Seskupené zřetězení je běžný problém na SQL Serveru bez přímých a záměrných funkcí, které by jej podporovaly (jako XMLAGG v Oracle, STRING_AGG nebo ARRAY_TO_STRING(ARRAY_AGG()) v PostgreSQL a GROUP_CONCAT v MySQL). Bylo to vyžádáno, ale zatím bez úspěchu, jak dokládají tyto položky Connect:
- Connect #247118 :SQL potřebuje verzi funkce MySQL group_Concat (Odloženo)
- Připojení #728969 :Objednané funkce sady – klauzule WITHIN GROUP (uzavřená, protože se neopraví)
** AKTUALIZACE leden 2017 ** :STRING_AGG() bude v SQL Server 2017; přečtěte si o tom zde, zde a zde.
Co je seskupené zřetězení?
Pro nezasvěcené je seskupené zřetězení, když chcete vzít více řádků dat a zkomprimovat je do jednoho řetězce (obvykle s oddělovači, jako jsou čárky, tabulátory nebo mezery). Někdo by tomu mohl říkat „horizontální spojení“. Rychlý vizuální příklad demonstrující, jak bychom zkomprimovali seznam domácích mazlíčků patřících každému členovi rodiny, od normalizovaného zdroje po „zploštělý“ výstup:
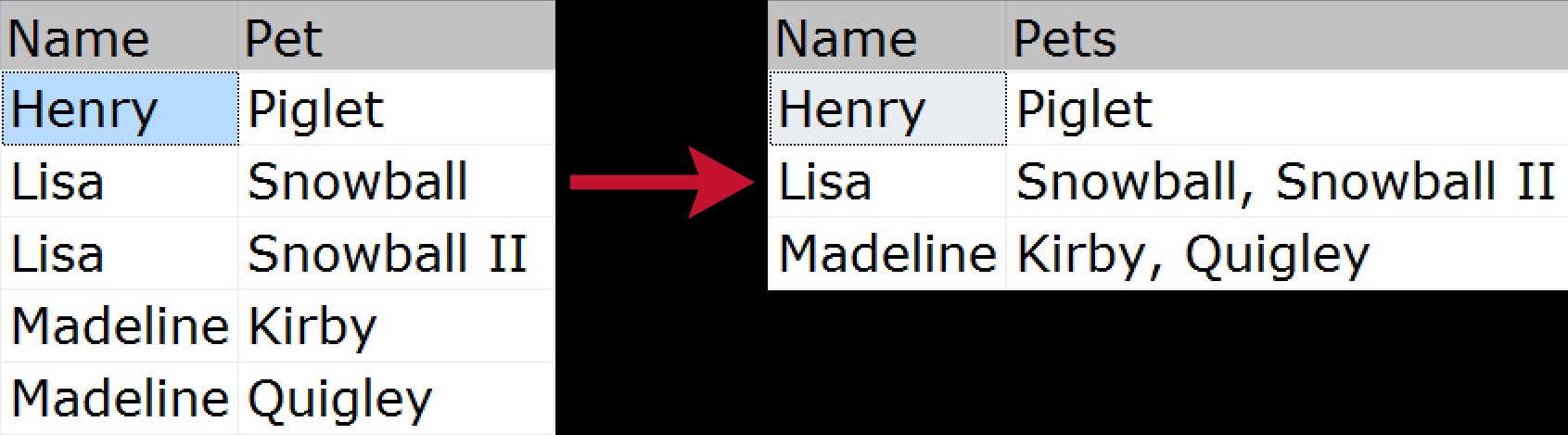
V průběhu let bylo mnoho způsobů, jak tento problém vyřešit; zde je jen několik na základě následujících ukázkových dat:
CREATE TABLE dbo.FamilyMemberPets ( Name SYSNAME, Pet SYSNAME, PRIMARY KEY(Name,Pet) ); INSERT dbo.FamilyMemberPets(Name,Pet) VALUES (N'Madeline',N'Kirby'), (N'Madeline',N'Quigley'), (N'Henry', N'Piglet'), (N'Lisa', N'Snowball'), (N'Lisa', N'Snowball II');
Nebudu demonstrovat vyčerpávající seznam všech přístupů seskupeného zřetězení, které byly kdy vytvořeny, protože se chci zaměřit na několik aspektů mého doporučeného přístupu, ale chci poukázat na několik z těch běžnějších:
Skalární UDF
CREATE FUNCTION dbo.ConcatFunction
(
@Name SYSNAME
)
RETURNS NVARCHAR(MAX)
WITH SCHEMABINDING
AS
BEGIN
DECLARE @s NVARCHAR(MAX);
SELECT @s = COALESCE(@s + N', ', N'') + Pet
FROM dbo.FamilyMemberPets
WHERE Name = @Name
ORDER BY Pet;
RETURN (@s);
END
GO
SELECT Name, Pets = dbo.ConcatFunction(Name)
