupci ze skupiny sloupců tabulky, data budou setříděna uvnitř datových stránek na základě hodnot sloupců klastrového indexového klíče a stránky budou propojeny na základě těchto hodnot indexového klíče. Tato seřazená tabulka se nazývá Clusterová tabulka .
V SQL Server je index považován za důležitý a účinný klíč v procesu ladění výkonu. Účelem vytvoření indexu je urychlit přístup k základní tabulce a načíst požadovaná data, aniž by bylo nutné skenovat všechny řádky tabulky pro vrácení požadovaných dat. Databázový rejstřík si můžete představit jako rejstřík knih, který vám pomůže rychle najít slova v knize, aniž byste museli číst celou knihu, abyste toto slovo našli. Předpokládejme například, že potřebujete získat informace o konkrétním zákazníkovi pomocí ID zákazníka. Pokud pro sloupec Customer ID v této tabulce není definován žádný index, SQL Server Engine zkontroluje všechny řádky tabulky, jeden po druhém, aby získal zákazníka s poskytnutým ID. Pokud je pro sloupec Customer ID v této tabulce definován index, SQL Server Engine vyhledá požadované hodnoty Customer ID v seřazeném indexu, nikoli v základní tabulce, aby získal informace o zákazníkovi, čímž se sníží počet naskenovaných údajů. řádků k načtení dat.
V SQL Server je index strukturován logicky jako 8K stránky nebo indexové uzly ve formě B-stromu. Struktura B-stromu obsahuje tři úrovně:Kořenová úroveň která obsahuje jednu stránku indexu v horní části B-stromu, Úroveň listu který se nachází ve spodní části B-stromu a obsahuje datové stránky a střední úroveň který zahrnuje všechny uzly umístěné mezi kořenovou a listovou úrovní, s hodnotami indexového klíče a ukazateli na následující stránky. Tento tvar B-stromu poskytuje rychlý způsob procházení datových stránek zleva doprava a shora dolů na základě indexového klíče.
V SQL Server existují dva hlavní typy indexů, Clustered index ve kterém jsou skutečná data uložena na stránkách indexu na úrovni listů, s možností vytvořit pouze jeden seskupený index pro každou tabulku, protože data uvnitř datových stránek a pořadí stránek budou seřazeny na základě seskupeného indexu klíč. Pokud ve své tabulce definujete omezení primárního klíče, bude seskupený index vytvořen automaticky, pokud nebyl pro tuto tabulku dříve definován žádný sdružený index. Druhým typem indexů je Neclusterovaný index který zahrnuje seřazenou kopii sloupců klíče indexu a ukazatel na zbytek sloupců v základní tabulce nebo seskupeném indexu s možností vytvořit až 999 neshlukovaných indexů pro každou tabulku.
SQL Server nám poskytuje další speciální typy indexů, jako je Unikátní index který se vytvoří automaticky, když je definováno jedinečné omezení k vynucení jedinečnosti konkrétních hodnot sloupců, Složený index ve kterém se na indexovém klíči bude podílet více než jeden klíčový sloupec, Krycí index ve kterém se všechny sloupce požadované konkrétním dotazem budou účastnit indexového klíče, filtrovaného indexu což je optimalizovaný index bez klastrů s predikátem filtru pro indexování pouze malé části řádků tabulky, Prostorový index který je vytvořen ve sloupcích, které ukládají prostorová data, index XML, který je vytvořen na binárních velkých objektech XML (BLOB) ve sloupcích datového typu XML, index úložiště sloupců ve kterém jsou data organizována ve sloupcovém datovém formátu, Fulltextový index který je vytvořen SQL Server Full-Text Engine a Hash index který se používá v tabulkách optimalizovaných pro paměť.
