Tým SQLskills miluje statistiky čekání. Když si prohlédnete příspěvky na tomto blogu (viz Paulovy příspěvky na Knee-Jerk Wait Statistics) a na webu SQLskills, uvidíte příspěvky od nás všech diskutujících o hodnotě statistik čekání, o tom, co hledáme a proč konkrétní čekání je problém. Paul o tom píše nejvíce, ale každý z nás obvykle začíná statistikou čekání, když řeší problém s výkonem. Co to znamená být proaktivní?
Abyste získali úplný obrázek o tom, co znamenají statistiky čekání během problému s výkonem, musíte vědět, jaká jsou vaše normální čekání. To znamená proaktivně zachycovat tyto informace a používat je jako referenci. Pokud tato data nemáte, pak když dojde k problému s výkonem, nebudete vědět, zda jsou ve vašem prostředí typické čekání PAGELATCH (docela možné), nebo pokud máte náhle problém související s tempdb kvůli nějakému novému kódu, který byl přidán. .
Údaje statistiky čekání
Již dříve jsem publikoval skript, který používám k zachycení statistik čekání, a je to skript, který pro klienty používám dlouhou dobu. Nedávno jsem však provedl změny ve svém skriptu a mírně upravil svou metodu. Dovolte mi vysvětlit proč…
Základním předpokladem statistiky čekání je, že SQL Server sleduje pokaždé, když vlákno musí na „něco čekat“. Čekáte na čtení stránky z disku? PAGEIOLATCH_XX počkat. Čekáte na udělení zámku, abyste provedli úpravu dat? LCX_M_XXX čekat. Čeká se na přidělení paměti, aby bylo možné provést dotaz? RESOURCE_SEMAPHORE počkat. Všechna tato čekání jsou sledována v sys.dm_os_wait_stats DMV a data se v průběhu času jen shromažďují... je to kumulativní zástupce čekání.
Například mám instanci SQL Server 2014 v jednom z mých virtuálních počítačů, který je aktivní a zhruba od 9:30 dnes ráno:
SELECT [sqlserver_start_time] FROM [sys].[dm_os_sys_info];
 Čas spuštění serveru SQL
Čas spuštění serveru SQL
Když se nyní podívám, jak vypadají moje statistiky čekání (pamatujte, až dosud kumulativní) pomocí Paulova skriptu, vidím, že TRACEWRITE je moje současné „standardní“ čekání:
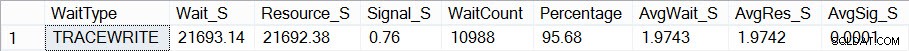 Aktuální souhrnné čekání
Aktuální souhrnné čekání
Dobře, nyní představíme pět minut sporu o tempdb a uvidíme, jak to ovlivní mé celkové statistiky čekání. Mám skript, který Jonathan dříve použil k vytvoření soupeření tempdb, a nastavil jsem ho tak, aby běžel 5 minut:
USE AdventureWorks2012;
GO
SET NOCOUNT ON;
GO
DECLARE @CurrentTime SMALLDATETIME = SYSDATETIME(), @EndTime SMALLDATETIME = DATEADD(MINUTE, 5, SYSDATETIME());
WHILE @CurrentTime < @EndTime
BEGIN
IF OBJECT_ID('tempdb..#temp') IS NOT NULL
BEGIN
DROP TABLE #temp;
END
CREATE TABLE #temp
(
ProductID INT PRIMARY KEY,
OrderQty INT,
TotalDiscount MONEY,
LineTotal MONEY,
Filler NCHAR(500) DEFAULT(N'') NOT NULL
);
INSERT INTO #temp(ProductID, OrderQty, TotalDiscount, LineTotal)
SELECT
sod.ProductID,
SUM(sod.OrderQty),
SUM(sod.LineTotal),
SUM(sod.OrderQty + sod.UnitPriceDiscount)
FROM Sales.SalesOrderDetail AS sod
GROUP BY ProductID;
DECLARE
@ProductNumber NVARCHAR(25),
@Name NVARCHAR(50),
@TotalQty INT,
@SalesTotal MONEY,
@TotalDiscount MONEY;
SELECT
@ProductNumber = p.ProductNumber,
@Name = p.Name,
@TotalQty = t1.OrderQty,
@SalesTotal = t1.LineTotal,
@TotalDiscount = t1.TotalDiscount
FROM Production.Product AS p
JOIN #temp AS t1 ON p.ProductID = t1.ProductID;
SET @CurrentTime = SYSDATETIME()
