V první části této série jsem představil základní terminologii týkající se protokolování, takže vám doporučuji si ji přečíst, než budete pokračovat v tomto příspěvku. Všechno ostatní, co v seriálu proberu, vyžaduje znát část architektury transakčního protokolu, takže o tom budu tentokrát diskutovat. I když seriál nebudete sledovat, některé z konceptů, které vysvětlím níže, stojí za to znát pro každodenní úkoly, které DBA řeší ve výrobě.
Strukturální hierarchie
Transakční protokol je interně organizován pomocí tříúrovňové hierarchie, jak je znázorněno na obrázku 1 níže.
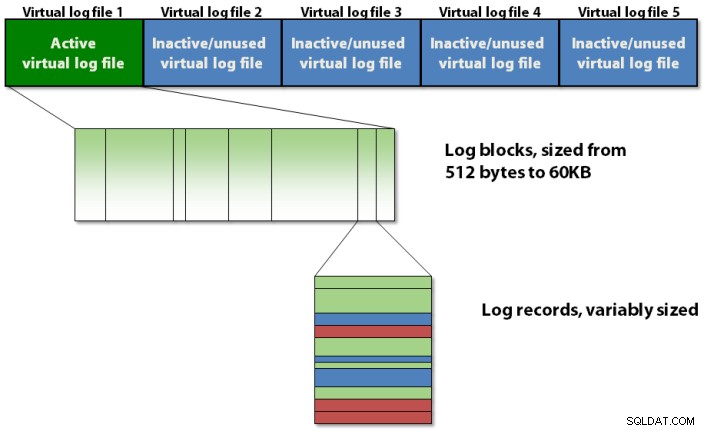 Obrázek 1:Tříúrovňová strukturální hierarchie protokolu transakcí
Obrázek 1:Tříúrovňová strukturální hierarchie protokolu transakcí
Protokol transakcí obsahuje soubory virtuálních protokolů, které obsahují bloky protokolu, které ukládají skutečné záznamy protokolu.
Virtuální soubory protokolu
Transakční protokol je rozdělen do sekcí nazývaných virtuální protokolové soubory , běžně nazývané pouze VLF . To se provádí za účelem usnadnění správy operací v protokolu transakcí pro správce protokolu na serveru SQL Server. Nemůžete určit, kolik VLF vytvoří SQL Server při prvním vytvoření databáze nebo při automatickém růstu souboru protokolu, ale můžete to ovlivnit. Algoritmus pro počet vytvořených VLF je následující:
- Velikost souboru protokolu menší než 64 MB:vytvořte 4 soubory VLF, každý o velikosti přibližně 16 MB
- Velikost souboru protokolu od 64 MB do 1 GB :vytvořte 8 VLF, každý přibližně 1/8 celkové velikosti
- Velikost souboru protokolu větší než 1 GB:vytvořte 16 VLF, každý přibližně 1/16 celkové velikosti
Před SQL Server 2014, kdy se soubor protokolu automaticky zvětšuje, je počet nových VLF přidaných na konec souboru protokolu určen algoritmem výše na základě velikosti automatického růstu. Pokud je však pomocí tohoto algoritmu velikost automatického růstu malá a soubor protokolu prochází mnoha automatickými růsty, může to vést k velmi velkému počtu malých VLF (tzv.fragmentace VLF ), což může být pro některé operace velký problém s výkonem (viz zde).
Kvůli tomuto problému se v SQL Server 2014 změnil algoritmus pro automatický růst souboru protokolu. Pokud je velikost automatického růstu menší než 1/8 celkové velikosti souboru protokolu, vytvoří se pouze jeden nový VLF, jinak se použije starý algoritmus. To drasticky snižuje počet VLF pro soubor protokolu, který prošel velkým množstvím automatického růstu. V tomto blogovém příspěvku jsem vysvětlil příklad rozdílu.
Každý VLF má pořadové číslo který jej jednoznačně identifikuje a používá se na různých místech, což vysvětlím níže a v budoucích příspěvcích. Mysleli byste si, že pořadová čísla začínají na 1 u zcela nové databáze, ale není tomu tak.
Na instanci SQL Server 2019 jsem vytvořil novou databázi, aniž bych uvedl jakékoli velikosti souborů, a poté zkontroloval VLF pomocí kódu níže:
CREATE DATABASE NewDB;
GO
SELECT
[file_id],
[vlf_begin_offset],
[vlf_size_mb],
[vlf_sequence_number]
FROM
sys.dm_db_log_info (DB_ID (N'NewDB'));
Všimněte si sys.dm_db_log_info DMV byl přidán do SQL Server 2016 SP2. Předtím (a dnes, protože stále existuje) můžete použít nezdokumentovaný DBCC LOGINFO příkaz, ale nemůžete mu dát výběrový seznam – stačí udělat DBCC LOGINFO(N'NewDB'); a pořadová čísla VLF jsou v FSeqNo sloupec sady výsledků.
