Není skvělé mít k dispozici novou verzi SQL Server? K tomu dochází pouze jednou za pár let a tento měsíc jsme byli svědky toho, že jeden dosáhl všeobecné dostupnosti. (Dobře, vím, že v Azure dostáváme novou verzi SQL Database téměř nepřetržitě, ale počítám to jako jiné.) S vědomím této nové verze je měsíční T-SQL úterý (hostuje Michael Swart – @mjswart) na téma všech věcí SQL Server 2016!
Není skvělé mít k dispozici novou verzi SQL Server? K tomu dochází pouze jednou za pár let a tento měsíc jsme byli svědky toho, že jeden dosáhl všeobecné dostupnosti. (Dobře, vím, že v Azure dostáváme novou verzi SQL Database téměř nepřetržitě, ale počítám to jako jiné.) S vědomím této nové verze je měsíční T-SQL úterý (hostuje Michael Swart – @mjswart) na téma všech věcí SQL Server 2016!
Dnes se tedy chci podívat na funkci Temporal Tables SQL 2016 a podívat se na některé situace plánu dotazů, které byste mohli nakonec vidět. Miluji Temporal Tables, ale narazil jsem na drobný problém, kterého byste si možná chtěli být vědomi.
Nyní, navzdory skutečnosti, že SQL Server 2016 je nyní v RTM, používám AdventureWorks2016CTP3, který si můžete stáhnout zde – ale nestahujte pouze AdventureWorks2016CTP3.bak , také uchopte SQLServer2016CTP3Samples.zip ze stejného webu.
Vidíte, v archivu vzorků je několik užitečných skriptů pro vyzkoušení nových funkcí, včetně některých skriptů pro dočasné tabulky. Je to oboustranně výhodné – můžete vyzkoušet spoustu nových funkcí a v tomto příspěvku nemusím tolik opakovat skript. Každopádně jděte a vezměte si dva skripty o Temporal Tables, spusťte AW 2016 CTP3 Temporal Setup.sql , následovaný Temporal System-Versioning Sample.sql .
Tyto skripty nastavují dočasné verze několika tabulek, včetně HumanResources.Employee . Vytváří HumanResources.Employee_Temporal (ačkoli technicky by se to dalo nazvat jakkoli). Na konci CREATE TABLE Tento bit se objeví a přidá dva skryté sloupce, které se použijí k označení, kdy je řádek platný, a indikují, že by měla být vytvořena tabulka s názvem HumanResources.Employee_Temporal_History pro uložení starých verzí.
... ValidFrom datetime2(7) VYGENEROVÁNO VŽDY JAKO ŘÁDEK START HIDDEN NOT NULL, ValidTo datetime2(7) VYGENEROVÁNO VŽDY JAKO KONEC ŘÁDKU HIDDEN NOT NULL, OBDOBÍ PRO SYSTEM_TIME (ValidFrom, ValidTo)) WITH (SYSTEM_VERSIONING =ON =[HumanResources].[Employee_Temporal_History]));
V tomto příspěvku chci prozkoumat, co se stane s plány dotazů při použití historie.
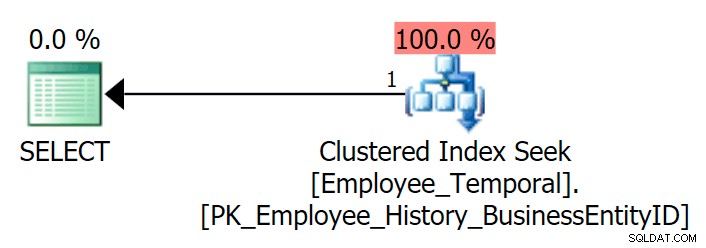
Pokud se dotazuji na tabulku, abych viděl poslední řádek pro konkrétní BusinessEntityID , dostávám Clustered Index Seek, jak bylo očekáváno.
SELECT e.BusinessEntityID, e.ValidFrom, e.ValidToFROM HumanResources.Employee_Temporal AS eWHERE e.BusinessEntityID =4;
Jsem si jistý, že bych mohl dotazovat tuto tabulku pomocí jiných indexů, pokud nějaké měla. Ale v tomto případě tomu tak není. Pojďme si jeden vytvořit.
VYTVOŘTE UNIKÁTNÍ INDEX rf_ix_Login on HumanResources.Employee_Temporal(LoginID);
Nyní mohu dotazovat tabulku pomocí LoginID a zobrazí se vyhledávání klíčů, pokud požádám o jiné sloupce než Loginid nebo BusinessEntityID . Nic z toho není překvapivé.