END Použil jsem příkazový řádek ke spuštění 10 relací, které spustily tento skript, a současně jsem spustil skript, který zachytil moji celkovou statistiku čekání, snímek čekání za 5 minut a poté znovu celkovou statistiku čekání. Za prvé, malé tajemství, protože benigní čekání neustále ignorujeme, může být užitečné nacpat je do tabulky, abyste mohli odkazovat na objekt, místo abyste museli neustále tvrdě kódovat seznam řetězců vyloučení v dotazu. Takže:
USE SQLskills_WaitStats; GO CREATE TABLE dbo.WaitsToIgnore(WaitType SYSNAME PRIMARY KEY); INSERT dbo.WaitsToIgnore(WaitType) VALUES(N'BROKER_EVENTHANDLER'), (N'BROKER_RECEIVE_WAITFOR'), (N'BROKER_TASK_STOP'), (N'BROKER_TO_FLUSH'), (N'BROKER_TRANSMITTER'), (N'CHECKPOINT_QUEUE'), (N'CHKPT'), (N'CLR_AUTO_EVENT'), (N'CLR_MANUAL_EVENT'), (N'CLR_SEMAPHORE'), (N'DBMIRROR_DBM_EVENT'), (N'DBMIRROR_EVENTS_QUEUE'), (N'DBMIRROR_WORKER_QUEUE'), (N'DBMIRRORING_CMD'), (N'DIRTY_PAGE_POLL'), (N'DISPATCHER_QUEUE_SEMAPHORE'), (N'EXECSYNC'), (N'FSAGENT'), (N'FT_IFTS_SCHEDULER_IDLE_WAIT'), (N'FT_IFTSHC_MUTEX'), (N'HADR_CLUSAPI_CALL'), (N'HADR_FILESTREAM_IOMGR_IOCOMPLETIO(N'), (N'HADR_LOGCAPTURE_WAIT'), (N'HADR_NOTIFICATION_DEQUEUE'), (N'HADR_TIMER_TASK'), (N'HADR_WORK_QUEUE'), (N'KSOURCE_WAKEUP'), (N'LAZYWRITER_SLEEP'), (N'LOGMGR_QUEUE'), (N'ONDEMAND_TASK_QUEUE'), (N'PWAIT_ALL_COMPONENTS_INITIALIZED'), (N'QDS_PERSIST_TASK_MAIN_LOOP_SLEEP'), (N'QDS_CLEANUP_STALE_QUERIES_TASK_MAIN_LOOP_SLEEP'), (N'REQUEST_FOR_DEADLOCK_SEARCH'), (N'RESOURCE_QUEUE'), (N'SERVER_IDLE_CHECK'), (N'SLEEP_BPOOL_FLUSH'), (N'SLEEP_DBSTARTUP'), (N'SLEEP_DCOMSTARTUP'), (N'SLEEP_MASTERDBREADY'), (N'SLEEP_MASTERMDREADY'), (N'SLEEP_MASTERUPGRADED'), (N'SLEEP_MSDBSTARTUP'), (N'SLEEP_SYSTEMTASK'), (N'SLEEP_TASK'), (N'SLEEP_TEMPDBSTARTUP'), (N'SNI_HTTP_ACCEPT'), (N'SP_SERVER_DIAGNOSTICS_SLEEP'), (N'SQLTRACE_BUFFER_FLUSH'), (N'SQLTRACE_INCREMENTAL_FLUSH_SLEEP'), (N'SQLTRACE_WAIT_ENTRIES'), (N'WAIT_FOR_RESULTS'), (N'WAITFOR'), (N'WAITFOR_TASKSHUTDOW(N'), (N'WAIT_XTP_HOST_WAIT'), (N'WAIT_XTP_OFFLINE_CKPT_NEW_LOG'), (N'WAIT_XTP_CKPT_CLOSE'), (N'XE_DISPATCHER_JOIN'), (N'XE_DISPATCHER_WAIT'), (N'XE_TIMER_EVENT');
Nyní jsme připraveni zachytit naše čekání:
/* Capture the instance start time
(in this case, time since waits have been accumulating) */
SELECT [sqlserver_start_time] FROM [sys].[dm_os_sys_info];
GO
/* Get the current time */
SELECT SYSDATETIME() AS [Before Test 1];
/* Get aggregate waits until now */
WITH [Waits] AS
(
SELECT
[wait_type],
[wait_time_ms] / 1000.0 AS [WaitS],
([wait_time_ms] - [signal_wait_time_ms]) / 1000.0 AS [ResourceS],
[signal_wait_time_ms] / 1000.0 AS [SignalS],
[waiting_tasks_count] AS [WaitCount],
100.0 * [wait_time_ms] / SUM ([wait_time_ms]) OVER() AS [Percentage],
ROW_NUMBER() OVER(ORDER BY [wait_time_ms] DESC) AS [RowNum]
FROM sys.dm_os_wait_stats
WHERE [wait_type] NOT IN (SELECT WaitType FROM SQLskills_Waits.WaitsToIgnore)
AND [waiting_tasks_count] > 0
)
SELECT
MAX ([W1].[wait_type]) AS [WaitType],
CAST (MAX ([W1].[WaitS]) AS DECIMAL (16,2)) AS [Wait_S],
CAST (MAX ([W1].[ResourceS]) AS DECIMAL (16,2)) AS [Resource_S],
CAST (MAX ([W1].[SignalS]) AS DECIMAL (16,2)) AS [Signal_S],
MAX ([W1].[WaitCount]) AS [WaitCount],
CAST (MAX ([W1].[Percentage]) AS DECIMAL (5,2)) AS [Percentage],
CAST ((MAX ([W1].[WaitS]) / MAX ([W1].[WaitCount])) AS DECIMAL (16,4)) AS [AvgWait_S],
CAST ((MAX ([W1].[ResourceS]) / MAX ([W1].[WaitCount])) AS DECIMAL (16,4)) AS [AvgRes_S],
