Je toho tolik, co můžete říci o historii a významu. Historie země, civilizace, každého z nás. Miluji citáty a líbí se mi tento od Teddyho Roosevelta (super chlap):
Čím více víte o minulosti, tím lépe jste připraveni na budoucnost.Proč v blogu o SQL Serveru poeticky (nebo se o to pokouším) o historii? Protože historie v SQL Server je také důležitá. Pokud na serveru SQL Server existuje problém s výkonem, je ideální problém vyřešit naživo, ale v některých případech mohou historické informace poskytnout kouřící zbraň nebo alespoň výchozí bod. Skvělým zdrojem historických informací v SQL Server je ERRORLOG. Ve svém původním příspěvku, Performance Issues:The First Encounter, jsem zmínil, že ERRORLOG pro mě býval dodatečným nápadem. Už ne. Během klientských auditů vždy zachycujeme ERRORLOGy, a i když jsme upozorněni na jakákoli vysoce závažná upozornění (která se zapisují do protokolu), není neslýchané najít v protokolu další zajímavé informace. Připravujeme se na budoucnost pomocí historických informací v protokolech; informace nám mohou pomoci vyřešit problém nebo potenciální problém dříve, než se stane katastrofální.
Zobrazení ERRORLOG
Nejprve zkontrolujeme některé možnosti zobrazení ERROLOG. Pokud jsem připojen k instanci, obvykle k ní přejdu přes SSMS (Správa | Protokoly SQL Serveru, kliknu pravým tlačítkem na protokol a zvolím Zobrazit protokol SQL Serveru). Z tohoto okna mohu pouze procházet protokolem nebo použít možnosti Filtr nebo Hledat k zúžení sady výsledků. Mohu také zobrazit více souborů tak, že je vyberu v levém podokně.
Pokud se dívám na data zachycená v některém z našich zdravotních auditů, prostě otevřu soubory protokolu v textovém editoru a prohlédnu si je (mám možnost přejít do prohlížeče a načíst je také). Soubory protokolu existují ve složce protokolu (výchozí umístění:C:\Program Files\Microsoft SQL Server\MSSQL12.SQL2014\MSSQL\Log), pokud bych se na ně chtěl někdy podívat na serveru. Mnozí z vás možná preferují zobrazení a/nebo prohledání protokolu pomocí nezdokumentované procedury sp_readerrorlog nebo rozšířené uložené procedury xp_readerrorlog.
A konečně, pokud jste všichni v PowerShellu, je to také možnost, jak číst protokol tímto způsobem (viz tento příspěvek:Použijte PowerShell k analýze protokolů chyb SQL Server 2012). Metoda je na vás – použijte to, co znáte a co vám vyhovuje – na obsahu skutečně záleží. A pamatujte si, že jsou chvíle, kdy budete muset jednoduše přečíst protokol, abyste pochopili pořadí událostí, a jindy můžete hledat konkrétní chybu nebo informaci.
Co je v ERRORLOG?
Jaké informace tedy kromě chyb můžeme najít v ERRORLOGU? Níže jsem uvedl mnoho položek, které mi přišly nejužitečnější. Všimněte si, že toto není vyčerpávající seznam (a jsem si jistý, že mnozí z vás budou mít návrhy, co by se mohlo přidat – neváhejte napsat komentář a já to mohu aktualizovat!), ale znovu, to jsem já hledá první když se proaktivně dívám na instanci.
- Zda je server fyzický nebo virtuální (hledejte položku System Manufacturer)
- Příznaky trasování povoleny při spuštění
- Pokud se v položce pro parametry spouštění registru posunete úplně doprava, uvidíte, zda jsou povoleny nějaké příznaky trasování:
 Příznaky trasování povoleny při spuštění
Příznaky trasování povoleny při spuštění
- Pokud se v položce pro parametry spouštění registru posunete úplně doprava, uvidíte, zda jsou povoleny nějaké příznaky trasování:
- Příznaky trasování povoleny nebo zakázány po spuštění instance
- Pokud uživatelé (nebo aplikace) povolí nebo zakážou příznak trasování pomocí DBCC TRACEON nebo DBCC TRACEOFF, zobrazí se v protokolu záznam
- Počet jader a soketů zjištěných SQL Serverem
- Vždy si rád ověřuji, že SQL Server vidí veškerý dostupný hardware – a pokud ne, je to varovný signál k dalšímu zkoumání. Dobrým příkladem je Jonathanův příspěvek Problémy s výkonem s SQL Server 0212 Enterprise Edition v rámci licencování CAL a Glennův příspěvek Rovnoměrné vyrovnávání dostupných základních licencí SQL Server mezi uzly NUMA, který také obsahuje užitečné TSQL pro dotazování na protokol.