FROM dbo.FamilyMemberPets
GROUP BY Name
ORDER BY Name; Poznámka:Existuje důvod, proč to neděláme:
SELECT DISTINCT Name, Pets = dbo.ConcatFunction(Name) FROM dbo.FamilyMemberPets ORDER BY Name;
Pomocí DISTINCT , funkce se spustí pro každý jednotlivý řádek, poté se odstraní duplikáty; pomocí GROUP BY , jsou nejprve odstraněny duplikáty.
Common Language Runtime (CLR)
Toto používá GROUP_CONCAT_S funkci naleznete na https://groupconcat.codeplex.com/:
SELECT Name, Pets = dbo.GROUP_CONCAT_S(Pet, 1) FROM dbo.FamilyMemberPets GROUP BY Name ORDER BY Name;
Rekurzivní CTE
Existuje několik variant této rekurze; tento vytáhne sadu odlišných jmen jako kotvu:
;WITH x as
(
SELECT Name, Pet = CONVERT(NVARCHAR(MAX), Pet),
r1 = ROW_NUMBER() OVER (PARTITION BY Name ORDER BY Pet)
FROM dbo.FamilyMemberPets
),
a AS
(
SELECT Name, Pet, r1 FROM x WHERE r1 = 1
),
r AS
(
SELECT Name, Pet, r1 FROM a WHERE r1 = 1
UNION ALL
SELECT x.Name, r.Pet + N', ' + x.Pet, x.r1
FROM x INNER JOIN r
ON r.Name = x.Name
AND x.r1 = r.r1 + 1
)
SELECT Name, Pets = MAX(Pet)
FROM r
GROUP BY Name
ORDER BY Name
OPTION (MAXRECURSION 0); Kurzor
Tady není moc co říct; kurzory obvykle nejsou optimální přístup, ale toto může být vaše jediná volba, pokud jste uvízli na serveru SQL Server 2000:
DECLARE @t TABLE(Name SYSNAME, Pets NVARCHAR(MAX),
PRIMARY KEY (Name));
INSERT @t(Name, Pets)
SELECT Name, N''
FROM dbo.FamilyMemberPets GROUP BY Name;
DECLARE @name SYSNAME, @pet SYSNAME, @pets NVARCHAR(MAX);
DECLARE c CURSOR LOCAL FAST_FORWARD
FOR SELECT Name, Pet
FROM dbo.FamilyMemberPets
ORDER BY Name, Pet;
OPEN c;
FETCH c INTO @name, @pet;
WHILE @@FETCH_STATUS = 0
BEGIN
UPDATE @t SET Pets += N', ' + @pet
WHERE Name = @name;
FETCH c INTO @name, @pet;
END
CLOSE c; DEALLOCATE c;
SELECT Name, Pets = STUFF(Pets, 1, 1, N'')
FROM @t
ORDER BY Name;
GO Svérázná aktualizace
Někteří lidé *milují* tento přístup; Vůbec nechápu tu přitažlivost.