CAST ((MAX ([W1].[SignalS]) / MAX ([W1].[WaitCount])) AS DECIMAL (16,4)) AS [AvgSig_S]
FROM [Waits] AS [W1]
INNER JOIN [Waits] AS [W2]
ON [W2].[RowNum] <= [W1].[RowNum]
GROUP BY [W1].[RowNum]
HAVING SUM ([W2].[Percentage]) - MAX ([W1].[Percentage]) < 95; -- percentage threshold
GO
/* Get the current time */
SELECT SYSDATETIME() AS [Before Test 2];
/* Capture a snapshot of waits over a 5 minute period */
IF EXISTS (SELECT * FROM [tempdb].[sys].[objects] WHERE [name] = N'##SQLskillsStats1')
DROP TABLE [##SQLskillsStats1];
IF EXISTS (SELECT * FROM [tempdb].[sys].[objects] WHERE [name] = N'##SQLskillsStats2')
DROP TABLE [##SQLskillsStats2];
GO
SELECT [wait_type], [waiting_tasks_count], [wait_time_ms],
[max_wait_time_ms], [signal_wait_time_ms]
INTO ##SQLskillsStats1
FROM sys.dm_os_wait_stats;
GO
WAITFOR DELAY '00:05:00';
GO
SELECT [wait_type], [waiting_tasks_count], [wait_time_ms],
[max_wait_time_ms], [signal_wait_time_ms]
INTO ##SQLskillsStats2
FROM sys.dm_os_wait_stats;
GO
WITH [DiffWaits] AS
(
SELECT -- Waits that weren't in the first snapshot
[ts2].[wait_type],
[ts2].[wait_time_ms],
[ts2].[signal_wait_time_ms],
[ts2].[waiting_tasks_count]
FROM [##SQLskillsStats2] AS [ts2]
LEFT OUTER JOIN [##SQLskillsStats1] AS [ts1]
ON [ts2].[wait_type] = [ts1].[wait_type]
WHERE [ts1].[wait_type] IS NULL
AND [ts2].[wait_time_ms] > 0
UNION
SELECT -- Diff of waits in both snapshots
[ts2].[wait_type],
[ts2].[wait_time_ms] - [ts1].[wait_time_ms] AS [wait_time_ms],
[ts2].[signal_wait_time_ms] - [ts1].[signal_wait_time_ms] AS [signal_wait_time_ms],
[ts2].[waiting_tasks_count] - [ts1].[waiting_tasks_count] AS [waiting_tasks_count]
FROM [##SQLskillsStats2] AS [ts2]
LEFT OUTER JOIN [##SQLskillsStats1] AS [ts1]
ON [ts2].[wait_type] = [ts1].[wait_type]
WHERE [ts1].[wait_type] IS NOT NULL
AND [ts2].[waiting_tasks_count] - [ts1].[waiting_tasks_count] > 0
AND [ts2].[wait_time_ms] - [ts1].[wait_time_ms] > 0
),
[Waits] AS
(
SELECT
[wait_type],
[wait_time_ms] / 1000.0 AS [WaitS],
([wait_time_ms] - [signal_wait_time_ms]) / 1000.0 AS [ResourceS],
[signal_wait_time_ms] / 1000.0 AS [SignalS],
[waiting_tasks_count] AS [WaitCount],
100.0 * [wait_time_ms] / SUM ([wait_time_ms]) OVER() AS [Percentage],
ROW_NUMBER() OVER(ORDER BY [wait_time_ms] DESC) AS [RowNum]
FROM [DiffWaits]
WHERE [wait_type] NOT IN (SELECT WaitType FROM SQLskills_WaitStats.dbo.WaitsToIgnore)
)
SELECT
[W1].[wait_type] AS [WaitType],
CAST ([W1].[WaitS] AS DECIMAL (16, 2)) AS [Wait_S],
CAST ([W1].[ResourceS] AS DECIMAL (16, 2)) AS [Resource_S],
CAST ([W1].[SignalS] AS DECIMAL (16, 2)) AS [Signal_S],
[W1].[WaitCount] AS [WaitCount],
CAST ([W1].[Percentage] AS DECIMAL (5, 2)) AS [Percentage],
CAST (([W1].[WaitS] / [W1].[WaitCount]) AS DECIMAL (16, 4)) AS [AvgWait_S],
CAST (([W1].[ResourceS] / [W1].[WaitCount]) AS DECIMAL (16, 4)) AS [AvgRes_S],
CAST (([W1].[SignalS] / [W1].[WaitCount]) AS DECIMAL (16, 4)) AS [AvgSig_S]
FROM [Waits] AS [W1]
INNER JOIN [Waits] AS [W2]
ON [W2].[RowNum] <= [W1].[RowNum]
GROUP BY [W1].[RowNum], [W1].[wait_type], [W1].[WaitS],
[W1].[ResourceS], [W1].[SignalS], [W1].[WaitCount], [W1].[Percentage]
HAVING SUM ([W2].[Percentage]) - [W1].[Percentage] < 95; -- percentage threshold
GO
-- Cleanup
IF EXISTS (SELECT * FROM [tempdb].[sys].[objects] WHERE [name] = N'##SQLskillsStats1')
DROP TABLE [##SQLskillsStats1];
IF EXISTS (SELECT * FROM [tempdb].[sys].[objects] WHERE [name] = N'##SQLskillsStats2')