- Všimněte si, že text této položky se v různých verzích SQL Serveru liší.
- Množství paměti zjištěné SQL Serverem
- Znovu chci ověřit, že SQL Server vidí veškerou paměť, která je pro něj dostupná.
- Potvrzení, že jsou povoleny uzamčené stránky v paměti (LPIM)
- I když je tato možnost povolena prostřednictvím zásad zabezpečení systému Windows, můžete potvrdit, že je povolena, vyhledáním zprávy „Používání zamčených stránek ve správci paměti“ v protokolu.
- Všimněte si, že pokud používáte příznak trasování 834, pak zpráva nebude říkat zamčené stránky, ale že se pro fond vyrovnávacích pamětí používají velké stránky.
- Použitá verze CLR
- Úspěch nebo selhání registrace hlavního názvu služby (SPN)
- Jak dlouho trvá, než se databáze uvede do režimu online
- Protokol zaznamenává, kdy se databáze spouští a když je online – zkontroluji, zda nějaká databáze netrvá příliš dlouho, než se objeví.
- Stav koncových bodů Service Broker a Database Mirroring – důležité, pokud používáte některou z funkcí
- Potvrzení, že je povolena okamžitá inicializace souboru (IFI)*
- Ve výchozím nastavení se tyto informace nezaprotokolují, ale pokud povolíte Trace Flag 3004 (a 3605 pro vynucení výstupu do protokolu), když vytvoříte nebo zvětšíte datový soubor, uvidíte v protokolu zprávy, které označují, zda IFI se používá nebo ne.
- Stav trasování SQL
- Když spustíte nebo zastavíte trasování SQL, zaprotokoluje se a já se podívám, zda existují nějaká trasování mimo výchozí trasování (dočasně nebo dlouhodobě). Pokud spouštíte monitorovací nástroj třetí strany, jako je SQL Sentry's Performance Advisor, můžete vidět aktivní trasování, které je vždy spuštěno, ale zachycuje pouze určité události, nebo můžete vidět spuštění trasování, spuštěné na krátkou dobu, pak stop. Nezajímá mě jedna nebo dvě další trasování, pokud nezachycují mnoho událostí, ale rozhodně věnuji pozornost, když běží více tras.
- Naposledy bylo dokončeno CHECKDB
- Tuto zprávu lidé často nechápou – když se instance spustí, přečte spouštěcí stránku pro každou databázi a zaznamená, kdy naposledy úspěšně proběhl CHECKDB. Většina lidí nečte celou zprávu:
 Datum posledního úspěšného dokončení DBCC CHECKDB
Datum posledního úspěšného dokončení DBCC CHECKDB Datum dokončení CHECKDB je 11. listopadu 2012, ale datum ERRORLOG je 7. července 2015. Je důležité si uvědomit, že SQL Server ne spusťte CHECKDB proti databázím při spuštění, zkontroluje hodnotu dbcclastknowngood na spouštěcí stránce (chcete-li zjistit, kdy se aktualizuje, podívejte se na můj příspěvek What Checks Update dbcclastknowngood. Také, pokud DBCC CHECKDB nebyl nikdy spuštěn proti databázi, pak žádná položka se zobrazí pro databázi zde.
- Tuto zprávu lidé často nechápou – když se instance spustí, přečte spouštěcí stránku pro každou databázi a zaznamená, kdy naposledy úspěšně proběhl CHECKDB. Většina lidí nečte celou zprávu:
- Dokončení CHECKDB
- Při spuštění CHECKDB proti databázi se výstup zaznamená do protokolu.
