Z hlavy mám pro vás 50% řešení.
Problém
SSIS opravdu se stará o metadata, takže jejich variace obvykle vedou k výjimkám. DTS bylo v tomto smyslu daleko shovívavější. Tato silná potřeba konzistentních metadat způsobuje, že použití zdroje plochých souborů je problematické.
Řešení založené na dotazech
Pokud je problém v komponentě, nepoužívejte ji. Na tomto přístupu se mi líbí, že koncepčně je to stejné jako dotazování na tabulku – nezáleží na pořadí sloupců ani na přítomnosti dalších sloupců.
Proměnné
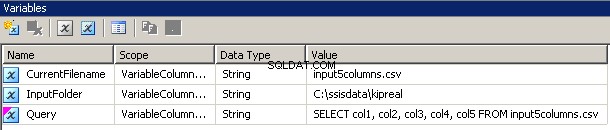
Vytvořil jsem 3 proměnné, všechny typu string:CurrentFileName, InputFolder a Query.
- InputFolder je pevně připojen ke zdrojové složce. V mém příkladu je to
C:\ssisdata\Kipreal - CurrentFileName je název souboru. Během návrhu to byl
input5columns.csvale to se změní za běhu. - Dotaz je výraz
"SELECT col1, col2, col3, col4, col5 FROM " + @[User::CurrentFilename]
Správce připojení
Nastavte připojení ke vstupnímu souboru pomocí ovladače JET OLEDB. Po jeho vytvoření, jak je popsáno v odkazovaném článku, jsem jej přejmenoval na FileOLEDB a nastavil výraz na ConnectionManager na "Data Source=" + @[User::InputFolder] + ";Provider=Microsoft.Jet.OLEDB.4.0;Extended Properties=\"text;HDR=Yes;FMT=CSVDelimited;\";"
Řízení toku
Můj tok řízení vypadá jako úloha toku dat vnořená do enumerátoru souborů Foreach
Foreach File Enumerator
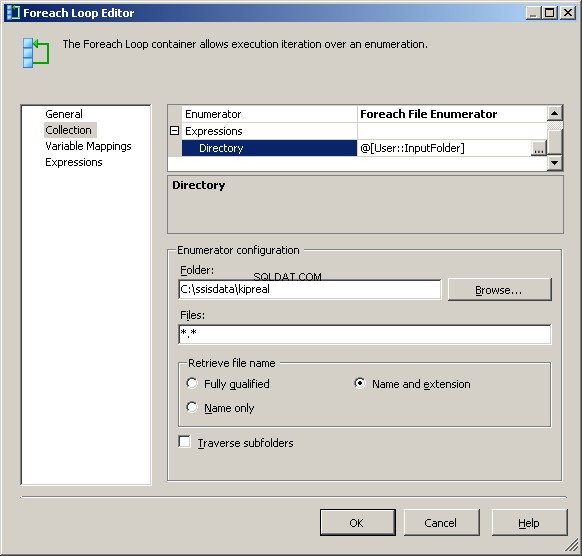
Enumerátor My Foreach File je nakonfigurován pro práci se soubory. Vložil jsem do adresáře výraz pro @[User::InputFolder] Všimněte si, že v tomto okamžiku, pokud je potřeba změnit hodnotu této složky, bude správně aktualizována jak ve Správci připojení, tak ve výčtu souborů. V "Načíst název souboru" místo výchozího "Plně kvalifikovaný" vyberte "Název a přípona"
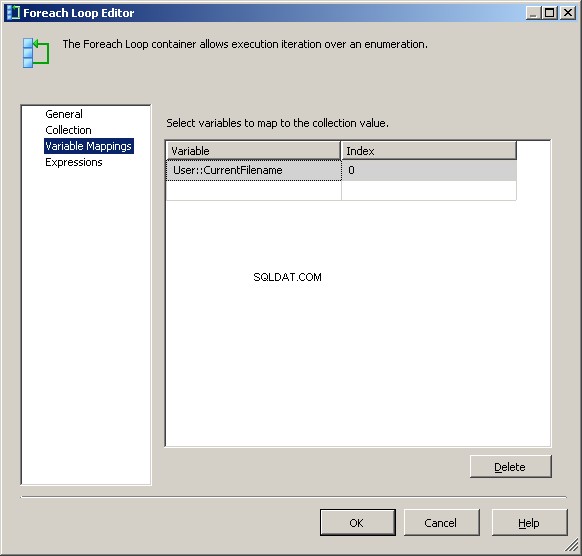
Na kartě Mapování proměnných přiřaďte hodnotu našemu @[User::CurrentFileName] proměnná
V tomto okamžiku každá iterace cyklu změní hodnotu @[User::Query odrážet aktuální název souboru.