DROP TABLE [##SQLskillsStats2];
GO
/* Get the current time */
SELECT SYSDATETIME() AS [After Test 1];
/* Get aggregate waits again */
WITH [Waits] AS
(
SELECT
[wait_type],
[wait_time_ms] / 1000.0 AS [WaitS],
([wait_time_ms] - [signal_wait_time_ms]) / 1000.0 AS [ResourceS],
[signal_wait_time_ms] / 1000.0 AS [SignalS],
[waiting_tasks_count] AS [WaitCount],
100.0 * [wait_time_ms] / SUM ([wait_time_ms]) OVER() AS [Percentage],
ROW_NUMBER() OVER(ORDER BY [wait_time_ms] DESC) AS [RowNum]
FROM sys.dm_os_wait_stats
WHERE [wait_type] NOT IN (SELECT WaitType FROM SQLskills_WaitStats.dbo.WaitsToIgnore)
AND [waiting_tasks_count] > 0
)
SELECT
MAX ([W1].[wait_type]) AS [WaitType],
CAST (MAX ([W1].[WaitS]) AS DECIMAL (16,2)) AS [Wait_S],
CAST (MAX ([W1].[ResourceS]) AS DECIMAL (16,2)) AS [Resource_S],
CAST (MAX ([W1].[SignalS]) AS DECIMAL (16,2)) AS [Signal_S],
MAX ([W1].[WaitCount]) AS [WaitCount],
CAST (MAX ([W1].[Percentage]) AS DECIMAL (5,2)) AS [Percentage],
CAST ((MAX ([W1].[WaitS]) / MAX ([W1].[WaitCount])) AS DECIMAL (16,4)) AS [AvgWait_S],
CAST ((MAX ([W1].[ResourceS]) / MAX ([W1].[WaitCount])) AS DECIMAL (16,4)) AS [AvgRes_S],
CAST ((MAX ([W1].[SignalS]) / MAX ([W1].[WaitCount])) AS DECIMAL (16,4)) AS [AvgSig_S]
FROM [Waits] AS [W1]
INNER JOIN [Waits] AS [W2]
ON [W2].[RowNum] <= [W1].[RowNum]
GROUP BY [W1].[RowNum]
HAVING SUM ([W2].[Percentage]) - MAX ([W1].[Percentage]) < 95; -- percentage threshold
GO
/* Get the current time */
SELECT SYSDATETIME() AS [After Test 2]; Když se podíváme na výstup, můžeme vidět, že zatímco běželo 10 instancí skriptu pro vytvoření soupeření tempdb, SOS_SCHEDULER_YIELD byl náš nejběžnější typ čekání a podle očekávání jsme měli také čekání PAGELATCH_XX:
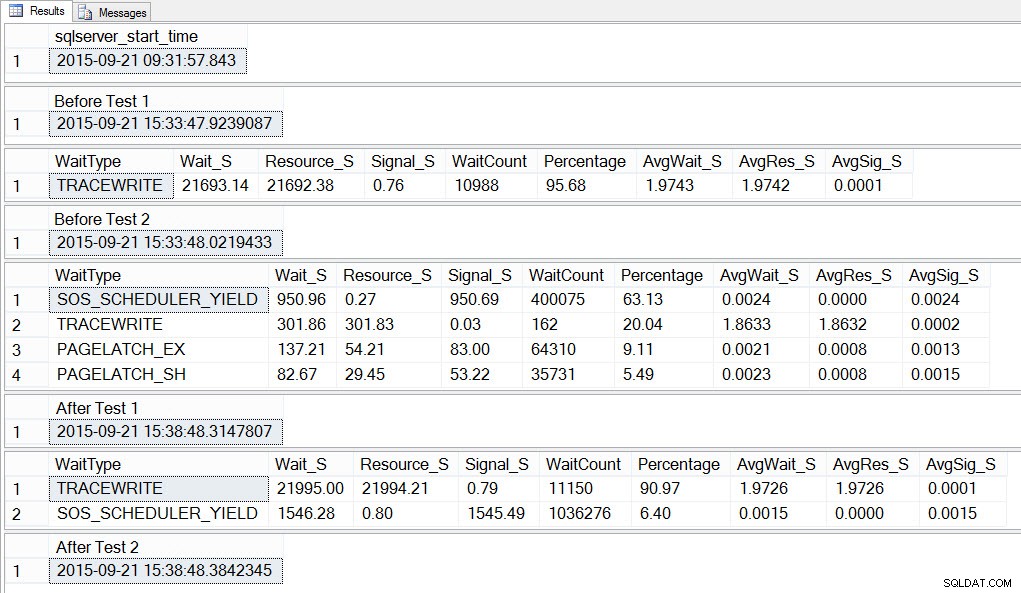
Pokud se podíváme na průměrnou čekací dobu PO dokončení testu, opět vidíme TRACEWRITE jako nejvyšší čekací dobu a SOS_SCHEDULER_YIELD vidíme jako čekání. V závislosti na tom, co ještě běží v prostředí, toto čekání může, ale nemusí přetrvávat v našich nejvyšších čekáních po dlouhou dobu a může, ale nemusí, probublávat jako typ čekání na prošetření.
Proaktivní zachycování statistik čekání
Ve výchozím nastavení jsou statistiky čekání kumulativní . Ano, můžete je kdykoli vymazat pomocí DBCC SQLPERF, ale zjistil jsem, že většina lidí to nedělá pravidelně, jen je nechávají hromadit. A to je v pořádku, ale pochopte, jak to ovlivňuje vaše data. Pokud svou instanci restartujete pouze při opravě nebo když dojde k problému (což se, doufejme, nestává často), mohou se tato data hromadit měsíce. Čím více dat máte, tím těžší je vidět malé odchylky… věci, které by mohly představovat problémy s výkonem. I když máte „velký problém“, který na několik minut ovlivňuje celý váš server, jako jsme to udělali zde s tempdb, nemusí to způsobit dostatečnou změnu ve vašich datech, aby byla detekována v kumulovaných datech. Spíše potřebujete pořídit snímek dat (zaznamenat je, počkat několik minut, znovu je zachytit a poté data porovnat), abyste viděli, co se skutečně děje právě .
Pokud tedy každých pár hodin zaznamenáte statistiku čekání, shromážděná data pouze ukazují pokračující agregaci v průběhu času. můžete porovnejte tyto snímky, abyste porozuměli výkonu mezi snímky, ale mohu vám říci, že když budete muset psát tento kód proti velkému souboru dat, je to utrpení (ale nejsem vývojář, takže to možná bude pro vás snadné ).