- Změny nastavení instance
- Pokud změníte nastavení na úrovni instance (např. maximální paměť serveru, prahovou hodnotu nákladů pro paralelismus) pomocí sp_configure nebo prostřednictvím uživatelského rozhraní (všimněte si, že nezaznamenává kdo změnil).
- Změny nastavení databáze
- Povolil někdo AUTO_SHRINK? Změnit možnost OBNOVENÍ na JEDNODUCHÉ a poté zpět na PLNÉ? Najdete ho zde.
- Změny stavu databáze
- Pokud někdo přepne databázi do režimu OFFLINE (nebo ji převede ONLINE), zaznamená se to.
- Informace o uváznutí*
- Pokud potřebujete zachytit informace o uváznutí, nechcete spouštět trasování, a používáte SQL Server 2005 až 2008R2, použijte příznak trasování 1222 k zápisu informací o uváznutí do protokolu ve formátu XML. Pro ty z vás, kteří používají SQL Server 2000 a nižší, můžete trasovat příznak 1204 (tento příznak trasování je k dispozici také v SQL Server 2005+, ale poskytuje minimální informace). Pokud používáte SQL Server 2012 nebo vyšší, není to potřeba, protože relace události system_health tyto informace zachycuje (a je tam i v letech 2008 a 20082, ale musíte je stáhnout z ring_buffer oproti cíli event_file).
- Zprávy FlushCache
- Pokud SQL Server vyprázdní mezipaměť, protože proces kontrolního bodu překročí interval obnovy databáze, uvidíte v protokolu sadu zpráv FlushCache (další informace naleznete v tomto příspěvku Boba Dorra). Nepleťte si tyto zprávy s těmi, které se zobrazují při spuštění DBCC FREEPROCCACHE nebo DBCC FREESYSTEMCACHE:
 Zpráva po spuštění DBCC FREEPROCCACHE nebo DBCC FREESYSTEMCACHE
Zpráva po spuštění DBCC FREEPROCCACHE nebo DBCC FREESYSTEMCACHE
- Pokud SQL Server vyprázdní mezipaměť, protože proces kontrolního bodu překročí interval obnovy databáze, uvidíte v protokolu sadu zpráv FlushCache (další informace naleznete v tomto příspěvku Boba Dorra). Nepleťte si tyto zprávy s těmi, které se zobrazují při spuštění DBCC FREEPROCCACHE nebo DBCC FREESYSTEMCACHE:
- Zprávy o uvolnění z domény AppDomain
- Protokol také zaznamenává, kdy jsou vytvořeny domény AppDomains, a zobrazí se pouze v případě, že používáte CLR. Pokud vidím, že AppDomain uvolňuje zprávy kvůli tlaku paměti, je třeba to dále prozkoumat.
V protokolu jsou další užitečné informace, jako je používaný režim ověřování, zda je či není povoleno připojení Dedicated Admin Connection (DAC) atd., ale mohu je také získat z sys.configurations a zkontroluji je se základními liniemi instance Diskutoval jsem dříve (Proaktivní kontroly stavu serveru SQL, část 3:Nastavení instance a databáze).
Co v ERROLOGU není, co byste mohli očekávat?
Toto je prozatím krátký seznam, protože hádám, že někteří z vás možná našli další věci, o kterých si mysleli, že budou v protokolu, ale nebyly...
- Přidání nebo odebrání databázových souborů nebo skupin souborů
- Spouštění nebo zastavování relací Extended Events
- Pokud však nasadíte spouštěč DDL nebo oznámení o události na úrovni serveru, můžete tyto informace zaprotokolovat. Další podrobnosti naleznete v příspěvku Jonathana, Logging Extended Events changes to ERRORLOG.
- Spuštění DBCC DROPCLEANBUFFERS se zobrazí v ERRORLOG
Správa protokolu
Pamatujte, že ve výchozím nastavení SQL Server uchovává pouze posledních šest (6) souborů protokolu (kromě aktuálního souboru) a soubor protokolu se obnoví pokaždé, když se SQL Server restartuje. V důsledku toho můžete mít někdy extrémně velké soubory protokolu, jejichž otevření chvíli trvá a je těžké se v nich prohrabat. Na druhou stranu, pokud narazíte na případ, kdy se instance několikrát restartuje, můžete ztratit důležité informace. Doporučuje se zvýšit počet uchovaných souborů na vyšší hodnotu (např. 30) a vytvořit úlohu agenta, která bude soubor převádět jednou týdně pomocí sp_cycle_errorlog.