SELECT * FROM HumanResources.Employee_Temporal eWHERE e.LoginID =N'adventure-works\rob0';
Pojďme na chvíli použít SQL Server Management Studio a podívejme se, jak tato tabulka vypadá v Object Exploreru.

Můžeme vidět tabulku Historie zmíněnou pod HumanResources.Employee_Temporal a sloupce a indexy ze samotné tabulky i tabulky historie. Ale zatímco indexy ve správné tabulce jsou primární klíč (na BusinessEntityID ) a index, který jsem právě vytvořil, tabulka Historie nemá odpovídající indexy.
Index v tabulce historie je na ValidTo a ValidFrom . Můžeme kliknout pravým tlačítkem na index a vybrat Vlastnosti a uvidíme tento dialog:
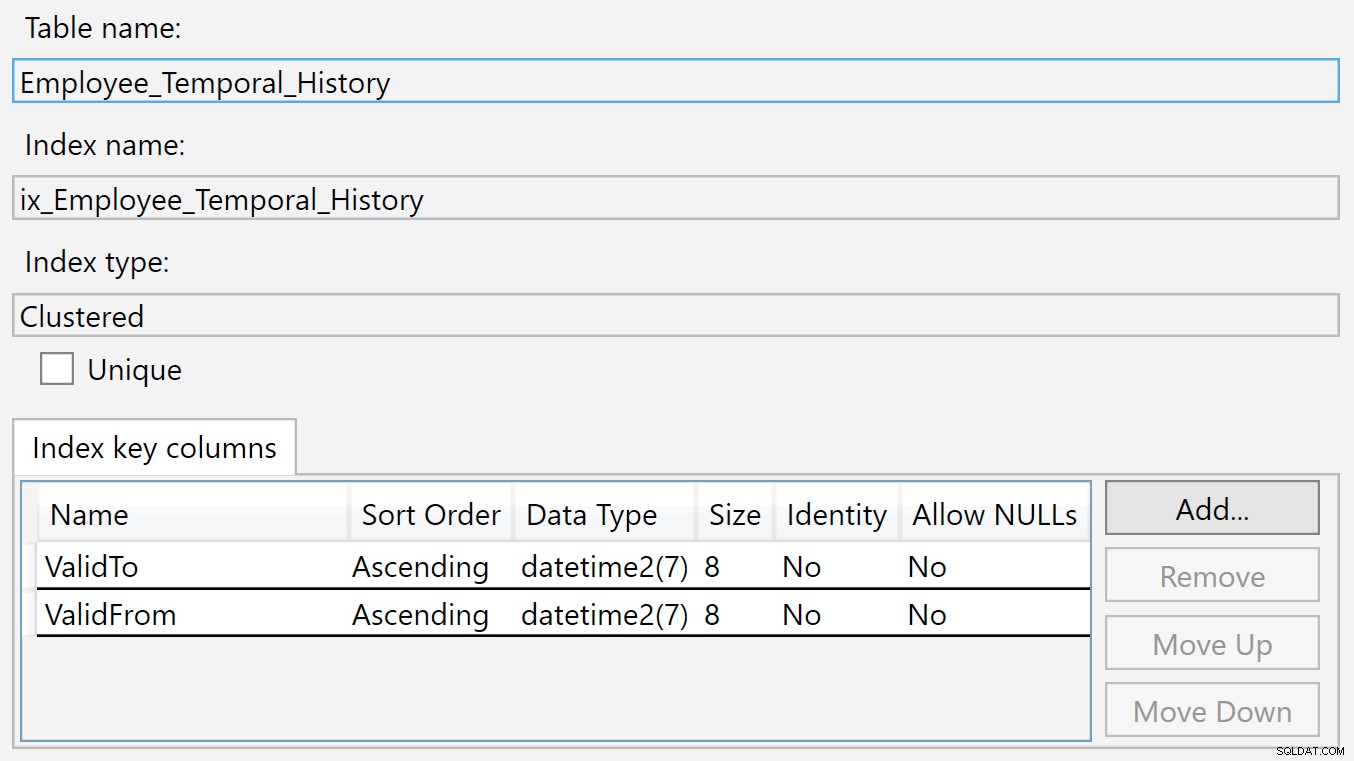
Do této tabulky Historie se vloží nový řádek, když již není platný v hlavní tabulce, protože byl právě odstraněn nebo změněn. Hodnoty v ValidTo sloupec jsou přirozeně vyplněny aktuálním časem, takže ValidTo funguje jako vzestupný klíč, jako sloupec identity, takže na konci struktury b-stromu se objeví nové vložky.