Moje tradiční metoda zachycování statistik čekání byla jednoduše každých pár hodin pořídit snímek sys.dm_os_wait_stats pomocí Paulova původního skriptu:
USE [BaselineData];
GO
IF NOT EXISTS (SELECT * FROM [sys].[tables] WHERE [name] = N'SQLskills_WaitStats_OldMethod')
BEGIN
CREATE TABLE [dbo].[SQLskills_WaitStats_OldMethod]
(
[RowNum] [bigint] IDENTITY(1,1) NOT NULL,
[CaptureDate] [datetime] NULL,
[WaitType] [nvarchar](120) NULL,
[Wait_S] [decimal](14, 2) NULL,
[Resource_S] [decimal](14, 2) NULL,
[Signal_S] [decimal](14, 2) NULL,
[WaitCount] [bigint] NULL,
[Percentage] [decimal](4, 2) NULL,
[AvgWait_S] [decimal](14, 4) NULL,
[AvgRes_S] [decimal](14, 4) NULL,
[AvgSig_S] [decimal](14, 4) NULL
);
CREATE CLUSTERED INDEX [CI_SQLskills_WaitStats_OldMethod]
ON [dbo].[SQLskills_WaitStats_OldMethod] ([CaptureDate],[RowNum]);
END
GO
/* Query to use in scheduled job */
USE [BaselineData];
GO
INSERT INTO [dbo].[SQLskills_WaitStats_OldMethod]
(
[CaptureDate] ,
[WaitType] ,
[Wait_S] ,
[Resource_S] ,
[Signal_S] ,
[WaitCount] ,
[Percentage] ,
[AvgWait_S] ,
[AvgRes_S] ,
[AvgSig_S]
)
EXEC ('WITH [Waits] AS (SELECT
[wait_type],
[wait_time_ms] / 1000.0 AS [WaitS],
([wait_time_ms] - [signal_wait_time_ms]) / 1000.0 AS [ResourceS],
[signal_wait_time_ms] / 1000.0 AS [SignalS],
[waiting_tasks_count] AS [WaitCount],
100.0 * [wait_time_ms] / SUM ([wait_time_ms]) OVER() AS [Percentage],
ROW_NUMBER() OVER(ORDER BY [wait_time_ms] DESC) AS [RowNum]
FROM sys.dm_os_wait_stats
WHERE [wait_type] NOT IN (SELECT WaitType FROM SQLskills_WaitStats.dbo.WaitsToIgnore)
)
SELECT
GETDATE(),
[W1].[wait_type] AS [WaitType],
CAST ([W1].[WaitS] AS DECIMAL(14, 2)) AS [Wait_S],
CAST ([W1].[ResourceS] AS DECIMAL(14, 2)) AS [Resource_S],
CAST ([W1].[SignalS] AS DECIMAL(14, 2)) AS [Signal_S],
[W1].[WaitCount] AS [WaitCount],
CAST ([W1].[Percentage] AS DECIMAL(4, 2)) AS [Percentage],
CAST (([W1].[WaitS] / [W1].[WaitCount]) AS DECIMAL (14, 4)) AS [AvgWait_S],
CAST (([W1].[ResourceS] / [W1].[WaitCount]) AS DECIMAL (14, 4)) AS [AvgRes_S],
CAST (([W1].[SignalS] / [W1].[WaitCount]) AS DECIMAL (14, 4)) AS [AvgSig_S]
FROM [Waits] AS [W1]
INNER JOIN [Waits] AS [W2]
ON [W2].[RowNum] <= [W1].[RowNum]
GROUP BY [W1].[RowNum], [W1].[wait_type], [W1].[WaitS], [W1].[ResourceS],
[W1].[SignalS], [W1].[WaitCount], [W1].[Percentage]
HAVING SUM ([W2].[Percentage]) - [W1].[Percentage] < 95;'
); Pak bych prošel a podíval se na horní část čekání na každý snímek, například:
SELECT [w].[CaptureDate] , [w].[WaitType] , [w].[Percentage] , [w].[Wait_S] , [w].[WaitCount] , [w].[AvgWait_S] FROM [dbo].[SQLskills_WaitStats_OldMethod] w JOIN ( SELECT MIN([RowNum]) AS [RowNumber] , [CaptureDate] FROM [dbo].[SQLskills_WaitStats_OldMethod] WHERE [CaptureDate] IS NOT NULL AND [CaptureDate] > GETDATE() - 60 GROUP BY [CaptureDate] ) m ON [w].[RowNum] = [m].[RowNumber] ORDER BY [w].[CaptureDate];
Moje nová, alternativní metoda je porovnat několik snímků statistiky čekání (se dvěma až třemi minutami mezi snímky) každou hodinu nebo tak. Tato informace mi pak přesně říká, na co systém v tu chvíli čekal:
USE [BaselineData];
GO
IF NOT EXISTS ( SELECT * FROM [sys].[tables] WHERE [name] = N'SQLskills_WaitStats')
BEGIN
CREATE TABLE [dbo].[SQLskills_WaitStats]
(
[RowNum] [bigint] IDENTITY(1,1) NOT NULL,
[CaptureDate] [datetime] NOT NULL DEFAULT (sysdatetime()),
[WaitType] [nvarchar](60) NOT NULL,
[Wait_S] [decimal](16, 2) NULL,
[Resource_S] [decimal](16, 2) NULL,
[Signal_S] [decimal](16, 2) NULL,
[WaitCount] [bigint] NULL,
[Percentage] [decimal](5, 2) NULL,
[AvgWait_S] [decimal](16, 4) NULL,
[AvgRes_S] [decimal](16, 4) NULL,
[AvgSig_S] [decimal](16, 4) NULL
) ON [PRIMARY];
CREATE CLUSTERED INDEX [CI_SQLskills_WaitStats]
ON [dbo].[SQLskills_WaitStats] ([CaptureDate],[RowNum]);
END
/* Query to use in scheduled job */
USE [BaselineData];
GO
IF EXISTS (SELECT * FROM [tempdb].[sys].[objects] WHERE [name] = N'##SQLskillsStats1')
DROP TABLE [##SQLskillsStats1];
IF EXISTS (SELECT * FROM [tempdb].[sys].[objects] WHERE [name] = N'##SQLskillsStats2')
