Jedním z více matoucích problémů k odstraňování problémů na serveru SQL Server mohou být problémy související s přidělením paměti. Některé dotazy potřebují ke spuštění více paměti než jiné, podle toho, jaké operace je třeba provést (např. řazení, hash). Optimalizátor SQL Serveru odhadne, kolik paměti je potřeba, a dotaz musí získat přidělení paměti, aby se mohl spustit. Drží toto povolení po dobu provádění dotazu – což znamená, že pokud optimalizátor nadhodnocuje paměť, můžete narazit na problémy se souběžností. Pokud podceňuje paměť, můžete v tempdb vidět úniky. Ani jedno není ideální, a když máte jednoduše příliš mnoho dotazů požadujících více paměti, než je k dispozici pro udělení, uvidíte, že RESOURCE_SEMAPHORE čeká. Existuje několik způsobů, jak na tento problém zaútočit, a jednou z mých nových oblíbených metod je použití Query Store.
Nastavení
Použijeme kopii WideWorldImporters, kterou jsem nafoukl pomocí uložené procedury DataLoadSimulation.DailyProcessToCreateHistory. Tabulka Sales.Orders má přibližně 4,6 milionu řádků a tabulka Sales.OrderLines má přibližně 9,2 milionu řádků. Obnovíme zálohu a povolíme Query Store a vymažeme všechna stará data Query Store, abychom pro tuto ukázku neměnili žádné metriky.
Připomenutí:Nespouštějte ALTER DATABASE
USE [master]; GO RESTORE DATABASE [WideWorldImporters] FROM DISK = N'C:\Backups\WideWorldImporters.bak' WITH FILE = 1, MOVE N'WWI_Primary' TO N'C:\Databases\WideWorldImporters\WideWorldImporters.mdf', MOVE N'WWI_UserData' TO N'C:\Databases\WideWorldImporters\WideWorldImporters_UserData.ndf', MOVE N'WWI_Log' TO N'C:\Databases\WideWorldImporters\WideWorldImporters.ldf', NOUNLOAD, REPLACE, STATS = 5 GO ALTER DATABASE [WideWorldImporters] SET QUERY_STORE = ON; GO ALTER DATABASE [WideWorldImporters] SET QUERY_STORE ( OPERATION_MODE = READ_WRITE, INTERVAL_LENGTH_MINUTES = 10 ); GO ALTER DATABASE [WideWorldImporters] SET QUERY_STORE CLEAR; GO
Uložená procedura, kterou použijeme k testování, se dotazuje na výše uvedené tabulky Orders a OrderLines na základě časového rozsahu:
USE [WideWorldImporters]; GO DROP PROCEDURE IF EXISTS [Sales].[usp_OrderInfo_OrderDate]; GO CREATE PROCEDURE [Sales].[usp_OrderInfo_OrderDate] @StartDate DATETIME, @EndDate DATETIME AS SELECT [o].[CustomerID], [o].[OrderDate], [o].[ContactPersonID], [ol].[Quantity] FROM [Sales].[Orders] [o] JOIN [Sales].[OrderLines] [ol] ON [o].[OrderID] = [ol].[OrderID] WHERE [OrderDate] BETWEEN @StartDate AND @EndDate ORDER BY [OrderDate]; GO
Testování
Provedeme uloženou proceduru se třemi různými sadami vstupních parametrů:
EXEC [Sales].[usp_OrderInfo_OrderDate] '2016-01-01', '2016-01-08'; GO EXEC [Sales].[usp_OrderInfo_OrderDate] '2016-01-01', '2016-06-30'; GO EXEC [Sales].[usp_OrderInfo_OrderDate] '2016-01-01', '2016-12-31'; GO
První provedení vrátí 1958 řádků, druhé vrátí 267 268 řádků a poslední vrátí více než 2,2 milionu řádků. Pokud se podíváte na časová období, není to překvapivé – čím větší je časové období, tím více dat se vrací.
Protože se jedná o uloženou proceduru, použité vstupní parametry zpočátku určují plán a také přidělenou paměť. Pokud se podíváme na skutečný plán provádění pro první spuštění, vidíme vnořené smyčky a přidělení paměti 2656 KB.