Jak jsem dříve nazýval index SQL Server, jedná se o dvousečný meč , kde SQL Server Query Optimizer může těžit z indexu navrženého dobře pro zlepšení výkonu vašich aplikací urychlením procesu načítání dat. Naproti tomu index, který je navržen špatným způsobem, nebude optimalizován SQL Server Query Optimizer a sníží výkon vašich aplikací zpomalením operací úpravy dat a spotřebovává vaše úložiště, aniž by to využilo v datech. procesy vyhledávání. Proto je lepší nejprve se řídit osvědčenými postupy a pokyny pro vytváření indexu, zkontrolovat účinek vytvoření na vývojové prostředí a najít kompromis mezi rychlostí operací načítání dat a režií přidání tohoto indexu do operací modifikace dat. a prostorové požadavky tohoto indexu před jeho použitím v produkčním prostředí.
Před vytvořením indexu si musíte prostudovat různé aspekty, které ovlivňují vytvoření a použití indexu. To zahrnuje typ databázového vytížení, Online Transaction Processing (OLTP) nebo Online Analytical Processing (OLAP), velikost tabulky , charakteristiky sloupců tabulky , pořadí řazení ze sloupců v dotazu typ indexu který odpovídá dotazu a vlastnostem úložiště, jako je FILLFACTOR a PAD_INDEX možnosti, které řídí procento prostoru na každé úrovni listu a na stránkách střední úrovně, které mají být vyplněny daty.