DROP TABLE [##SQLskillsStats2];
GO
/* Capture wait stats */
SELECT [wait_type], [waiting_tasks_count], [wait_time_ms],
[max_wait_time_ms], [signal_wait_time_ms]
INTO ##SQLskillsStats1
FROM sys.dm_os_wait_stats;
GO
/* Wait some amount of time */
WAITFOR DELAY '00:02:00';
GO
/* Capture wait stats again */
SELECT [wait_type], [waiting_tasks_count], [wait_time_ms],
[max_wait_time_ms], [signal_wait_time_ms]
INTO ##SQLskillsStats2
FROM sys.dm_os_wait_stats;
GO
/* Diff the waits */
WITH [DiffWaits] AS
(
SELECT -- Waits that weren't in the first snapshot
[ts2].[wait_type],
[ts2].[wait_time_ms],
[ts2].[signal_wait_time_ms],
[ts2].[waiting_tasks_count]
FROM [##SQLskillsStats2] AS [ts2]
LEFT OUTER JOIN [##SQLskillsStats1] AS [ts1]
ON [ts2].[wait_type] = [ts1].[wait_type]
WHERE [ts1].[wait_type] IS NULL
AND [ts2].[wait_time_ms] > 0
UNION
SELECT -- Diff of waits in both snapshots
[ts2].[wait_type],
[ts2].[wait_time_ms] - [ts1].[wait_time_ms] AS [wait_time_ms],
[ts2].[signal_wait_time_ms] - [ts1].[signal_wait_time_ms] AS [signal_wait_time_ms],
[ts2].[waiting_tasks_count] - [ts1].[waiting_tasks_count] AS [waiting_tasks_count]
FROM [##SQLskillsStats2] AS [ts2]
LEFT OUTER JOIN [##SQLskillsStats1] AS [ts1]
ON [ts2].[wait_type] = [ts1].[wait_type]
WHERE [ts1].[wait_type] IS NOT NULL
AND [ts2].[waiting_tasks_count] - [ts1].[waiting_tasks_count] > 0
AND [ts2].[wait_time_ms] - [ts1].[wait_time_ms] > 0
),
[Waits] AS
(
SELECT
[wait_type],
[wait_time_ms] / 1000.0 AS [WaitS],
([wait_time_ms] - [signal_wait_time_ms]) / 1000.0 AS [ResourceS],
[signal_wait_time_ms] / 1000.0 AS [SignalS],
[waiting_tasks_count] AS [WaitCount],
100.0 * [wait_time_ms] / SUM ([wait_time_ms]) OVER() AS [Percentage],
ROW_NUMBER() OVER(ORDER BY [wait_time_ms] DESC) AS [RowNum]
FROM [DiffWaits]
WHERE [wait_type] NOT IN (SELECT WaitType FROM SQLskills_WaitStats.dbo.WaitsToIgnore)
)
INSERT INTO [BaselineData].[dbo].[SQLskills_WaitStats]
(
[WaitType] ,
[Wait_S] ,
[Resource_S] ,
[Signal_S] ,
[WaitCount] ,
[Percentage] ,
[AvgWait_S] ,
[AvgRes_S] ,
[AvgSig_S]
)
SELECT
[W1].[wait_type],
CAST ([W1].[WaitS] AS DECIMAL (16, 2)) ,
CAST ([W1].[ResourceS] AS DECIMAL (16, 2)) ,
CAST ([W1].[SignalS] AS DECIMAL (16, 2)) ,
[W1].[WaitCount] ,
CAST ([W1].[Percentage] AS DECIMAL (5, 2)) ,
CAST (([W1].[WaitS] / [W1].[WaitCount]) AS DECIMAL (16, 4)) ,
CAST (([W1].[ResourceS] / [W1].[WaitCount]) AS DECIMAL (16, 4)) ,
CAST (([W1].[SignalS] / [W1].[WaitCount]) AS DECIMAL (16, 4))
FROM [Waits] AS [W1]
INNER JOIN [Waits] AS [W2]
ON [W2].[RowNum] <= [W1].[RowNum]
GROUP BY [W1].[RowNum], [W1].[wait_type], [W1].[WaitS], [W1].[ResourceS],
[W1].[SignalS], [W1].[WaitCount], [W1].[Percentage]
HAVING SUM ([W2].[Percentage]) - [W1].[Percentage] < 95; -- percentage threshold
GO
/* Clean up the temp tables */
IF EXISTS (SELECT * FROM [tempdb].[sys].[objects] WHERE [name] = N'##SQLskillsStats1')
DROP TABLE [##SQLskillsStats1];
IF EXISTS (SELECT * FROM [tempdb].[sys].[objects] WHERE [name] = N'##SQLskillsStats2')
DROP TABLE [##SQLskillsStats2]; Je moje nová metoda lepší? Myslím, že ano, protože je to lepší znázornění toho, jak čekání vypadá přímo v okamžiku zachycení, a stále se vzorkuje v pravidelných intervalech. U obou metod se obvykle dívám, jaká byla nejvyšší čekací doba v době zachycení:
SELECT [w].[CaptureDate] , [w].[WaitType] , [w].[Percentage] , [w].[Wait_S] , [w].[WaitCount] , [w].[AvgWait_S] FROM [dbo].[SQLskills_WaitStats] w JOIN ( SELECT MIN([RowNum]) AS [RowNumber], [CaptureDate] FROM [dbo].[SQLskills_WaitStats] WHERE [CaptureDate] > GETDATE() - 30 GROUP BY [CaptureDate] ) m ON [w].[RowNum] = [m].[RowNumber] ORDER BY [w].[CaptureDate];
Výsledky:
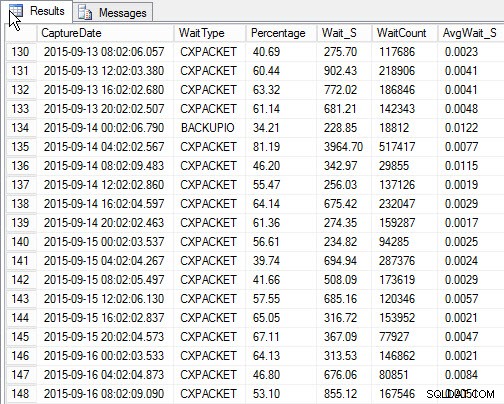 Nejvyšší čekání na každý snímek (ukázkový výstup)
Nejvyšší čekání na každý snímek (ukázkový výstup)
Nevýhodou, která existovala u mého původního skriptu, je, že je to stále jen snímek . Mohu trendovat nejvyšší čekání v průběhu času, ale pokud se vyskytne problém mezi snímky, nezobrazí se. Co tedy můžete dělat?
