Pokud nepíšete aplikaci, o které s jistotou víte, že bude muset být přenosná, nebo pokud chcete pouze základní informace, jako výchozí bych pro začátek použil proprietární zobrazení systému SQL Server.
Information_Schema pohledy zobrazují pouze objekty, které jsou kompatibilní se standardem SQL-92. To znamená, že neexistuje žádné zobrazení informačního schématu ani pro zcela základní konstrukce, jako jsou indexy (tyto nejsou definovány ve standardu a jsou ponechány jako podrobnosti implementace.) Natož jakékoli proprietární funkce SQL Serveru.
Navíc to není tak úplně všelék na přenositelnost, který lze předpokládat. Implementace se mezi systémy stále liší. Oracle to vůbec neimplementuje „out of the box“ a dokumenty MySql říkají:
Uživatelé SQL Server 2000 (který také dodržuje standard) si mohou všimnout silné podobnosti. MySQL však vynechalo mnoho sloupců, které nejsou pro naši implementaci relevantní, a přidala sloupce, které jsou specifické pro MySQL. Jedním takovým sloupcem je sloupec ENGINE v tabulce INFORMATION_SCHEMA.TABLES.
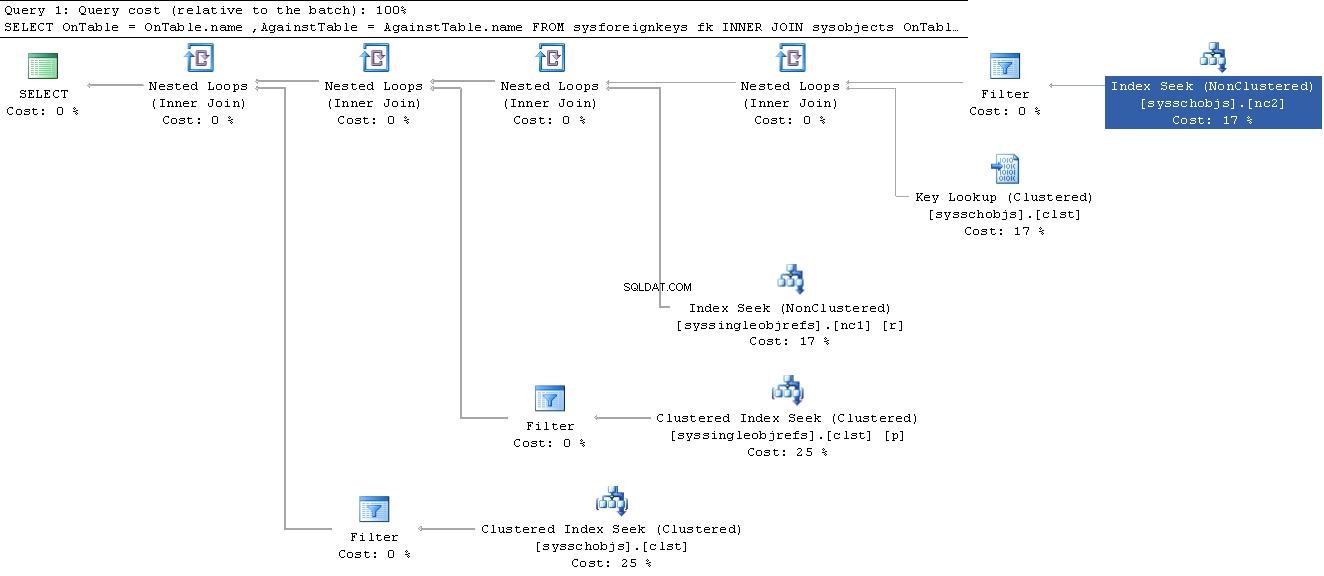
I pro konstrukce SQL typu chleba s máslem, jako jsou omezení cizího klíče, Information_Schema práce s pohledy může být výrazně méně efektivní než se sys. pohledy, protože neodhalují ID objektů, která by umožňovala efektivní dotazování.
např. Viz otázka Zpomalení SQL dotazu z 1 sekundy na 11 minut - proč? a prováděcí plány.
INFORMAČNÍ_SCHÉMA
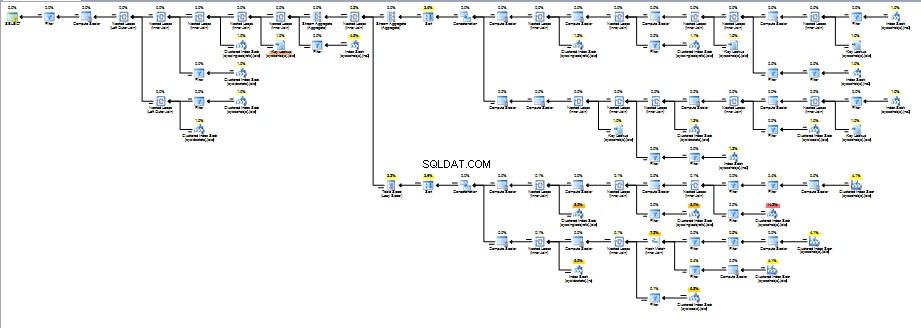
sys