Strategie indexování tabulek je jedním z nejdůležitějších klíčů pro ladění a optimalizaci výkonu. Na serveru SQL Server jsou indexy (jak seskupené, tak indexy bez klastrů) vytvořeny pomocí struktury B-stromu, ve které každá stránka funguje jako dvojitě propojený uzel seznamu s informacemi o předchozích a následujících stránkách. Tato struktura B-stromu, nazývaná Forward Scan, usnadňuje čtení řádků z indexu skenováním nebo vyhledáváním jeho stránek od začátku do konce. Přestože dopředné skenování je výchozí a velmi známá metoda skenování indexu, SQL Server nám poskytuje možnost skenovat řádky indexu ve struktuře B-stromu od konce do začátku. Tato schopnost se nazývá Backward Scan. V tomto článku uvidíme, jak se to stane a jaké jsou výhody a nevýhody metody zpětného skenování.
SQL Server nám poskytuje možnost číst data z indexu tabulky skenováním uzlů struktury B-stromu indexu od začátku do konce pomocí metody Forward Scan nebo čtením uzlů stromové struktury B od konce do začátku pomocí Metoda zpětného skenování. Jak název napovídá, zpětné skenování se provádí při čtení opačném než je pořadí sloupce obsaženého v indexu, což se provádí s volbou DESC v příkazu řazení ORDER BY T-SQL, který určuje směr operace skenování.
Ve specifických situacích SQL Server Engine zjistí, že čtení indexových dat od konce do začátku metodou zpětného skenování je rychlejší než čtení v normálním pořadí pomocí metody skenování vpřed, což může vyžadovat nákladný proces třídění pomocí SQL. Motor. Mezi takové případy patří použití agregační funkce MAX() a situace, kdy je řazení výsledku dotazu opačné než pořadí indexu. Hlavní nevýhodou metody zpětného skenování je to, že SQL Server Query Optimizer vždy zvolí provedení pomocí sériového provádění plánu, aniž by mohl využívat výhody paralelních plánů provádění.
Předpokládejme, že máme následující tabulku, která bude obsahovat informace o zaměstnancích společnosti. Tabulku lze vytvořit pomocí příkazu CREATE TABLE T-SQL níže:
VYTVOŘTE TABULKU [dbo].[Zaměstnanci společnosti]( [ID] [INT] IDENTITA (1,1) , [EmpID] [int] NOT NULL, [Emp_First_Name] [nvarchar](50) NULL, [Emp_Last_Name] [ nvarchar](50) NULL, [EmpDepID] [int] NOT NULL, [Emp_Status] [int] NOT NULL, [EMP_PhoneNumber] [nvarchar](50) NULL, [Emp_Address] [nvarchar](max) NULL, [Emp_EmploymentDate] [DATUM ČAS] NULL, PRIMÁRNÍ KLÍČ SE SLUZENÝ ( [ID] ASC)ZAP [PRIMÁRNÍ]))