DECLARE @Name SYSNAME, @Pets NVARCHAR(MAX);
DECLARE @t TABLE(Name SYSNAME, Pet SYSNAME, Pets NVARCHAR(MAX),
PRIMARY KEY (Name, Pet));
INSERT @t(Name, Pet)
SELECT Name, Pet FROM dbo.FamilyMemberPets
ORDER BY Name, Pet;
UPDATE @t SET @Pets = Pets = COALESCE(
CASE COALESCE(@Name, N'')
WHEN Name THEN @Pets + N', ' + Pet
ELSE Pet END, N''),
@Name = Name;
SELECT Name, Pets = MAX(Pets)
FROM @t
GROUP BY Name
ORDER BY Name; PRO CESTA XML
Docela snadno můj preferovaný způsob, alespoň částečně, protože je to jediný způsob, jak *zaručit* objednávku bez použití kurzoru nebo CLR. To znamená, že se jedná o velmi surovou verzi, která neřeší několik dalších inherentních problémů, o kterých budu dále diskutovat:
SELECT Name, Pets = STUFF((SELECT N', ' + Pet FROM dbo.FamilyMemberPets AS p2 WHERE p2.name = p.name ORDER BY Pet FOR XML PATH(N'')), 1, 2, N'') FROM dbo.FamilyMemberPets AS p GROUP BY Name ORDER BY Name;
Viděl jsem, že mnoho lidí mylně předpokládá, že nový CONCAT() funkce představená v SQL Server 2012 byla odpovědí na tyto požadavky na funkce. Tato funkce je určena pouze pro práci se sloupci nebo proměnnými v jednom řádku; nelze jej použít ke spojení hodnot mezi řádky.
Další informace o FOR XML PATH
FOR XML PATH('') sám o sobě není dost dobrý – má známé problémy s entitizací XML. Pokud například aktualizujete jedno ze jmen domácích zvířat tak, aby obsahovalo závorku HTML nebo ampersand:
UPDATE dbo.FamilyMemberPets SET Pet = N'Qui>gle&y' WHERE Pet = N'Quigley';
Ty se někde během cesty přeloží do entit bezpečných pro XML:
Qui>gle&y
Vždy tedy používám PATH, TYPE).value() , takto:
SELECT Name, Pets = STUFF((SELECT N', ' + Pet FROM dbo.FamilyMemberPets AS p2 WHERE p2.name = p.name ORDER BY Pet FOR XML PATH(N''), TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.FamilyMemberPets AS p GROUP BY Name ORDER BY Name;
Vždy také používám NVARCHAR , protože nikdy nevíte, kdy některý podkladový sloupec bude obsahovat Unicode (nebo bude později změněn).
V .value() můžete vidět následující varianty , nebo dokonce další:
... TYPE).value(N'.', ... ... TYPE).value(N'(./text())[1]', ...
Ty jsou zaměnitelné, všechny nakonec představují stejný řetězec; výkonnostní rozdíly mezi nimi (více níže) byly zanedbatelné a možná zcela nedeterministické.
Dalším problémem, se kterým se můžete setkat, jsou určité znaky ASCII, které nelze v XML reprezentovat; například pokud řetězec obsahuje znak 0x001A (CHAR(26) ), zobrazí se tato chybová zpráva:
FOR XML nemohl serializovat data pro uzel 'NoName', protože obsahuje znak (0x001A), který není v XML povolen. Chcete-li tato data načíst pomocí FOR XML, převeďte je na binární, varbinární nebo obrazový datový typ a použijte direktivu BINARY BASE64.
Zdá se mi to docela složité, ale doufejme, že se toho nemusíte obávat, protože data takto neukládáte nebo se je alespoň nesnažíte používat ve seskupeném zřetězení. Pokud ano, možná se budete muset vrátit k jednomu z dalších přístupů.