Ale jak to funguje, když chcete dotazovat tabulku?
Pokud se chceme v naší tabulce dotazovat na to, co bylo aktuální v určitém časovém okamžiku, měli bychom použít strukturu dotazu jako:
SELECT * FROM HumanResources.Employee_TemporalFOR SYSTEM_TIME K 20160612 11:22';
Tento dotaz potřebuje zřetězit příslušné řádky z hlavní tabulky s příslušnými řádky z tabulky historie.
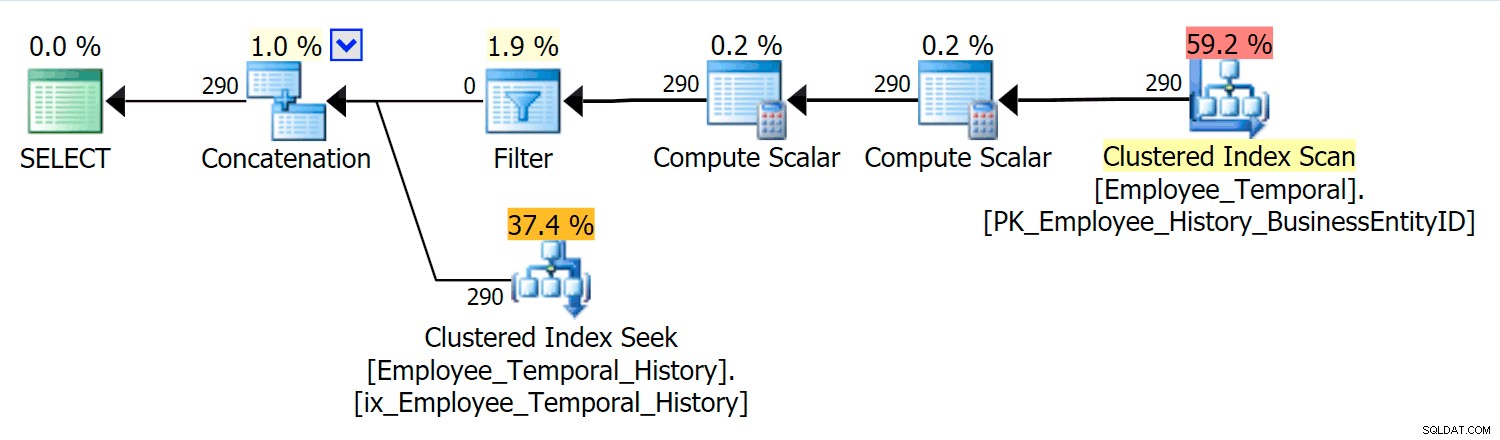
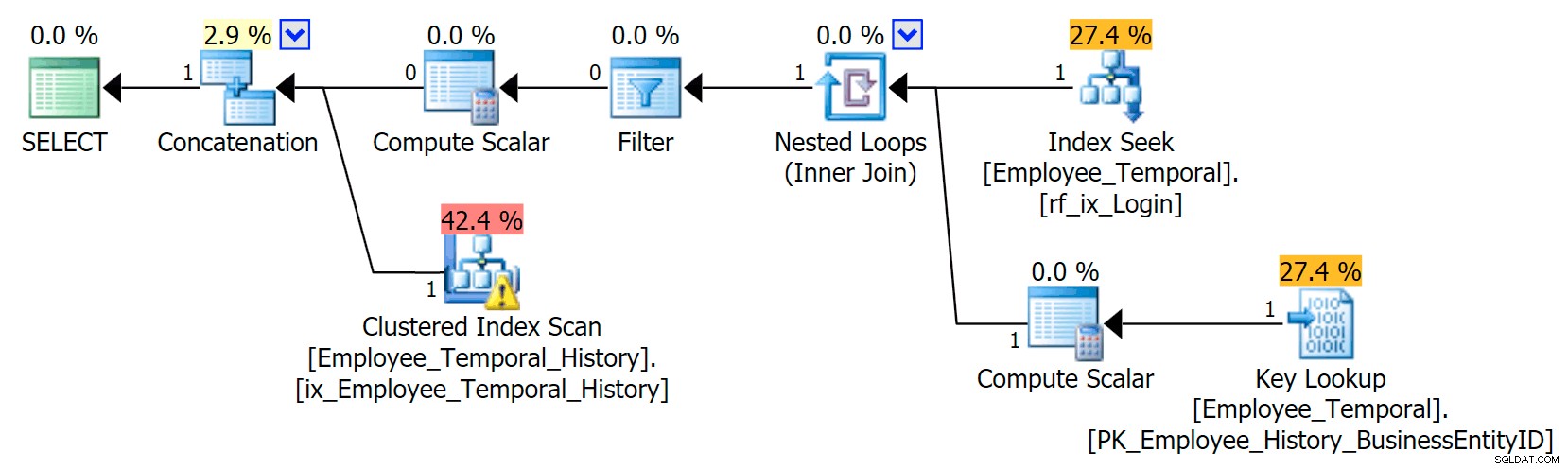
V tomto scénáři byly řádky, které byly platné v okamžiku, který jsem vybral, všechny z tabulky historie, ale přesto vidíme Clustered Index Scan proti hlavní tabulce, která byla filtrována operátorem Filtr. Predikát tohoto filtru je:
[HumanResources].[Employee_Temporal].[ValidFrom] <='2016-06-12 11:22:00.0000000' AND [HumanResources].[Employee_Temporal].[ValidTo]-> 06-2016 :00.0000000'
Vraťme se k tomu za chvíli.
Clustered Index Seek v tabulce Historie musí jednoznačně využívat predikát hledání na ValidTo. Start of the Seek’s Range Scan je HumanResources.Employee_Temporal_History.ValidTo > Skalární operátor('2016-06-12 11:22:00') , ale není tam žádný konec, protože každý řádek má ValidTo po čase, na kterém nám záleží, je kandidátský řádek a musí být otestován na odpovídající ValidFrom hodnotu pomocí reziduálního predikátu, což je HumanResources.Employee_Temporal_History.ValidFrom <= '2016-06-12 11:22:00' .
Nyní je obtížné indexovat intervaly; to je známá věc, o které se mluvilo na mnoha blozích. Nejúčinnější řešení zvažují kreativní způsoby psaní dotazů, ale žádná taková chytrá řešení nebyla zabudována do Temporal Tables. Můžete však umístit indexy i do jiných sloupců, například do ValidFrom, nebo dokonce mít indexy, které odpovídají typům dotazů, které můžete mít v hlavní tabulce. Se seskupeným indexem, který je složeným klíčem na obou ValidTo a ValidFrom , tyto dva sloupce jsou zahrnuty do každého druhého sloupce, což poskytuje dobrou příležitost pro testování zbytkových predikátů.
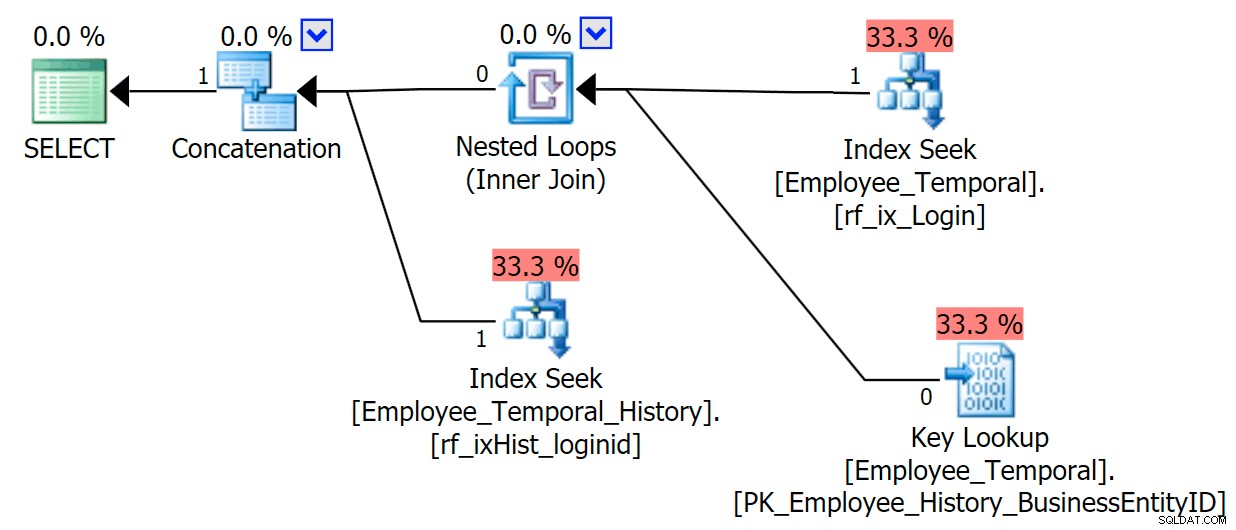
Pokud vím, které přihlašovací jméno mě zajímá, můj plán bude mít jiný tvar.
