SQL Server 2014 CTP1 je k dispozici již několik týdnů a pravděpodobně jste viděli poměrně hodně tisku o tabulkách optimalizovaných pro paměť a aktualizovatelných indexech columnstore. I když si to jistě zaslouží pozornost, v tomto příspěvku jsem chtěl prozkoumat nové vylepšení paralelismu SELECT … INTO. Vylepšení je jednou z těch hotových změn, které, jak to vypadá, nevyžadují významné změny kódu, aby z nich mohly těžit. Moje průzkumy byly provedeny pomocí verze Microsoft SQL Server 2014 (CTP1) – 11.0.9120.5 (X64), Enterprise Evaluation Edition.
Paralelní VÝBĚR … DO
SQL Server 2014 zavádí paralelní funkci SELECT ... INTO pro databáze a k otestování této funkce jsem použil databázi AdventureWorksDW2012 a verzi tabulky FactInternetSales, která měla 61 847 552 řádků (za přidání těchto řádků jsem odpovídal já; standardně se s databází nedodávají).
Protože tato funkce od CTP1 vyžaduje úroveň kompatibility databáze 110, pro účely testování jsem nastavil databázi na úroveň kompatibility 100 a pro svůj první test provedl následující dotaz:
SELECT [ProductKey],
[OrderDateKey],
[DueDateKey],
[ShipDateKey],
[CustomerKey],
[PromotionKey],
[CurrencyKey],
[SalesTerritoryKey],
[SalesOrderNumber],
[SalesOrderLineNumber],
[RevisionNumber],
[OrderQuantity],
[UnitPrice],
[ExtendedAmount],
[UnitPriceDiscountPct],
[DiscountAmount],
[ProductStandardCost],
[TotalProductCost],
[SalesAmount],
[TaxAmt],
[Freight],
[CarrierTrackingNumber],
[CustomerPONumber],
[OrderDate],
[DueDate],
[ShipDate]
INTO dbo.FactInternetSales_V2
FROM dbo.FactInternetSales; Doba provádění dotazu byla 3 minuty a 19 sekund na mém testovacím virtuálním počítači a skutečný plán provádění dotazu byl následující:

SQL Server používal sériový plán, jak jsem očekával. Všimněte si také, že moje tabulka obsahovala neshlukovaný index columnstore, který byl naskenován (tento neshlukovaný index columnstore jsem vytvořil pro použití s jinými testy, ale později vám také ukážu plán provádění dotazu na index clusteru columnstore). Plán nepoužíval paralelismus a Columnstore Index Scan používal režim spouštění řádků místo režimu dávkového spouštění.
Dále jsem upravil úroveň kompatibility databáze (a povšimněte si, že v CTP1 zatím není úroveň kompatibility SQL Server 2014):
USE [master]; GO ALTER DATABASE [AdventureWorksDW2012] SET COMPATIBILITY_LEVEL = 110; GO
Zahodil jsem tabulku FactInternetSales_V2 a poté znovu spustil svůj původní SELECT ... INTO úkon. Tentokrát byla doba provádění dotazu 1 minuta a 7 sekund a skutečný plán provádění dotazu byl následující:
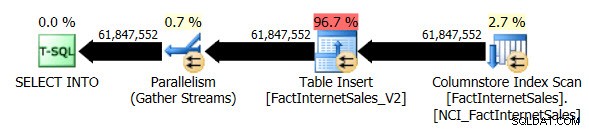
Nyní máme paralelní plán a jediná změna, kterou jsem musel provést, byla úroveň kompatibility databáze pro AdventureWorksDW2012. Můj testovací virtuální počítač má přiděleny čtyři vCPU a plán provádění dotazů rozdělil řádky do čtyř vláken:

Nonclustered Columnstore Index Scan při použití paralelismu nepoužíval režim dávkového spuštění. Místo toho používal režim provádění řádku.
Zde je tabulka s dosavadními výsledky testů:
| Typ skenování | Úroveň kompatibility | Paralelní SELECT … INTO | Režim provádění | Trvání |
|---|---|---|---|---|
| Neclustered Columnstore Index Scan | 100 | Ne | Řádek | 3:19 |
| Neclustered Columnstore Index Scan | 110 | Ano | Řádek | 1:07 |
Takže jako další test jsem zrušil index neklastrovaný columnstore a znovu spustil SELECT ... INTO dotaz pomocí databázové kompatibility úrovně 100 a 110.
Spuštění testu úrovně kompatibility 100 trvalo 5 minut a 44 sekund a byl vygenerován následující plán:
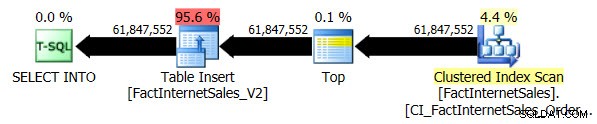
Sériové skenování indexu clusteru trvalo o 2 minuty a 25 sekund déle než sériové skenování indexu indexu Columnstore bez clusterů.
Při použití úrovně kompatibility 110 trvalo spuštění dotazu 1 minutu a 55 sekund a byl vygenerován následující plán:

Podobně jako u testu paralelního neshlukovaného indexového skenování Columnstore rozložilo paralelní skenování indexu clusteru řádky ve čtyřech vláknech:
Následující tabulka shrnuje tyto dva výše uvedené testy:
| Typ skenování | Úroveň kompatibility | Paralelní SELECT … INTO | Režim provádění | Trvání |
|---|---|---|---|---|
| Skenování seskupeného indexu | 100 | Ne | Řádek (není k dispozici) | 5:44 |
| Skenování seskupeného indexu | 110 | Ano | Řádek (není k dispozici) | 1:55 |
Takže jsem přemýšlel o výkonu pro clusterovaný index columnstore (nový v SQL Server 2014), takže jsem vypustil existující indexy a vytvořil clusterovaný index columnstore v tabulce FactInternetSales. Také jsem musel zrušit osm různých omezení cizích klíčů definovaných v tabulce, než jsem mohl vytvořit seskupený index columnstore.
Diskuse se stává poněkud akademickou, protože srovnávám SELECT ... INTO výkon na úrovních kompatibility databází, které původně nenabízely klastrované indexy columnstore – stejně jako dřívější testy pro neklastrované indexy columnstore na úrovni kompatibility databází 100 – a přesto je zajímavé vidět a porovnat celkové charakteristiky výkonu.
CREATE CLUSTERED COLUMNSTORE INDEX [CCSI_FactInternetSales] ON [dbo].[FactInternetSales] WITH (DROP_EXISTING = OFF); GO
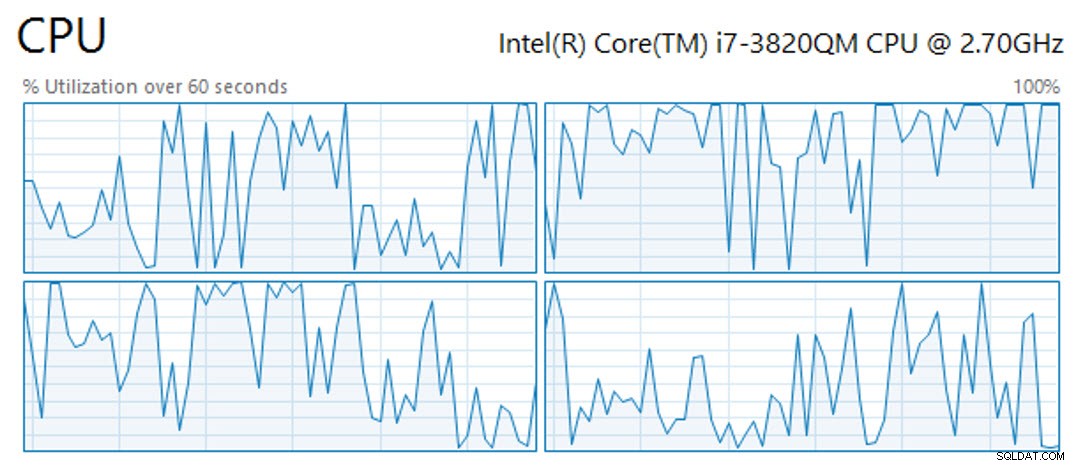
Kromě toho operace vytvoření klastrovaného indexu columnstore na 61 847 552 milionech řádkových tabulek trvala 11 minut a 25 sekund se čtyřmi dostupnými vCPU (z nichž operace využívala všechny), 4 GB RAM a virtuálním hostujícím úložištěm na OCZ Vertex SSD. Během této doby nebyly CPU po celou dobu fixovány, ale spíše zobrazovaly vrcholy a poklesy (níže ukázka 60 sekund aktivity CPU):
Po vytvoření seskupeného indexu columnstore jsem znovu provedl dva SELECT ... INTO testy. Spuštění testu úrovně kompatibility 100 trvalo 3 minuty a 22 sekund a plán byl podle očekávání sériový (ukazuji verzi plánu SQL Server Management Studio od clusterového skenování indexu Columnstore, od SQL Server 2014 CTP1 , ještě není plně rozpoznán Plan Explorer):