Fragmentace indexu SQL Server
Vaše práce jako DBA není omezena na vytvoření správného indexu. Jakmile je index vytvořen, měli byste sledovat používání indexu a statistiky, například potřebujete vědět, zda se tento index nepoužívá špatně nebo vůbec. Můžete tak poskytnout správné řešení pro údržbu těchto indexů nebo je nahradit efektivnějšími. Tímto způsobem si zachováte nejvyšší použitelný výkon pro váš systém. Můžete si položit otázku:Proč nástroj SQL Server Query Optimizer již nepoužívá můj index, ačkoli to dříve dělal?
Odpověď se týká především průběžných změn dat a schémat, které se provádějí na základní tabulce a které by se měly projevit v indexech. Postupem času a se všemi těmito změnami se stránky indexu netřídí, což způsobí fragmentaci indexu. Dalším důvodem fragmentace je pokus vložit novou hodnotu nebo aktualizovat aktuální hodnotu a nová hodnota se nevejde do aktuálně dostupného volného místa. V tomto případě bude stránka rozdělena na dvě stránky, kde nová stránka bude vytvořena fyzicky za poslední stránkou. A můžete si představit čtení z fragmentovaného indexu a počet stránek, které by měly být naskenovány, a samozřejmě počet I/O operací provedených k získání několika záznamů kvůli vzdálenosti mezi těmito stránkami. A kvůli těmto dodatečným nákladům na používání tohoto fragmentovaného indexu bude nástroj SQL Server Query Optimizer tento index ignorovat.