Každopádně výsledky z dotazování sys.dm_db_log_info byly:
file_id vlf_begin_offset vlf_size_mb vlf_sequence_number ------- ---------------- ----------- ------------------- 2 8192 1.93 37 2 2039808 1.93 0 2 4071424 1.93 0 2 6103040 2.17 0
Všimněte si, že první VLF začíná odsazením 8 192 bajtů do souboru protokolu. Je to proto, že všechny databázové soubory, včetně transakčního protokolu, mají stránku záhlaví souboru, která zabírá prvních 8 kB a ukládá různá metadata o souboru.
Proč tedy SQL Server pro první pořadové číslo VLF vybere 37 a ne 1? Najde nejvyšší pořadové číslo VLF v modelu databáze a poté pro každou novou databázi použije první VLF protokolu transakcí toto číslo plus 1 jako pořadové číslo. Nevím, proč byl tento algoritmus zvolen zpět v mlhách času, ale je tomu tak minimálně od SQL Server 7.0.
Abych to dokázal, spustil jsem tento kód:
SELECT
MAX ([vlf_sequence_number]) AS [Max_VLF_SeqNo]
FROM
sys.dm_db_log_info (DB_ID (N'model')); A výsledky byly:
Max_VLF_SeqNo -------------------- 36
Tak tady to máte.
O VLF a o tom, jak se používají, je toho k diskusi více, ale prozatím stačí vědět, že každý VLF má pořadové číslo, které se u každého VLF zvyšuje o jedničku.
Blokování protokolu
Každý VLF obsahuje malé záhlaví metadat a zbytek prostoru je vyplněn bloky protokolu. Každý blok protokolu začíná na 512 bajtech a bude narůstat v 512bajtových krocích na maximální velikost 60 kB, v tomto okamžiku musí být zapsán na disk. Blok protokolu může být zapsán na disk dříve, než dosáhne své maximální velikosti, pokud nastane jedna z následujících situací:
- Transakce se potvrdí a pro tuto transakci se nepoužívá zpožděná trvanlivost, takže blok protokolu musí být zapsán na disk, aby byla transakce trvalá
- Je používána zpožděná trvanlivost a na pozadí se spustí úloha časovače „vyprázdnit aktuální blok protokolu na disk“ 1 ms
- Stránka datového souboru se zapisuje na disk kontrolním bodem nebo líným zapisovačem a v aktuálním bloku protokolu je jeden nebo více záznamů protokolu, které ovlivňují stránku, která se má zapsat (pamatujte, že protokolování před zápisem musí být zaručeno)
Blok protokolu můžete považovat za něco jako stránku s proměnnou velikostí, která ukládá záznamy protokolu v pořadí, v jakém jsou vytvořeny transakcemi měnícími databázi. Pro každou transakci neexistuje blok protokolu; záznamy protokolu pro více souběžných transakcí lze prolínat v bloku protokolu. Možná si myslíte, že by to představovalo potíže pro operace, které potřebují najít všechny záznamy protokolu pro jednu transakci, ale není tomu tak, jak vysvětlím, když v dalším příspěvku popíšu, jak funguje vrácení transakcí.
Navíc, když je blok protokolu zapsán na disk, je zcela možné, že obsahuje záznamy protokolu z nepotvrzených transakcí. To také není problém kvůli způsobu, jakým funguje zotavení po havárii – což je pěkných pár příspěvků v budoucnosti seriálu.
Zaznamenat pořadová čísla
Bloky protokolu mají ID v rámci VLF, začínající na 1 a zvyšující se o 1 pro každý nový blok protokolu ve VLF. Záznamy protokolu mají také ID v bloku protokolu, začínající na 1 a zvyšující se o 1 pro každý nový záznam protokolu v bloku protokolu. Takže všechny tři prvky ve strukturální hierarchii protokolu transakcí mají ID a jsou sloučeny do trojstranného identifikátoru zvaného sekvenční číslo protokolu , běžněji označované jednoduše jako LSN .
LSN je definováno jako
Základní práce jsou hotové!
I když je důležité vědět o VLF, podle mého názoru je LSN nejdůležitějším konceptem pro pochopení implementace protokolování SQL Serverem, protože LSN jsou základním kamenem, na kterém je postaveno vrácení transakcí a zotavení po havárii, a LSN se budou objevovat znovu a znovu, protože Postupuji v sérii. V dalším příspěvku se budu zabývat zkrácením protokolu a kruhovou povahou protokolu transakcí, což vše souvisí s VLF a jak se znovu používají.