Abychom odpověděli na vaši otázku, proč to SQL Server dělá, odpověď je, že dotaz není kompilován v logickém pořadí, každý příkaz je kompilován na základě své vlastní hodnoty, takže když se generuje plán dotazů pro váš příkaz select, optimalizátor neví, že @val1 a @Val2 se stanou 'val1' a 'val2' v tomto pořadí.
Když SQL Server nezná hodnotu, musí co nejlépe odhadnout, kolikrát se tato proměnná objeví v tabulce, což může někdy vést k suboptimálním plánům. Můj hlavní bod je, že stejný dotaz s různými hodnotami může generovat různé plány. Představte si tento jednoduchý příklad:
IF OBJECT_ID(N'tempdb..#T', 'U') IS NOT NULL
DROP TABLE #T;
CREATE TABLE #T (ID INT IDENTITY PRIMARY KEY, Val INT NOT NULL, Filler CHAR(1000) NULL);
INSERT #T (Val)
SELECT TOP 991 1
FROM sys.all_objects a
UNION ALL
SELECT TOP 9 ROW_NUMBER() OVER(ORDER BY a.object_id) + 1
FROM sys.all_objects a;
CREATE NONCLUSTERED INDEX IX_T__Val ON #T (Val);
Vše, co jsem zde udělal, je vytvořit jednoduchou tabulku a přidat 1000 řádků s hodnotami 1-10 pro sloupec val 1 se však objeví 991krát a zbývajících 9 se objeví pouze jednou. Předpokladem je tento dotaz:
SELECT COUNT(Filler)
FROM #T
WHERE Val = 1;
Efektivnější by bylo pouze prohledat celou tabulku, než použít index pro hledání a poté provést 991 vyhledávání v záložkách, abyste získali hodnotu Filler , avšak pouze s 1 řádkem následující dotaz:
SELECT COUNT(Filler)
FROM #T
WHERE Val = 2;
bude efektivnější provádět vyhledávání indexu a vyhledávání jedné záložky pro získání hodnoty Filler (a spuštění těchto dvou dotazů to potvrdí)
Jsem si docela jistý, že hranice pro vyhledávání a vyhledávání záložek se skutečně liší v závislosti na situaci, ale je poměrně nízká. Pomocí ukázkové tabulky jsem s trochou pokusů a omylů zjistil, že potřebuji Val aby měl sloupec 38 řádků s hodnotou 2, než optimalizátor přešel na úplné prohledání tabulky přes hledání indexu a vyhledávání záložek:
IF OBJECT_ID(N'tempdb..#T', 'U') IS NOT NULL
DROP TABLE #T;
DECLARE @I INT = 38;
CREATE TABLE #T (ID INT IDENTITY PRIMARY KEY, Val INT NOT NULL, Filler CHAR(1000) NULL);
INSERT #T (Val)
SELECT TOP (991 - @i) 1
FROM sys.all_objects a
UNION ALL
SELECT TOP (@i) 2
FROM sys.all_objects a
UNION ALL
SELECT TOP 8 ROW_NUMBER() OVER(ORDER BY a.object_id) + 2
FROM sys.all_objects a;
CREATE NONCLUSTERED INDEX IX_T__Val ON #T (Val);
SELECT COUNT(Filler), COUNT(*)
FROM #T
WHERE Val = 2;
Takže pro tento příklad je limit 3,7 % odpovídajících řádků.