Různé způsoby, jak získat fragmentaci indexu
SQL Server nám poskytuje různé způsoby, jak získat procento fragmentace indexu. Prvním způsobem je zkontrolovat procento fragmentace indexu v Indexu Vlastnosti v okně Fragmentace viz níže:
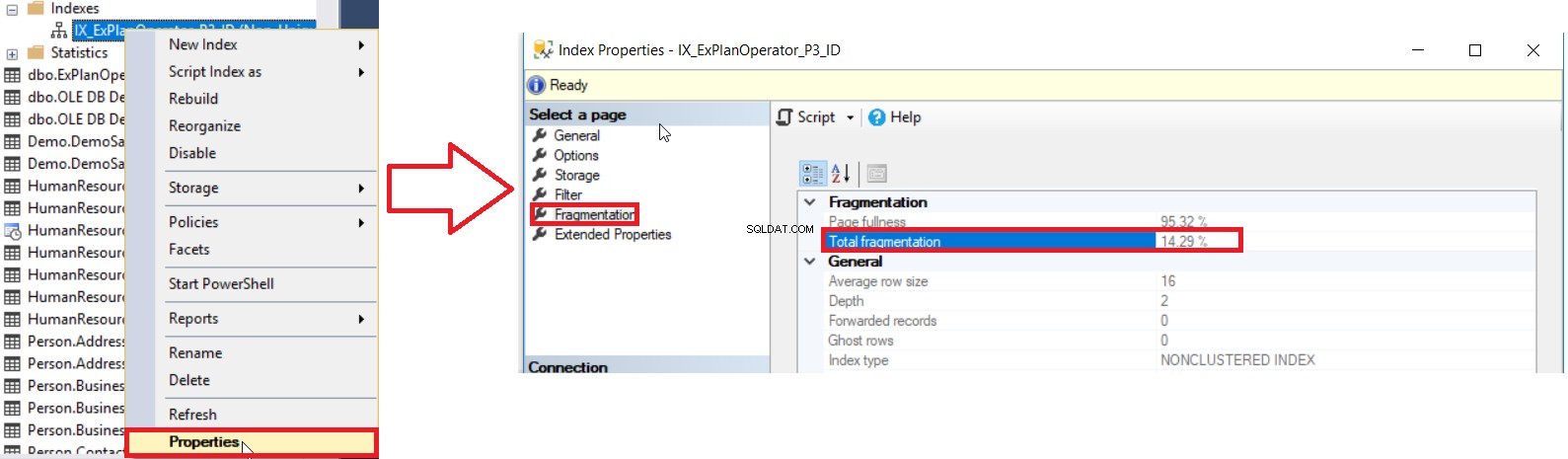
Chcete-li však zkontrolovat úroveň fragmentace více indexů, musíte nejprve provést kontrolu metody uživatelského rozhraní pro všechny indexy, jeden po druhém, což je operace, která ztrácí čas. Druhou dostupnou metodou, jak zkontrolovat úroveň fragmentace všech indexů databáze, je dotazování se na DMF sys.dm_db_index_physical_stats a spojení s DMV sys.indexes za účelem získání všech informací o těchto indexech, přičemž je třeba vzít v úvahu, že tyto statistiky budou aktualizovány, když Služba SQL Server se restartuje pomocí dotazu podobného následujícímu:
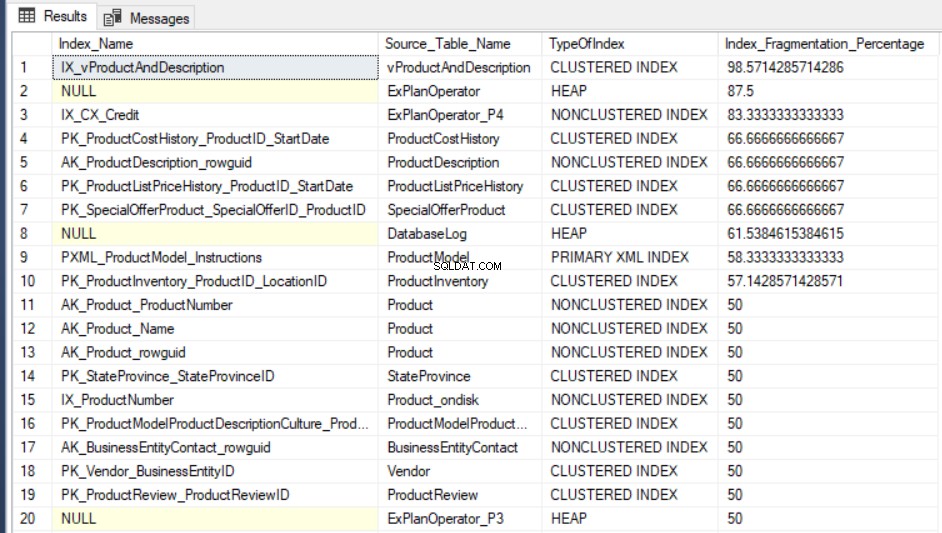
SELECT Indx.name AS Index_Name, OBJECT_NAME(Indx.OBJECT_ID) AS Source_Table_Name, Index_Stat.index_type_desc AS TypeOfIndex, Index_Stat.avg_fragmentation_in_percent Index_Fragmentation_Percentage FROM sys.dm_db_index_physical_stats(DB_ID(), NULL, NULL, NULL, NULL) Index_Stat INNER JOIN sys.indexes Indx ON Indx.object_id = Index_Stat.object_id AND Indx.index_id = Index_Stat.index_id ORDER BY Index_Fragmentation_Percentage DESC