Po vytvoření tabulky ji naplníme 10 000 fiktivními záznamy pomocí příkazu INSERT níže:
INSERT INTO [dbo].[CompanyEmployees] ([EmpID] ,[Emp_First_Name] ,[Emp_Last_Name] ,[EmpDepID] ,[Emp_Status] ,[EMP_PhoneNumber] ,[Emp_Adresa] ,[Emp_Address] ,[EmyD AAA','BBB',4,1,9624488779,'AMM','2006-10-15')GO 10 000
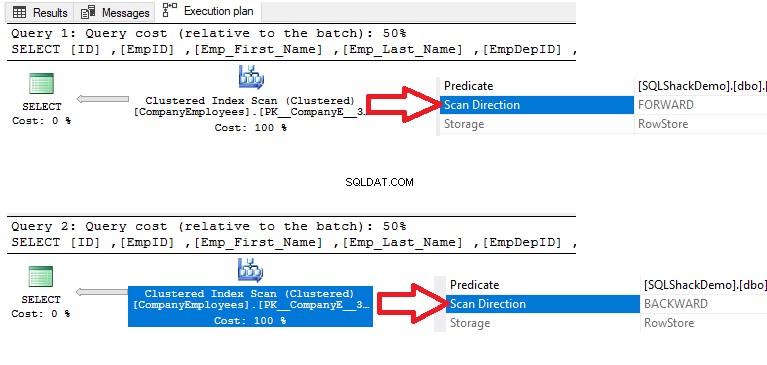
Pokud provedeme níže uvedený příkaz SELECT k načtení dat z dříve vytvořené tabulky, budou řádky seřazeny podle hodnot sloupce ID ve vzestupném pořadí, které je stejné jako pořadí seskupeného indexu:
SELECT [ID] ,[EmpID] ,[Emp_First_Name] ,[Emp_Last_Name] ,[EmpDepID] ,[Emp_Status] ,[EMP_PhoneNumber] ,[Emp_Address] ,[Emp_EmploymentDate] FROM[Eploydboeshack] FROM[EploeboesShack] ] OBJEDNAT PODLE [ID] ASC
Poté zkontrolujete plán provádění pro tento dotaz a provede se skenování seskupeného indexu za účelem získání setříděných dat z indexu, jak je znázorněno v plánu provádění níže:
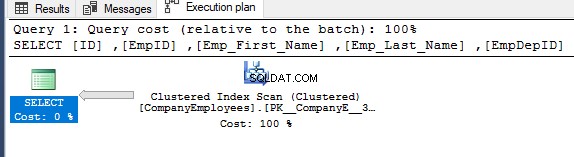
Chcete-li zjistit směr skenování, které se provádí na seskupeném indexu, klepněte pravým tlačítkem na uzel skenování indexu a procházejte vlastnosti uzlu. Ve vlastnostech uzlu Clustered Index Scan zobrazí vlastnost Scan Direction směr skenování, které se provádí na indexu v rámci daného dotazu, což je Forward Scan, jak je znázorněno na snímku níže:

Směr skenování indexu lze také získat z plánu provádění XML z vlastnosti ScanDirection pod uzlem IndexScan, jak je znázorněno níže:
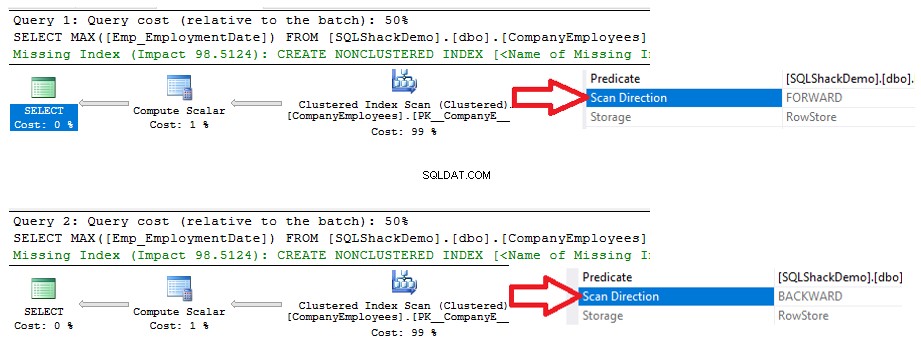
Předpokládejme, že potřebujeme získat maximální hodnotu ID z dříve vytvořené tabulky CompanyEmployees pomocí dotazu T-SQL níže:
VYBERTE MAX ([ID]) Z [dbo].[CompanyEmployees]
Poté si prohlédněte plán provádění, který je vygenerován provedením tohoto dotazu. Uvidíte, že bude provedena kontrola seskupeného indexu, jak je znázorněno v plánu provádění níže:
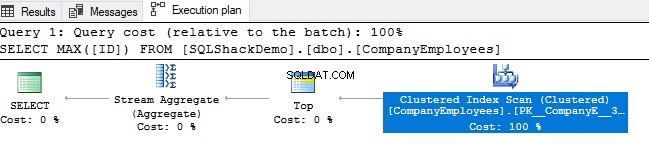
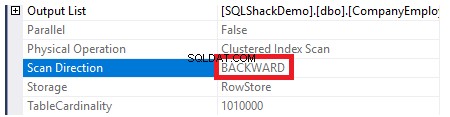
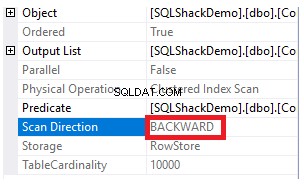
Chcete-li zkontrolovat směr skenování indexu, projdeme vlastnosti uzlu Clustered Index Scan. Výsledek nám ukáže, že SQL Server Engine preferuje skenování clusterového indexu od konce k začátku, což bude v tomto případě rychlejší, aby získal maximální hodnotu sloupce ID, protože index je již seřazen podle sloupce ID, jak je znázorněno níže:
Pokud se také pokusíme získat dříve vytvořená data tabulky pomocí následujícího příkazu SELECT, záznamy budou seřazeny podle hodnot sloupce ID, ale tentokrát, na rozdíl od pořadí seskupeného indexu, zadáním možnosti řazení DESC v ORDER Klauzule BY zobrazená níže:
SELECT [ID] ,[EmpID] ,[Emp_First_Name] ,[Emp_Last_Name] ,[EmpDepID] ,[Emp_Status] ,[EMP_PhoneNumber] ,[Emp_Address] ,[Emp_EmploymentDate] FROM[Eploydboeshack] FROM[EploeboesShack] ] OBJEDNAT PODLE [ID] DESC
Pokud zkontrolujete plán provádění vygenerovaný po provedení předchozího dotazu SELECT, uvidíte, že bude provedena kontrola seskupeného indexu za účelem získání požadovaných záznamů tabulky, jak je uvedeno níže:
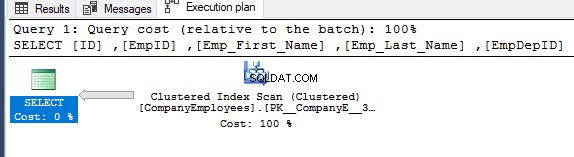
Vlastnosti uzlu Clustered Index Scan ukážou, že směr skenování, který SQL Server Engine upřednostňuje, je směr zpětného skenování, který je v tomto případě rychlejší, kvůli řazení dat opačným než skutečné řazení clusterového indexu, vezmeme-li v úvahu, že index je již seřazen vzestupně podle sloupce ID, jak je znázorněno níže:
Porovnání výkonu
Předpokládejme, že máme níže uvedené příkazy SELECT, které získávají informace o všech zaměstnancích, kteří byli přijati od roku 2010, dvakrát; poprvé bude vrácená sada výsledků setříděna vzestupně podle hodnot sloupce ID a podruhé bude vrácená sada výsledků seřazena sestupně podle hodnot sloupce ID pomocí příkazů T-SQL níže:
SELECT [ID] ,[EmpID] ,[Emp_First_Name] ,[Emp_Last_Name] ,[EmpDepID] ,[Emp_Status] ,[EMP_PhoneNumber] ,[Emp_Address] ,[Emp_EmploymentDate] FROM[Eploydboeshack] FROM[EploeboesShack] ] WHERE Emp_EmploymentDate>='2010-01-01' OBJEDNAT PODLE [ID] MOŽNOSTI ASC (MAXDOP 1) PŘEJDĚTE VYBRAT [ID] ,[EmpID] ,[Emp_First_Name] ,[Emp_Last_Name] ,[EmpDepID] Status] EMP_PhoneNumber] ,[Emp_Address] ,[Emp_EmploymentDate] OD [SQLShackDemo].[dbo].[CompanyEmployees] WHERE Emp_EmploymentDate>='2010-01-01' OBJEDNÁVKA PODLE [ID] DESC GOLF OPTION MAX.Při kontrole prováděcích plánů, které jsou generovány provedením dvou dotazů SELECT, výsledek ukáže, že bude provedeno skenování na seskupeném indexu ve dvou dotazech za účelem načtení dat, ale směr skenování v prvním dotazu bude vpřed. Skenování kvůli třídění dat ASC a zpětné skenování ve druhém dotazu kvůli použití třídění dat DESC, aby se nahradila potřeba znovu uspořádat data, jak je uvedeno níže:
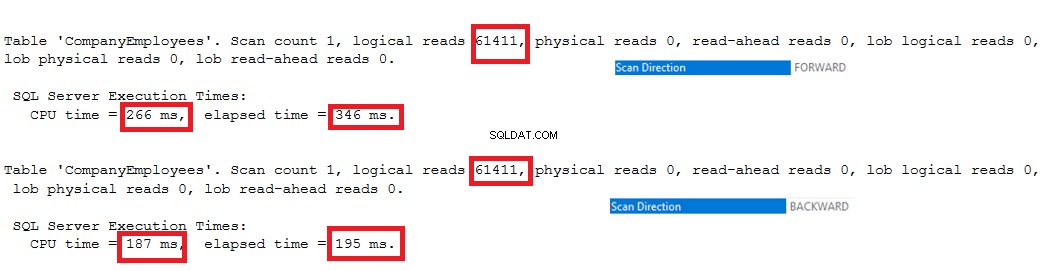
Pokud také zkontrolujeme statistiky provádění IO a TIME dvou dotazů, uvidíme, že oba dotazy provádějí stejné operace IO a spotřebovávají téměř hodnoty provádění a CPU.