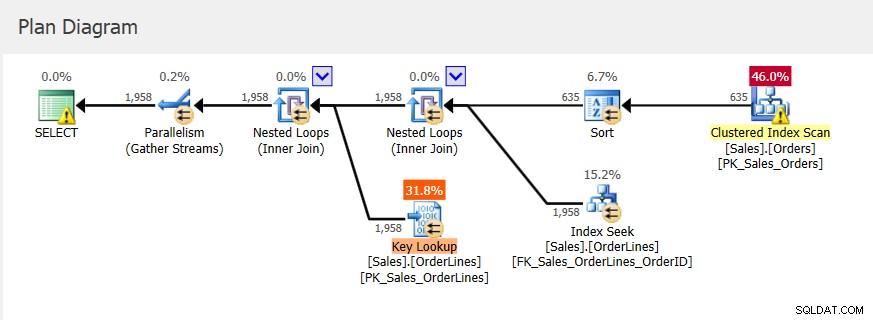
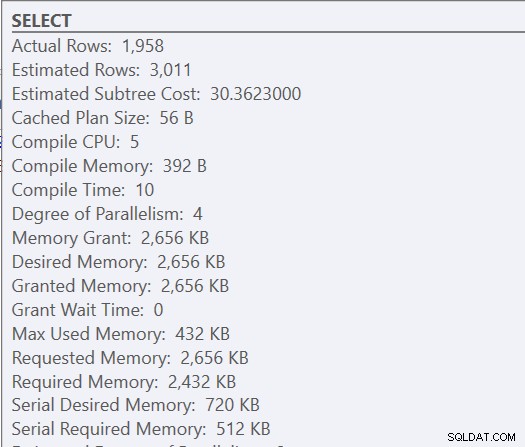
Následná spuštění mají stejný plán (jako to, co bylo uloženo do mezipaměti) a stejné přidělení paměti, ale získáme vodítko, že to nestačí, protože existuje varování o řazení.
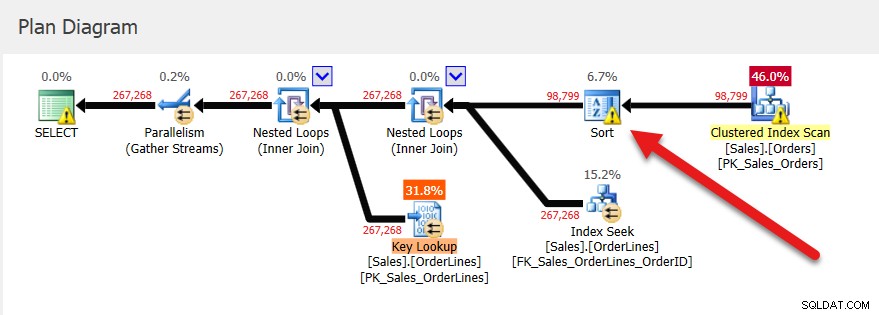
Pokud se podíváme do Query Store na tuto uloženou proceduru, vidíme tři spuštění a stejné hodnoty pro UsedKB memory, ať už se podíváme na Průměr, Minimum, Maximum, Poslední nebo Standardní odchylka. Poznámka:Informace o přidělení paměti v úložišti dotazů jsou hlášeny jako počet stránek o velikosti 8 kB.
SELECT [qst].[query_sql_text], [qsq].[query_id], [qsp].[plan_id], [qsq].[object_id], [rs].[count_executions], [rs].[last_execution_time], [rs].[avg_duration], [rs].[avg_logical_io_reads], [rs].[avg_query_max_used_memory] * 8 AS [AvgUsedKB], [rs].[min_query_max_used_memory] * 8 AS [MinUsedKB], --memory grant (reported as the number of 8 KB pages) for the query plan within the aggregation interval [rs].[max_query_max_used_memory] * 8 AS [MaxUsedKB], [rs].[last_query_max_used_memory] * 8 AS [LastUsedKB], [rs].[stdev_query_max_used_memory] * 8 AS [StDevUsedKB], TRY_CONVERT(XML, [qsp].[query_plan]) AS [QueryPlan_XML] FROM [sys].[query_store_query] [qsq] JOIN [sys].[query_store_query_text] [qst] ON [qsq].[query_text_id] = [qst].[query_text_id] JOIN [sys].[query_store_plan] [qsp] ON [qsq].[query_id] = [qsp].[query_id] JOIN [sys].[query_store_runtime_stats] [rs] ON [qsp].[plan_id] = [rs].[plan_id] WHERE [qsq].[object_id] = OBJECT_ID(N'Sales.usp_OrderInfo_OrderDate');

Pokud v tomto scénáři hledáme problémy s přidělením paměti – kde je plán uložen do mezipaměti a znovu použit – Query Store nám nepomůže.
Ale co když je konkrétní dotaz zkompilován při spuštění, buď kvůli nápovědě RECOMPILE, nebo protože je to ad-hoc?