Výstupní výsledek dotazování AdventureWorks2016CTP3 testovací databáze bude podobná následující:
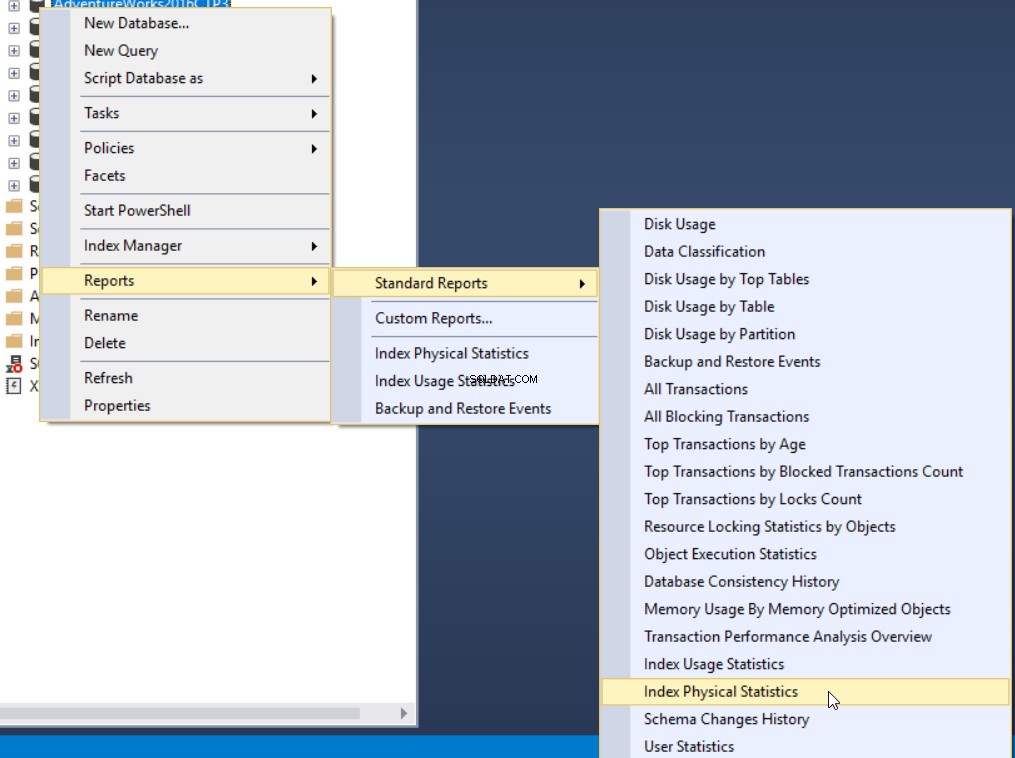
Třetí metodou, jak získat procento fragmentace, je použít standardní sestavu vestavěnou do serveru SQL Server s názvem Index Physical Statistics. Tato sestava vrací užitečné informace o oddílech indexu, procentu fragmentace, počtu stránek na každém oddílu indexu a doporučení, jak vyřešit problém s fragmentací indexu přebudováním nebo reorganizací indexu. Chcete-li zprávu zobrazit, klikněte pravým tlačítkem na databázi, vyberte možnost Zprávy, Standardní zprávy a vyberte Indexovat fyzické statistiky, jak je uvedeno níže:
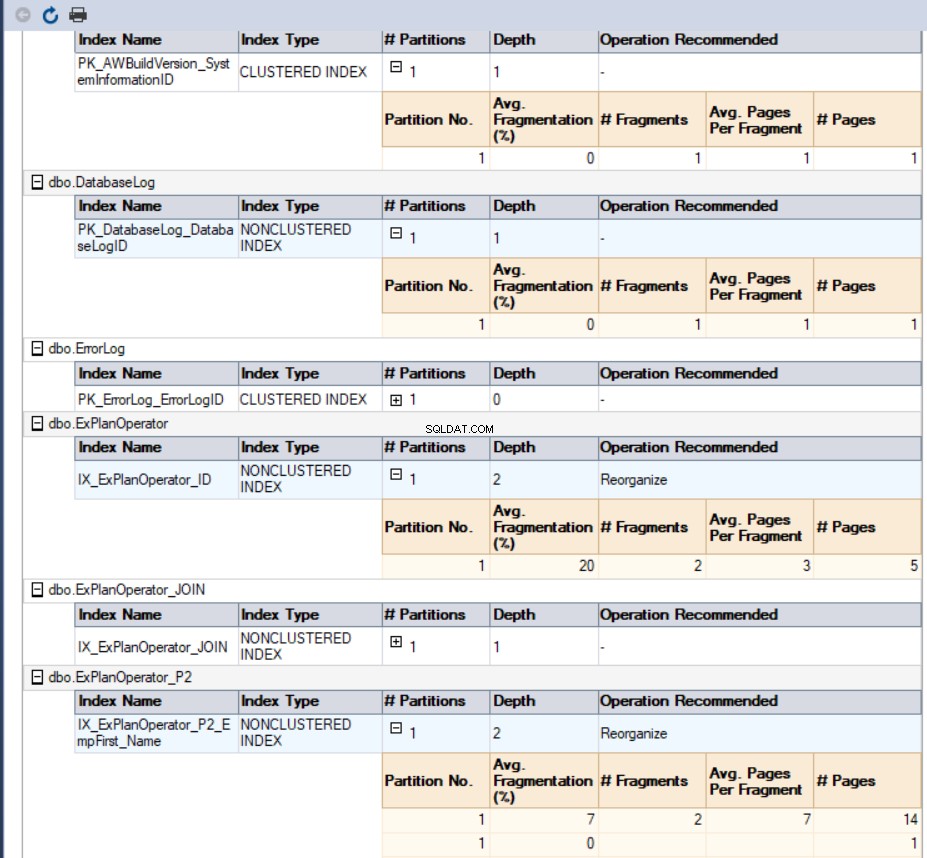
V našem případě bude vygenerovaný přehled vypadat takto:
Posledním a nejjednodušším způsobem, jak získat procento fragmentace všech databázových indexů, je nástroj dbForge Index Manager. dbForge Index Manager nástroj je doplněk, který lze přidat do vašeho SQL Server Management Studio a analyzovat indexy databází SQL Server a poskytuje vám velmi užitečnou zprávu se stavem vybraných databázových indexů a návrhy na údržbu, abyste vyřešili tyto problémy s fragmentací indexů.