Protože dotaz nezná, kolik řádků se bude shodovat, když používáte proměnnou, musí uhodnout, a nejjednodušší způsob je zjistit celkový počet řádků a vydělit ho celkovým počtem odlišných hodnot ve sloupci, takže v tomto příkladu odhadovaný počet řádků pro WHERE val = @Val je 1000 / 10 =100, Skutečný algoritmus je složitější než tento, ale například to bude stačit. Když se tedy podíváme na plán provádění:
DECLARE @i INT = 2;
SELECT COUNT(Filler)
FROM #T
WHERE Val = @i;
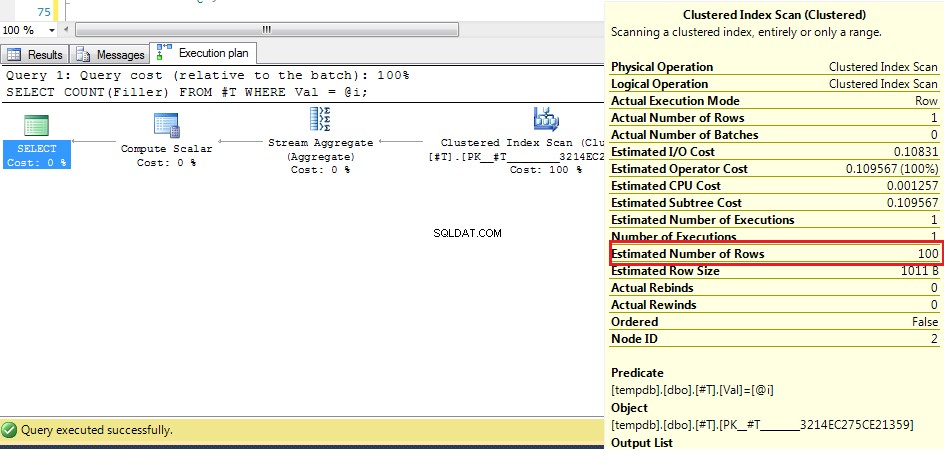
Zde (s původními daty) můžeme vidět, že odhadovaný počet řádků je 100, ale skutečný počet řádků je 1. Z předchozích kroků víme, že s více než 38 řádky se optimalizátor rozhodne pro skenování sdruženého indexu přes index hledat, takže protože nejlepší odhad počtu řádků je vyšší než tento, plán pro neznámou proměnnou je skenování shlukovaného indexu.
Jen pro další doložení teorie, pokud vytvoříme tabulku s 1000 řádky čísel 1-27 rovnoměrně rozložených (takže odhadovaný počet řádků bude přibližně 1000 / 27 =37,037)
IF OBJECT_ID(N'tempdb..#T', 'U') IS NOT NULL
DROP TABLE #T;
CREATE TABLE #T (ID INT IDENTITY PRIMARY KEY, Val INT NOT NULL, Filler CHAR(1000) NULL);
INSERT #T (Val)
SELECT TOP 27 ROW_NUMBER() OVER(ORDER BY a.object_id)
FROM sys.all_objects a;