Můžeme změnit proceduru tak, aby do příkazu byla přidána nápověda RECOMPILE (což se doporučuje před přidáním RECOMPILE na úrovni procedury nebo spuštěním procedury WITH RECOMIPLE):
ALTER PROCEDURE [Sales].[usp_OrderInfo_OrderDate] @StartDate DATETIME, @EndDate DATETIME AS SELECT [o].[CustomerID], [o].[OrderDate], [o].[ContactPersonID], [ol].[Quantity] FROM [Sales].[Orders] [o] JOIN [Sales].[OrderLines] [ol] ON [o].[OrderID] = [ol].[OrderID] WHERE [OrderDate] BETWEEN @StartDate AND @EndDate ORDER BY [OrderDate] OPTION (RECOMPILE); GO
Nyní znovu spustíme naši proceduru se stejnými vstupními parametry jako dříve a zkontrolujeme výstup:

Všimněte si, že máme nové query_id – text dotazu se změnil, protože jsme do něj přidali OPTION (RECOMPILE) – a také máme dvě nové hodnoty plan_id a pro jeden z našich plánů máme různá čísla přidělení paměti. Pro plan_id 5 je pouze jedno provedení a čísla přidělení paměti odpovídají počátečnímu provedení – takže plán je pro malé časové období. Dva větší rozsahy dat vytvořily stejný plán, ale existuje značná variabilita v přidělení paměti – 94 528 pro minimum a 573 568 pro maximum.
Pokud se podíváme na informace o přidělení paměti pomocí sestav Query Store, tato variabilita se ukáže trochu jinak. Otevřením přehledu Top Resource Consumers z databáze a následnou změnou metriky na Memory Consumption (KB) a Avg se náš dotaz s RECOMPILE dostane na začátek seznamu.
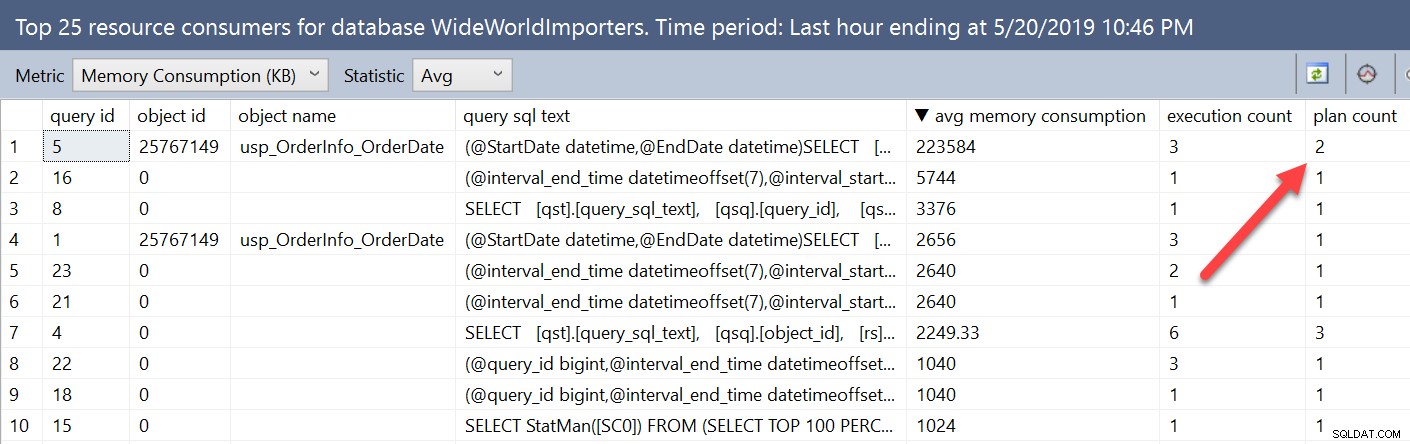
V tomto okně jsou metriky agregovány podle dotazu, nikoli podle plánu. Dotaz, který jsme provedli přímo proti zobrazením Query Store, neuváděl pouze query_id, ale také plan_id. Zde vidíme, že dotaz má dva plány a oba je můžeme zobrazit v okně souhrnu plánu, ale metriky jsou v tomto zobrazení kombinovány pro všechny plány.