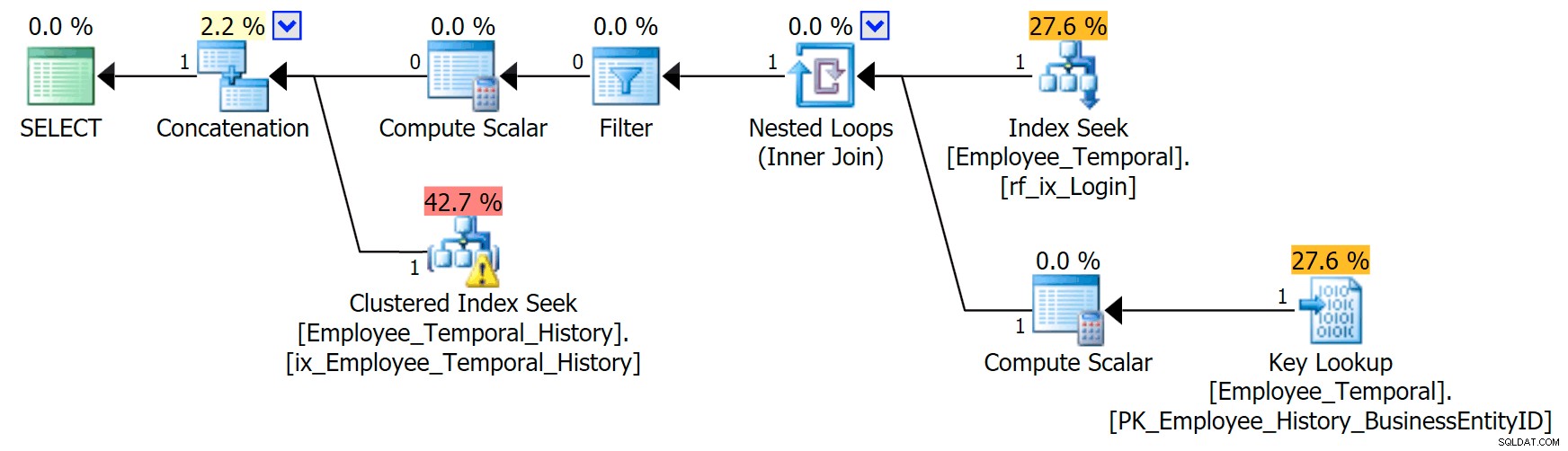
Horní větev operátoru Concatenation vypadá podobně jako předtím, ačkoli tento operátor Filter vstoupil do bitvy, aby odstranil všechny řádky, které nejsou platné, ale Clustered Index Seek na spodní větvi má varování. Toto je varování před zbytkovým predikátem, jako příklady v mém dřívějším příspěvku. Je schopen filtrovat záznamy, které jsou platné do určitého okamžiku po uplynutí doby, na které nám záleží, ale zbytkový predikát nyní filtruje podle LoginID stejně jako ValidFrom .
[HumanResources].[Employee_Temporal_History].[ValidFrom] <='2016-06-12 11:22:00.0000000' AND [HumanResources].[Employee_Temporal_History]<-robal_History][AdvenIDID=" /před>Změny v řádcích rob0 budou představovat malou část řádků v historii. Tento sloupec nebude jedinečný jako v hlavní tabulce, protože řádek mohl být změněn několikrát, ale stále existuje dobrý kandidát na indexování.