Dále jsem změnil úroveň kompatibility databáze na 110 a znovu spustil test, který tentokrát dotaz trval 1 minutu a 11 sekund a měl následující skutečný plán provádění:

Plán rozdělil řádky do čtyř vláken a stejně jako neklastrovaný index columnstore byl režim provádění klastrovaného prohledávání indexu Columnstore řádkový a ne dávkový.
Následující tabulka shrnuje všechny testy v tomto příspěvku (v pořadí podle trvání od nejnižší k nejvyšší):
| Typ skenování | Úroveň kompatibility | Paralelní SELECT … INTO | Režim provádění | Trvání |
|---|---|---|---|---|
| Neclustered Columnstore Index Scan | 110 | Ano | Řádek | 1:07 |
| Clustered Columnstore Index Scan | 110 | Ano | Řádek | 1:11 |
| Skenování seskupeného indexu | 110 | Ano | Řádek (není k dispozici) | 1:55 |
| Neclustered Columnstore Index Scan | 100 | Ne | Řádek | 3:19 |
| Clustered Columnstore Index Scan | 100 | Ne | Řádek | 3:22 |
| Skenování seskupeného indexu | 100 | Ne | Řádek (není k dispozici) | 5:44 |
Pár postřehů:
- Nejsem si jistý, zda je rozdíl mezi paralelním
SELECT ... INTOoperace proti indexu neshlukovaného úložiště sloupců oproti indexu seskupeného úložiště sloupců je statisticky významná. Potřeboval bych udělat více testů, ale myslím, že bych s jejich provedením počkal až do RTM. - Mohu s jistotou říci, že paralelní
SELECT ... INTOvýrazně překonaly sériové ekvivalenty v rámci testů indexu klastrovaného indexu, neklastrovaného úložiště sloupců a klastrovaného úložiště sloupců.
Stojí za zmínku, že tyto výsledky jsou pro CTP verzi produktu a moje testy by měly být vnímány jako něco, co by mohlo změnit chování RTM – takže mě méně zajímaly samostatné doby trvání oproti tomu, jak se tyto doby trvání porovnávaly mezi sériovým a paralelním podmínky.
Některé výkonové funkce vyžadují značné refaktoring – ale pro SELECT ... INTO zlepšení, vše, co jsem musel udělat, bylo zvýšit úroveň kompatibility databáze, abych začal vidět výhody, což je rozhodně něco, co oceňuji.