Tyto hodnoty nám ukazují, jak chytrý je SQL Server Engine při výběru nejvhodnějšího a nejrychlejšího směru skenování indexu pro načtení dat pro uživatele, což je v prvním případě skenování vpřed a v druhém případě skenování zpět, jak je zřejmé z níže uvedených statistik. :
Pojďme znovu navštívit předchozí příklad MAX. Předpokládejme, že potřebujeme získat maximální ID zaměstnanců, kteří byli přijati v roce 2010 a později. K tomu použijeme následující příkazy SELECT, které seřadí načtená data podle hodnoty sloupce ID s řazením ASC v prvním dotazu a s řazením DESC ve druhém dotazu:
SELECT MAX([Emp_EmploymentDate]) Z [SQLShackDemo].[dbo].[CompanyEmployees] WHERE [Emp_EmploymentDate]>='2017-01-01' GROUP PODLE ID ORDER BY [ID] ASC OPTION (MAXGODOP 1) SELECT MAX([Emp_EmploymentDate]) Z [SQLShackDemo].[dbo].[CompanyEmployees] WHERE [Emp_EmploymentDate]>='2017-01-01' GROUP PODLE ID ORDER BY [ID] DESC OPTION (MAXDOP pre 1) GO>Z prováděcích plánů vygenerovaných provedením dvou příkazů SELECT uvidíte, že oba dotazy provedou operaci skenování na seskupeném indexu, aby načetly maximální hodnotu ID, ale v různých směrech skenování; Dopředné skenování v prvním dotazu a zpětné skenování ve druhém dotazu díky možnostem řazení ASC a DESC, jak je uvedeno níže:
Statistika IO generovaná těmito dvěma dotazy nebude ukazovat žádný rozdíl mezi dvěma směry skenování. Ale statistika TIME ukazuje velký rozdíl mezi výpočtem maximálního ID řádků, když jsou tyto řádky skenovány od začátku do konce pomocí metody Forward Scan, a skenováním od konce k začátku pomocí metody Backward Scan. Z níže uvedeného výsledku je zřejmé, že metoda Backward Scan je optimální metodou skenování pro získání maximální hodnoty ID:
Optimalizace výkonu
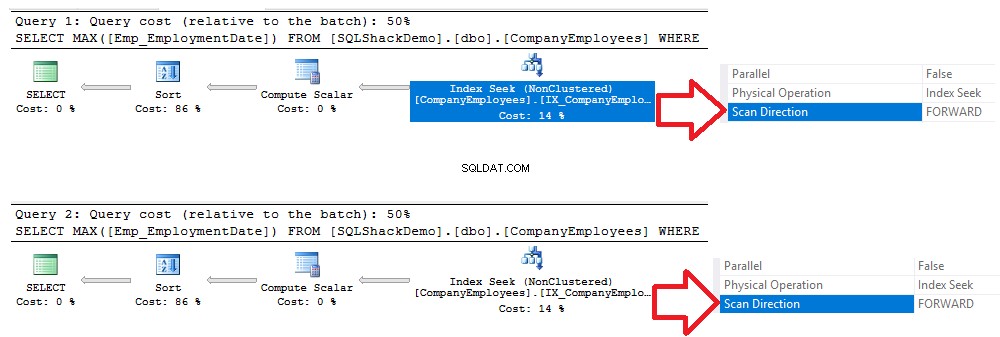
Jak jsem zmínil na začátku tohoto článku, indexování dotazů je nejdůležitějším klíčem v procesu ladění a optimalizace výkonu. Pokud v předchozím dotazu zařídíme přidání neshlukovaného indexu do sloupce EmploymentDate tabulky CompanyEmployees pomocí příkazu CREATE INDEX T-SQL níže:
CREATE NENCLUSTERED INDEX IX_CompanyEmployees_Emp_EmploymentDate ON CompanyEmployees (Emp_EmploymentDate)Poté provedeme stejné předchozí dotazy, jak je ukázáno níže:[Wplom]SELECT MAX([Emp_EmploymentDate]) [Wplom]SELECT[Emp_EmploymentDate]) FROM]SELECT [Emp_EmploymentDate]) FROM]SELECT]EmpeSQL]Comp. ='2017-01-01' SKUPINA PODLE ID POŘADÍ PODLE [ID] MOŽNOSTI ASC (MAXDOP 1) VYBERTE MAX ([Emp_EmploymentDate]) Z [SQLShackDemo].[dbo].[CompanyEmployees] WHERE [Emp_EmploymentDate]>='2017] -01-01' SESKUPIT PODLE ID OBJEDNAT PODLE MOŽNOSTI [ID] DESC (MAXDOP 1) PŘEJÍTPři kontrole prováděcích plánů vygenerovaných po provedení dvou dotazů uvidíte, že bude provedeno vyhledávání na nově vytvořeném indexu bez klastrů a oba dotazy budou skenovat index od začátku do konce pomocí metody Forward Scan, aniž by nutnost provést Backward Scan pro urychlení načítání dat, i když jsme ve druhém dotazu použili možnost řazení DESC. K tomu došlo v důsledku přímého vyhledávání indexu bez nutnosti provést úplné skenování indexu, jak je znázorněno v porovnání plánů provádění níže:
Stejný výsledek lze odvodit ze statistik IO a TIME generovaných z předchozích dvou dotazů, kde tyto dva dotazy spotřebují stejné množství času provádění, CPU a IO operací, s velmi malým rozdílem, jak je znázorněno na snímku statistik níže. :
Užitečný nástroj:
dbForge Index Manager – praktický doplněk SSMS pro analýzu stavu indexů SQL a řešení problémů s fragmentací indexů.