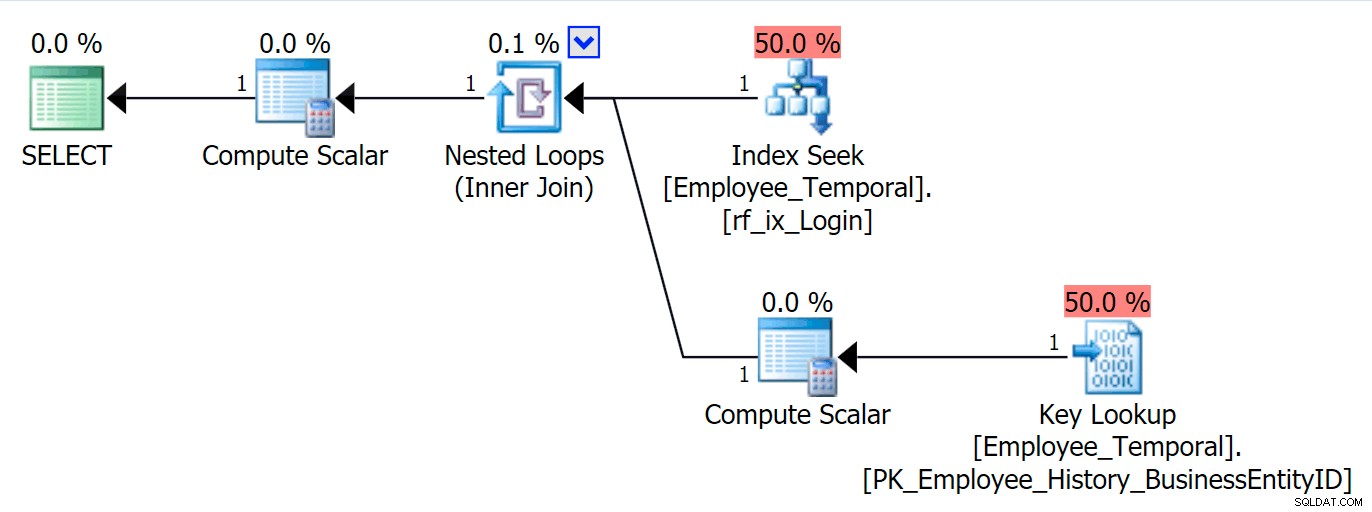
CREATE INDEX rf_ixHist_loginidON HumanResources.Employee_Temporal_History(LoginID);Tento nový index má významný vliv na náš plán.
Nyní se naše hledání seskupeného indexu změnilo na hledání seskupeného indexu!!
Vidíte, nástroj pro optimalizaci dotazů nyní zjistil, že nejlepší by bylo použít nový index. Ale také rozhodne, že snaha s hledáním všech ostatních sloupců (protože jsem se ptal na všechny sloupce) by byla prostě příliš mnoho práce. Bylo dosaženo bodu zvratu (v tomto případě bohužel nesprávný předpoklad) a místo něj byl zvolen Clustered Index SCAN. I když bez indexu bez klastrů by nejlepší možností bylo použít hledání klastrového indexu, když byl neclusterový index zvažován a zamítnut z důvodů bodu zvratu, rozhodne se skenovat.
Je frustrující, že jsem tento index právě vytvořil a jeho statistiky by měly být dobré. Měl by vědět, že hledání, které vyžaduje přesně jedno vyhledávání, by mělo být lepší než skenování klastrovaného indexu (pouze podle statistik – pokud jste si mysleli, že by to mělo vědět, protože
LoginIDje v hlavní tabulce jedinečný, pamatujte, že tomu tak nemuselo být vždy). Domnívám se tedy, že vyhledávání v tabulkách historie by se mělo vyhnout, i když jsem o tom ještě neudělal dost průzkumu.Kdybychom nyní dotazovali pouze sloupce, které se objevují v našem neseskupeném indexu, dosáhli bychom mnohem lepšího chování. Nyní, když není vyžadováno žádné vyhledávání, je náš nový index v tabulce historie šťastně používán. Stále potřebuje použít zbytkový predikát na základě možnosti filtrovat pouze na
LoginIDaValidTo, ale chová se to mnohem lépe než přechod do Clustered Index Scan.SELECT LoginID, ValidFrom, ValidToFROM HumanResources.Employee_TemporalFOR SYSTEM_TIME K '20160612 11:22'WHERE LoginID =N'adventure-works\rob0'
Indexujte tedy tabulky historie zvláštními způsoby, s ohledem na to, jak je budete dotazovat. Zahrňte potřebné sloupce, abyste se vyhnuli vyhledávání, protože se skutečně vyhýbáte skenování.
Tyto tabulky historie se mohou zvětšit, pokud se data často mění. Dávejte tedy pozor na to, jak se s nimi zachází. Ke stejné situaci dochází při použití druhého
FOR SYSTEM_TIMEkonstrukty, takže byste měli (jako vždy) zkontrolovat plány, které vaše dotazy produkují, a indexovat, abyste se ujistili, že máte dobrou pozici pro využití velmi výkonné funkce SQL Server 2016.