Výkon
Výše uvedená ukázková data umožňují snadno dokázat, že všechny tyto metody dělají to, co očekáváme, ale je těžké je smysluplně porovnávat. Vyplnil jsem tedy tabulku mnohem větší sadou:
TRUNCATE TABLE dbo.FamilyMemberPets; INSERT dbo.FamilyMemberPets(Name,Pet) SELECT o.name, c.name FROM sys.all_objects AS o INNER JOIN sys.all_columns AS c ON o.[object_id] = c.[object_id] ORDER BY o.name, c.name;
Pro mě to bylo 575 objektů s celkovým počtem 7 080 řádků; nejširší objekt měl 142 sloupů. Nyní znovu, pravda, neměl jsem v úmyslu porovnávat každý jednotlivý přístup v historii SQL Serveru; jen těch pár zajímavostí, které jsem zveřejnil výše. Zde byly výsledky:
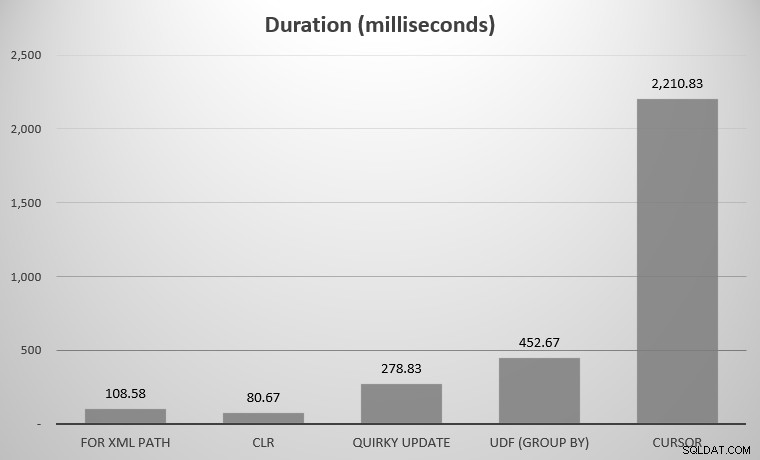
Můžete si všimnout, že chybí několik uchazečů; UDF pomocí DISTINCT a rekurzivní CTE byly tak mimo grafy, že by zkreslily měřítko. Zde jsou výsledky všech sedmi přístupů v tabulkové formě:
| Přístup | Trvání (milisekundy) |
|---|---|
| PRO CESTA XML | 108,58 |
| CLR | 80,67 |
| Zvláštní aktualizace | 278,83 |
| UDF (GROUP BY) | 452,67 |
| UDF (DISTINCT) | 5 893,67 |
| Kurzor | 2 210,83 |
| Rekurzivní CTE | 70 240,58 |
Průměrná doba trvání v milisekundách pro všechny přístupy
Všimněte si také, že varianty FOR XML PATH byly testovány nezávisle, ale vykazovaly velmi malé rozdíly, takže jsem je jen zkombinoval pro průměr. Pokud to opravdu chcete vědět, .[1] zápis v mých testech vyšel nejrychleji; YMMV.
Závěr
Pokud se nenacházíte v obchodě, kde je CLR jakýmkoliv způsobem překážkou, a zejména pokud neřešíte jen jednoduché názvy nebo jiné řetězce, měli byste určitě zvážit projekt CodePlex. Nepokoušejte se znovu vynalézt kolo, nezkoušejte neintuitivní triky a hacky, abyste vytvořili CROSS APPLY nebo jiné konstrukce fungují jen o něco rychleji než přístupy bez CLR výše. Vezměte to, co funguje, a zapojte to. A sakra, protože získáte i zdrojový kód, můžete jej vylepšit nebo rozšířit, pokud chcete.
Pokud je problém CLR, pak FOR XML PATH je pravděpodobně vaše nejlepší volba, ale stále si budete muset dávat pozor na záludné postavy. Pokud jste uvízli na serveru SQL Server 2000, jedinou možnou možností je UDF (nebo podobný kód nezabalený do UDF).
Příště
Pár věcí, které chci prozkoumat v následujícím příspěvku:odstranění duplikátů ze seznamu, seřazení seznamu podle něčeho jiného, než je samotná hodnota, případy, kdy může být vložení kteréhokoli z těchto přístupů do UDF bolestivé, a praktické případy použití pro tuto funkci.