Variabilita v přidělení paměti je zřejmá, když se díváme přímo na pohledy. Dotazy s variabilitou můžeme najít pomocí uživatelského rozhraní změnou statistiky z Avg na StDev:
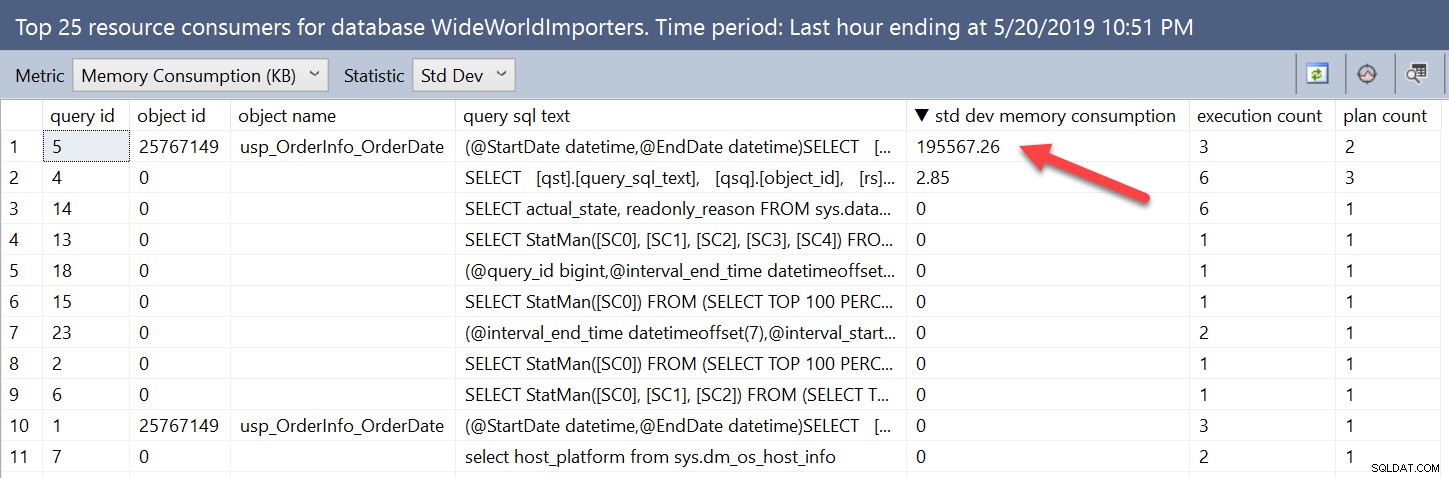
Stejné informace můžeme najít dotazem na zobrazení Query Store a seřazením podle stdev_query_max_used_memory sestupně. Můžeme však také vyhledávat na základě rozdílu mezi minimálním a maximálním přidělením paměti nebo procenta rozdílu. Pokud bychom se například obávali případů, kdy byl rozdíl v grantech větší než 512 MB, mohli bychom spustit:
SELECT [qst].[query_sql_text], [qsq].[query_id], [qsp].[plan_id], [qsq].[object_id], [rs].[count_executions], [rs].[last_execution_time], [rs].[avg_duration], [rs].[avg_logical_io_reads], [rs].[avg_query_max_used_memory] * 8 AS [AvgUsedKB], [rs].[min_query_max_used_memory] * 8 AS [MinUsedKB], [rs].[max_query_max_used_memory] * 8 AS [MaxUsedKB], [rs].[last_query_max_used_memory] * 8 AS [LastUsedKB], [rs].[stdev_query_max_used_memory] * 8 AS [StDevUsedKB], TRY_CONVERT(XML, [qsp].[query_plan]) AS [QueryPlan_XML] FROM [sys].[query_store_query] [qsq] JOIN [sys].[query_store_query_text] [qst] ON [qsq].[query_text_id] = [qst].[query_text_id] JOIN [sys].[query_store_plan] [qsp] ON [qsq].[query_id] = [qsp].[query_id] JOIN [sys].[query_store_runtime_stats] [rs] ON [qsp].[plan_id] = [rs].[plan_id] WHERE ([rs].[max_query_max_used_memory]*8) - ([rs].[min_query_max_used_memory]*8) > 524288;
Ti z vás, kteří používají SQL Server 2017 s indexy Columnstore, kteří mají výhodu zpětné vazby Memory Grant, mohou tyto informace také použít v Query Store. Nejprve změníme naši tabulku Orders tak, aby přidala seskupený index Columnstore:
ALTER TABLE [Sales].[Invoices] DROP CONSTRAINT [FK_Sales_Invoices_OrderID_Sales_Orders]; GO ALTER TABLE [Sales].[Orders] DROP CONSTRAINT [FK_Sales_Orders_BackorderOrderID_Sales_Orders]; GO ALTER TABLE [Sales].[OrderLines] DROP CONSTRAINT [FK_Sales_OrderLines_OrderID_Sales_Orders]; GO ALTER TABLE [Sales].[Orders] DROP CONSTRAINT [PK_Sales_Orders] WITH ( ONLINE = OFF ); GO CREATE CLUSTERED COLUMNSTORE INDEX CCI_Orders ON [Sales].[Orders];
Poté nastavíme režim česání databáze na 140, abychom mohli využít zpětnou vazbu o přidělení paměti:
ALTER DATABASE [WideWorldImporters] SET COMPATIBILITY_LEVEL = 140; GO