INSERT #T (val)
SELECT TOP 973 t1.Val
FROM #T AS t1
CROSS JOIN #T AS t2
CROSS JOIN #T AS t3
ORDER BY t2.Val, t3.Val;
CREATE NONCLUSTERED INDEX IX_T__Val ON #T (Val);
Poté spusťte dotaz znovu, získáme plán s hledáním indexu:
DECLARE @i INT = 2;
SELECT COUNT(Filler)
FROM #T
WHERE Val = @i;
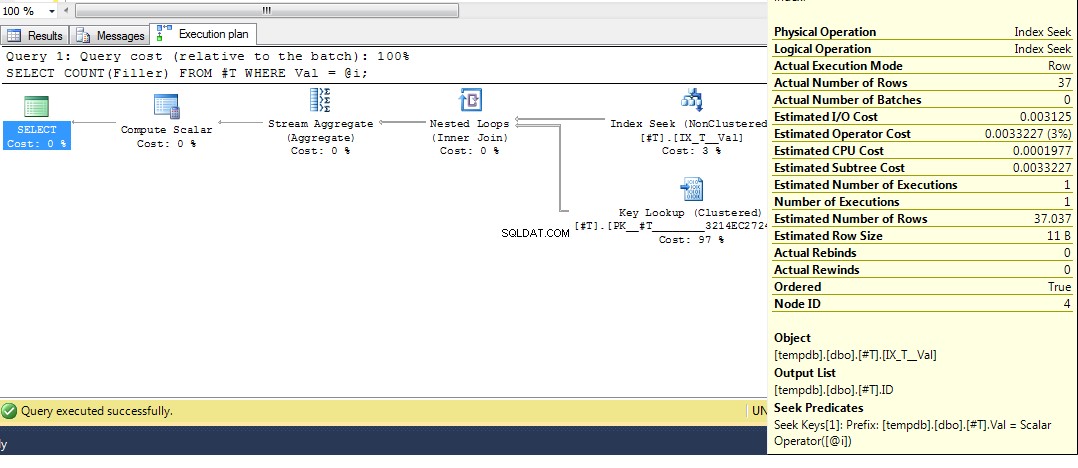
Doufejme, že to docela obsáhle pokryje, proč jste získali tento plán. Nyní předpokládám, že další otázkou je, jak vynutit jiný plán, a odpovědí je použít nápovědu k dotazu OPTION (RECOMPILE) , k vynucení kompilace dotazu v době provádění, kdy je známá hodnota parametru. Návrat k původním datům, kde je nejlepší plán pro Val = 2 je vyhledávání, ale pomocí proměnné získáme plán s indexovým skenováním, můžeme spustit:
DECLARE @i INT = 2;
SELECT COUNT(Filler)
FROM #T
WHERE Val = @i;
GO
DECLARE @i INT = 2;
SELECT COUNT(Filler)
FROM #T
WHERE Val = @i
OPTION (RECOMPILE);
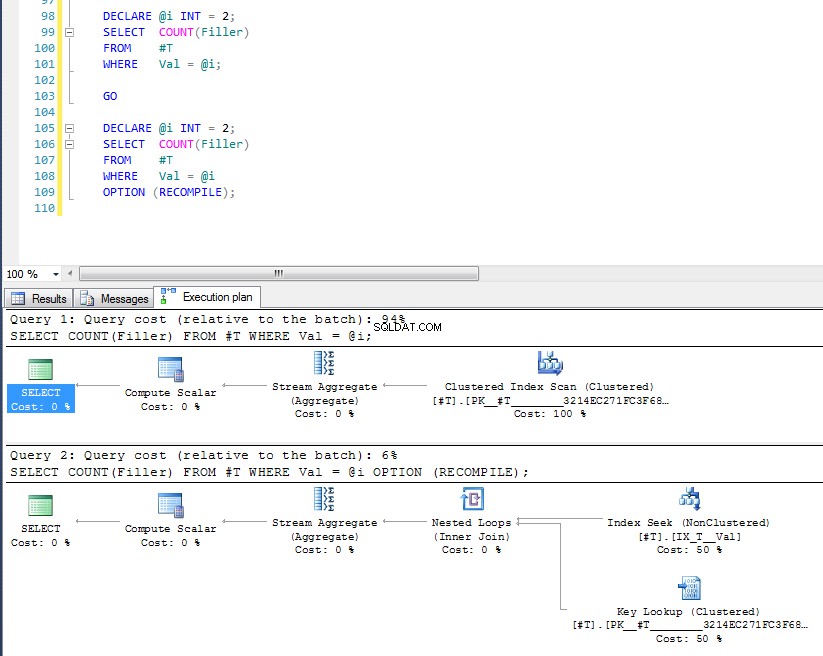
Vidíme, že druhý používá vyhledávání indexu a vyhledávání klíčů, protože zkontroloval hodnotu proměnné v době provádění a pro tuto konkrétní hodnotu je vybrán nejvhodnější plán. Problém s OPTION (RECOMPILE) to znamená, že nemůžete využít plánů dotazů uložených v mezipaměti, takže pokaždé vznikají dodatečné náklady na kompilaci dotazu.