Mohli byste zvýšit frekvenci svých zajetí. Možná namísto zachycování statistik čekání každou hodinu je zaznamenáváte každých 15 minut. Nebo možná každých 10. Čím častěji zaznamenáváte data, tím větší je šance, že budete mít problém s výkonem.
Další možností by bylo použití aplikace třetí strany, jako je SQL Sentry Performance Advisor, ke sledování čekání. Performance Advisor získává úplně stejné informace z DMV sys.dm_os_wait_stats. Každých 10 sekund se dotazuje sys.dm_os_wait_stats pomocí velmi jednoduchého dotazu:
SELECT * FROM sys.dm_os_wait_stats WHERE wait_time_ms > 0;
V zákulisí pak Performance Advisor vezme tato data a přidá je do své monitorovací databáze. Když vidíte data, benigní čekání se odstraní a delty se vypočítají za vás. Kromě toho má Performance Advisor fantastický displej (pohled na palubní desku je mnohem hezčí než textový výstup výše) a můžete si kolekci upravit, pokud chcete. Pokud se podíváme na Performance Advisor a podíváme se na data z celého dne, snadno zjistím, kde jsem měl problém v podokně Čekání serveru SQL:
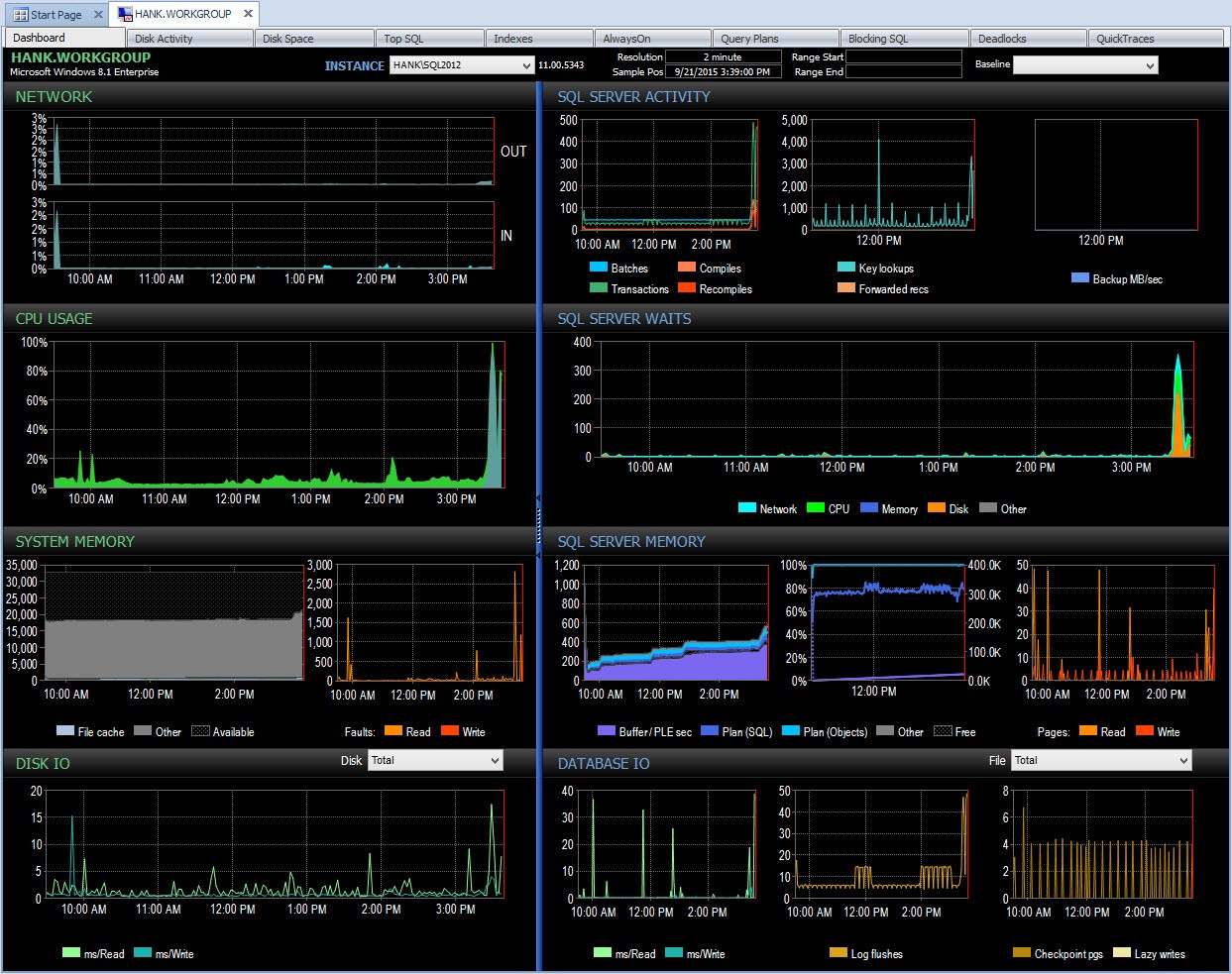 Panel poradce pro výkon pro daný den
Panel poradce pro výkon pro daný den
A pak mohu prozkoumat toto časové období po 15:00, abych dále prozkoumal, co se stalo:
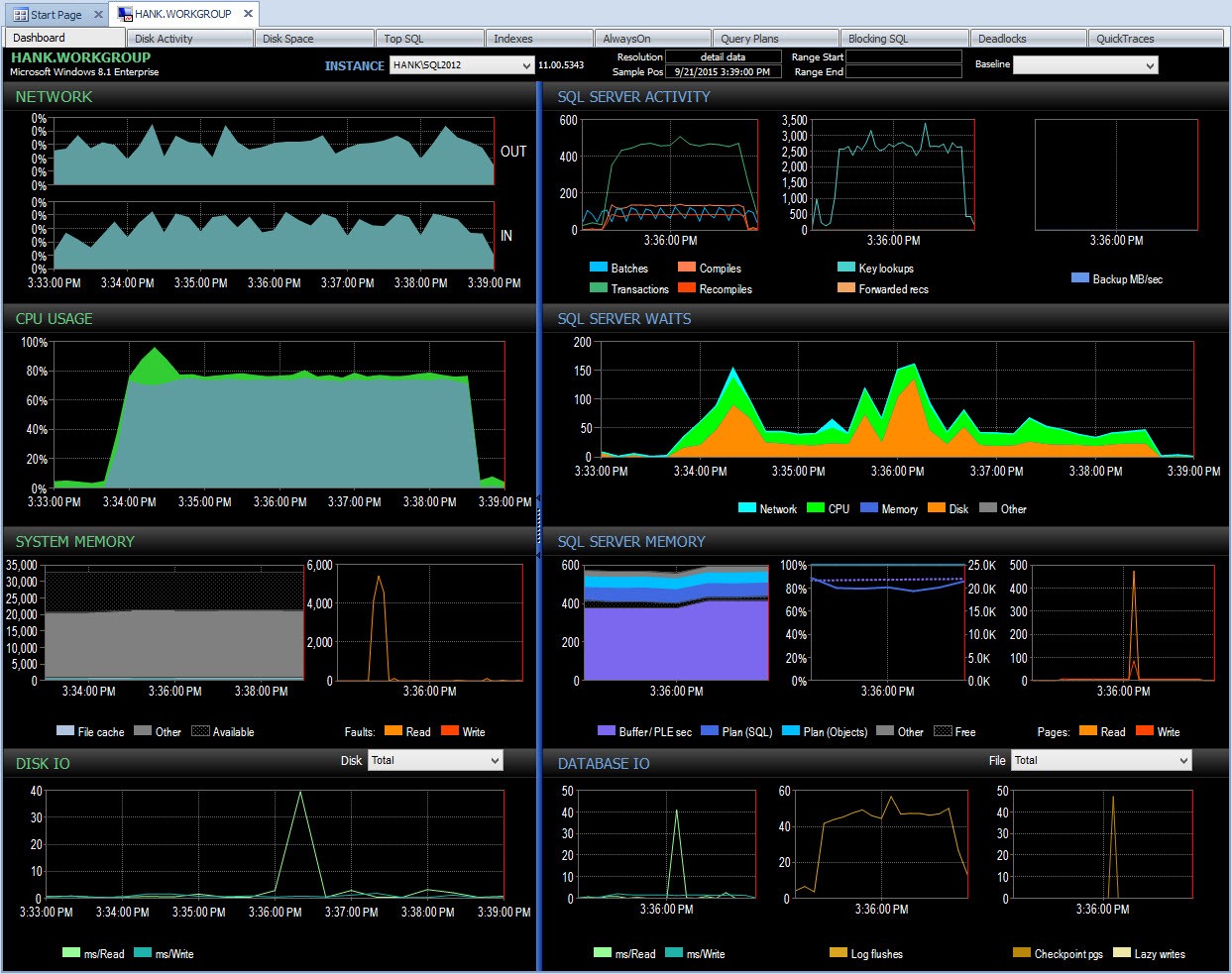 Projděte si PA během problému s výkonem