Kromě správy souborů můžete ovlivnit, jaké informace se zapisují do protokolu. Jednou z nejběžnějších položek, které vytvářejí nepořádek v ERRORLOG, je úspěšná záloha:
 Zálohování bylo úspěšně dokončeno
Zálohování bylo úspěšně dokončeno
Pokud máte instanci s mnoha databázemi a zálohy protokolu transakcí se pořizují s jakoukoli pravidelností (např. každých 15 minut), uvidíte, že se protokol rychle zaplní zprávami, což ztěžuje nalezení skutečného problému. Naštěstí můžete použít příznak trasování 3226 k deaktivaci zpráv o úspěšném zálohování (chyby se budou stále zobrazovat v protokolu a všechny položky budou stále existovat v msdb).
Další sada zpráv, které zahlcují protokol, jsou zprávy o úspěšném přihlášení. Toto je možnost, kterou konfigurujete pro instanci na kartě Zabezpečení:
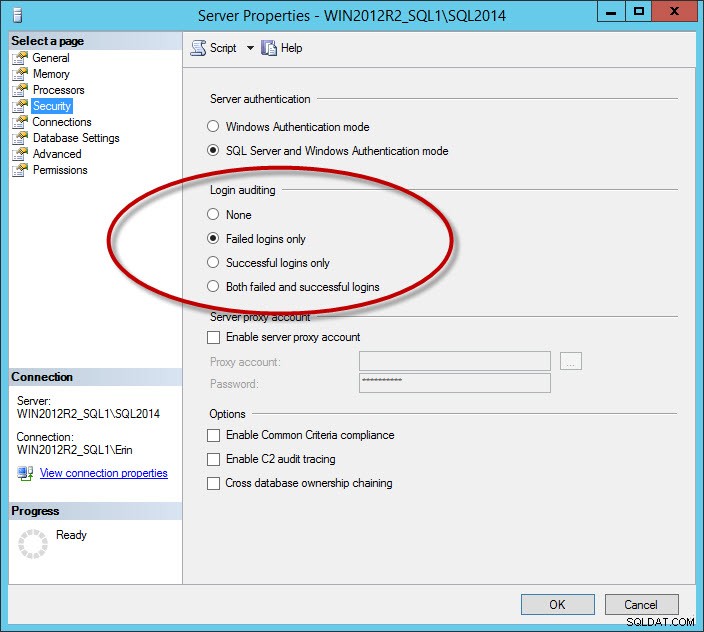 Možnost zabezpečení pro protokolování úspěšných a/nebo neúspěšných přihlášení
Možnost zabezpečení pro protokolování úspěšných a/nebo neúspěšných přihlášení
Pokud zaznamenáte úspěšná přihlášení nebo neúspěšná a úspěšná přihlášení, můžete mít velmi velké soubory protokolu, i když soubory denně převracíte (záleží na tom, kolik uživatelů se připojí). Doporučuji zachytit pouze neúspěšná přihlášení. U podniků, které vyžadují protokolování úspěšných přihlášení, zvažte použití funkce Audit přidané v SQL Server 2008. Poznámka:Pokud změníte nastavení auditování přihlášení, neprojeví se to, dokud nerestartujete instanci.
Nepodceňujte ERRORLOG
Jak vidíte, v ERRORLOGu je několik skvělých informací, které můžete použít nejen při odstraňování problémů s výkonem nebo vyšetřování chyb, ale také při proaktivním monitorování instance. V protokolu můžete najít informace, které nikde jinde nenajdete; ujistěte se, že to pravidelně kontrolujete a nenecháte to jako dodatečný nápad.
Podívejte se na další díly této série:
- Část 1:Místo na disku
- Část 2:Údržba
- Část 3:Nastavení instance a databáze