Co způsobuje, že dotaz s křížovou aplikací funguje na tomto jednoduchém dokumentu XML tak špatně a že je exponenciálně pomalejší, jak roste datová sada?
Je to použití nadřazené osy k získání ID atributu z uzlu položky.
Právě tato část plánu dotazů je problematická.

Všimněte si 423 řádků vycházejících z funkce s nižší hodnotou tabulky.
Přidáním pouze jednoho dalšího uzlu položky se třemi uzly pole získáte toto.
Vráceno 732 řádků.
Co když zdvojnásobíme uzly z prvního dotazu na celkem 6 uzlů položek?
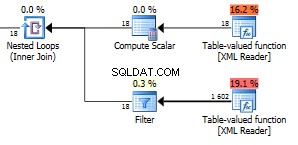
Máme k dispozici neuvěřitelných 1602 vrácených řádků.
Obrázek 18 v horní funkci představuje všechny uzly polí ve vašem XML. Máme zde 6 položek se třemi poli v každé položce. Těchto 18 uzlů se používá ve vnořených smyčkách, které se spojují proti jiné funkci, takže 18 provedení vracejících 1602 řádků dává, že vrací 89 řádků na iteraci. To je náhodou přesný počet uzlů v celém XML. Ve skutečnosti je to o jeden více než všechny viditelné uzly. nevím proč. Tento dotaz můžete použít ke kontrole celkového počtu uzlů ve vašem XML.
select count(*)
from @XML.nodes('//*, //@*, //*/text()') as T(X)
Takže algoritmus používaný SQL Serverem k získání hodnoty, když použijete nadřazenou osu .. ve funkci hodnot je, že nejprve najde všechny uzly, na kterých skartujete, v posledním případě 18. Pro každý z těchto uzlů skartuje a vrátí celý dokument XML a zkontroluje operátor filtru pro uzel, který skutečně chcete. Zde máte svůj exponenciální růst. Místo použití rodičovské osy byste měli použít jednu křížovou aplikaci navíc. Nejprve skartujte na předmět a poté na pole.
select I.X.value('@name', 'varchar(5)') as item_name,
F.X.value('@id', 'uniqueidentifier') as field_id,
F.X.value('@type', 'int') as field_type,
F.X.value('text()[1]', 'nvarchar(15)') as field_value
from #temp as T
cross apply T.x.nodes('/data/item') as I(X)
cross apply I.X.nodes('field') as F(X)
Také jsem změnil způsob, jakým přistupujete k textové hodnotě pole. Pomocí . přiměje SQL Server hledat podřízené uzly do field a zřetězit tyto hodnoty ve výsledku. Nemáte žádné podřízené hodnoty, takže výsledek je stejný, ale je dobré se vyhnout tomu, aby tato část byla součástí plánu dotazů (operátor UDX).
Pokud používáte index XML, plán dotazů nemá problém s nadřazenou osou, ale přesto budete mít prospěch ze změny způsobu načítání hodnoty pole.