Projděte si PA během problému s výkonem
Sledování na vlastní pěst, pokud jsem náhodou nevyfotografoval statistiku čekání ve stejnou dobu pomocí skriptu, zmeškal jsem zachycení jakýchkoli dat o tomto problému s výkonem. Protože Performance Advisor uchovává informace po delší dobu, pokud máte výkyv ve výkonu, uděláte mějte k dispozici údaje o čekacích statistikách (spolu se spoustou dalších informací), které vám pomohou problém prozkoumat, a také historická data, abyste pochopili, jaká normální čekací doba ve vašem prostředí existuje.
Shrnutí
Ať už zvolíte jakoukoli metodu sledování čekání, je nejprve důležité pochopit jak SQL Server ukládá informace o čekání, abyste rozuměli datům, která vidíte, pokud je pravidelně zachycujete. Pokud k zachycení čekání musíte spouštět své vlastní skripty, jste omezeni tím, že možná nezachytíte odchylky tak snadno, jako byste mohli se softwarem třetích stran. Ale to je v pořádku – mít nějaké množství výchozích dat, abyste mohli začít chápat, co je „normální“, je lepší než nemít vůbec nic . Když si vytváříte úložiště a začínáte se seznamovat s prostředím, můžete si přizpůsobit své zachytávací skripty podle potřeby, abyste vyřešili případné problémy. Pokud máte výhodu softwaru třetí strany, využijte tyto informace co nejlépe a ujistěte se, že rozumíte tomu, jak se shromažďují a ukládají čekací doby.