Nakonec změníme naši uloženou proceduru tak, abychom z našeho dotazu odstranili OPTION (RECOMPILE) a poté ji několikrát spustili s různými vstupními hodnotami:
ALTER PROCEDURE [Sales].[usp_OrderInfo_OrderDate] @StartDate DATETIME, @EndDate DATETIME AS SELECT [o].[CustomerID], [o].[OrderDate], [o].[ContactPersonID], [ol].[Quantity] FROM [Sales].[Orders] [o] JOIN [Sales].[OrderLines] [ol] ON [o].[OrderID] = [ol].[OrderID] WHERE [OrderDate] BETWEEN @StartDate AND @EndDate ORDER BY [OrderDate]; GO EXEC [Sales].[usp_OrderInfo_OrderDate] '2016-01-01', '2016-01-08'; GO EXEC [Sales].[usp_OrderInfo_OrderDate] '2016-01-01', '2016-06-30'; GO EXEC [Sales].[usp_OrderInfo_OrderDate] '2016-01-01', '2016-12-31'; GO EXEC [Sales].[usp_OrderInfo_OrderDate] '2016-01-01', '2016-06-30'; GO EXEC [Sales].[usp_OrderInfo_OrderDate] '2016-01-01', '2016-01-08'; GO EXEC [Sales].[usp_OrderInfo_OrderDate] '2016-01-01', '2016-12-31'; GO
V obchodě dotazů vidíme následující:

Máme nový plán pro query_id =1, který má jiné hodnoty pro metriky přidělení paměti a o něco nižší StDev, než jsme měli s plan_id 6. Pokud se podíváme do plánu v Query Store, vidíme, že přistupuje ke clusterovanému indexu Columnstore :
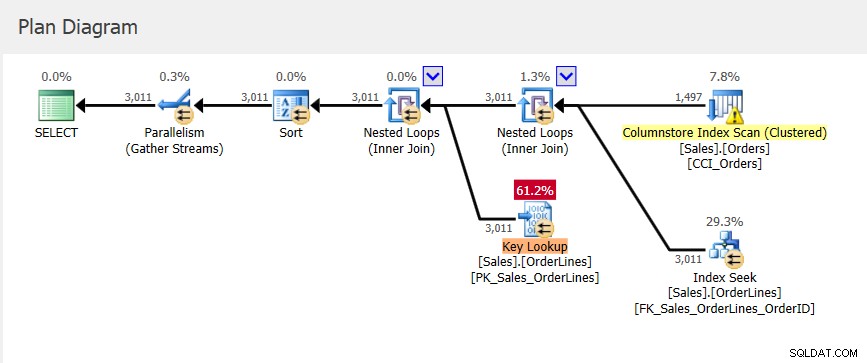
Pamatujte, že plán v Query Store je ten, který byl proveden, ale obsahuje pouze odhady. Zatímco plán v mezipaměti plánu má informace o přidělení paměti aktualizované, když dojde k zpětné vazbě paměti, tyto informace se nepoužijí na existující plán v Query Store.
Shrnutí
Zde je to, co se mi líbí na používání Query Store k prohlížení dotazů s variabilními paměťovými granty:data se automaticky shromažďují. Pokud se tento problém objeví neočekávaně, nemusíme nic zavádět, abychom se pokusili shromáždit informace, již je máme zachycené v Query Store. V případě, kdy je dotaz parametrizován, může být obtížnější najít variabilitu přidělení paměti kvůli potenciálu statických hodnot kvůli ukládání plánu do mezipaměti. Můžeme však také zjistit, že v důsledku rekompilace má dotaz více plánů s extrémně odlišnými hodnotami přidělení paměti, které bychom mohli použít ke sledování problému. Existuje celá řada způsobů, jak problém prozkoumat pomocí dat zachycených v Query Store, a to vám umožní podívat se na problémy proaktivně i reaktivně.