Datový tok
Toto je vlastně nejjednodušší kousek. Použijte zdroj OLE DB a připojte jej, jak je uvedeno.
Použijte správce připojení FileOLEDB a změňte režim přístupu k datům na "Příkaz SQL z proměnné." Použijte @[User::Query] klikněte na OK a jste připraveni pracovat. 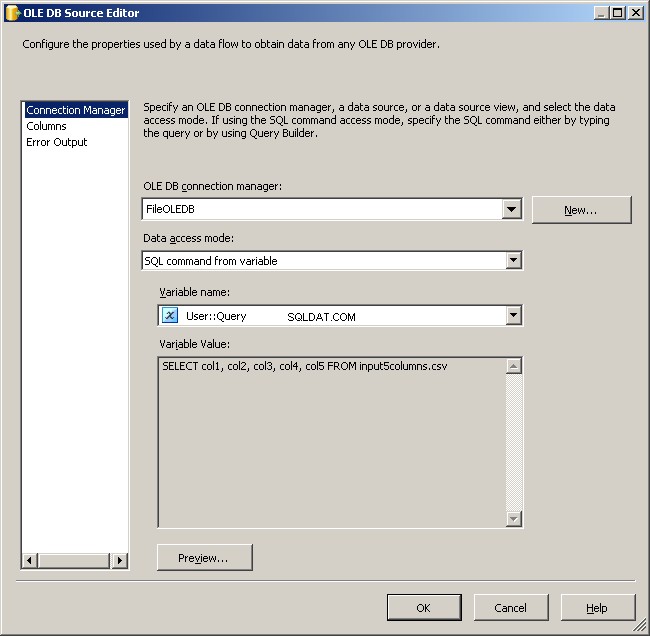
Ukázková data
Vytvořil jsem dva ukázkové soubory input5columns.csv a input7columns.csv Všechny sloupce z 5 jsou v 7, ale 7 je má v jiném pořadí (sloupec2 je pořadová pozice 2 a 6). Negoval jsem všechny hodnoty v 7, aby bylo snadno zřejmé, se kterým souborem se pracuje.
col1,col3,col2,col5,col4
1,3,2,5,4
1111,3333,2222,5555,4444
11,33,22,55,44
111,333,222,555,444
a
col1,col3,col7,col5,col4,col6,col2
-1111,-3333,-7777,-5555,-4444,-6666,-2222
-111,-333,-777,-555,-444,-666,-222
-1,-3,-7,-5,-4,-6,-2
-11,-33,-77,-55,-44,-666,-222
Výsledkem spuštění balíčku jsou tyto dva snímky obrazovky
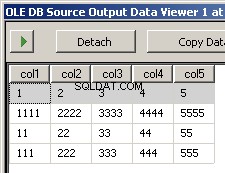
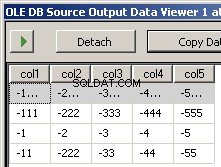
Co chybí
Nevím o způsobu, jak říci přístupu založenému na dotazu, že je v pořádku, pokud sloupec neexistuje. Pokud existuje jedinečný klíč, předpokládám, že byste mohli definovat svůj dotaz tak, aby obsahoval pouze sloupce, které musí být u toho a poté provést vyhledávání v souboru, abyste se pokusili získat sloupce, které měli být tam a nepropadnout vyhledávání, pokud sloupec neexistuje. Docela nemotorné.