Po instalaci doplňku dbForge Index Manager do vašeho SSMS jej můžete spustit kliknutím pravým tlačítkem myši na databázi, kterou chcete skenovat, a výběrem Index Manager a poté Spravovat fragmentaci indexu jak je uvedeno níže:
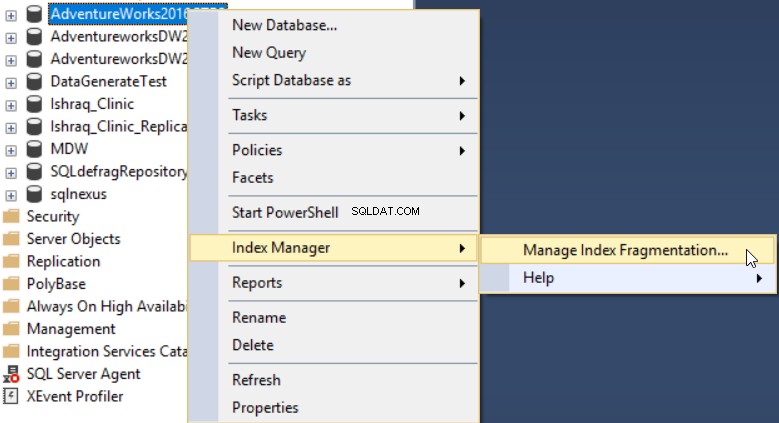
Nástroj dbForge Index Manager vám umožňuje získat celkový obrázek o fragmentaci vybraných databázových indexů s doporučením správných akcí k vyřešení tohoto problému, jak je uvedeno níže:

Nástroj dbForge Index Manager vám také umožňuje přepínat mezi databázemi a po naskenování této databáze vám poskytne novou zprávu, jak je uvedeno níže:
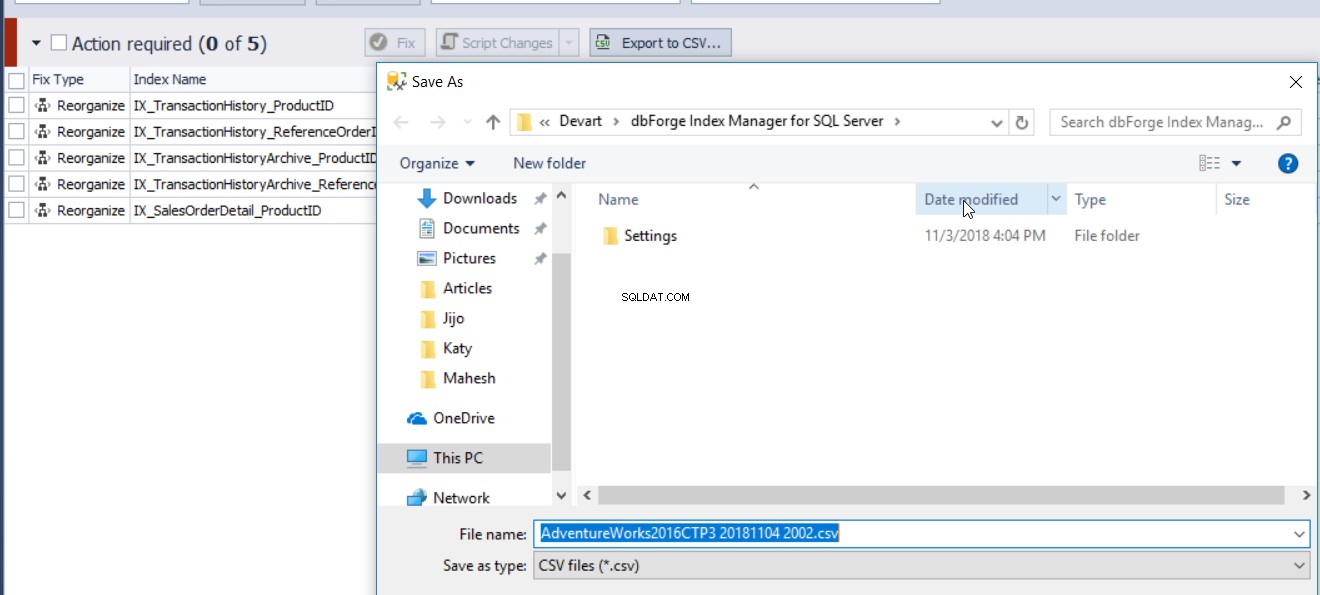
Zprávu o fragmentaci indexu vygenerovanou nástrojem dbForge Index Manager lze exportovat do souboru CSV za účelem analýzy stavu fragmentace indexů, jak je uvedeno níže:
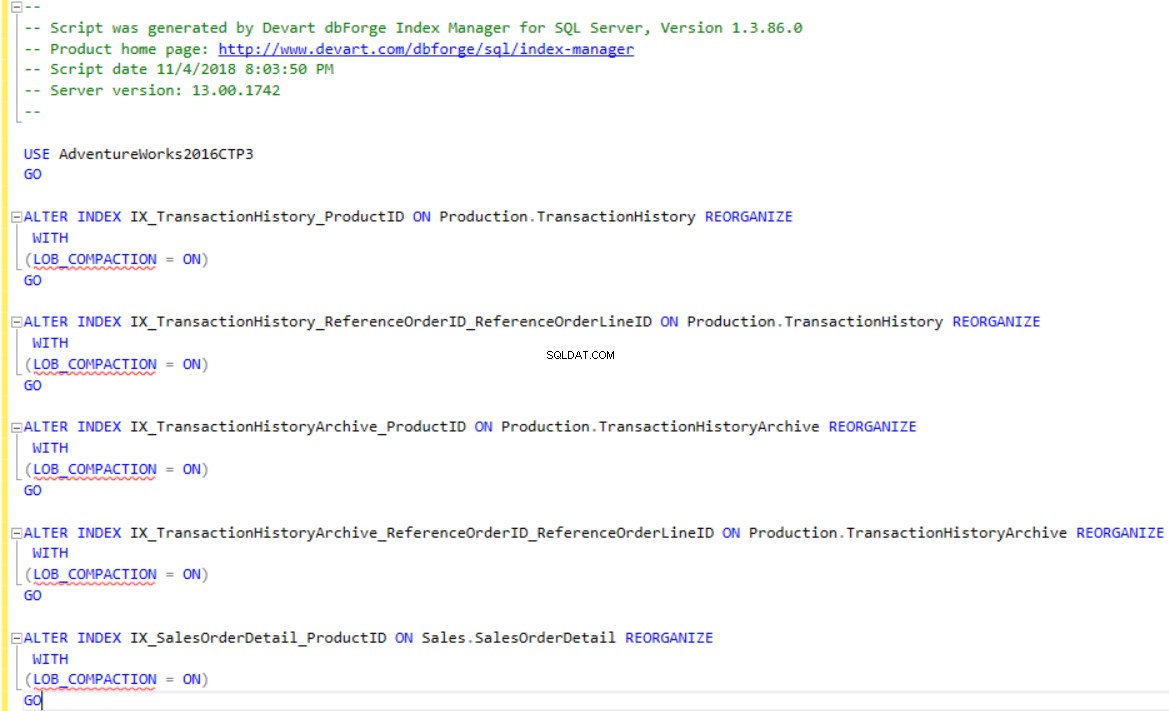
dbForge Index Manager umožňuje generovat T-SQL skripty pro obnovu nebo reorganizaci indexů podle doporučení nástroje. Použijte Změny skriptu možnost zobrazit nebo uložit skript pro indexy, které jsou fragmentované, jak je uvedeno níže:
Nástroj dbForge Index Manager vám poskytuje možnost opravit problém s fragmentací indexu přímo kliknutím na Opravit tlačítko, které provede doporučenou akci přímo na vybraných indexech a zobrazí stav opravy na Výsledku sloupec, jak je znázorněno níže:

Pokud kliknete na tlačítko Znovu analyzovat po úspěšném provedení operace opravy znovu prohledá fragmentaci indexu v databázi. To, co je zde uvedeno v tomto článku, je pouze úvodem k tomu, jak nám nástroj dbForge Index Manager pomůže identifikovat a opravit problémy s fragmentací indexu. Doporučuji vám jej stáhnout a zkontrolovat, co vám tento nástroj může nabídnout.
Užitečné odkazy:
- Základy indexování
- Typy indexů
- Popsány seskupené a neshlukované indexy
- Struktury seskupených indexů
Užitečný nástroj:
dbForge Index Manager – praktický doplněk SSMS pro analýzu stavu indexů SQL a řešení problémů s fragmentací indexů.